Recognition: unknown
HiddenObjects: Scalable Diffusion-Distilled Spatial Priors for Object Placement
Pith reviewed 2026-05-10 16:04 UTC · model grok-4.3
The pith
Spatial priors for placing objects in scenes can be learned at scale by distilling implicit knowledge from text-conditioned diffusion models, yielding better results than human annotations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Implicit knowledge of natural object-scene relationships encoded in diffusion models can be made explicit by densely evaluating placement candidates through inpainting on authentic backgrounds, producing spatial priors that outperform both human-annotated placements and prior methods on image editing benchmarks.
What carries the argument
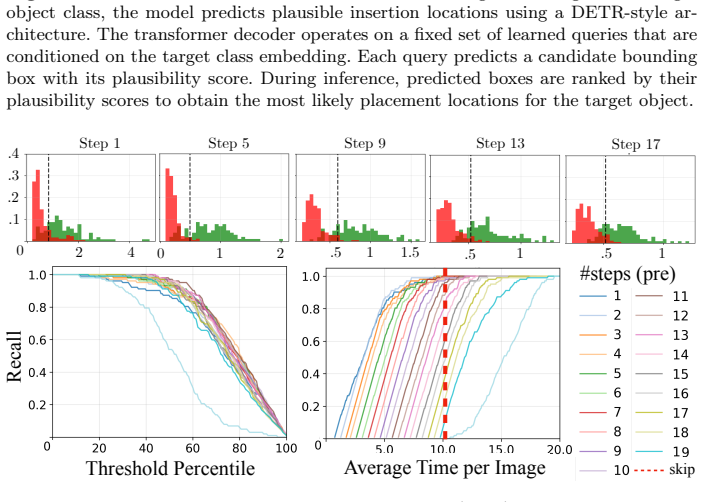
The diffusion-based inpainting pipeline that evaluates dense bounding-box insertions on real scenes to generate ranked, class-conditioned placement scores.
If this is right
- The distilled priors improve object insertion quality in downstream image editing over sparse human annotations.
- A lightweight model distilled from the priors runs 230000 times faster than the original evaluation pipeline.
- The priors surpass both existing placement algorithms and zero-shot vision-language models on object placement tasks.
- The framework enables construction of large-scale placement datasets across many scenes and categories without manual effort.
Where Pith is reading between the lines
- The same distillation process could be repeated with newer diffusion models to iteratively refine the priors.
- These priors might reduce unnatural artifacts when used to guide other generative image models.
- Extending the pipeline to video or 3D scenes could produce temporal or depth-aware placement models.
Load-bearing premise
The inpainting scores measure genuine placement naturalness rather than diffusion model artifacts or biases that might not transfer to editing tasks.
What would settle it
Human evaluators consistently rating high-scoring placements from the pipeline as less realistic than low-scoring ones on a held-out set of scenes.
Figures



















read the original abstract
We propose a method to learn explicit, class-conditioned spatial priors for object placement in natural scenes by distilling the implicit placement knowledge encoded in text-conditioned diffusion models. Prior work relies either on manually annotated data, which is inherently limited in scale, or on inpainting-based object-removal pipelines, whose artifacts promote shortcut learning. To address these limitations, we introduce a fully automated and scalable framework that evaluates dense object placements on high-quality real backgrounds using a diffusion-based inpainting pipeline. With this pipeline, we construct HiddenObjects, a large-scale dataset comprising 27M placement annotations, evaluated across 27k distinct scenes, with ranked bounding box insertions for different images and object categories. Experimental results show that our spatial priors outperform sparse human annotations on a downstream image editing task (3.90 vs. 2.68 VLM-Judge), and significantly surpass existing placement baselines and zero-shot Vision-Language Models for object placement. Furthermore, we distill these priors into a lightweight model for fast practical inference (230,000x faster).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HiddenObjects, a dataset of 27M ranked placement annotations generated by applying a diffusion-based inpainting pipeline to evaluate dense object insertions on 27k real backgrounds. Spatial priors are learned from this data and distilled into a lightweight model; the central claim is that these priors outperform sparse human annotations (3.90 vs. 2.68 VLM-Judge) on a downstream image-editing task, exceed existing placement baselines and zero-shot VLMs, and enable 230,000x faster inference.
Significance. If the evaluation is shown to be independent of the diffusion model and VLM-Judge biases, the work would provide a scalable, annotation-free route to explicit spatial priors that meaningfully improves object placement in editing pipelines. The reported inference speedup would also make the approach practically deployable.
major comments (3)
- [Abstract] Abstract: The headline result (3.90 vs. 2.68 VLM-Judge on the editing task) is presented without any description of the inpainting pipeline controls, the exact ranking procedure for the 27M placements, statistical significance tests, or validation that the VLM-Judge correlates with human naturalness judgments. These omissions make it impossible to assess whether the reported gains reflect genuine placement quality or pipeline artifacts.
- [Evaluation] Evaluation / downstream task: The manuscript does not report any ablation that removes or replaces the diffusion-inpainting component, nor any correlation analysis between the VLM-Judge and the diffusion model family used to generate the training scores. Without such checks, the superiority claim risks circularity, as both the training signal and the evaluation metric could encode the same model biases rather than independent naturalness.
- [§4] §4 (or equivalent experiments section): No human-study validation or cross-model judge comparison is provided to confirm that the VLM-Judge metric is orthogonal to the diffusion model used for data generation. This is load-bearing for the central claim that the distilled priors transfer to real editing tasks without shortcut learning.
minor comments (2)
- [Dataset construction] The description of scene and category diversity in the 27k backgrounds and 27M annotations would benefit from explicit statistics (e.g., object category distribution, scene type coverage) to allow readers to judge generalization.
- [Distillation] Notation for the distilled lightweight model (architecture, training objective, exact speedup measurement) is introduced only in the abstract and would be clearer with a dedicated paragraph or table in the main text.
Simulated Author's Rebuttal
We thank the referee for the insightful comments on our paper. We have carefully considered each point and provide detailed responses below. Where appropriate, we will revise the manuscript to address the concerns raised, particularly by adding more methodological details, ablations, and validation studies.
read point-by-point responses
-
Referee: The headline result (3.90 vs. 2.68 VLM-Judge on the editing task) is presented without any description of the inpainting pipeline controls, the exact ranking procedure for the 27M placements, statistical significance tests, or validation that the VLM-Judge correlates with human naturalness judgments. These omissions make it impossible to assess whether the reported gains reflect genuine placement quality or pipeline artifacts.
Authors: We agree that additional details in the abstract would improve clarity. In the revised manuscript, we will expand the abstract to include a brief overview of the inpainting pipeline controls and the ranking procedure used to generate the 27M annotations. We will also report p-values or statistical significance for the VLM-Judge comparisons. For the correlation of VLM-Judge with human judgments, we will add a new analysis in the supplementary material showing agreement on a held-out set of images. revision: yes
-
Referee: The manuscript does not report any ablation that removes or replaces the diffusion-inpainting component, nor any correlation analysis between the VLM-Judge and the diffusion model family used to generate the training scores. Without such checks, the superiority claim risks circularity, as both the training signal and the evaluation metric could encode the same model biases rather than independent naturalness.
Authors: We acknowledge the potential for circularity and the value of such ablations. While the training signal comes from diffusion-based inpainting scores and the evaluation uses a separate VLM-Judge, we will add in the revision a correlation analysis between the diffusion scores and VLM-Judge scores on the same placements to demonstrate they capture distinct aspects. We will also include an ablation study replacing the diffusion inpainting with a non-diffusion baseline where possible, and discuss how using real backgrounds and dense placements mitigates shortcut learning. This will be detailed in the experiments section. revision: yes
-
Referee: No human-study validation or cross-model judge comparison is provided to confirm that the VLM-Judge metric is orthogonal to the diffusion model used for data generation. This is load-bearing for the central claim that the distilled priors transfer to real editing tasks without shortcut learning.
Authors: We agree that additional validation would strengthen the work. In the revised manuscript, we will include results from a small-scale human study on a subset of the image editing outputs to correlate VLM-Judge scores with human naturalness ratings. We will also perform and report cross-model judge comparisons using an alternative vision-language model to verify consistency and orthogonality to the original diffusion model family. These will be added to Section 4. revision: yes
Circularity Check
No significant circularity: derivation is data-driven and externally evaluated.
full rationale
The paper generates a large placement dataset (27M annotations) via diffusion inpainting on real backgrounds, trains class-conditioned spatial priors on the resulting ranked scores, and evaluates the priors on a downstream image-editing task using an independent VLM-Judge metric. No equations, self-definitions, or self-citations are presented that reduce any load-bearing claim (e.g., the 3.90 vs 2.68 VLM-Judge result or outperformance of baselines) to the input scores by construction. The pipeline is explicitly described as distilling implicit knowledge into explicit priors and then testing transfer, with no renaming of known results or ansatz smuggling. The derivation chain therefore remains self-contained against the stated external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Text-conditioned diffusion models contain implicit, class-conditioned knowledge about realistic object placement in natural scenes.
Reference graph
Works this paper leans on
-
[1]
In: ICCV (2025)
Abdelreheem, A., Aleotti, F., Watson, J., Qureshi, Z., Eldesokey, A., Wonka, P., Brostow, G., Vicente, S., Garcia-Hernando, G.: Placeit3d: Language-guided object placement in real 3d scenes. In: ICCV (2025)
2025
-
[2]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report (2025),https://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Batifol, S., Blattmann, A., Boesel, F., Consul, S., Diagne, C., Dockhorn, T., En- glish, J., English, Z., Esser, P., Kulal, S., et al.: Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space. arxivabs/2506.15742 (2025)
work page internal anchor Pith review arXiv 2025
-
[4]
Bau,D.,Zhu,J.Y.,Strobelt,H.,Lapedriza,A.,Zhou,B.,Torralba,A.:Understand- ing the role of individual units in a deep neural network. Proceedings of the Na- tional Academy of Sciences (2020).https://doi.org/10.1073/pnas.1907375117, https://www.pnas.org/content/early/2020/08/31/1907375117
-
[5]
In: ICLR (2019)
Bau, D., Zhu, J.Y., Strobelt, H., Zhou, B., Tenenbaum, J.B., Freeman, W.T., Torralba, A.: Gan dissection: Visualizing and understanding generative adversarial networks. In: ICLR (2019)
2019
-
[6]
ACM Comput
Boukerche, A., Zheng, L., Alfandi, O.: Outlier detection: Methods, models, and classification. ACM Comput. Surv.53(3), 55:1–55:37 (2021)
2021
-
[7]
In: ECCV
Canet Tarrés, G., Lin, Z., Zhang, Z., Zhang, J., Song, Y., Ruta, D., Gilbert, A., Collomosse, J., Kim, S.Y.: Thinking outside the bbox: Unconstrained generative object compositing. In: ECCV. pp. 476–495 (2024)
2024
-
[8]
Referring layer decomposition.arXiv preprint arXiv:2602.19358, 2026
Chen, F., Shen, Y., Xu, L., Yuan, Y., Zhang, S., Niu, Y., Wen, L.: Referring layer decomposition. arXiv preprint arXiv:2602.19358 (2026)
-
[9]
In: CVPR
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: CVPR. pp. 24185–24198 (2024)
2024
-
[10]
Neurocomputing p
Cheng, X., Zhai, P., Yang, D., Meng, X., Xia, Y., Zhang, L.: Diverse object place- ment with dual interaction. Neurocomputing p. 131161 (2025)
2025
-
[11]
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large- scale hierarchical image database. In: CVPR. pp. 248–255 (2009).https://doi. org/10.1109/CVPR.2009.5206848
-
[12]
In: ICCV
Doersch, C., Gupta, A., Efros, A.A.: Unsupervised visual representation learning by context prediction. In: ICCV. pp. 1422–1430 (2015)
2015
-
[13]
In: ECCV
Dvornik, N., Mairal, J., Schmid, C.: Modeling visual context is key to augmenting object detection datasets. In: ECCV. pp. 364–380 (2018)
2018
-
[14]
http://www.pascal-network.org/challenges/VOC/voc2012/workshop/index.html 16 M
Everingham, M., Van Gool, L., Williams, C.K.I., Winn, J., Zisserman, A.: The PASCAL Visual Object Classes Challenge 2012 (VOC2012) Results. http://www.pascal-network.org/challenges/VOC/voc2012/workshop/index.html 16 M. Schouten et al
2012
-
[15]
In: CVPR (2008)
Galleguillos, C., Rabinovich, A., Belongie, S.: Object categorization using co- occurrence, location and appearance. In: CVPR (2008)
2008
-
[16]
ICME (2025)
Gao, B., Zhang, B., Niu, L.: Object placement for anything. ICME (2025)
2025
-
[17]
In: ICCV (2025)
Gao, J., Joseph, K.J., la Torre, F.D.: Teleportraits: Training-free people insertion into any scene. In: ICCV (2025)
2025
-
[18]
In: CVPR (2019)
Gupta, A., Dollar, P., Girshick, R.: LVIS: A dataset for large vocabulary instance segmentation. In: CVPR (2019)
2019
-
[19]
ACM Trans- actions on graphics (TOG)26(3), 4–es (2007)
Hays, J., Efros, A.A.: Scene completion using millions of photographs. ACM Trans- actions on graphics (TOG)26(3), 4–es (2007)
2007
-
[20]
arXiv preprint arXiv:2412.14462 (2024)
He, J., Li, W., Liu, Y., Kim, J., Wei, D., Pfister, H.: Affordance-aware object insertion via mask-aware dual diffusion. arXiv preprint arXiv:2412.14462 (2024)
-
[21]
In: Moens, M., Huang, X., Specia, L., Yih, S.W
Hessel, J., Holtzman, A., Forbes, M., Bras, R.L., Choi, Y.: Clipscore: A reference- free evaluation metric for image captioning. In: Moens, M., Huang, X., Specia, L., Yih, S.W. (eds.) EMNLP. pp. 7514–7528. Association for Computational Linguis- tics (2021)
2021
-
[22]
In: CVPR (2025)
Huang, I., Bao, Y., Truong, K., Zhou, H., Schmid, C., Guibas, L., Fathi, A.: Fire- place: Geometric refinements of llm common sense reasoning for 3d object place- ment. In: CVPR (2025)
2025
-
[23]
In: CVPR
Kulal, S., Brooks, T., Aiken, A., Wu, J., Yang, J., Lu, J., Efros, A.A., Singh, K.K.: Putting people in their place: Affordance-aware human insertion into scenes. In: CVPR. pp. 17089–17099 (2023)
2023
-
[24]
NeurIPS31(2018)
Lee, D., Liu, S., Gu, J., Liu, M.Y., Yang, M.H., Kautz, J.: Context-aware synthesis and placement of object instances. NeurIPS31(2018)
2018
-
[25]
ACM Multimedia (2025)
Li, C., Wang, W., Li, Q., Lepri, B., Sebe, N., Nie, W.: Freeinsert: Disentangled text-guided object insertion in 3d gaussian scene without spatial priors. ACM Multimedia (2025)
2025
-
[26]
Li, T., Ku, M., Wei, C., Chen, W.: Dreamedit: Subject-driven image editing. Trans. Mach. Learn. Res. (2023)
2023
-
[27]
arXiv preprint arXiv:2507.16813 (2025)
Liang, D., Jia, J., Liu, Y., Lau, R.W.: Hocomp: Interaction-aware human-object composition. arXiv preprint arXiv:2507.16813 (2025)
-
[28]
Lin, C.H., Yumer, E., Wang, O., Shechtman, E., Lucey, S.: St-gan: Spatial trans- formergenerativeadversarialnetworksforimagecompositing.In:CVPR.pp.9455– 9464 (2018)
2018
-
[29]
In: ECCV
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: ECCV. pp. 740–755 (2014)
2014
-
[30]
In: CVPR
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tuning. In: CVPR. pp. 26296–26306 (2024)
2024
-
[31]
arXiv preprint arXiv:2107.01889 (2021)
Liu, L., Liu, Z., Zhang, B., Li, J., Niu, L., Liu, Q., Zhang, L.: Opa: object placement assessment dataset. arXiv preprint arXiv:2107.01889 (2021)
-
[32]
arXiv preprint arXiv:2309.15508 (2023)
Lu, L., Li, J., Zhang, B., Niu, L.: Dreamcom: Finetuning text-guided inpainting model for image composition. arXiv preprint arXiv:2309.15508 (2023)
-
[33]
arXiv preprint arXiv:2205.14280 (2022)
Niu, L., Liu, Q., Liu, Z., Li, J.: Fast object placement assessment. arXiv preprint arXiv:2205.14280 (2022)
-
[34]
In: CVPR (2019)
Papadopoulos, D.P., Tamaazousti, Y., Ofli, F., Weber, I., Torralba, A.: How to make a pizza: Learning a compositional layer-based gan model. In: CVPR (2019)
2019
-
[35]
In: ECCV
Parihar, R., Gupta, H., VS, S., Babu, R.V.: Text2place: Affordance-aware text guided human placement. In: ECCV. pp. 57–77 (2024)
2024
-
[36]
In: CVPR (2025) HiddenObjects17
Parihar, R., Sarkar, S., Vora, S., Kundu, J., Babu, R.V.: Monoplace3d: Learning 3d-aware object placement for 3d monocular detection. In: CVPR (2025) HiddenObjects17
2025
-
[37]
arXiv preprint arXiv:2504.17076 (2025)
Petersen, J., Abati, D., Habibian, A., Wiggers, A.: Scene-aware location mod- eling for data augmentation in automotive object detection. arXiv preprint arXiv:2504.17076 (2025)
-
[38]
In: ICLR (2024)
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. In: ICLR (2024)
2024
-
[39]
In: CVPR
Poska, M., Huang, S.X., Hwang, B.: Hopnet: Harmonizing object placement net- work for realistic image generation via object composition. In: CVPR. pp. 6344– 6354 (2025)
2025
-
[40]
In: ECCV
Qin, Y., Xu, J., Wang, R., Chen, X.: Think before placement: Common sense enhanced transformer for object placement. In: ECCV. pp. 35–50 (2024)
2024
-
[41]
In: ICCV (2007)
Rabinovich, A., Vedaldi, A., Galleguillos, C., Wiewiora, E., Belongie, S.: Objects in context. In: ICCV (2007)
2007
-
[42]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., Chen, M.: Hierarchical text- conditional image generation with clip latents. arXiv preprint arXiv:2204.06125 1(2), 3 (2022)
work page internal anchor Pith review arXiv 2022
-
[43]
Ren, T., Liu, S., Zeng, A., Lin, J., Li, K., Cao, H., Chen, J., Huang, X., Chen, Y., Yan, F., Zeng, Z., Zhang, H., Li, F., Yang, J., Li, H., Jiang, Q., Zhang, L.: Grounded sam: Assembling open-world models for diverse visual tasks (2024)
2024
-
[44]
In: CVPR (2021)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR (2021)
2021
-
[45]
In: SCIA (2025)
Schouten, M., Kaya, M.O., Belongie, S., Papadopoulos, D.P.: Poem: Precise object- level editing via mllm control. In: SCIA (2025)
2025
-
[46]
Schuhmann, C.: Aesthetic predictor v2.5.https://github.com/discus0434/ aesthetic-predictor-v2-5/(may 2024), gitHub repository
2024
-
[47]
In: NeurIPS (2022)
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al.: Laion-5b: An open large-scale dataset for training next generation image-text models. In: NeurIPS (2022)
2022
-
[48]
In: ICLR (2025), https://openreview.net/forum?id=ZeaTvXw080
Tewel,Y.,Gal,R.,Samuel,D.,Atzmon,Y.,Wolf,L.,Chechik,G.:Add-it:Training- free object insertion in images with pretrained diffusion models. In: ICLR (2025), https://openreview.net/forum?id=ZeaTvXw080
2025
-
[49]
In: ICCV
Torralba: Context-based vision system for place and object recognition. In: ICCV. pp. 273–280 (2003)
2003
-
[50]
In: CVPR
Tripathi, S., Chandra, S., Agrawal, A., Tyagi, A., Rehg, J.M., Chari, V.: Learning to generate synthetic data via compositing. In: CVPR. pp. 461–470 (2019)
2019
-
[51]
In: ECCV Workshop
Volokitin, A., Susmelj, I., Agustsson, E., Van Gool, L., Timofte, R.: Efficiently detecting plausible locations for object placement using masked convolutions. In: ECCV Workshop. pp. 252–266 (2020)
2020
-
[52]
In: CVPR (2025)
Wasserman, N., Rotstein, N., Ganz, R., Kimmel, R.: Paint by inpaint: Learning to add image objects by removing them first. In: CVPR (2025)
2025
-
[53]
In: ICCV
Winter,D.,Shul,A.,Cohen,M.,Berman,D.,Pritch,Y.,Rav-Acha,A.,Hoshen,Y.: Objectmate: A recurrence prior for object insertion and subject-driven generation. In: ICCV. pp. 16281–16291 (2025)
2025
-
[54]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-image technical report. arXiv preprint arXiv:2508.02324 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
In: AAAI
Xu, J., Huang, Y., Cheng, J., Yang, Y., Xu, J., Wang, Y., Duan, W., Yang, S., Jin, Q., Li, S., Teng, J., Yang, Z., Zheng, W., Liu, X., Zhang, D., Ding, M., Zhang, X., Huang, S., Gu, X., Huang, M., Tang, J., Dong, Y.: Visionreward: Fine-grained multi-dimensional human preference learning for image and video generation. In: AAAI. pp. 11269–11277 (2026) 18 M...
2026
-
[56]
In: NeurIPS
Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagere- ward: learning and evaluating human preferences for text-to-image generation. In: NeurIPS. pp. 15903–15935 (2023)
2023
-
[57]
ImgEdit: A Unified Image Editing Dataset and Benchmark
Ye, Y., He, X., Li, Z., Lin, B., Yuan, S., Yan, Z., Hou, B., Yuan, L.: Imgedit: A unified image editing dataset and benchmark. arXiv preprint arXiv:2505.20275 (2025)
work page internal anchor Pith review arXiv 2025
-
[58]
In: NeurIPS (2023)
Yuan, L., Hong, J., Sarukkai, V., Fatahalian, K.: Learning to place objects into scenes by hallucinating scenes around objects. In: NeurIPS (2023)
2023
- [59]
-
[60]
In: ECCV
Zhang, L., Wen, T., Min, J., Wang, J., Han, D., Shi, J.: Learning object placement by inpainting for compositional data augmentation. In: ECCV. pp. 566–581 (2020)
2020
-
[61]
In: CVPR
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: CVPR. pp. 3836–3847 (2023)
2023
-
[62]
Computational Visual Media 6(1), 79–93 (2020)
Zhang, S.H., Zhou, Z.P., Liu, B., Dong, X., Hall, P.: What and where: A context- based recommendation system for object insertion. Computational Visual Media 6(1), 79–93 (2020)
2020
-
[63]
IEEE transactions on pattern analysis and machine intelligence40(6), 1452–1464 (2017)
Zhou, B., Lapedriza, A., Khosla, A., Oliva, A., Torralba, A.: Places: A 10 million image database for scene recognition. IEEE transactions on pattern analysis and machine intelligence40(6), 1452–1464 (2017)
2017
-
[64]
IJCV127(3), 302– 321 (2019)
Zhou, B., Zhao, H., Puig, X., Xiao, T., Fidler, S., Barriuso, A., Torralba, A.: Semantic understanding of scenes through the ade20k dataset. IJCV127(3), 302– 321 (2019)
2019
-
[65]
IEEE Transactions on Visualization and Com- puter Graphics30(7), 3151–3165 (2022)
Zhou, H., Ma, R., Zhang, L.X., Gao, L., Mahdavi-Amiri, A., Zhang, H.: Sac-gan: Structure-aware image composition. IEEE Transactions on Visualization and Com- puter Graphics30(7), 3151–3165 (2022)
2022
-
[66]
In: CVPR
Zhou, H., Zuo, X., Ma, R., Cheng, L.: Bootplace: Bootstrapped object placement with detection transformers. In: CVPR. pp. 19294–19303 (2025)
2025
-
[67]
In: ECCV
Zhou, S., Liu, L., Niu, L., Zhang, L.: Learning object placement via dual-path graph completion. In: ECCV. pp. 373–389 (2022)
2022
-
[68]
apple”, “cat
Zhu, S., Lin, Z., Cohen, S., Kuen, J., Zhang, Z., Chen, C.: Topnet: Transformer- based object placement network for image compositing. In: CVPR. pp. 1838–1847 (2023) HiddenObjectsA-1 Appendix potted plant Input BG Human Annot. Ours elephant Input BG Human Annot. Ours keyboard car elephant cat bicycle pizza Fig.9: Image inpainting with object placement pri...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.