Recognition: unknown
HOG-Layout: Hierarchical 3D Scene Generation, Optimization and Editing via Vision-Language Models
Pith reviewed 2026-05-10 15:10 UTC · model grok-4.3
The pith
HOG-Layout generates text-driven hierarchical 3D scenes with retrieval-augmented consistency and optimization for physical plausibility, enabling real-time editing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HOG-Layout enables text-driven hierarchical scene generation, optimization and real-time scene editing with large language models (LLMs) and vision-language models (VLMs). It improves scene semantic consistency and plausibility through retrieval-augmented generation (RAG) technology, incorporates an optimization module to enhance physical consistency, and adopts a hierarchical representation to enhance inference and optimization, achieving real-time editing. Experimental results demonstrate that HOG-Layout produces more reasonable environments compared with existing baselines, while supporting fast and intuitive scene editing.
What carries the argument
The hierarchical 3D scene representation that combines retrieval-augmented generation for semantic matching with a dedicated optimization module for physical constraints.
If this is right
- Generated scenes maintain higher semantic alignment with text descriptions than prior automated methods.
- Physical constraints are enforced automatically through the optimization stage.
- Hierarchical structure allows scene modifications in real time rather than full regeneration.
- The system outperforms baseline approaches in producing overall reasonable 3D environments.
- Editing becomes intuitive because changes propagate efficiently through the hierarchy.
Where Pith is reading between the lines
- Users without 3D modeling expertise could build and tweak complex virtual spaces using everyday language descriptions.
- Integration with embodied AI agents might become simpler if scenes can be regenerated or adjusted on the fly to match new instructions.
- Development pipelines for VR experiences could shorten if text-to-scene conversion reduces the need for manual layout work.
- Comparative user studies measuring editing time and perceived realism against existing tools would directly test the practical speedup.
Load-bearing premise
That retrieval-augmented generation paired with the optimization module will produce both semantic consistency and physical plausibility without creating new artifacts or needing repeated manual adjustments.
What would settle it
A collection of text prompts for which the output scenes contain either clear semantic mismatches with the input description or physically impossible arrangements that the optimization step cannot correct without user intervention.
Figures











read the original abstract
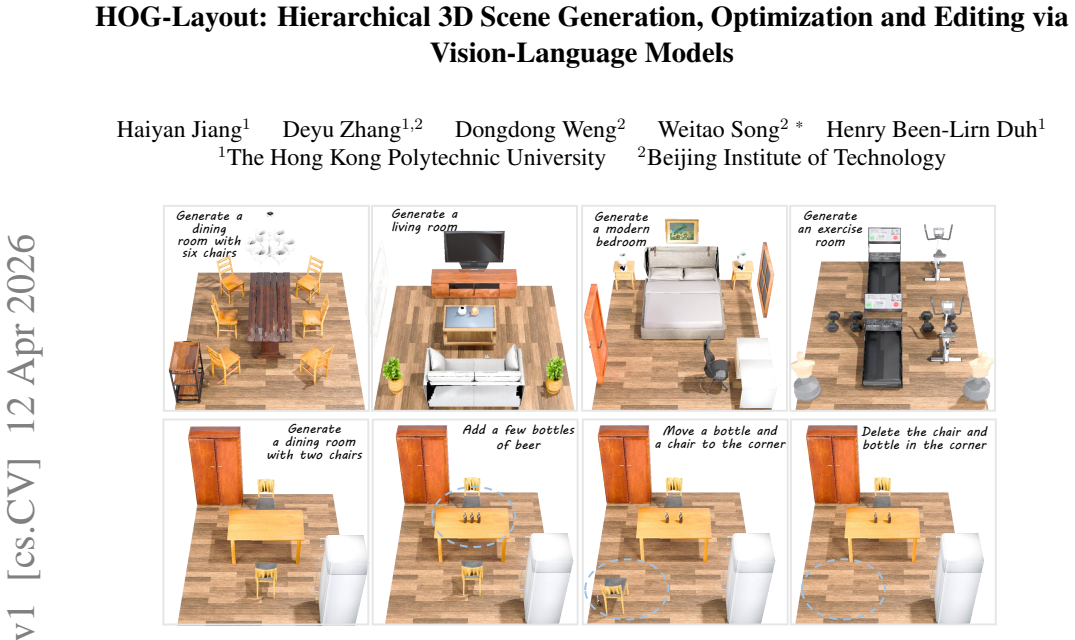
3D layout generation and editing play a crucial role in Embodied AI and immersive VR interaction. However, manual creation requires tedious labor, while data-driven generation often lacks diversity. The emergence of large models introduces new possibilities for 3D scene synthesis. We present HOG-Layout that enables text-driven hierarchical scene generation, optimization and real-time scene editing with large language models (LLMs) and vision-language models (VLMs). HOG-Layout improves scene semantic consistency and plausibility through retrieval-augmented generation (RAG) technology, incorporates an optimization module to enhance physical consistency, and adopts a hierarchical representation to enhance inference and optimization, achieving real-time editing. Experimental results demonstrate that HOG-Layout produces more reasonable environments compared with existing baselines, while supporting fast and intuitive scene editing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HOG-Layout, a text-driven framework for hierarchical 3D scene generation, optimization, and real-time editing that combines LLMs and VLMs. It employs retrieval-augmented generation (RAG) to improve semantic consistency, an optimization module to enhance physical plausibility, and a hierarchical scene representation to support efficient inference and editing. The central claim is that HOG-Layout produces more reasonable 3D environments than existing baselines while enabling fast and intuitive scene editing.
Significance. If the experimental claims are substantiated, the work could advance Embodied AI and VR by providing an integrated pipeline that leverages large models for semantic understanding while using optimization to enforce physical constraints. The hierarchical representation enabling real-time editing is a potentially useful practical contribution, though its impact depends on rigorous validation of the optimization module's role.
major comments (1)
- [Experimental evaluation] Experimental evaluation section: the headline claim of superior results over baselines rests on the optimization module (paired with RAG) delivering physical consistency, yet no ablation removing the optimizer is reported, nor are quantitative physical metrics such as inter-object penetration volume, support violation counts, or stability under gravity simulation provided. This leaves the attribution of improvements and the 'without introducing new artifacts' aspect untested, directly undermining the central experimental assertion.
minor comments (1)
- [Abstract] Abstract: the statement that 'experimental results demonstrate' superiority would be strengthened by briefly naming the datasets, number of scenes, and specific baselines used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment on experimental evaluation below and will revise the manuscript accordingly to strengthen the claims.
read point-by-point responses
-
Referee: [Experimental evaluation] Experimental evaluation section: the headline claim of superior results over baselines rests on the optimization module (paired with RAG) delivering physical consistency, yet no ablation removing the optimizer is reported, nor are quantitative physical metrics such as inter-object penetration volume, support violation counts, or stability under gravity simulation provided. This leaves the attribution of improvements and the 'without introducing new artifacts' aspect untested, directly undermining the central experimental assertion.
Authors: We acknowledge that the manuscript does not include an explicit ablation study isolating the optimization module nor quantitative physical metrics such as inter-object penetration volume, support violation counts, or gravity-based stability simulations. To address this directly, we will add a dedicated ablation study in the revised experimental section comparing HOG-Layout with and without the optimization module. We will also report quantitative physical consistency metrics, including penetration volumes, support violation counts, and results from gravity simulations, to substantiate the module's contribution and confirm that improvements occur without introducing new artifacts. These additions will strengthen the attribution of results and the overall experimental validation. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper describes an integrated system (RAG + optimization module + hierarchical representation) for text-driven 3D scene generation and editing. No mathematical derivations, first-principles predictions, or equations are presented that could reduce to fitted inputs or self-definitions. Experimental claims rest on comparisons to baselines rather than any self-referential prediction loop. No load-bearing self-citations or uniqueness theorems are invoked in the provided text. The architecture is a pragmatic combination of existing LLM/VLM techniques; its performance claims are empirical and externally falsifiable via the reported user studies and visuals.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Optuna: A next-generation hyperparameter optimization framework
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD international conference on knowl- edge discovery & data mining , pages 2623–2631, 2019. 3
2019
-
[3]
Cc3d: Layout-conditioned generation of compositional 3d scenes
Sherwin Bahmani, Jeong Joon Park, Despoina Paschalidou, Xingguang Yan, Gordon Wetzstein, Leonidas Guibas, and Andrea Tagliasacchi. Cc3d: Layout-conditioned generation of compositional 3d scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision , pages 7171– 7181, 2023. 2
2023
-
[4]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for un- derstanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Gaudi: A neural architect for immersive 3d scene genera- tion
Miguel Angel Bautista, Pengsheng Guo, Samira Abnar, Wal- ter Talbott, Alexander Toshev, Zhuoyuan Chen, Laurent Dinh, Shuangfei Zhai, Hanlin Goh, Daniel Ulbricht, et al. Gaudi: A neural architect for immersive 3d scene genera- tion. Advances in Neural Information Processing Systems , 35:25102–25116, 2022. 2
2022
-
[6]
Algorithms for hyper-parameter optimization
James Bergstra, Rémi Bardenet, Yoshua Bengio, and Balázs Kégl. Algorithms for hyper-parameter optimization. Ad- vances in neural information processing systems , 24, 2011. 3
2011
-
[7]
Vip- llava: Making large multimodal models understand arbitrary visual prompts
Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P Meyer, Yuning Chai, Dennis Park, and Yong Jae Lee. Vip- llava: Making large multimodal models understand arbitrary visual prompts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 12914– 12923, 2024. 2
2024
-
[8]
I-design: Personal- ized llm interior designer
Ata Çelen, Guo Han, Konrad Schindler, Luc Van Gool, Iro Armeni, Anton Obukhov, and Xi Wang. I-design: Personal- ized llm interior designer. In European Conference on Com- puter Vision, pages 217–234. Springer, 2024. 2
2024
-
[9]
Text to 3d scene genera- tion with rich lexical grounding
Angel Chang, Will Monroe, Manolis Savva, Christopher Potts, and Christopher D Manning. Text to 3d scene genera- tion with rich lexical grounding. In Proceedings of the 53rd Annual Meeting of the Association for Computational Lin- guistics and the 7th International Joint Conference on Nat- ural Language Processing (V olume 1: Long Papers) , pages 53–62, 2015. 2
2015
-
[10]
Sceneseer: 3d scene design with natural language
Angel X Chang, Mihail Eric, Manolis Savva, and Christo- pher D Manning. Sceneseer: 3d scene design with natural language. arXiv preprint arXiv:1703.00050, 2017. 2
-
[11]
Ll3da: Visual interactive instruction tuning for omni-3d understanding reasoning and planning
Sijin Chen, Xin Chen, Chi Zhang, Mingsheng Li, Gang Yu, Hao Fei, Hongyuan Zhu, Jiayuan Fan, and Tao Chen. Ll3da: Visual interactive instruction tuning for omni-3d understanding reasoning and planning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26428–26438, 2024. 2
2024
-
[12]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13142–13153, 2023. 6, 3
2023
-
[13]
Global-local tree search in vlms for 3d indoor scene generation
Wei Deng, Mengshi Qi, and Huadong Ma. Global-local tree search in vlms for 3d indoor scene generation. In Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8975–8984, 2025. 1, 2
2025
-
[14]
Disentangled 3d scene genera- tion with layout learning
Dave Epstein, Ben Poole, Ben Mildenhall, Alexei A Efros, and Aleksander Holynski. Disentangled 3d scene genera- tion with layout learning. arXiv preprint arXiv:2402.16936,
-
[15]
Ctrl-room: Controllable text-to-3d room meshes generation with layout constraints
Chuan Fang, Yuan Dong, Kunming Luo, Xiaotao Hu, Rakesh Shrestha, and Ping Tan. Ctrl-room: Controllable text-to-3d room meshes generation with layout constraints. In 2025 International Conference on 3D Vision (3DV), pages 692–701. IEEE, 2025. 1, 2
2025
-
[16]
Layoutgpt: Compositional visual plan- ning and generation with large language models
Weixi Feng, Wanrong Zhu, Tsu-jui Fu, Varun Jampani, Ar- jun Akula, Xuehai He, Sugato Basu, Xin Eric Wang, and William Yang Wang. Layoutgpt: Compositional visual plan- ning and generation with large language models. Advances in Neural Information Processing Systems, 36:18225–18250,
-
[17]
3d-future: 3d fur- niture shape with texture
Huan Fu, Rongfei Jia, Lin Gao, Mingming Gong, Binqiang Zhao, Steve Maybank, and Dacheng Tao. 3d-future: 3d fur- niture shape with texture. International Journal of Computer Vision, 129(12):3313–3337, 2021. 6
2021
-
[18]
3d-llm: In- jecting the 3d world into large language models
Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, and Chuang Gan. 3d-llm: In- jecting the 3d world into large language models. Advances in Neural Information Processing Systems, 36:20482–20494,
-
[19]
Scenenn: A scene meshes dataset with annotations
Binh-Son Hua, Quang-Hieu Pham, Duc Thanh Nguyen, Minh-Khoi Tran, Lap-Fai Yu, and Sai-Kit Yeung. Scenenn: A scene meshes dataset with annotations. In 2016 fourth in- ternational conference on 3D vision (3DV) , pages 92–101. Ieee, 2016. 2
2016
-
[20]
Chat-scene: Bridging 3d scene and large language models with object identifiers
Haifeng Huang, Yilun Chen, Zehan Wang, Rongjie Huang, Runsen Xu, Tai Wang, Luping Liu, Xize Cheng, Yang Zhao, Jiangmiao Pang, et al. Chat-scene: Bridging 3d scene and large language models with object identifiers. Advances in Neural Information Processing Systems , 37: 113991–114017, 2024. 2
2024
-
[21]
Openclip
Gabriel Ilharco, Mitchell Wortsman, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Hannaneh Hajishirzi, Ali Farhadi, et al. Openclip. Zenodo, 2021. 4
2021
-
[22]
Billion- scale similarity search with gpus
Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion- scale similarity search with gpus. IEEE transactions on big data, 7(3):535–547, 2019. 3
2019
-
[23]
Scaffolding coordinates to promote vision-language coordination in large multi-modal models
Xuanyu Lei, Zonghan Yang, Xinrui Chen, Peng Li, and Yang Liu. Scaffolding coordinates to promote vision-language coordination in large multi-modal models. In Proceedings of the 31st International Conference on Computational Lin- guistics, pages 2886–2903, 2025. 2
2025
-
[24]
Hyperband: A novel bandit-based approach to hyperparameter optimization
Lisha Li, Kevin Jamieson, Giulia DeSalvo, Afshin Ros- tamizadeh, and Ameet Talwalkar. Hyperband: A novel bandit-based approach to hyperparameter optimization. Journal of Machine Learning Research, 18(185):1–52, 2018. 3
2018
-
[25]
Grains: Generative re- cursive autoencoders for indoor scenes
Manyi Li, Akshay Gadi Patil, Kai Xu, Siddhartha Chaudhuri, Owais Khan, Ariel Shamir, Changhe Tu, Baoquan Chen, Daniel Cohen-Or, and Hao Zhang. Grains: Generative re- cursive autoencoders for indoor scenes. ACM Transactions on Graphics (TOG), 38(2):1–16, 2019. 1, 2
2019
-
[26]
2024.doi:10.48550/arXiv.2402.04717
Chenguo Lin and Yadong Mu. Instructscene: Instruction- driven 3d indoor scene synthesis with semantic graph prior. arXiv preprint arXiv:2402.04717, 2024. 2
-
[27]
Flairgpt: Repurposing llms for interior designs
Gabrielle Littlefair, Niladri Shekhar Dutt, and Niloy J Mitra. Flairgpt: Repurposing llms for interior designs. In Computer Graphics F orum, page e70036. Wiley Online Library, 2025. 2
2025
-
[28]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. Advances in neural information processing systems, 36:34892–34916, 2023. 2
2023
-
[29]
End-to-end optimization of scene layout
Andrew Luo, Zhoutong Zhang, Jiajun Wu, and Joshua B Tenenbaum. End-to-end optimization of scene layout. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition , pages 3754–3763, 2020. 1, 2
2020
-
[30]
Language-driven synthe- sis of 3d scenes from scene databases
Rui Ma, Akshay Gadi Patil, Matthew Fisher, Manyi Li, Sören Pirk, Binh-Son Hua, Sai-Kit Yeung, Xin Tong, Leonidas Guibas, and Hao Zhang. Language-driven synthe- sis of 3d scenes from scene databases. ACM Transactions on Graphics (TOG), 37(6):1–16, 2018. 2
2018
-
[31]
Generative layout modeling using con- straint graphs
Wamiq Para, Paul Guerrero, Tom Kelly, Leonidas J Guibas, and Peter Wonka. Generative layout modeling using con- straint graphs. In Proceedings of the IEEE/CVF interna- tional conference on computer vision , pages 6690–6700,
-
[32]
Cofs: Controllable furniture layout synthesis
Wamiq Reyaz Para, Paul Guerrero, Niloy Mitra, and Peter Wonka. Cofs: Controllable furniture layout synthesis. In ACM SIGGRAPH 2023 conference proceedings, pages 1–11, 2023
2023
-
[33]
Atiss: Autore- gressive transformers for indoor scene synthesis
Despoina Paschalidou, Amlan Kar, Maria Shugrina, Karsten Kreis, Andreas Geiger, and Sanja Fidler. Atiss: Autore- gressive transformers for indoor scene synthesis. Advances in neural information processing systems , 34:12013–12026,
-
[34]
Compositional 3d scene generation using locally conditioned diffusion
Ryan Po and Gordon Wetzstein. Compositional 3d scene generation using locally conditioned diffusion. In 2024 In- ternational Conference on 3D Vision (3DV), pages 651–663. IEEE, 2024. 1, 2
2024
-
[35]
Sg-vae: Scene grammar variational autoencoder to generate new in- door scenes
Pulak Purkait, Christopher Zach, and Ian Reid. Sg-vae: Scene grammar variational autoencoder to generate new in- door scenes. In European Conference on Computer Vision , pages 155–171. Springer, 2020. 1, 2
2020
-
[36]
Gpt4point: A unified framework for point-language understanding and generation
Zhangyang Qi, Ye Fang, Zeyi Sun, Xiaoyang Wu, Tong Wu, Jiaqi Wang, Dahua Lin, and Hengshuang Zhao. Gpt4point: A unified framework for point-language understanding and generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 26417– 26427, 2024. 2
2024
-
[37]
Habitat-Matterport 3D Dataset (HM3D): 1000 Large-scale 3D Environments for Embodied AI
Santhosh K Ramakrishnan, Aaron Gokaslan, Erik Wijmans, Oleksandr Maksymets, Alex Clegg, John Turner, Eric Un- dersander, Wojciech Galuba, Andrew Westbury, Angel X Chang, et al. Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai. arXiv preprint arXiv:2109.08238, 2021. 2
work page internal anchor Pith review arXiv 2021
-
[38]
Sentence-bert: Sentence embeddings using siamese bert-networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of the 2019 conference on empirical methods in natural lan- guage processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages 3982–3992, 2019. 4
2019
-
[39]
Fast and flex- ible indoor scene synthesis via deep convolutional genera- tive models
Daniel Ritchie, Kai Wang, and Yu-an Lin. Fast and flex- ible indoor scene synthesis via deep convolutional genera- tive models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 6182–6190,
-
[40]
Controlroom3d: Room gen- eration using semantic proxy rooms
Jonas Schult, Sam Tsai, Lukas Höllein, Bichen Wu, Jialiang Wang, Chih-Yao Ma, Kunpeng Li, Xiaofang Wang, Felix Wimbauer, Zijian He, et al. Controlroom3d: Room gen- eration using semantic proxy rooms. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6201–6210, 2024. 1, 2
2024
-
[41]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card. arXiv preprint arXiv:2601.03267, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Roomdreamer: Text-driven 3d indoor scene synthesis with coherent geome- try and texture
Liangchen Song, Liangliang Cao, Hongyu Xu, Kai Kang, Feng Tang, Junsong Yuan, and Yang Zhao. Roomdreamer: Text-driven 3d indoor scene synthesis with coherent geome- try and texture. arXiv preprint arXiv:2305.11337, 2023. 2
-
[43]
Layoutvlm: Differentiable optimization of 3d layout via vision-language models
Fan-Yun Sun, Weiyu Liu, Siyi Gu, Dylan Lim, Goutam Bhat, Federico Tombari, Manling Li, Nick Haber, and Jia- jun Wu. Layoutvlm: Differentiable optimization of 3d layout via vision-language models. In Proceedings of the Computer Vision and Pattern Recognition Conference , pages 29469– 29478, 2025. 1, 2, 6, 7
2025
-
[44]
Sceneeval: Evaluating semantic coherence in text-conditioned 3d indoor scene syn- thesis
Hou In Ivan Tam, Hou In Derek Pun, Austin T Wang, An- gel X Chang, and Manolis Savva. Sceneeval: Evaluating semantic coherence in text-conditioned 3d indoor scene syn- thesis. In Proceedings of the IEEE/CVF Winter Confer- ence on Applications of Computer Vision , pages 7355–7365,
-
[45]
Diffuscene: Denoising diffu- sion models for generative indoor scene synthesis
Jiapeng Tang, Yinyu Nie, Lev Markhasin, Angela Dai, Justus Thies, and Matthias Nießner. Diffuscene: Denoising diffu- sion models for generative indoor scene synthesis. In Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20507–20518, 2024. 2
2024
-
[46]
Planit: Planning and in- stantiating indoor scenes with relation graph and spatial prior networks
Kai Wang, Yu-An Lin, Ben Weissmann, Manolis Savva, An- gel X Chang, and Daniel Ritchie. Planit: Planning and in- stantiating indoor scenes with relation graph and spatial prior networks. ACM Transactions on Graphics (TOG) , 38(4):1– 15, 2019. 1, 2
2019
-
[47]
Chain-of-thought prompting elicits reasoning in large lan- guage models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large lan- guage models. Advances in neural information processing systems, 35:24824–24837, 2022. 2
2022
-
[48]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v. arXiv preprint arXiv:2310.11441, 2023. 2
work page internal anchor Pith review arXiv 2023
-
[49]
3d-grand: A million-scale dataset for 3d-llms with better grounding and less hallucination
Jianing Yang, Xuweiyi Chen, Nikhil Madaan, Madhavan Iyengar, Shengyi Qian, David F Fouhey, and Joyce Chai. 3d-grand: A million-scale dataset for 3d-llms with better grounding and less hallucination. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 29501–29512, 2025. 2
2025
-
[50]
Holodeck: Language guided gen- eration of 3d embodied ai environments
Yue Yang, Fan-Yun Sun, Luca Weihs, Eli VanderBilt, Al- varo Herrasti, Winson Han, Jiajun Wu, Nick Haber, Ranjay Krishna, Lingjie Liu, et al. Holodeck: Language guided gen- eration of 3d embodied ai environments. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16227–16237, 2024. 1, 2, 6, 3
2024
-
[51]
Tree of thoughts: Deliberate problem solving with large language models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. Advances in neural information processing systems, 36:11809–11822, 2023. 2
2023
-
[52]
Long-clip: Unlocking the long-text capability of clip
Beichen Zhang, Pan Zhang, Xiaoyi Dong, Yuhang Zang, and Jiaqi Wang. Long-clip: Unlocking the long-text capability of clip. In European conference on computer vision , pages 310–325. Springer, 2024. 6
2024
-
[53]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. Qwen3 embedding: Advancing text embedding and reranking through foundation models. arXiv preprint arXiv:2506.05176, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Dreamscene360: Uncon- strained text-to-3d scene generation with panoramic gaus- sian splatting
Shijie Zhou, Zhiwen Fan, Dejia Xu, Haoran Chang, Pradyumna Chari, Tejas Bharadwaj, Suya You, Zhangyang Wang, and Achuta Kadambi. Dreamscene360: Uncon- strained text-to-3d scene generation with panoramic gaus- sian splatting. In European Conference on Computer Vision, pages 324–342. Springer, 2024. 1, 2
2024
-
[55]
Gala3d: Towards text-to-3d complex scene genera- tion via layout-guided generative gaussian splatting
Xiaoyu Zhou, Xingjian Ran, Yajiao Xiong, Jinlin He, Zhi- wei Lin, Yongtao Wang, Deqing Sun, and Ming-Hsuan Yang. Gala3d: Towards text-to-3d complex scene genera- tion via layout-guided generative gaussian splatting. In In- ternational Conference on Machine Learning, pages 62108– 62118, 2024. 1, 2
2024
-
[56]
Scenegraphnet: Neural message passing for 3d indoor scene augmentation
Yang Zhou, Zachary While, and Evangelos Kalogerakis. Scenegraphnet: Neural message passing for 3d indoor scene augmentation. In Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision , pages 7384–7392,
-
[57]
Details of the Experiment Setup In the comparative experiment and ablation study, for all VLM and LLM usage, we use GPT-4o-2024-08-06 with the default parameters
1, 2 HOG-Layout: Hierarchical 3D Scene Generation, Optimization and Editing via Vision-Language Models Supplementary Material A. Details of the Experiment Setup In the comparative experiment and ablation study, for all VLM and LLM usage, we use GPT-4o-2024-08-06 with the default parameters. The experiment is conducted on a single computer with the followi...
2024
-
[58]
Area-based Method: A simpler approach where the force magnitude is proportional to the overlapping area of the bounding boxes, and the direction is de- termined by the vector connecting the centroids
-
[59]
left", "back
SAT-based Method: A more precise approach (em- ployed in our final implementation) using the Sep- arating Axis Theorem (SAT) . It calculates the Mini- mum Translation V ector (MTV)required to separate polygons, providing exact direction and magnitude for the collision force. Algorithm 1 Hierarchical Force-Directed Optimization Input: Objects S = {O1, . . ...
-
[60]
front"‘: The top edge/wall of the top-down view (where the Y-coordinate is highest). * ‘
ROOM & COORDINATE SYSTEM INFORMATION * Scene Type : An existing indoor environment that may already contain some objects. * Coordinate System : The scene uses a grid-based coordinate system (Blender-based). A top-down render with overlaid grid lines and labeled coordinates (x, y) is provided as part of the input. * The X-axis points to the right. * The Y-...
-
[61]
Use it to understand spatial layout, available space, and wall positions
YOUR INPUT * Layout description / design goal: ‘{layout_description}‘ * Existing objects (already in the scene): ‘‘‘json {existing_json} ‘‘‘ * Objects to place (you must provide placements for these): ‘‘‘json {new_json} ‘‘‘ * Visual Input : * A top-down render of the current scene with grid lines and labeled coordinates is provided alongside this prompt. ...
-
[62]
placements
OUTPUT FORMAT & FIELD DEFINITIONS Your response must and only be a strict JSON code block with the following structure. Do not add any Markdown markers, explanations, or other text. ‘‘‘json { "placements": [ { "objectId": "id_of_the_object_to_place", "parentId": " id_of_the_supporting_object_or_floor", "position": [x, y], "rotation": [0, 0, yaw_in_degrees...
-
[63]
CORE LAYOUT LOGIC & RULES
-
[64]
parentId
PARENTID IS ONLY FOR PHYSICAL ATTACHMENT: A functional relationship (like a chair and a desk) does not imply a ‘parentId‘ relationship. A chair should be on the floor (‘"parentId": "floor"‘) and then use ‘adjacent ‘ and ‘point_towards‘ to express its relationship with the desk
-
[65]
LARGE FURNITURE MUST BE ON THE FLOOR : The ‘ parentId‘ for large items like chairs, sofas, beds, tables, and cabinets must be ‘"floor"‘
-
[66]
AVOID COLLISIONS : Newly placed objects must not overlap with any existing objects (unless it is explicitly placed on one of their surfaces)
-
[67]
FUNCTIONAL GROUPING : Group functionally related objects together based on ‘layout_description‘ and common sense (e.g., a chair facing a desk , a nightstand next to a bed)
-
[68]
SPATIAL REASONABLENESS : Ensure the layout leaves reasonable pathways and adheres to ergonomic principles
-
[69]
ceiling"‘ for hanging fixtures or ‘parentId =
HANGING / WALL-MOUNTED ITEMS : You may use ‘ parentId = "ceiling"‘ for hanging fixtures or ‘parentId = "wall"‘ for wall-mounted and wall- hung items. When ‘parentId‘ is ‘"wall"‘, you must set ‘against_wall‘ to one of ‘"front"‘, ‘"back"‘, ‘"left"‘, or ‘"right"‘ (never ‘"none "‘), because the system needs to know which wall the object attaches to. Doors are...
-
[70]
Never create loops where objects align with /or point toward each other simultaneously
ORIENTATION CONSTRAINTS : For each object, choose at most one of ‘point_towards‘ or ‘align_with ‘. Never create loops where objects align with /or point toward each other simultaneously. Wall-alignment hints (‘against_wall‘) take precedence over both
-
[71]
target‘ must refer to an existing object or an object that appears in the ‘placements‘ list
REFERENCE CONSISTENCY : Every identifier used in ‘point_towards‘, ‘align_with‘, or ‘adjacent. target‘ must refer to an existing object or an object that appears in the ‘placements‘ list. Do not reference objects that are absent from the output. ---
-
[72]
SUGGESTED THINKING PROCESS
-
[73]
Analyze Requirements : Carefully read the ‘ layout_description‘ to understand the overall design style and functional needs
-
[74]
Place Large Objects : First, determine the positions of large, foundational objects (like beds, desks, sofas) as they form the skeleton of the scene
-
[75]
Place Associated Objects : Next, place smaller and medium-sized objects that are functionally related to the large ones (e.g., placing a chair by a desk, a lamp on a nightstand)
-
[76]
Fill with Decorative Objects : Finally, place decorative items like plants and rugs based on the remaining space and overall aesthetics
-
[77]
Objects to place
Review and Verify : Re-examine the entire layout to ensure all rules are followed, there are no collisions, and the scene is harmonious and practical. Now, based on all the information above, please generate the final JSON output for all " Objects to place". C. Prompt for the Evaluation of SP Score In the experiment, we used GPT-5 to evaluate the semantic...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.