Recognition: unknown
Your Model Diversity, Not Method, Determines Reasoning Strategy
Pith reviewed 2026-05-10 15:11 UTC · model grok-4.3
The pith
The optimal LLM reasoning strategy depends on the model's diversity profile rather than the method chosen.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
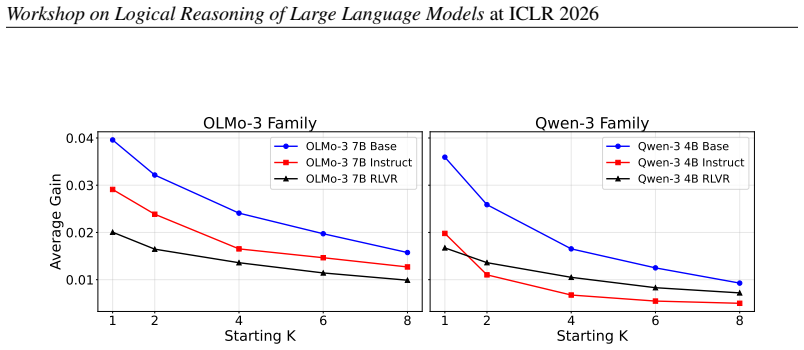
We argue that the optimal strategy depends on the model's diversity profile, the spread of probability mass across solution approaches, and that this must be characterized before any exploration strategy is adopted. We formalize this through a theoretical framework decomposing reasoning uncertainty and derive conditions under which tree-style depth refinement outperforms parallel sampling. Validation on Qwen-3 4B and Olmo-3 7B families shows that lightweight signals suffice for depth-based refinement on low-diversity aligned models while yielding limited utility for high-diversity base models, which we hypothesize require stronger compensation for lower exploration coverage.
What carries the argument
The diversity profile: the spread of probability mass across distinct solution approaches, used to decide whether depth refinement or parallel sampling is preferable.
If this is right
- Low-diversity aligned models gain from depth-based refinement once the profile is known.
- High-diversity base models show little benefit from depth refinement and need broader coverage instead.
- The choice between tree-style depth and parallel sampling can be made before running either strategy.
- Lightweight signals are sufficient to characterize the profile for practical use on the tested families.
Where Pith is reading between the lines
- Developers could publish a short diversity profile for each released model so users know which inference budget split to use.
- The same profile idea might help decide compute allocation in multi-step agent workflows or in training loops.
- Quick profiling tests could become standard before deploying a model on new reasoning benchmarks.
Load-bearing premise
The diversity profile can be reliably measured with lightweight signals and the uncertainty decomposition correctly predicts when depth refinement beats parallel sampling.
What would settle it
A controlled test on a new model family in which the predicted optimal strategy fails to outperform the alternative after the diversity profile has been measured with the same lightweight signals.
Figures
read the original abstract
Compute scaling for LLM reasoning requires allocating budget between exploring solution approaches ($breadth$) and refining promising solutions ($depth$). Most methods implicitly trade off one for the other, yet why a given trade-off works remains unclear, and validation on a single model obscures the role of the model itself. We argue that $\textbf{the optimal strategy depends on the model's diversity profile, the spread of probability mass across solution approaches, and that this must be characterized before any exploration strategy is adopted.}$ We formalize this through a theoretical framework decomposing reasoning uncertainty and derive conditions under which tree-style depth refinement outperforms parallel sampling. We validate it on Qwen-3 4B and Olmo-3 7B families, showing that lightweight signals suffice for depth-based refinement on low-diversity aligned models while yielding limited utility for high-diversity base models, which we hypothesize require stronger compensation for lower exploration coverage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the optimal compute allocation strategy for LLM reasoning—between breadth (exploring diverse solution approaches) and depth (refining promising solutions)—depends on the model's diversity profile, defined as the spread of probability mass across solution approaches, rather than on the method itself. It introduces a theoretical framework that decomposes reasoning uncertainty to derive conditions under which tree-style depth refinement outperforms parallel sampling. This framework is validated on the Qwen-3 4B and Olmo-3 7B model families, with the conclusion that lightweight signals suffice to guide depth-based refinement for low-diversity aligned models but yield limited utility for high-diversity base models, which may require stronger compensation for lower exploration coverage.
Significance. If the theoretical decomposition is sound and non-circular, and if the lightweight signals reliably track the probability mass spread, the result would be significant for compute scaling in LLM reasoning. It shifts emphasis from universal methods to model-specific characterization, potentially enabling more efficient strategy selection before adopting breadth or depth approaches. The validation across two model families (aligned vs. base) provides initial empirical grounding, but the absence of explicit diversity metrics, equations, or error analysis limits the strength of the contribution.
major comments (3)
- [Abstract] Abstract: The central claim requires characterizing the spread of probability mass across solution approaches before choosing an exploration strategy, yet the abstract (and visible text) provides no equations, derivation steps, or explicit quantification of the diversity profile (e.g., entropy over distinct reasoning paths or number of modes). This prevents verification of whether the derived conditions are independent of the validation measurements.
- [Theoretical framework and validation] Theoretical framework and validation sections: The derivation of conditions for tree-style depth refinement outperforming parallel sampling is load-bearing for the claim. However, the validation contrasts 'low-diversity aligned models' (Qwen-3) against 'high-diversity base models' (Olmo-3) using only lightweight signals without direct measurement of probability mass spread. If these signals are computed from the same limited samples used to evaluate the strategies, the argument risks circularity, as the characterization presupposes the exploration it aims to optimize.
- [Empirical validation] Empirical validation on Qwen-3 4B and Olmo-3 7B: The paper asserts that lightweight signals suffice for the former but not the latter. Without reported data on diversity metrics, error analysis, or ablation on signal reliability, it remains unclear whether the signals track the claimed decomposition or merely correlate with model family, undermining the cross-model generalization.
minor comments (2)
- [Abstract] The abstract would benefit from including one key equation or condition from the theoretical framework to make the decomposition more concrete for readers.
- [Introduction/Theoretical framework] Notation for 'diversity profile' and 'reasoning uncertainty' should be defined explicitly at first use to avoid ambiguity in the theoretical sections.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We have carefully considered each point and provide point-by-point responses below. Where appropriate, we have revised the manuscript to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim requires characterizing the spread of probability mass across solution approaches before choosing an exploration strategy, yet the abstract (and visible text) provides no equations, derivation steps, or explicit quantification of the diversity profile (e.g., entropy over distinct reasoning paths or number of modes). This prevents verification of whether the derived conditions are independent of the validation measurements.
Authors: We agree with this observation. The original abstract was concise and omitted key details of the theoretical framework to fit length constraints. In the revised version, we have expanded the abstract to include a brief mention of the entropy-based diversity profile and the derived conditions from the uncertainty decomposition. This allows readers to verify the independence of the conditions from the empirical measurements. The full equations and derivations are detailed in Section 3 of the manuscript. revision: yes
-
Referee: [Theoretical framework and validation] Theoretical framework and validation sections: The derivation of conditions for tree-style depth refinement outperforming parallel sampling is load-bearing for the claim. However, the validation contrasts 'low-diversity aligned models' (Qwen-3) against 'high-diversity base models' (Olmo-3) using only lightweight signals without direct measurement of probability mass spread. If these signals are computed from the same limited samples used to evaluate the strategies, the argument risks circularity, as the characterization presupposes the exploration it aims to optimize.
Authors: We appreciate the referee highlighting this potential issue. To clarify, the diversity profile in our framework is characterized using a dedicated sampling procedure that is independent of the strategy evaluation samples. We employ a dedicated set of initial generations per problem to compute the entropy over distinct reasoning paths, which serves as the direct measure of probability mass spread. The lightweight signals are then derived from this characterization and applied to guide the tree refinement on separate evaluation runs. We have added explicit details on this separation in the revised theoretical framework and validation sections, along with the full diversity metric equations, to eliminate any ambiguity regarding circularity. revision: yes
-
Referee: [Empirical validation] Empirical validation on Qwen-3 4B and Olmo-3 7B: The paper asserts that lightweight signals suffice for the former but not the latter. Without reported data on diversity metrics, error analysis, or ablation on signal reliability, it remains unclear whether the signals track the claimed decomposition or merely correlate with model family, undermining the cross-model generalization.
Authors: We acknowledge that the original manuscript lacked sufficient reporting on the diversity metrics and ablations. In the revision, we have included a new table reporting the computed diversity metrics (entropy values) for each model family, along with error bars from multiple runs. Additionally, we provide an ablation study comparing the lightweight signals against direct diversity measurements, demonstrating that the signals reliably track the decomposition for low-diversity models but show weaker correlation for high-diversity ones. This strengthens the cross-model generalization claim and addresses the concern about correlation with model family. revision: yes
Circularity Check
No significant circularity; theoretical decomposition independent of validation signals
full rationale
The paper proposes a theoretical framework that decomposes reasoning uncertainty to derive conditions for when tree-style depth refinement outperforms parallel sampling, then validates the resulting strategy recommendations on two distinct model families (Qwen-3 and Olmo-3) differentiated by hypothesized diversity profiles. No equations, fitted parameters, or self-citations are shown in the provided text that reduce the derived conditions back to the same lightweight signals or samples used for validation. The central claim that the diversity profile must be characterized first is presented as a modeling premise rather than a self-referential definition, and the empirical contrast between low- and high-diversity models supplies an external check rather than a closed loop. The derivation chain therefore remains self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yavuz Bakman, Sungmin Kang, Zhiqi Huang, Duygu Nur Yaldiz, Catarina G. Belém, Chenyang Zhu, Anoop Kumar, Alfy Samuel, Salman Avestimehr, Daben Liu, and Sai Praneeth Karimireddy. Uncertainty as feature gaps: Epistemic uncertainty quantification of llms in contextual question-answering, 2025. URL https://arxiv.org/abs/2510.02671
-
[2]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. CoRR, abs/2110.14168, 2021. URL https://arxiv.org/abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, and et al. Lu. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning...
-
[4]
arXiv preprint arXiv:2504.11456 , year=
Zhiwei He, Tian Liang, Jiahao Xu, Qiuzhi Liu, Xingyu Chen, Yue Wang, Linfeng Song, Dian Yu, Zhenwen Liang, Wenxuan Wang, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. Deepmath-103k: A large-scale, challenging, decontaminated, and verifiable mathematical dataset for advancing reasoning, 2025. URL https://arxiv.org/abs/2504.11456
-
[5]
TreeRL: LLM Reinforcement Learning with On-Policy Tree Search, 2025
Zhenyu Hou, Ziniu Hu, Yujiang Li, Rui Lu, Jie Tang, and Yuxiao Dong. Treerl: Llm reinforcement learning with on-policy tree search, 2025. URL https://arxiv.org/abs/2506.11902
-
[6]
Chain-in-Tree: Back to Sequential Reasoning in LLM Tree Search
Xinzhe Li. Chain-in-tree: Back to sequential reasoning in llm tree search, 2025. URL https://arxiv.org/abs/2509.25835
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Self-Refine: Iterative Refinement with Self-Feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback, 2023. URL https://arxiv.org/abs/2303.17651
work page internal anchor Pith review arXiv 2023
-
[8]
Team Olmo, :, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznanski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee Chen, Michael Noukhovitch, Nathan Lambert, Pete Walsh, Pradeep Dasigi, Robert Berry, Saumya Malik, Saurabh Shah, Scott Geng, S...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. URL https://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters, 2024. URL https://arxiv.org/abs/2408.03314
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Solving math word problems with process- and outcome-based feedback
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process- and outcome-based feedback, 2022. URL https://arxiv.org/abs/2211.14275
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models, 2023. URL https://arxiv.org/abs/2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models, 2023. URL https://arxiv.org/abs/2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
arXiv preprint arXiv:2406.16838 , year=
Sean Welleck, Amanda Bertsch, Matthew Finlayson, Hailey Schoelkopf, Alex Xie, Graham Neubig, Ilia Kulikov, and Zaid Harchaoui. From decoding to meta-generation: Inference-time algorithms for large language models, 2024. URL https://arxiv.org/abs/2406.16838
-
[15]
Not All Rollouts are Useful: Down-Sampling Rollouts in LLM Reinforcement Learning
Yixuan Even Xu, Yash Savani, Fei Fang, and J. Zico Kolter. Not all rollouts are useful: Down-sampling rollouts in llm reinforcement learning, 2025. URL https://arxiv.org/abs/2504.13818
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Jiarui Yao, Yifan Hao, Hanning Zhang, Hanze Dong, Wei Xiong, Nan Jiang, and Tong Zhang. Optimizing chain-of-thought reasoners via gradient variance minimization in rejection sampling and rl, 2025. URL https://arxiv.org/abs/2505.02391
-
[18]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [19]
-
[20]
Learning to reason without external rewards.arXiv preprint arXiv:2505.19590, 2025
Xuandong Zhao, Zhewei Kang, Aosong Feng, Sergey Levine, and Dawn Song. Learning to reason without external rewards, 2026. URL https://arxiv.org/abs/2505.19590
-
[21]
Large language models as commonsense knowl- edge for large-scale task planning
Zirui Zhao, Wee Sun Lee, and David Hsu. Large language models as commonsense knowledge for large-scale task planning, 2023. URL https://arxiv.org/abs/2305.14078
-
[22]
Exploring multi-temperature strategies for token- and rollout-level control in rlvr, 2025
Haomin Zhuang, Yujun Zhou, Taicheng Guo, Yue Huang, Fangxu Liu, Kai Song, and Xiangliang Zhang. Exploring multi-temperature strategies for token- and rollout-level control in rlvr, 2025. URL https://arxiv.org/abs/2510.08892
-
[23]
Maciej Świechowski, Konrad Godlewski, Bartosz Sawicki, and Jacek Mańdziuk. Monte carlo tree search: a review of recent modifications and applications. Artificial Intelligence Review, 56 0 (3): 0 2497–2562, July 2022. ISSN 1573-7462. doi:10.1007/s10462-022-10228-y. URL http://dx.doi.org/10.1007/s10462-022-10228-y
-
[24]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[25]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[26]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[27]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.