Recognition: unknown
Taking a Pulse on How Generative AI is Reshaping the Software Engineering Research Landscape
Pith reviewed 2026-05-10 15:09 UTC · model grok-4.3
The pith
Survey of 457 SE researchers shows generative AI use is widespread but concentrated in writing and early stages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GenAI use is widespread among the surveyed researchers, with many reporting pressure to adopt and align their work with it. Usage concentrates in writing and early-stage activities while methodological and analytical tasks remain largely human-driven. Productivity gains are widely perceived, yet concerns about trust, correctness, and regulatory uncertainty persist; researchers emphasize human oversight to address risks such as inaccuracies and bias and call for clearer governance including guidance on responsible use and peer review.
What carries the argument
Large-scale mixed-methods survey of 457 authors from top SE venues (2023-2025) that produces taxonomies of GenAI use cases across research activities, opportunities, risks, mitigation strategies, and governance needs.
If this is right
- Writing and ideation steps in SE research can be sped up by GenAI while core methodological integrity stays protected by human control.
- Productivity improvements are expected mainly in early phases rather than in analysis or validation.
- Risks of inaccuracy and bias require explicit human verification steps in every project that uses GenAI.
- Peer-review processes need updated guidance on how to evaluate GenAI-assisted submissions.
- Clear institutional and venue-level policies on responsible GenAI use would reduce uncertainty for researchers.
Where Pith is reading between the lines
- The same usage pattern (high early-stage adoption, low analytical adoption) may appear in other empirical research fields if surveyed similarly.
- The taxonomies of risks and mitigation strategies could serve as a starting template for governance discussions outside software engineering.
- Repeated surveys using the same instrument would allow tracking whether analytical-task usage increases as tools improve.
- Journal and conference policies that ignore these patterns risk creating inconsistent enforcement of disclosure and verification rules.
Load-bearing premise
The 457 self-selected respondents from authors in top software engineering venues between 2023 and 2025 accurately represent the practices and views of the broader SE research community.
What would settle it
A follow-up survey of a larger or differently sampled group of software engineering researchers that finds markedly lower adoption rates, different usage distributions across research stages, or weaker calls for governance.
Figures



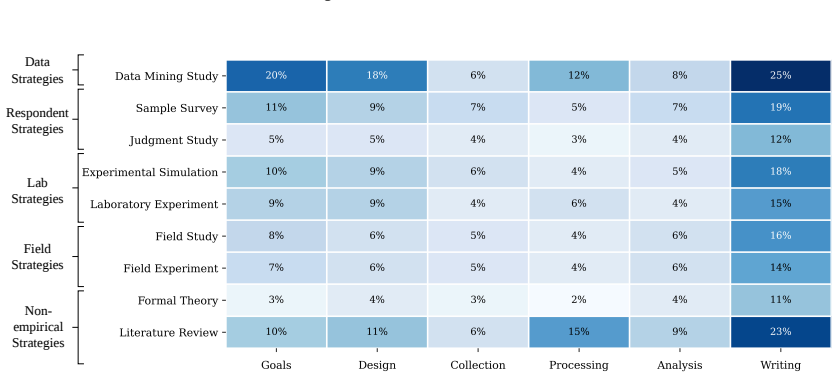
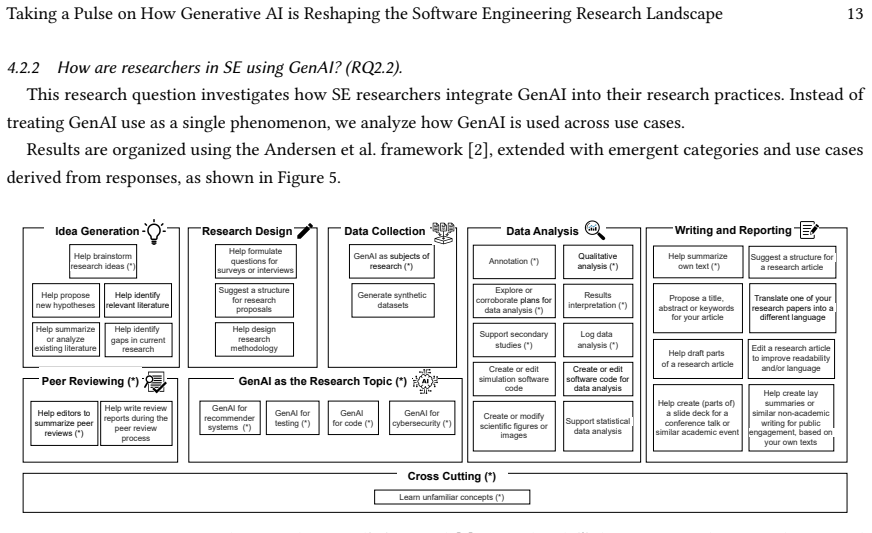





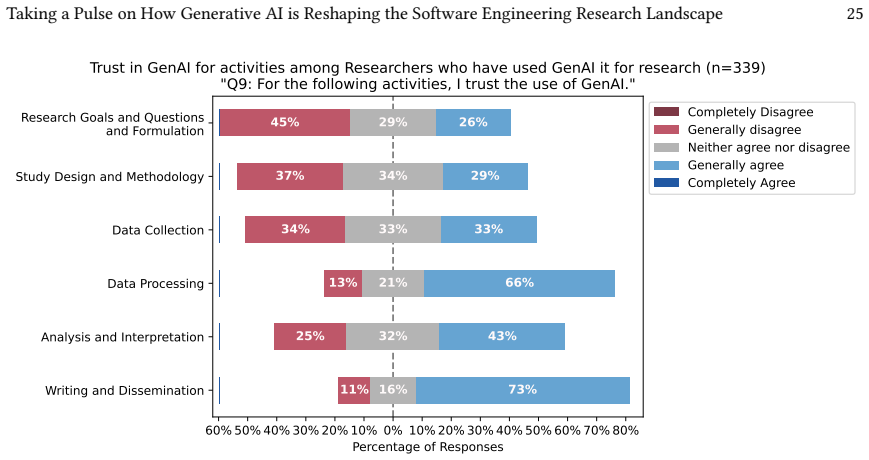


read the original abstract
Context: Software engineering (SE) researchers increasingly study Generative AI (GenAI) while also incorporating it into their own research practices. Despite rapid adoption, there is limited empirical evidence on how GenAI is used in SE research and its implications for research practices and governance. Aims: We conduct a large-scale survey of 457 SE researchers publishing in top venues between 2023 and 2025. Method: Using quantitative and qualitative analyses, we examine who uses GenAI and why, where it is used across research activities, and how researchers perceive its benefits, opportunities, challenges, risks, and governance. Results: GenAI use is widespread, with many researchers reporting pressure to adopt and align their work with it. Usage is concentrated in writing and early-stage activities, while methodological and analytical tasks remain largely human-driven. Although productivity gains are widely perceived, concerns about trust, correctness, and regulatory uncertainty persist. Researchers highlight risks such as inaccuracies and bias, emphasize mitigation through human oversight and verification, and call for clearer governance, including guidance on responsible use and peer review. Conclusion: We provide a fine-grained, SE-specific characterization of GenAI use across research activities, along with taxonomies of GenAI use cases for research and peer review, opportunities, risks, mitigation strategies, and governance needs. These findings establish an empirical baseline for the responsible integration of GenAI into academic practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports results from a survey of 457 SE researchers who published in top venues during 2023-2025. Using mixed quantitative and qualitative analysis, it describes patterns of GenAI adoption, concentration of use in writing and early-stage research activities, perceived productivity benefits alongside concerns about trust and correctness, and calls for improved governance and peer-review guidance. The work develops taxonomies of use cases, risks, mitigation strategies, and governance needs to establish an empirical baseline for responsible GenAI integration in SE research.
Significance. If the descriptive findings hold within the sampled population, the paper supplies a timely, SE-specific empirical baseline on GenAI use that can inform research practices, conference policies, and future studies. Strengths include the large sample size, combination of quantitative and qualitative data, and production of reusable taxonomies for use cases and governance; these elements add concrete value beyond purely anecdotal accounts of AI adoption.
major comments (2)
- [Method] Method section: the sampling frame is restricted to authors publishing in top venues 2023-2025; while this scope is explicitly stated, the paper should include a dedicated discussion of selection effects and any weighting or sensitivity checks performed, because the central claims of widespread adoption and perceived pressure rest on the assumption that responses from this group accurately characterize active SE research practices.
- [Results] Results section: limited information is provided on response rate, non-response bias analysis, or validation of self-reported usage; these details are load-bearing for the quantitative claims (e.g., prevalence of GenAI use and concentration in writing tasks) and should be expanded with concrete numbers and procedures.
minor comments (2)
- [Abstract] Abstract: the summary of results would be strengthened by briefly noting the achieved response rate or any bias-mitigation steps, consistent with standard reporting for survey studies.
- [Discussion] The taxonomies of GenAI use cases and governance needs are valuable but would benefit from a summary table to improve readability and allow easier reference by readers.
Simulated Author's Rebuttal
We thank the referee for their positive assessment and recommendation for minor revision. Their comments on methodological transparency are well-taken, and we address each point below with plans for revision.
read point-by-point responses
-
Referee: [Method] Method section: the sampling frame is restricted to authors publishing in top venues 2023-2025; while this scope is explicitly stated, the paper should include a dedicated discussion of selection effects and any weighting or sensitivity checks performed, because the central claims of widespread adoption and perceived pressure rest on the assumption that responses from this group accurately characterize active SE research practices.
Authors: We agree that an explicit discussion of selection effects would improve the paper. Although the sampling frame is described in the Method section, the revised manuscript will add a dedicated paragraph in the Limitations section. This paragraph will note that authors publishing in top venues during 2023-2025 may differ systematically from the broader SE research community (e.g., greater institutional resources or earlier exposure to emerging tools), potentially inflating reported adoption rates and perceived pressure. No weighting or sensitivity checks were performed, as the survey targeted a defined population of recent top-venue authors rather than a probability sample of all SE researchers; we lacked auxiliary population-level data for such adjustments. We will also restate that all claims are scoped to this population. revision: yes
-
Referee: [Results] Results section: limited information is provided on response rate, non-response bias analysis, or validation of self-reported usage; these details are load-bearing for the quantitative claims (e.g., prevalence of GenAI use and concentration in writing tasks) and should be expanded with concrete numbers and procedures.
Authors: We acknowledge that these details should be expanded. The revised Results and Method sections will report the total number of unique authors identified from the publication records and the resulting response rate. A formal non-response bias analysis was not conducted because the survey was anonymous and no demographic data on non-respondents were available; we will add this explanation along with any available checks (such as early-versus-late responder comparisons on key variables). For self-reported usage, we will describe the attention-check items and internal consistency verifications included in the instrument. Objective validation was not feasible under the anonymous design and ethical constraints. revision: yes
Circularity Check
No circularity: claims rest directly on survey data analysis
full rationale
The paper is a descriptive survey study with no derivations, equations, fitted parameters, or predictions. All results (usage patterns, perceptions, taxonomies) are obtained by direct quantitative/qualitative analysis of the 457 responses. No self-citation forms a load-bearing premise for the central claims, and no step reduces by construction to prior inputs or definitions. Sampling and self-report biases are validity issues external to circularity analysis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-reported survey responses accurately reflect researchers' actual GenAI usage, perceptions, and behaviors.
Reference graph
Works this paper leans on
-
[1]
Toufique Ahmed, Premkumar Devanbu, Christoph Treude, and Michael Pradel. 2025. Can LLMs replace manual annotation of software engineering artifacts?. In2025 IEEE/ACM 22nd International Conference on Mining Software Repositories (MSR). IEEE, 526–538
2025
-
[2]
Jens Peter Andersen, Lise Degn, Rachel Fishberg, Ebbe K Graversen, Serge PJM Horbach, Evanthia Kalpazidou Schmidt, Jesper W Schneider, and Mads P Sørensen. 2025. Generative Artificial Intelligence (GenAI) in the research process–A survey of researchers’ practices and perceptions. Technology in Society81 (2025), 102813
2025
-
[3]
Sebastian Baltes, Florian Angermeir, Chetan Arora, Marvin Muñoz Barón, Chunyang Chen, Lukas Böhme, Fabio Calefato, Neil Ernst, Davide Falessi, Brian Fitzgerald, et al. 2025. Guidelines for empirical studies in software engineering involving large language models.arXiv preprint arXiv:2508.15503(2025)
work page internal anchor Pith review arXiv 2025
-
[4]
Sebastian Baltes and Paul Ralph. 2022. Sampling in software engineering research: a critical review and guidelines.Empir. Softw. Eng.27, 4 (2022), 94. https://doi.org/10.1007/S10664-021-10072-8
-
[5]
Muneera Bano, Rashina Hoda, Didar Zowghi, and Christoph Treude. 2024. Large language models for qualitative research in software engineering: exploring opportunities and challenges.Automated Software Engineering31, 1 (2024), 8
2024
-
[6]
Cauã Ferreira Barros, Bruna Borges Azevedo, Valdemar Vicente Graciano Neto, Mohamad Kassab, Marcos Kalinowski, Hugo Alexandre D Do Nasci- mento, and Michelle CGSP Bandeira. 2025. Large language model for qualitative research: A systematic mapping study. In2025 IEEE/ACM International Workshop on Methodological Issues with Empirical Studies in Software Engi...
2025
-
[7]
Virginia Braun and Victoria Clarke. 2006. Using thematic analysis in psychology.Qualitative research in psychology3, 2 (2006), 77–101
2006
-
[8]
John L Campbell, Charles Quincy, Jordan Osserman, and Ove K Pedersen. 2013. Coding in-depth semistructured interviews: Problems of unitization and intercoder reliability and agreement.Sociological methods & research42, 3 (2013), 294–320
2013
-
[9]
Rudrajit Choudhuri, Bianca Trinkenreich, Rahul Pandita, Eirini Kalliamvakou, Igor Steinmacher, Marco Gerosa, Christopher Sanchez, and Anita Sarma. 2025. What Guides Our Choices? Modeling Developers’ Trust and Behavioral Intentions Towards GenAI. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE Computer Society, 624–624
2025
-
[10]
Ronnie de Souza Santos, Italo Santos, Maria Teresa Baldassarre, Cleyton Magalhaes, and Mairieli Wessel. 2025. An Investigation on How AI-Generated Responses Affect Software Engineering Surveys.arXiv e-prints(2025), arXiv–2512
2025
-
[11]
2025.State of AI-Assisted Software Development
DORA Team. 2025.State of AI-Assisted Software Development. Technical Report. Google Cloud. https://dora.dev/research/2025/dora-report/ Accessed: April 2026
2025
-
[12]
Katia Romero Felizardo, Anderson Deizepe, Daniel Coutinho, Genildo Gomes, Maria Meireles, Marco Gerosa, and Igor Steinmacher. 2025. On the difficulties of conducting and replicating systematic literature reviews studies using LLMs in software engineering. In2025 IEEE/ACM International Workshop on Methodological Issues with Empirical Studies in Software En...
2025
-
[13]
Katia Romero Felizardo, Márcia Sampaio Lima, Anderson Deizepe, Tayana Uchôa Conte, and Igor Steinmacher. 2024. ChatGPT application in Systematic Literature Reviews in Software Engineering: an evaluation of its accuracy to support the selection activity. InEmpirical Software Engineering and Measurement. 25–36
2024
-
[14]
D Garrison, Martha Cleveland-Innes, Marguerite Koole, and James Kappelman. 2006. Revisiting methodological issues in transcript analysis: Negotiated coding and reliability.The Internet and Higher Education9, 1 (2006), 1–8
2006
-
[15]
Marco Gerosa, Bianca Trinkenreich, Igor Steinmacher, and Anita Sarma. 2024. Can AI serve as a substitute for human subjects in software engineering research?Automated Software Engineering31, 1 (2024), 13
2024
-
[16]
Yolanda Gil, Mark Greaves, James Hendler, and Haym Hirsh. 2014. Amplify scientific discovery with artificial intelligence.Science346, 6206 (2014), 171–172
2014
-
[17]
GitHub. 2025. Octoverse 2025: The State of Open Source. https://github.blog/news-insights/octoverse/octoverse-a-new-developer-joins-github- every-second-as-ai-leads-typescript-to-1/ Accessed: April 2026
2025
-
[18]
Jacqueline Harding, William D’Alessandro, NG Laskowski, and Robert Long. 2024. AI language models cannot replace human research participants. Ai & Society39, 5 (2024), 2603–2605
2024
-
[19]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large Language Models for Software Engineering: A Systematic Literature Review.ACM Transactions on Software Engineering and Methodology(2024). https: //doi.org/10.1145/3695988 Manuscript submitted to ACM 36 Trinkenreich et al
-
[20]
Aleksi Huotala, Miikka Kuutila, Paul Ralph, and Mika Mäntylä. 2024. The promise and challenges of using LLMs to accelerate the screening process of systematic reviews. InProceedings of the 28th International Conference on Evaluation and Assessment in Software Engineering. 262–271
2024
- [21]
-
[22]
Qusai Khraisha, Sophie Put, Johanna Kappenberg, Azza Warraitch, and Kristin Hadfield. 2024. Can large language models replace humans in systematic reviews? Evaluating GPT-4’s efficacy in screening and extracting data from peer-reviewed and grey literature in multiple languages. Research Synthesis Methods(2024)
2024
-
[23]
Dmitry Kobak, Rita González-Márquez, Emőke-Ágnes Horvát, and Jan Lause. 2025. Delving into LLM-assisted writing in biomedical publications through excess vocabulary.Science Advances11, 27 (2025), eadt3813. https://doi.org/10.1126/sciadv.adt3813
-
[24]
Matheus De Morais Leça, Lucas Valença, Reydne Santos, and Ronnie De Souza Santos. 2025. Applications and implications of large language models in qualitative analysis: A new frontier for empirical software engineering. In2025 IEEE/ACM International Workshop on Methodological Issues with Empirical Studies in Software Engineering (WSESE). IEEE, 36–43
2025
-
[25]
Jenny T Liang, Carmen Badea, Christian Bird, Robert DeLine, Denae Ford, Nicole Forsgren, and Thomas Zimmermann. 2024. Can gpt-4 replicate empirical software engineering research?Proc. of the ACM on Software Engineering1, FSE (2024), 1330–1353
2024
-
[26]
Weixin Liang, Yuhui Zhang, Hancheng Cao, Binglu Wang, Daisy Yi Ding, Xinyu Yang, Kailas Vodrahalli, Siyu He, Daniel Scott Smith, Yian Yin, Daniel A. McFarland, and James Zou. 2024. Can Large Language Models Provide Useful Feedback on Research Papers? A Large-Scale Empirical Analysis.NEJM AI1, 8 (2024). https://doi.org/10.1056/AIoa2400196
-
[27]
Ziming Luo, Zonglin Yang, Zexin Xu, Wei Yang, and Xinya Du. 2025. LLM4SR: A Survey on Large Language Models for Scientific Research.CoRR abs/2501.04306 (2025). https://doi.org/10.48550/arXiv.2501.04306
-
[28]
Marshall McLuhan. 1977. Laws of the Media.ETC: A Review of General Semantics(1977), 173–179
1977
-
[29]
2015.Qualitative research: A guide to design and implementation
Sharan B Merriam and Elizabeth J Tisdell. 2015.Qualitative research: A guide to design and implementation. John Wiley & Sons
2015
-
[30]
Studying the Usage of Text-To-Text Transfer Transformer to Support Code-Related Tasks , booktitle =
Courtney Miller, Paige Rodeghero, Margaret-Anne Storey, Denae Ford, and Thomas Zimmermann. 2021. "How Was Your Weekend?" Software Development Teams Working From Home During COVID-19. In2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE). 624–636. https://doi.org/10.1109/ICSE43902.2021.00064
-
[31]
Tanisha Mishra, Edward Sutanto, Rini Rossanti, Nayana Pant, Anum Ashraf, Akshay Raut, Germaine Uwabareze, Ajayi Oluwatomiwa, and Bushra Zeeshan. 2024. Use of large language models as artificial intelligence tools in academic research and publishing among global clinical researchers. Scientific Reports14, 1 (2024), 31672
2024
-
[32]
Cristina Martinez Montes, Robert Feldt, Cristina Miguel Martos, Sofia Ouhbi, Shweta Premanandan, and Daniel Graziotin. 2025. Large Language Models in Thematic Analysis: Prompt Engineering, Evaluation, and Guidelines for Qualitative Software Engineering Research.arXiv preprint arXiv:2510.18456(2025)
- [33]
-
[34]
Zeeshan Rasheed, Muhammad Waseem, Aakash Ahmad, Kai-Kristian Kemell, Xiaofeng Wang, Anh Nguyen-Duc, and Pekka Abrahamsson. 2024. Can Large Language Models Serve as Data Analysts? A Multi-Agent Assisted Approach for Qualitative Data Analysis.CoRRabs/2402.01386 (2024). https://doi.org/10.48550/ARXIV.2402.01386
-
[35]
Daniel Russo, Sebastian Baltes, Niels van Berkel, Paris Avgeriou, Fabio Calefato, Beatriz Cabrero-Daniel, Gemma Catolino, Jürgen Cito, Neil Ernst, Thomas Fritz, et al. 2024. Generative ai in software engineering must be human-centered: The copenhagen manifesto.J. Syst. Softw.216 (2024), 112115
2024
-
[36]
Mary Shaw. 2002. What makes good research in software engineering?International Journal on Software Tools for Technology Transfer4, 1 (2002), 1–7
2002
-
[37]
Chenglei Si, Diyi Yang, and Tatsunori Hashimoto. 2025. Can LLMs Generate Novel Research Ideas? A Large-Scale Human Study with 100+ NLP Researchers. InProceedings of the 13th International Conference on Learning Representations (ICLR)
2025
-
[38]
Stack Overflow. 2025. 2025 Developer Survey. https://survey.stackoverflow.co/2025/ Accessed: April 2026
2025
-
[39]
Igor Steinmacher, Jacob Mcauley Penney, Katia Romero Felizardo, Alessandro F Garcia, and Marco A Gerosa. 2024. Can ChatGPT emulate humans in software engineering surveys?. InProc. of the 18th ACM/IEEE Int’l. Symposium on Empirical Software Engineering and Measurement. 414–419
2024
-
[40]
Margaret-Anne Storey, Neil A Ernst, Courtney Williams, and Eirini Kalliamvakou. 2020. The who, what, how of software engineering research: a socio-technical framework.Empirical Software Engineering25, 5 (2020), 4097–4129
2020
-
[41]
Eugene Syriani, Istvan David, and Gauransh Kumar. 2024. Screening articles for systematic reviews with ChatGPT.Journal of Computer Languages 80 (2024), 101287. https://doi.org/10.1016/j.cola.2024.101287
-
[42]
Christoph Treude and Margaret-Anne Storey. 2025. Generative ai and empirical software engineering: A paradigm shift. In2025 2nd IEEE/ACM International Conference on AI-powered Software (AIware). IEEE, 233–239
2025
-
[43]
Bianca Trinkenreich, Fabio Calefato, Geir Hanssen, Kelly Blincoe, Marcos Kalinowski, Mauro Pezzè, Paolo Tell, and Margaret-Anne D. Storey. 2025. Get on the Train or be Left on the Station: Using LLMs for Software Engineering Research. InProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering, FSE Companion 2025, Cla...
-
[44]
Richard Van Noorden and Jeffrey M Perkel. 2023. AI and science: what 1,600 researchers think.Nature621, 7980 (2023), 672–675. Manuscript submitted to ACM Taking a Pulse on How Generative AI is Reshaping the Software Engineering Research Landscape 37
2023
-
[45]
Stefan Wagner, Marvin Muñoz Barón, Davide Falessi, and Sebastian Baltes. 2025. Towards evaluation guidelines for empirical studies involving llms. In2025 IEEE/ACM International Workshop on Methodological Issues with Empirical Studies in Software Engineering (WSESE). IEEE, 24–27
2025
- [46]
-
[47]
Viggo Tellefsen Wivestad and Astri Moksnes Barbala. 2025. Attitudes Towards LLM Use Among Software Engineering Researchers: Results From A Two-Phase Survey Study. InProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering. 1531–1535
2025
-
[48]
Claes Wohlin, Per Runeson, Martin Höst, Magnus C. Ohlsson, Björn Regnell, and Anders Wesslén. 2012.Experimentation in Software Engineering. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-29044-2
-
[49]
Ruoxi Xu, Yingfei Sun, Mengjie Ren, Shiguang Guo, Ruotong Pan, Hongyu Lin, Le Sun, and Xianpei Han. 2024. AI for social science and social science of AI: A survey.Information Processing & Management61, 2 (2024), 103665. https://doi.org/10.1016/J.IPM.2024.103665
-
[50]
Ting Zhang, Ivana Clairine Irsan, Ferdian Thung, and David Lo. 2025. Revisiting sentiment analysis for software engineering in the era of large language models.ACM Transactions on Software Engineering and Methodology34, 3 (2025), 1–30
2025
-
[51]
Ruiyang Zhou, Lu Chen, and Kai Yu. 2024. Is LLM a Reliable Reviewer? A Comprehensive Evaluation of LLM on Automatic Paper Reviewing Tasks. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation, LREC/COLING 2024. ELRA and ICCL, 9340–9351. Manuscript submitted to ACM
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.