Recognition: unknown
BankerToolBench: Evaluating AI Agents in End-to-End Investment Banking Workflows
Pith reviewed 2026-05-10 15:52 UTC · model grok-4.3
The pith
Even the best frontier AI model fails nearly half the rubric criteria in end-to-end investment banking workflows and produces no client-ready outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
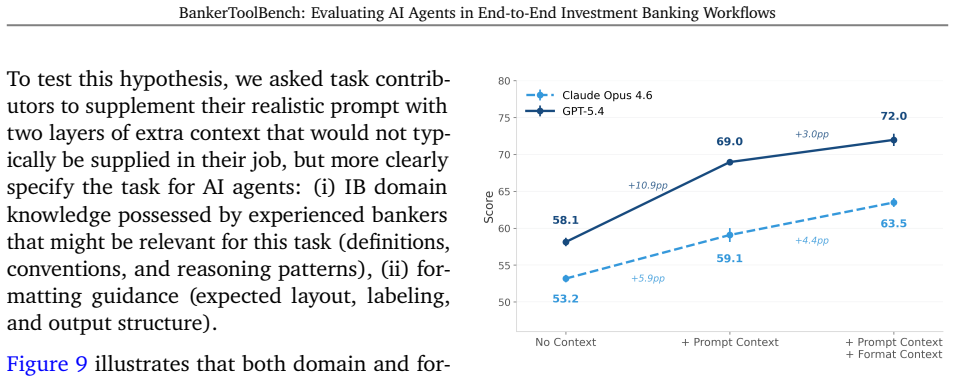
BankerToolBench evaluates AI agents on complete analytical workflows that junior investment bankers perform daily. The benchmark requires agents to interpret senior requests, retrieve and integrate data from industry platforms, and assemble polished deliverables that meet professional standards. When nine frontier models were tested, the top performer satisfied only slightly more than half the rubric criteria established by practicing bankers, and zero outputs were judged ready for client delivery.
What carries the argument
BankerToolBench is an open-source benchmark consisting of end-to-end junior banker workflows scored against more than 100 rubric criteria defined by veteran investment bankers to measure practical stakeholder utility.
If this is right
- Cross-artifact consistency failures must be resolved before AI agents can reliably handle these multi-document workflows.
- The benchmark supplies an automated method for tracking progress on agentic capabilities in high-stakes professional settings.
- Current frontier models leave the economic value of automating up to 21-hour tasks unrealized.
- Failure modes identified in the evaluation point to concrete directions for improving agent performance on complex, tool-using tasks.
Where Pith is reading between the lines
- Benchmarks modeled on BankerToolBench could be created for other labor-intensive professions to measure where AI delegation becomes viable.
- Specialized training on maintaining consistency across Excel, PowerPoint, and report formats may be required to close the observed gaps.
- Success on this benchmark could serve as a measurable proxy for broader progress in reliable, multi-step agentic systems.
- The zero client-ready rate suggests that even high rubric scores may still miss subtle professional standards that only domain experts can fully assess.
Load-bearing premise
The 100-plus rubric criteria and task selection, developed through collaboration with 502 investment bankers, accurately reflect client expectations and typical junior banker workflows.
What would settle it
A model that passes more than 90 percent of the rubric criteria on multiple BankerToolBench tasks and receives at least some client-ready ratings from practicing bankers would falsify the reported performance gap.
Figures








read the original abstract
Existing AI benchmarks lack the fidelity to assess economically meaningful progress on professional workflows. To evaluate frontier AI agents in a high-value, labor-intensive profession, we introduce BankerToolBench (BTB): an open-source benchmark of end-to-end analytical workflows routinely performed by junior investment bankers. To develop an ecologically valid benchmark grounded in representative work environments, we collaborated with 502 investment bankers from leading firms. BTB requires agents to execute senior banker requests by navigating data rooms, using industry tools (market data platform, SEC filings database), and generating multi-file deliverables--including Excel financial models, PowerPoint pitch decks, and PDF/Word reports. Completing a BTB task takes bankers up to 21 hours, underscoring the economic stakes of successfully delegating this work to AI. BTB enables automated evaluation of any LLM or agent, scoring deliverables against 100+ rubric criteria defined by veteran investment bankers to capture stakeholder utility. Testing 9 frontier models, we find that even the best-performing model (GPT-5.4) fails nearly half of the rubric criteria and bankers rate 0% of its outputs as client-ready. Our failure analysis reveals key obstacles (such as breakdowns in cross-artifact consistency) and improvement directions for agentic AI in high-stakes professional workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BankerToolBench (BTB), an open-source benchmark for AI agents performing end-to-end junior investment banking workflows. Developed via collaboration with 502 bankers from leading firms, BTB tasks require agents to navigate data rooms, use tools like market data platforms and SEC filings databases, and produce multi-file deliverables (Excel models, PowerPoint decks, PDF/Word reports). Automated scoring against 100+ rubric criteria defined by veteran bankers shows that even the best model (GPT-5.4) fails nearly half the criteria, with bankers rating 0% of outputs as client-ready; the work includes failure analysis on obstacles such as cross-artifact consistency.
Significance. If the tasks and rubrics accurately reflect real workflows, the results highlight substantial limitations in frontier AI agents for high-stakes professional tasks with clear economic value (workflows taking up to 21 hours). The practitioner collaboration and open-source release provide a valuable resource for evaluating agentic systems in specialized domains, and the failure modes identified could inform targeted improvements.
major comments (2)
- [Methods] Methods section: The central claims rest on the ecological validity of tasks and 100+ rubric criteria developed through collaboration with 502 bankers, yet the manuscript provides no details on elicitation methods, firm/task sampling, inter-rater reliability, pilot validation, or external review of the criteria. Without these, the reported failure rates (~50% for GPT-5.4) and 0% client-ready assessment cannot be independently interpreted or verified as representative of client expectations.
- [Evaluation and Results] Evaluation and Results: The automated scoring procedure against the rubric is described at a high level, but the paper does not specify how scoring is implemented for complex artifacts (e.g., Excel consistency checks or PowerPoint content evaluation), nor does it release the full rubric or scoring code. This makes the quantitative results difficult to reproduce and raises questions about potential biases in the automated component.
minor comments (2)
- [Abstract] The abstract and introduction refer to 'GPT-5.4' without clarifying whether this is a specific released model, internal version, or placeholder; this should be disambiguated for readers.
- [Results] Table or figure presenting per-model failure rates would benefit from including confidence intervals or variance across tasks to strengthen the comparative claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional transparency will strengthen the manuscript. We address each major comment below and will revise the paper accordingly.
read point-by-point responses
-
Referee: [Methods] Methods section: The central claims rest on the ecological validity of tasks and 100+ rubric criteria developed through collaboration with 502 bankers, yet the manuscript provides no details on elicitation methods, firm/task sampling, inter-rater reliability, pilot validation, or external review of the criteria. Without these, the reported failure rates (~50% for GPT-5.4) and 0% client-ready assessment cannot be independently interpreted or verified as representative of client expectations.
Authors: We agree that the current Methods section is insufficiently detailed for independent assessment of ecological validity. In the revised manuscript we will expand the section to document the elicitation process (structured interviews and workflow capture protocols used with the 502 bankers), the sampling approach across firms and task types, inter-rater reliability statistics for the rubric criteria, pilot-study results, and the external review steps performed by veteran bankers. These additions will allow readers to evaluate how representative the tasks and rubrics are of actual client expectations. revision: yes
-
Referee: [Evaluation and Results] Evaluation and Results: The automated scoring procedure against the rubric is described at a high level, but the paper does not specify how scoring is implemented for complex artifacts (e.g., Excel consistency checks or PowerPoint content evaluation), nor does it release the full rubric or scoring code. This makes the quantitative results difficult to reproduce and raises questions about potential biases in the automated component.
Authors: We acknowledge that the automated scoring description is too high-level and that the full rubric and code were not released with the initial submission. We will add a dedicated subsection detailing the scoring implementation for multi-file artifacts, including the specific checks used for Excel model consistency, data integrity, and PowerPoint narrative/layout evaluation. We will also release the complete rubric and the scoring codebase as part of the open-source benchmark package to support full reproducibility and external scrutiny of the automated component. revision: yes
Circularity Check
No circularity: empirical benchmark with independent evaluation results
full rationale
The paper introduces an empirical benchmark (BankerToolBench) and reports direct performance measurements of frontier models against 100+ rubric criteria. No equations, derivations, fitted parameters, or self-referential definitions appear in the provided text. Task and rubric construction via banker collaboration is presented as an input to the evaluation rather than a quantity derived from the reported outcomes. The failure rates and client-readiness claims are therefore not reduced to the authors' own parameters or prior self-citations by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tasks and 100+ rubric criteria developed with 502 investment bankers accurately capture ecologically valid junior banker workflows and stakeholder utility.
Reference graph
Works this paper leans on
- [1]
-
[2]
HealthBench: Evaluating Large Language Models Towards Improved Human Health
URL https://www.anthropic. com/research/anthropic-economic-index-january-2026-report. R. K. Arora, J. Wei, R. S. Hicks, P. Bowman, J. Quiñonero-Candela, F. Tsimpourlas, M. Sharman, M. Shah, A. Vallone, A. Beutel, et al. Healthbench: Evaluating large language models towards improved human health.arXiv preprint arXiv:2505.08775,
work page internal anchor Pith review arXiv 2026
-
[3]
Y. Bai, S. Kadavath, S. Kundu, A. Askell, J. Kernion, A. Jones, A. Chen, A. Goldie, A. Mirhoseini, C. McKinnon, C. Chen, C. Olsson, C. Olah, D. Hernandez, D. Drain, D. Ganguli, D. Li, E. Tran- Johnson, E. Perez, J. Kerr, J. Mueller, J. Ladish, J. Landau, K. Ndousse, K. Lukosuite, L. Lovitt, M. Sellitto, N. Elhage, N. Schiefer, N. Mercado, N. DasSarma, R. ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
A. Bigeard, L. Nashold, R. Krishnan, and S. Wu. Finance agent benchmark: Benchmarking llms on real-world financial research tasks.arXiv preprint arXiv:2508.00828,
-
[5]
20 BankerToolBench: Evaluating AI Agents in End-to-End Investment Banking Workflows Z. Chen, W. Chen, C. Smiley, S. Shah, I. Borova, D. Langdon, R. Moussa, M. Beane, T.-H. Huang, B. R. Routledge, et al. FinQA: A dataset of numerical reasoning over financial data. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing,
2021
-
[6]
X. Guo, H. Xia, Z. Liu, H. Cao, Z. Yang, Z. Liu, S. Wang, J. Niu, C. Wang, Y. Wang, et al. Fineval: A chinese financial domain knowledge evaluation benchmark for large language models. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies,
2025
-
[7]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
S. Levine, A. Kumar, G. Tucker, and J. Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems.arXiv preprint arXiv:2005.01643,
work page internal anchor Pith review arXiv 2005
-
[8]
X.Li, N.Ben-Israel, Y.Raz, B.Ahmed, D.Serebro, andA.Raux. Repomod-bench: Abenchmarkforcode repository modernization via implementation-agnostic testing.arXiv preprint arXiv:2602.22518,
-
[9]
URL https://www.anthropic.com/research/ economic-index-march-2026-report. A. J. Menkveld. High frequency trading and the new market makers.Journal of financial Markets, 16 (4):712–740,
2026
-
[10]
T. Patwardhan, R. Dias, E. Proehl, G. Kim, M. Wang, O. Watkins, S. P. Fishman, M. Aljubeh, P. Thacker, L. Fauconnet, et al. GDPval: Evaluating AI model performance on real-world economically valuable tasks.arXiv preprint arXiv:2510.04374,
- [11]
-
[13]
URLhttps://arxiv.org/abs/2604.07666. Y. Qin, S. Liang, Y. Ye, K. Zhu, L. Yan, Y. Lu, Y. Lin, X. Cong, X. Tang, B. Qian, et al. ToolLLM: Facilitating large language models to master 16000+ real-world APIs. InInternational Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Autorubric: Unifying Rubric-based LLM Evaluation
D. Rao and C. Callison-Burch. Autorubric: A unified framework for rubric-based LLM evaluation. arXiv preprint arXiv:2603.00077,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z.Shao,P.Wang,Q.Zhu,R.Xu,J.Song,X.Bi,H.Zhang,M.Zhang,Y.Li,etal. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
H. Son. Goldman Sachs taps Anthropic’s Claude to automate accounting, compliance roles.https:// www.cnbc.com/2026/02/06/anthropic-goldman-sachs-ai-model-accounting.html, February
2026
-
[17]
X. Wang, B. Li, Y. Song, F. F. Xu, X. Tang, M. Zhuge, J. Pan, Y. Song, B. Li, J. Singh, H. H. Tran, F. Li, R. Ma, M. Zheng, B. Qian, Y. Shao, N. Muennighoff, Y. Zhang, B. Hui, J. Lin, R. Brennan, H. Peng, H. Ji, and G. Neubig. OpenHands: An open platform for AI software developers as generalist agents. InInternational Conference on Learning Representation...
-
[18]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. Wei, H. Lin, J. Tang, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Zhou, J. Lin, K. Dang, K. Bao, K. Yang, L. Yu, L. Deng, M. Li, M. Xue, M. Li, P. Zhang, P. Wang, Q. Zhu, R. Men, R. Gao, S. Liu, S. Luo, T. ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
S. Yao, N. Shinn, P. Razavi, and K. Narasimhan.𝜏-bench: A benchmark for tool-agent-user interaction in real-world domains.arXiv preprint arXiv:2406.12045,
work page internal anchor Pith review arXiv
- [20]
-
[21]
We consider using the thresholdedScoreas a predictor to approximate these labels, which offer a more interpretable quality measure of the deliverable. Over this ratings data, we assess the quality of our predictor via itsrelative risk: Relative Risk= Pr(Acceptable|Score≥𝑇) Pr(Acceptable|Score< 𝑇) We select the threshold𝑇 which leads to the best predictor ...
2025
-
[22]
import <pkg>; help(<pkg>)
and the built-in agent harnesses without modification, running evaluations via:harbor run . Agent harnesses use their own built-in functionality and heuristics to determine when to terminate, handle tool call failures (e.g., due to incorrect arguments supplied) or error signals, and manage time/step budgets, etc. C.1. Task prompt template Agent harnesses ...
2007
-
[23]
E.1. Details of Construct Definition and Workflow Taxonomy To identify the workflows performed by junior investment bankers that are common and high value (Section 4.1), we conducted 2 surveys of the broader IB population: a Job Task Analysis (JTA) survey, and a survey on AI-value in their job. We ensured representative survey samples by stratifying recru...
2019
-
[24]
RTX & GD - Merger Mode
should have a header labeled “RTX & GD - Merger Mode.” All formulas should be linked to the cell (i.e, C21) and not named cells. The Model should include these sections in the following order. List of all the transaction assumptions Transaction source and uses Write-up of assets and a purchase price allocation on the balance sheet. The Model should includ...
2024
-
[25]
The model should include a detailed Net Cost Mix section
Valuation assumptions: - WACC of 12.0% - Mid-year discounting convention - Terminal value calculated using a 15x EV/EBITDA exit multiple - Use share price as of December 31, 2024, ($81.26) The model should include a detailed net revenue mix section based on Uber’s revenue by service line (Mobility, Delivery, and Freight) and also by geography (United Stat...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.