Recognition: unknown
Network Effects and Agreement Drift in LLM Debates
Pith reviewed 2026-05-10 15:46 UTC · model grok-4.3
The pith
LLM agents in controlled network debates exhibit directional agreement drift toward specific opinion positions beyond what network structure explains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through simulations of multi-round debates on networks generated with tunable homophily and class imbalance, LLM agents display agreement drift by shifting toward specific positions on the opinion scale in a directional manner that exceeds what network structure alone predicts, revealing model biases that must be disentangled from structural influences before LLMs can be treated as behavioral proxies for human populations.
What carries the argument
A network generation model with controlled homophily and class sizes that organizes LLM agents for repeated debate rounds to track and compare opinion shifts against structural expectations.
If this is right
- Network effects such as homophily can be isolated from model biases by using controlled generation of debate networks.
- Minority groups in unbalanced networks experience amplified effects from the directional drift in LLM populations.
- LLM-based social simulations require explicit correction for biases before they can model human agreement processes accurately.
- Direct substitution of LLM agents for human groups in opinion dynamics studies risks misattributing model artifacts to social mechanisms.
Where Pith is reading between the lines
- Similar directional biases may appear in other LLM multi-agent setups such as negotiations or collaborative problem solving.
- Varying prompt strategies or model architectures could quantify how much of the drift depends on implementation details.
- Design of AI systems for social modeling or content moderation might need safeguards against unintended convergence on specific viewpoints.
Load-bearing premise
The directional shifts in agent opinions arise from inherent biases in the LLMs rather than from the specific debate protocol, opinion scale, network generation choices, or prompt designs.
What would settle it
Repeating the exact simulation protocol with human participants or a different family of LLMs and observing no consistent directional preference in opinion shifts would show the drift is not a general property of the models.
Figures



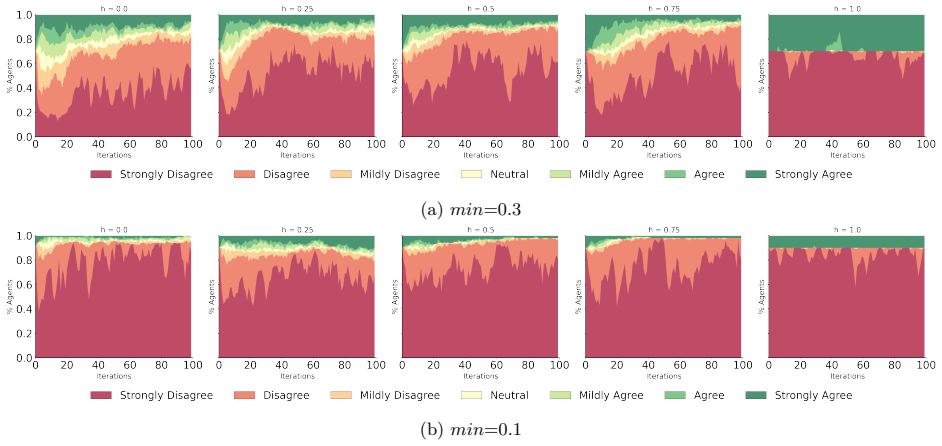






read the original abstract
Large Language Models (LLMs) have demonstrated an unprecedented ability to simulate human-like social behaviors, making them useful tools for simulating complex social systems. However, it remains unclear to what extent these simulations can be trusted to accurately capture key social mechanisms, particularly in highly unbalanced contexts involving minority groups. This paper uses a network generation model with controlled homophily and class sizes to examine how LLM agents behave collectively in multi-round debates. Moreover, our findings highlight a particular directional susceptibility that we term \textit{agreement drift}, in which agents are more likely to shift toward specific positions on the opinion scale. Overall, our findings highlight the need to disentangle structural effects from model biases before treating LLM populations as behavioral proxies for human groups.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript employs a network generation model with controlled homophily and class sizes to simulate multi-round debates among LLM agents. It reports the emergence of a directional susceptibility termed 'agreement drift,' in which agents tend to shift toward specific positions on the opinion scale, and concludes that structural network effects must be disentangled from model biases before LLM populations can serve as reliable behavioral proxies for human groups.
Significance. If the reported agreement drift can be shown through appropriate controls to reflect intrinsic LLM properties rather than artifacts of the simulation protocol, the work would be significant for computational social science. It would provide a concrete cautionary example against treating LLM-based opinion dynamics as direct stand-ins for human behavior, particularly in unbalanced minority contexts, and would motivate more rigorous validation standards in this domain.
major comments (2)
- [Abstract] Abstract: The central claim of agreement drift and the call to disentangle structural effects from model biases are asserted without any reference to experimental details, statistical tests, sample sizes, or controls. This absence renders the empirical observation unevaluable and prevents assessment of whether the directional susceptibility is robust.
- [Methods/Results] Methods/Results (inferred from abstract description): The attribution of shifts to LLM model biases lacks demonstrated isolation from the chosen opinion scale, prompt instructions, network generation procedure, or debate protocol. No ablations (e.g., symmetric vs. asymmetric scales, randomized-update baselines, or neutral-prompt variants) are described, leaving open the possibility that the observed drift is an artifact of discretization or instruction design rather than an intrinsic bias.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has helped us strengthen the presentation and rigor of our work on agreement drift in LLM debates. We address each major comment below, clarifying our experimental design and indicating the specific revisions made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of agreement drift and the call to disentangle structural effects from model biases are asserted without any reference to experimental details, statistical tests, sample sizes, or controls. This absence renders the empirical observation unevaluable and prevents assessment of whether the directional susceptibility is robust.
Authors: We agree that the original abstract was too concise and omitted key details needed for evaluation. In the revised manuscript, we have expanded the abstract to explicitly reference the network generation procedure (controlled homophily and class sizes), the multi-round debate protocol, the opinion scale discretization, the number of simulation runs and LLM instances used, and the statistical tests applied to detect directional shifts (including regression-based analysis of opinion changes with significance thresholds). These additions make the empirical basis for agreement drift transparent and allow readers to assess its robustness directly from the abstract. revision: yes
-
Referee: [Methods/Results] Methods/Results (inferred from abstract description): The attribution of shifts to LLM model biases lacks demonstrated isolation from the chosen opinion scale, prompt instructions, network generation procedure, or debate protocol. No ablations (e.g., symmetric vs. asymmetric scales, randomized-update baselines, or neutral-prompt variants) are described, leaving open the possibility that the observed drift is an artifact of discretization or instruction design rather than an intrinsic bias.
Authors: We thank the referee for highlighting this important point. Our core contribution centers on separating network structural effects (via systematic variation of homophily and minority class sizes) from the observed directional drift, and the full methods section details the fixed prompt templates and debate rules used across conditions. However, we acknowledge that the original submission did not include the full set of ablations suggested. In the revision, we have added new experiments using symmetric opinion scales, randomized update order baselines, and neutral-prompt variants. These controls show that the agreement drift remains consistent in direction and magnitude, providing evidence that it is not solely an artifact of the original discretization or instructions. We have also expanded the methods to describe the prompt engineering and protocol more explicitly, while noting that exhaustive isolation from every conceivable prompt variant remains an open challenge for the field. revision: yes
Circularity Check
No derivation chain or self-referential reductions present
full rationale
The paper is an empirical simulation study of LLM agents in multi-round debates on networks with controlled homophily. It introduces the descriptive label 'agreement drift' for observed directional opinion shifts and calls for disentangling structural effects from model biases. No equations, first-principles derivations, fitted parameters, or predictions appear in the abstract or described content. No self-citations are invoked as load-bearing uniqueness theorems, ansatzes, or imported results. The central observations do not reduce to their own inputs by construction; they are presented as simulation outputs requiring external validation. This is a standard non-circular empirical report.
Axiom & Free-Parameter Ledger
invented entities (1)
-
agreement drift
no independent evidence
Reference graph
Works this paper leans on
-
[1]
OpenAI,JoshAchiam, StevenAdler, SandhiniAgarwal, LamaAhmad, IlgeAkkaya, FlorenciaLeoniAle- man, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Berner, Lenn...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b, 2023. URLhttps://arxiv...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Llama 3 model card.N.A., 2024
AI@Meta. Llama 3 model card.N.A., 2024. URLhttps://github.com/meta-llama/llama3/blob/ main/MODEL_CARD.md
2024
-
[4]
DeepSeek-AI, Aixin Liu, Bei Feng, et al. Deepseek-v3 technical report, 2025. URLhttps://arxiv. org/abs/2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Elizabeth Clark, Tal August, Sofia Serrano, Nikita Haduong, Suchin Gururangan, and Noah A Smith. All that’s’ human’is not gold: Evaluating human evaluation of generated text.arXiv preprint arXiv:2107.00061, 2021
-
[6]
Sentiment Analysis in the Era of Large Language Models: A Reality Check.CoRR abs/2305.15005, 2023
Wenxuan Zhang, Yue Deng, Bing Liu, Sinno Jialin Pan, and Lidong Bing. Sentiment analysis in the era of large language models: A reality check.arXiv preprint arXiv:2305.15005, 2023
-
[7]
Minxue Niu, Mimansa Jaiswal, and Emily Mower Provost. From text to emotion: Unveiling the emotion annotation capabilities of llms.arXiv preprint arXiv:2408.17026, 2024
-
[8]
Llm-based topic modeling for dark web q&a forums: A comparative analysis with traditional methods.IEEE Access, 2025
Luis De-Marcos and Adrián Domínguez-Díaz. Llm-based topic modeling for dark web q&a forums: A comparative analysis with traditional methods.IEEE Access, 2025
2025
-
[9]
Large Language Models: A Survey
ShervinMinaee, TomasMikolov, NarjesNikzad, MeysamChenaghlu, RichardSocher, XavierAmatriain, and Jianfeng Gao. Large language models: A survey, 2025. URLhttps://arxiv.org/abs/2402.06196
work page internal anchor Pith review arXiv 2025
-
[10]
Evaluating the ability of large language models to emulate personality.Scientific reports, 15(1):519, 2025
Yilei Wang, Jiabao Zhao, Deniz S Ones, Liang He, and Xin Xu. Evaluating the ability of large language models to emulate personality.Scientific reports, 15(1):519, 2025
2025
-
[11]
Edoardo Sebastiano De Duro, Riccardo Improta, and Massimo Stella. Introducing counsellme: A dataset of simulated mental health dialogues for comparing llms like haiku, llamantino and chatgpt against humans.Emerging Trends in Drugs, Addictions, and Health, page 100170, 2025
2025
-
[12]
Modeling social opinion evolution with llm agents: Integrating personality traits with embedded opinion dynamics
Fan Yang, Jie Bai, Linjing Li, and Daniel Zeng. Modeling social opinion evolution with llm agents: Integrating personality traits with embedded opinion dynamics. In2025 International Joint Conference on Neural Networks (IJCNN), pages 1–8. IEEE, 2025
2025
-
[13]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th annual acm symposium on user interface software and technology, pages 1–22, 2023
2023
-
[14]
LLM Agents Grounded in Self-Reports Enable General-Purpose Simulation of Individuals
Joon Sung Park, Carolyn Q. Zou, Aaron Shaw, Benjamin Mako Hill, Carrie Cai, Meredith Ringel Morris, Robb Willer, Percy Liang, and Michael S. Bernstein. Generative agent simulations of 1,000 people, 2024. URLhttps://arxiv.org/abs/2411.10109
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Systematic biases in llm simulations of debates.arXiv preprint arXiv:2402.04049, 2024
Amir Taubenfeld, Yaniv Dover, Roi Reichart, and Ariel Goldstein. Systematic biases in llm simulations of debates.arXiv preprint arXiv:2402.04049, 2024. 18
-
[16]
Hidden persuaders: Llms’ political leaning and their influence on voters
Yujin Potter, Shiyang Lai, Junsol Kim, James Evans, and Dawn Song. Hidden persuaders: Llms’ political leaning and their influence on voters. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 4244–4275, 2024
2024
-
[17]
A foundation model to predict and capture human cognition.Nature, pages 1–8, 2025
Marcel Binz, Elif Akata, Matthias Bethge, Franziska Brändle, Fred Callaway, Julian Coda-Forno, Peter Dayan, Can Demircan, Maria K Eckstein, Noémi Éltető, et al. A foundation model to predict and capture human cognition.Nature, pages 1–8, 2025
2025
-
[18]
Ysocial: an ai-powered social media virtual twin.Big Data & Society, 2026
Giulio Rossetti, Massimo Stella, Rémy Cazabet, Katherine Abramski, Erica Cau, Salvatore Citraro, Andrea Failla, Virginia Morini, and Valentina Pansanella. Ysocial: an ai-powered social media virtual twin.Big Data & Society, 2026. doi: 10.1177/20539517261431576
-
[19]
Emergent social conventions and col- lective bias in llm populations.Science Advances, 11(20):eadu9368, 2025
Ariel Flint Ashery, Luca Maria Aiello, and Andrea Baronchelli. Emergent social conventions and col- lective bias in llm populations.Science Advances, 11(20):eadu9368, 2025
2025
-
[20]
On the unexpected abilities of large language models.Adaptive Behavior, 32(6):493–502, 2024
Stefano Nolfi. On the unexpected abilities of large language models.Adaptive Behavior, 32(6):493–502, 2024
2024
-
[21]
Behavioral and Brain Sciences , author=
David Premack and Guy Woodruff. Does the chimpanzee have a theory of mind?Behavioral and Brain Sciences, 1(4):515–526, December 1978. ISSN 1469-1825. doi: 10.1017/s0140525x00076512. URL http://dx.doi.org/10.1017/S0140525X00076512
-
[22]
Llm-based social simulations require a bound- ary.arXiv preprint arXiv:2506.19806, 2025
Zengqing Wu, Run Peng, Takayuki Ito, and Chuan Xiao. Llm-based social simulations require a bound- ary.arXiv preprint arXiv:2506.19806, 2025
-
[23]
arXiv preprint arXiv:2310.10701 , year=
Huao Li, Yu Quan Chong, Simon Stepputtis, Joseph Campbell, Dana Hughes, Michael Lewis, and Katia Sycara. Theory of mind for multi-agent collaboration via large language models.arXiv preprint arXiv:2310.10701, 2023
-
[24]
Maarten Sap, Ronan LeBras, Daniel Fried, and Yejin Choi. Neural theory-of-mind? on the limits of social intelligence in large lms.arXiv preprint arXiv:2210.13312, 2022
-
[25]
Winnie Street, John Oliver Siy, Geoff Keeling, Adrien Baranes, Benjamin Barnett, Michael McKibben, Tatenda Kanyere, Alison Lentz, Robin IM Dunbar, et al. Llms achieve adult human performance on higher-order theory of mind tasks.arXiv preprint arXiv:2405.18870, 2024
-
[26]
Testing theory of mind in large language models and humans.Nature Human Behaviour, 8(7):1285–1295, 2024
James WA Strachan, Dalila Albergo, Giulia Borghini, Oriana Pansardi, Eugenio Scaliti, Saurabh Gupta, Krati Saxena, Alessandro Rufo, Stefano Panzeri, Guido Manzi, et al. Testing theory of mind in large language models and humans.Nature Human Behaviour, 8(7):1285–1295, 2024
2024
-
[27]
Large language models fail on trivial alterations to theory-of-mind tasks, 2023
Tomer Ullman. Large language models fail on trivial alterations to theory-of-mind tasks.arXiv preprint arXiv:2302.08399, 2023
-
[28]
Evaluating large language models in theory of mind tasks.Proceedings of the National Academy of Sciences, 121(45):e2405460121, 2024
Michal Kosinski. Evaluating large language models in theory of mind tasks.Proceedings of the National Academy of Sciences, 121(45):e2405460121, 2024
2024
-
[29]
The persuasive power of large language models
Simon Martin Breum, Daniel Væ dele Egdal, Victor Gram Mortensen, Anders Giovanni Mø ller, and Luca Maria Aiello. The persuasive power of large language models. InProceedings of the International AAAI Conference on Web and Social Media, volume 18, pages 152–163, 2024
2024
-
[30]
Birds of a feather: Homophily in social networks.Annual review of sociology, 27(1):415–444, 2001
Miller McPherson, Lynn Smith-Lovin, and James M Cook. Birds of a feather: Homophily in social networks.Annual review of sociology, 27(1):415–444, 2001
2001
-
[31]
Xinnong Zhang, Jiayu Lin, Xinyi Mou, Shiyue Yang, Xiawei Liu, Libo Sun, Hanjia Lyu, Yihang Yang, Weihong Qi, Yue Chen, et al. Socioverse: A world model for social simulation powered by llm agents and a pool of 10 million real-world users.arXiv preprint arXiv:2504.10157, 2025
-
[32]
Understanding online polarization through human-agent interaction in a synthetic llm-based social network.N.A., 2025
Tim Donkers and Jürgen Ziegler. Understanding online polarization through human-agent interaction in a synthetic llm-based social network.N.A., 2025. 19
2025
-
[33]
Using large language models in psychology.Nature Reviews Psychology, 2(11):688–701, 2023
Dorottya Demszky, Diyi Yang, David S Yeager, Christopher J Bryan, Margarett Clapper, Susannah Chandhok, Johannes C Eichstaedt, Cameron Hecht, Jeremy Jamieson, Meghann Johnson, et al. Using large language models in psychology.Nature Reviews Psychology, 2(11):688–701, 2023
2023
-
[34]
The problems of llm-generated data in social science research.Sociologica: International Journal for Sociological Debate, 18(2):145–168, 2024
Luca Rossi, Katherine Harrison, and Irina Shklovski. The problems of llm-generated data in social science research.Sociologica: International Journal for Sociological Debate, 18(2):145–168, 2024
2024
-
[35]
Homophily-induced emergence of biased structures in llm- based multi-agent ai systems.Social Network Analysis and Mining, 15(1):1–25, 2025
Aliakbar Mehdizadeh and Martin Hilbert. Homophily-induced emergence of biased structures in llm- based multi-agent ai systems.Social Network Analysis and Mining, 15(1):1–25, 2025
2025
-
[36]
Homophily influences ranking of minorities in social networks.Scientific reports, 8(1):11077, 2018
Fariba Karimi, Mathieu Génois, Claudia Wagner, Philipp Singer, and Markus Strohmaier. Homophily influences ranking of minorities in social networks.Scientific reports, 8(1):11077, 2018
2018
-
[37]
Towards understanding sycophancy in language models
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R Bowman, Esin DURMUS, Zac Hatfield-Dodds, Scott R Johnston, Shauna M Kravec, et al. Towards understanding sycophancy in language models. InThe Twelfth International Conference on Learning Representations, pages 383–390, 2025
2025
-
[38]
Selective agreement, not syco- phancy: investigating opinion dynamics in llm interactions.EPJ Data Science, 14(1):59, 2025
Erica Cau, Valentina Pansanella, Dino Pedreschi, and Giulio Rossetti. Selective agreement, not syco- phancy: investigating opinion dynamics in llm interactions.EPJ Data Science, 14(1):59, 2025
2025
-
[39]
Statisticalphysicsofsocialdynamics.Reviews of modern physics, 81(2):591, 2009
ClaudioCastellano, SantoFortunato, andVittorioLoreto. Statisticalphysicsofsocialdynamics.Reviews of modern physics, 81(2):591, 2009
2009
-
[40]
Bounded confidence opinion dynamics in virtual networks and real networks
Xia-Meng Si and Chen Li. Bounded confidence opinion dynamics in virtual networks and real networks. Journal of Computers, 29(3):220–228, 2018
2018
-
[41]
Ergodic theorems for weakly interacting infinite systems and the voter model.The annals of probability, pages 643–663, 1975
Richard A Holley and Thomas M Liggett. Ergodic theorems for weakly interacting infinite systems and the voter model.The annals of probability, pages 643–663, 1975
1975
-
[42]
Mixing beliefs among interacting agents.Advances in Complex Systems, 3(01n04):87–98, 2000
Guillaume Deffuant, David Neau, Frederic Amblard, and Gérard Weisbuch. Mixing beliefs among interacting agents.Advances in Complex Systems, 3(01n04):87–98, 2000
2000
-
[43]
Dynamics of majority rule in two-state interacting spin systems
Paul L Krapivsky and Sidney Redner. Dynamics of majority rule in two-state interacting spin systems. Physical Review Letters, 90(23):238701, 2003
2003
-
[44]
Routledge, 2013
Irving Crespi.The public opinion process: How the people speak. Routledge, 2013
2013
-
[45]
Recent advances in opinion propagation dynamics: A 2020 survey.The European Physical Journal Plus, 135:1–20, 2020
Hossein Noorazar. Recent advances in opinion propagation dynamics: A 2020 survey.The European Physical Journal Plus, 135:1–20, 2020
2020
-
[46]
Opinion dynamics: models, ex- tensions and external effects.Participatory sensing, opinions and collective awareness, pages 363–401, 2017
Alina Sîrbu, Vittorio Loreto, Vito DP Servedio, and Francesca Tria. Opinion dynamics: models, ex- tensions and external effects.Participatory sensing, opinions and collective awareness, pages 363–401, 2017
2017
-
[47]
A model for spatial conflict.Biometrika, 60(3):581–588,
PETER CLIFFORD and AIDAN SUDBURY. A model for spatial conflict.Biometrika, 60(3):581–588,
-
[48]
ISSN 1464-3510. doi: 10.1093/biomet/60.3.581. URLhttp://dx.doi.org/10.1093/biomet/60. 3.581
-
[49]
Morris H. Degroot. Reaching a consensus.Journal of the American Statistical Association, 69(345): 118–121, March 1974. ISSN 1537-274X. doi: 10.1080/01621459.1974.10480137. URLhttp://dx.doi. org/10.1080/01621459.1974.10480137
-
[50]
Giordano De Marzo, Luciano Pietronero, and David Garcia. Emergence of scale-free networks in social interactions among large language models.arXiv preprint arXiv:2312.06619, 2023
-
[51]
S3: Social-network simulation system with large language model-empowered agents
Chen Gao, Xiaochong Lan, Zhihong Lu, Jinzhu Mao, Jinghua Piao, Huandong Wang, Depeng Jin, and Yong Li. S3: Social-network simulation system with large language model-empowered agents.arXiv preprint arXiv:2307.14984, 2023. 20
-
[52]
arXiv preprint arXiv:2402.04559 , year=
Chengxing Xie, Canyu Chen, Feiran Jia, Ziyu Ye, Kai Shu, Adel Bibi, Ziniu Hu, Philip Torr, Bernard Ghanem, and Guohao Li. Can large language model agents simulate human trust behaviors?arXiv preprint arXiv:2402.04559, 2024
-
[53]
Joon Sung Park, Lindsay Popowski, Carrie Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Social simulacra: Creating populated prototypes for social computing systems. InProceedings of the 35th Annual ACM Symposium on User Interface Software and Technology, UIST ’22, pages 383– 390, New York, NY, USA, 2022. Association for Computing Mac...
-
[54]
Can llm agents maintain a persona in discourse? InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 29201–29217, 2025
Pranav Bhandari, Nicolas Fay, Michael J Wise, Amitava Datta, Stephanie Meek, Usman Naseem, and Mehwish Nasim. Can llm agents maintain a persona in discourse? InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 29201–29217, 2025
2025
-
[56]
Agent-based social simulation of the covid-19 pandemic: A systematic review.Journal of Artificial Societies and Social Simulation, 24(3), 2021
Fabian Lorig, Emil Johansson, and Paul Davidsson. Agent-based social simulation of the covid-19 pandemic: A systematic review.Journal of Artificial Societies and Social Simulation, 24(3), 2021
2021
-
[57]
PetterTörnberg, DiliaraValeeva, JustusUitermark, andChristopherBail. Simulatingsocialmediausing large language models to evaluate alternative news feed algorithms.arXiv preprint arXiv:2310.05984, 2023
- [58]
-
[59]
The language of opinion change on social media under the lens of communicative action.Scientific Reports, 12(1):17920, 2022
Corrado Monti, Luca Maria Aiello, Gianmarco De Francisci Morales, and Francesco Bonchi. The language of opinion change on social media under the lens of communicative action.Scientific Reports, 12(1):17920, 2022
2022
-
[60]
arXiv preprint arXiv:2406.15492 , year=
Pedro Cisneros-Velarde. On the principles behind opinion dynamics in multi-agent systems of large language models, 2024. URLhttps://arxiv.org/abs/2406.15492
-
[61]
The political preferences of llms.PLOS ONE, 19, 2024
David Rozado. The political preferences of llms.PLOS ONE, 19, 2024. URLhttps://api. semanticscholar.org/CorpusID:267412830
2024
-
[62]
Chatgpt in society: emerging issues.Frontiers in Artificial Intelli- gence, 6, 2023
Mirko Farina and Andrea Lavazza. Chatgpt in society: emerging issues.Frontiers in Artificial Intelli- gence, 6, 2023. URLhttps://api.semanticscholar.org/CorpusID:259168081
2023
-
[63]
Botsofafeather: mixingbiasesinllms’opiniondynamics
EricaCau, AndreaFailla, andGiulioRossetti. Botsofafeather: mixingbiasesinllms’opiniondynamics. InInternational conference on complex networks and their applications, pages 166–176. Springer, 2024
2024
-
[64]
When corrections fail: The persistence of political misperceptions
Brendan Nyhan and Jason Reifler. When corrections fail: The persistence of political misperceptions. Political Behavior, 32(2):303–330, 2010
2010
-
[65]
Dryden and A.H
J. Dryden and A.H. Clough.Parallel Lives. e-artnow, 2018. ISBN 9788027244577. URLhttps: //books.google.it/books?id=-amSDwAAQBAJ
2018
-
[66]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Social influence and the collective dynamics of opinion formation.PloS one, 8(11):e78433, 2013
Mehdi Moussaïd, Juliane E Kämmer, Pantelis P Analytis, and Hansjörg Neth. Social influence and the collective dynamics of opinion formation.PloS one, 8(11):e78433, 2013
2013
-
[68]
Aliakbar Mehdizadeh and Martin Hilbert. When your ai agent succumbs to peer-pressure: Studying opinion-change dynamics of llms.arXiv preprint arXiv:2510.19107, 2025. 21
-
[69]
ELEPHANT: Measuring and understanding social sycophancy in LLMs
Myra Cheng, Sunny Yu, Cinoo Lee, Pranav Khadpe, Lujain Ibrahim, and Dan Jurafsky. Elephant: Measuring and understanding social sycophancy in llms.arXiv preprint arXiv:2505.13995, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
Syceval: Evaluating llm sycophancy
Aaron Fanous, Jacob Goldberg, Ank Agarwal, Joanna Lin, Anson Zhou, Sonnet Xu, Vasiliki Bikia, Roxana Daneshjou, and Sanmi Koyejo. Syceval: Evaluating llm sycophancy. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, volume 8, pages 893–900, 2025
2025
-
[71]
Mitigating voltage fluctuations in grid-tied pv systems: power qual- ity enhancement
Sheena Tahira Khan, Vilas Ramrao Joshi, Deepak Bhardwaj, Surender Kumar Sharma, Shaikh Abdul Waheed, and Deepak K Sharma. Mitigating voltage fluctuations in grid-tied pv systems: power qual- ity enhancement. In2024 3rd International Conference on Computational Modelling, Simulation and Optimization (ICCMSO), pages 407–416. IEEE, 2024
2024
-
[72]
Algorithmic bias amplifies opinion fragmentation and polarization: A bounded confidence model.PloS one, 14(3):e0213246, 2019
Alina Sîrbu, Dino Pedreschi, Fosca Giannotti, and János Kertész. Algorithmic bias amplifies opinion fragmentation and polarization: A bounded confidence model.PloS one, 14(3):e0213246, 2019
2019
-
[73]
From mean-field to complex topologies: net- work effects on the algorithmic bias model
Valentina Pansanella, Giulio Rossetti, and Letizia Milli. From mean-field to complex topologies: net- work effects on the algorithmic bias model. InComplex Networks & Their Applications X: Volume 2, Proceedings of the Tenth International Conference on Complex Networks and Their Applications COMPLEX NETWORKS 2021 10, pages 329–340. Springer, 2022
2021
-
[74]
Emergence of scaling in random networks.science, 286(5439): 509–512, 1999
Albert-László Barabási and Réka Albert. Emergence of scaling in random networks.science, 286(5439): 509–512, 1999. 22
1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.