Recognition: unknown
From Translation to Superset: Benchmark-Driven Evolution of a Production AI Agent from Rust to Python
Pith reviewed 2026-05-10 15:46 UTC · model grok-4.3
The pith
Benchmark-driven LLM translation evolves a Rust AI agent port into a Python superset with near-parity performance and 15.9 times less code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
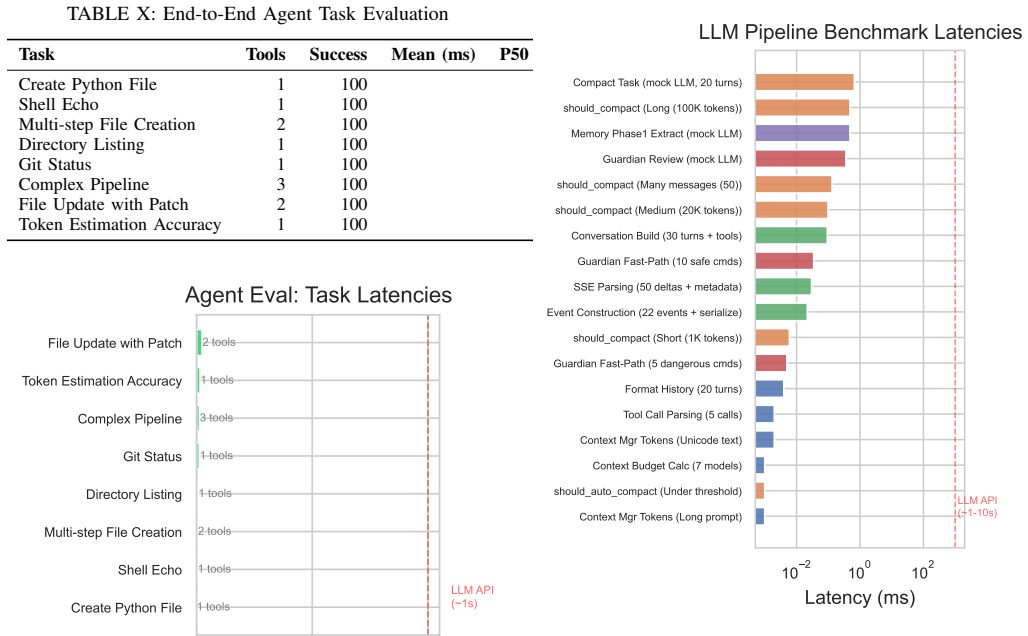
The authors show that their LLM-assisted diff-translate-test loop, driven by agent benchmarks, produces a Python port of the Codex CLI that resolves 59 of 80 SWE-bench Verified tasks and 42.5 percent on Terminal-Bench, compared to 56 and 47.5 percent for Rust, while expanding into a superset with 30 feature-flagged extensions and a 15.9x code reduction.
What carries the argument
The central mechanism is the benchmark-as-objective-function methodology, in which public benchmarks direct the LLM's translation refinements and reveal issues such as API mismatches and silent failures through repeated execution.
If this is right
- The Python architecture supports continuous upstream synchronization via repeated diff-translate-test cycles.
- Benchmark-driven debugging proves more effective than static testing for identifying translation problems.
- Python's expressiveness delivers substantial code reduction for latency-bound AI agents with little performance penalty.
- The port transitions from strict parity to an extended platform with additional features like multi-agent orchestration and safety mechanisms.
Where Pith is reading between the lines
- Such translation loops could lower the barrier for experimenting with language-specific optimizations in agent systems.
- The method might generalize to migrating other production AI tools where benchmarks can serve as proxies.
- Feature extensions developed in the superset could be selectively integrated back into the original implementation.
Load-bearing premise
The assumption that the chosen benchmarks serve as complete proxies for production behavior and that benchmark-driven debugging will catch every critical translation error without introducing undetected failures.
What would settle it
Running the Python port on a large set of internal production coding tasks not included in SWE-bench or Terminal-Bench and finding substantially more failures or new silent errors would indicate the claim does not hold.
Figures








read the original abstract
Cross-language migration of large software systems is a persistent engineering challenge, particularly when the source codebase evolves rapidly. We present a methodology for LLM-assisted continuous code translation in which a large language model translates a production Rust codebase (648K LOC, 65 crates) into Python (41K LOC, 28 modules), with public agent benchmarks as the objective function driving iterative refinement. Our subject system is Codex CLI, a production AI coding agent. We demonstrate that: (1) the Python port resolves 59/80 SWE-bench Verified tasks (73.8%) versus Rust's 56/80 (70.0%), and achieves 42.5% on Terminal-Bench versus Rust's 47.5%, confirming near-parity on real-world agentic tasks; (2) benchmark-driven debugging, revealing API protocol mismatches, environment pollution, a silent WebSocket failure mode, and an API 400 crash, is more effective than static testing alone; (3) the architecture supports continuous upstream synchronisation via an LLM-assisted diff-translate-test loop; and (4) the Python port has evolved into a capability superset with 30 feature-flagged extensions (multi-agent orchestration, semantic memory, guardian safety, cost tracking) absent from Rust, while preserving strict parity mode for comparison. Our evaluation shows that for LLM-based agents where API latency dominates, Python's expressiveness yields a 15.9x code reduction with negligible performance cost, while the benchmark-as-objective-function methodology provides a principled framework for growing a cross-language port from parity into an extended platform.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a methodology for LLM-assisted continuous code translation of a production Rust AI coding agent (Codex CLI, 648K LOC across 65 crates) into Python (41K LOC across 28 modules), driven by public agent benchmarks (SWE-bench Verified and Terminal-Bench) as the objective function for iterative refinement. It claims the resulting Python port achieves near-parity (59/80 or 73.8% vs Rust's 56/80 or 70.0% on SWE-bench Verified; 42.5% vs 47.5% on Terminal-Bench), that benchmark-driven debugging effectively surfaces issues such as API protocol mismatches and a silent WebSocket failure, that the architecture enables continuous upstream synchronization, and that the Python version has evolved into a superset with 30 feature-flagged extensions while preserving parity mode, all with a 15.9x code reduction.
Significance. If the central claims hold under rigorous evaluation, the work supplies a practical, benchmark-guided framework for cross-language migration and incremental extension of complex production AI agents. The explicit use of public benchmarks for both validation and debugging, combined with the reported code-size reduction in a latency-dominated domain, offers a replicable template that could inform engineering practice for maintaining and evolving agentic systems. The continuous diff-translate-test loop and superset evolution are particularly noteworthy strengths for reproducibility and extensibility.
major comments (3)
- [Abstract] Abstract: The central 'near-parity' claim rests on the specific benchmark scores (73.8% vs 70.0% on SWE-bench Verified; 42.5% vs 47.5% on Terminal-Bench), yet the manuscript provides no description of the test harness, environmental controls between Rust and Python runs, number of evaluation trials, variance, or statistical tests for the small observed differences. This information is required to substantiate that the deltas reflect genuine equivalence rather than uncontrolled factors.
- [Abstract] Abstract / Evaluation: The assertion that benchmark-driven debugging is more effective than static testing alone (and successfully caught API mismatches, environment pollution, WebSocket failure, and API 400 errors) is load-bearing for the translation methodology, but lacks quantification such as the number of iterations required, the fraction of issues detected exclusively by benchmarks, or an ablation comparing the two approaches.
- [Abstract] Abstract: The validation that the Python port constitutes a successful continuous translation and superset rests on the two public benchmarks serving as sufficient proxies for production behavior. The manuscript should include an analysis of benchmark coverage for key production aspects (long sessions, specific API protocols) to address the risk of undetected silent failures remaining after translation.
minor comments (1)
- The 15.9x code reduction is derived from the stated 648K to 41K LOC figures; a brief note clarifying whether these counts exclude comments, blank lines, or generated code would aid precise interpretation.
Simulated Author's Rebuttal
We are grateful to the referee for providing detailed feedback that helps improve the clarity and rigor of our work. We have made revisions to address the major comments on evaluation details and have provided point-by-point responses below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central 'near-parity' claim rests on the specific benchmark scores (73.8% vs 70.0% on SWE-bench Verified; 42.5% vs 47.5% on Terminal-Bench), yet the manuscript provides no description of the test harness, environmental controls between Rust and Python runs, number of evaluation trials, variance, or statistical tests for the small observed differences. This information is required to substantiate that the deltas reflect genuine equivalence rather than uncontrolled factors.
Authors: We agree with the need for more details on the evaluation setup. In the revised version, we have added a description of the test harness in the Evaluation section, specifying the use of the public SWE-bench and Terminal-Bench frameworks with their standard configurations. We describe the environmental controls, including matching hardware, software dependencies, and isolation methods between the Rust and Python executions. Regarding the number of trials, variance, and statistical tests, we note that our evaluation followed the single-run protocol standard for these benchmarks to ensure comparability with published results; we have added this clarification and a discussion of potential variance sources without performing additional statistical analysis, as the focus was on practical parity rather than statistical significance of small deltas. revision: yes
-
Referee: [Abstract] Abstract / Evaluation: The assertion that benchmark-driven debugging is more effective than static testing alone (and successfully caught API mismatches, environment pollution, WebSocket failure, and API 400 errors) is load-bearing for the translation methodology, but lacks quantification such as the number of iterations required, the fraction of issues detected exclusively by benchmarks, or an ablation comparing the two approaches.
Authors: We agree that quantification would be valuable. In the revision, we have included the number of major translation iterations performed (the process was iterative until parity was achieved), and we enumerate that the listed issues (API mismatches, etc.) were detected during benchmark runs after static checks passed. We provide a qualitative argument for why benchmarks were necessary, but acknowledge the absence of a formal ablation study, which would require a separate controlled experiment not part of this work. We have added this as a limitation. revision: partial
-
Referee: [Abstract] Abstract: The validation that the Python port constitutes a successful continuous translation and superset rests on the two public benchmarks serving as sufficient proxies for production behavior. The manuscript should include an analysis of benchmark coverage for key production aspects (long sessions, specific API protocols) to address the risk of undetected silent failures remaining after translation.
Authors: We recognize the importance of assessing benchmark coverage. In the revised manuscript, we have added a subsection discussing how SWE-bench and Terminal-Bench cover aspects of production use, such as multi-turn interactions for long sessions and command execution for API protocols. We analyze potential gaps, such as specific internal API behaviors, and have included this risk in the limitations section, suggesting that the continuous synchronization architecture allows for ongoing validation against production data. revision: yes
Circularity Check
No circularity; empirical results on external public benchmarks
full rationale
The paper reports observed success rates on two independent public benchmarks (SWE-bench Verified and Terminal-Bench) after an LLM-assisted translation process. These benchmarks are external to the work and serve as the objective function without any internal equations, fitted parameters, or self-referential definitions that would make the reported percentages reduce to the inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in the provided text to justify the central claims. The derivation chain consists of engineering steps (translation, debugging, feature extension) whose outcomes are measured against outside standards, rendering the paper self-contained with no load-bearing circular reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Public benchmarks such as SWE-bench Verified and Terminal-Bench serve as adequate proxies for production AI agent performance
Forward citations
Cited by 1 Pith paper
-
HARBOR: Automated Harness Optimization
HARBOR formalizes harness optimization as constrained noisy Bayesian optimization over mixed-variable spaces and reports a case study where it outperforms manual tuning on a production coding agent.
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. d. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockmanet al., “Evaluating large language models trained on code,” inarXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Laude Institute, “Terminal-bench: Benchmarking LLM agents on real- world terminal tasks,”arXiv preprint arXiv:2601.11868, 2025, https: //www.tbench.ai/
work page internal anchor Pith review arXiv 2025
-
[3]
Model context protocol: A standard for tool-augmented LLM systems,
Anthropic, “Model context protocol: A standard for tool-augmented LLM systems,” 2025, https://modelcontextprotocol.io
2025
-
[4]
A complexity measure,
T. J. McCabe, “A complexity measure,”IEEE Transactions on Software Engineering, vol. SE-2, no. 4, pp. 308–320, 1976
1976
-
[5]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
J. Yang, C. E. Jimenez, A. Wettig, K. Liber, K. Narasimhan, and O. Press, “SWE-agent: Agent-computer interfaces enable automated software engineering,”arXiv preprint arXiv:2405.15793, 2024
work page internal anchor Pith review arXiv 2024
-
[6]
SWE-bench: Can language models resolve real-world GitHub issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan, “SWE-bench: Can language models resolve real-world GitHub issues?” inInternational Conference on Learning Representa- tions (ICLR), 2024
2024
-
[7]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
X. Wanget al., “OpenDevin: An open platform for AI software developers as generalist agents,”arXiv preprint arXiv:2407.16741, 2024
work page internal anchor Pith review arXiv 2024
-
[8]
ChatDev: Communicative agents for software develop- ment,
C. Qianet al., “ChatDev: Communicative agents for software develop- ment,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024
2024
-
[9]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” in International Conference on Learning Representations (ICLR), 2023
2023
-
[10]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess `ı, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,”Advances in Neural Infor- mation Processing Systems, vol. 36, 2024
2024
-
[11]
Lost in translation: A study of bugs introduced by large language models while translating code,
R. Pan, A. R. Ibrahimzada, R. Krishna, D. J. Murali, J. Pavezet al., “Lost in translation: A study of bugs introduced by large language models while translating code,”Proceedings of the IEEE/ACM 46th International Conference on Software Engineering (ICSE), 2024
2024
-
[12]
An empirical study on learning bug-fixing patches in the wild via neural machine translation,
M. Tufano, C. Watson, G. Bavota, M. Di Penta, M. White, and D. Poshyvanyk, “An empirical study on learning bug-fixing patches in the wild via neural machine translation,”ACM Transactions on Software Engineering and Methodology, vol. 28, no. 4, pp. 1–29, 2019
2019
-
[13]
Elements of software science
M. H. Halstead, “Elements of software science.” Elsevier, 1977
1977
-
[14]
A systematic eval- uation of large language models of code,
F. F. Xu, U. Alon, G. Neubig, and V . J. Hellendoorn, “A systematic eval- uation of large language models of code,” inInternational Symposium on Machine Programming (MAPS), 2022. APPENDIX Table XIII lists all 30 feature flags in the codex.enhancementsmodule, grouped by sub-package. Each flag can be toggled at runtime via--enable FLAG /--disable FLAG, via ...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.