Recognition: unknown
Seeing Through Touch: Tactile-Driven Visual Localization of Material Regions
Pith reviewed 2026-05-10 15:49 UTC · model grok-4.3
The pith
Touch input can pinpoint matching material regions in complex images by learning dense local visuo-tactile correspondences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a model learning local visuo-tactile alignment via dense cross-modal feature interactions produces tactile saliency maps for touch-conditioned material segmentation. This is enabled by introducing in-the-wild multi-material scene images and a material-diversity pairing strategy that aligns each tactile sample with varied visuals while keeping tactile consistency, yielding substantially better localization performance than global-alignment baselines on new and prior benchmarks.
What carries the argument
Dense cross-modal feature interactions that produce tactile saliency maps for local material correspondence
Load-bearing premise
The in-the-wild multi-material images and material-diversity pairing strategy overcome fine-grained correspondence limits of close-up datasets without adding new biases.
What would settle it
Evaluation on a fresh collection of multi-material scenes that introduce new lighting, scale, or texture variations outside the training distribution, where the method shows no gain over global-alignment baselines.
Figures




















read the original abstract
We address the problem of tactile localization, where the goal is to identify image regions that share the same material properties as a tactile input. Existing visuo-tactile methods rely on global alignment and thus fail to capture the fine-grained local correspondences required for this task. The challenge is amplified by existing datasets, which predominantly contain close-up, low-diversity images. We propose a model that learns local visuo-tactile alignment via dense cross-modal feature interactions, producing tactile saliency maps for touch-conditioned material segmentation. To overcome dataset constraints, we introduce: (i) in-the-wild multi-material scene images that expand visual diversity, and (ii) a material-diversity pairing strategy that aligns each tactile sample with visually varied yet tactilely consistent images, improving contextual localization and robustness to weak signals. We also construct two new tactile-grounded material segmentation datasets for quantitative evaluation. Experiments on both new and existing benchmarks show that our approach substantially outperforms prior visuo-tactile methods in tactile localization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper addresses tactile localization by identifying image regions matching the material properties of a tactile input. Existing methods fail due to global alignment and limited close-up datasets. The authors propose a model using dense cross-modal feature interactions to generate tactile saliency maps for material segmentation. They introduce in-the-wild multi-material images, a material-diversity pairing strategy, and two new tactile-grounded datasets. Experiments on new and existing benchmarks show substantial outperformance over prior visuo-tactile methods.
Significance. If the results hold, the work advances fine-grained visuo-tactile alignment beyond global methods, with value in the new datasets and pairing strategy for robustness to weak signals. The experimental sections provide concrete metrics, baseline comparisons, and ablations, addressing the abstract's initial lack of quantitative detail and supporting the central claims without circularity or unsupported leaps.
minor comments (3)
- Abstract: The claim of 'substantially outperforms' lacks any quantitative metrics or baseline names; adding 1-2 key numbers (e.g., mIoU gains) would make the summary self-contained.
- §3 (Method): The description of dense cross-modal interactions would benefit from an explicit equation or diagram showing how tactile and visual features are fused at each spatial location.
- Table 1 and Table 2: Ensure all reported metrics include standard deviations over multiple runs to allow assessment of statistical significance of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The evaluation correctly identifies the core limitations of prior global-alignment methods and the value of our dense cross-modal interactions, material-diversity pairing, and new datasets. No specific major comments were raised in the report.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces a new model for dense cross-modal visuo-tactile feature interactions, along with new in-the-wild datasets and a material-diversity pairing strategy. Its central claims rest on empirical outperformance metrics, ablation studies, and benchmark comparisons rather than any mathematical derivation or prediction that reduces by construction to author-defined inputs, fitted parameters, or self-citations. No equations or uniqueness theorems are invoked that loop back to the paper's own fitted quantities; the argument chain is self-contained through novel architectural components and external data contributions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dense cross-modal feature interactions suffice to capture fine-grained local material correspondences from tactile inputs.
Reference graph
Works this paper leans on
-
[1]
Gradio: Hassle-Free Sharing and Testing of ML Models in the Wild
Abubakar Abid, Ali Abdalla, Ali Abid, Dawood Khan, Ab- dulrahman Alfozan, and James Zou. Gradio: Hassle-free sharing and testing of ml models in the wild.arXiv preprint arXiv:1906.02569, 2019. 12
work page Pith review arXiv 1906
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hin- ton. Layer normalization.arXiv preprint arXiv:1607.06450,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Opensurfaces: A richly annotated catalog of surface appear- ance
Sean Bell, Paul Upchurch, Noah Snavely, and Kavita Bala. Opensurfaces: A richly annotated catalog of surface appear- ance. InSIGGRAPH, 2013. 2, 5, 6, 7, 15
2013
-
[5]
Material recognition in the wild with the materials in context database
Sean Bell, Paul Upchurch, Noah Snavely, and Kavita Bala. Material recognition in the wild with the materials in context database. InCVPR, 2015. 1, 4, 15
2015
-
[6]
Roberto Calandra, Andrew Owens, Manu Upadhyaya, Wen- zhen Yuan, Justin Lin, Edward H Adelson, and Sergey Levine. The feeling of success: Does touch sensing help predict grasp outcomes?arXiv preprint arXiv:1710.05512,
-
[7]
Masked-attention mask transformer for universal image segmentation
Bowen Cheng, Ishan Misra, Alexander G Schwing, Alexan- der Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. InCVPR,
-
[8]
Touch100k: A large-scale touch-language-vision dataset for touch-centric multimodal representation.Infor- mation Fusion, 2025
Ning Cheng, Jinan Xu, Changhao Guan, Jing Gao, Weihao Wang, You Li, Fandong Meng, Jie Zhou, Bin Fang, and Wen- juan Han. Touch100k: A large-scale touch-language-vision dataset for touch-centric multimodal representation.Infor- mation Fusion, 2025. 16
2025
-
[9]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 4, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Mul- timodal visual-tactile representation learning through self- supervised contrastive pre-training
Vedant Dave, Fotios Lygerakis, and Elmar Rueckert. Mul- timodal visual-tactile representation learning through self- supervised contrastive pre-training. InICRA, 2024. 2, 16
2024
-
[11]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InCVPR, 2009. 5
2009
-
[12]
Tactile-augmented radiance fields
Yiming Dou, Fengyu Yang, Yi Liu, Antonio Loquercio, and Andrew Owens. Tactile-augmented radiance fields. In CVPR, 2024. 2
2024
-
[13]
The pascal visual object classes challenge: A retrospective.IJCV,
Mark Everingham, SM Ali Eslami, Luc Van Gool, Christo- pher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes challenge: A retrospective.IJCV,
-
[14]
A touch, vision, and language dataset for multimodal align- ment
Letian Fu, Gaurav Datta, Huang Huang, William Chung-Ho Panitch, Jaimyn Drake, Joseph Ortiz, Mustafa Mukadam, Mike Lambeta, Roberto Calandra, and Ken Goldberg. A touch, vision, and language dataset for multimodal align- ment. InICML, 2024. 2, 5, 6, 8
2024
-
[15]
Ob- jectfolder 2.0: A multisensory object dataset for sim2real transfer
Ruohan Gao, Zilin Si, Yen-Yu Chang, Samuel Clarke, Jean- nette Bohg, Li Fei-Fei, Wenzhen Yuan, and Jiajun Wu. Ob- jectfolder 2.0: A multisensory object dataset for sim2real transfer. InCVPR, 2022. 5
2022
-
[16]
The ob- jectfolder benchmark: Multisensory learning with neural and real objects
Ruohan Gao, Yiming Dou, Hao Li, Tanmay Agarwal, Jean- nette Bohg, Yunzhu Li, Li Fei-Fei, and Jiajun Wu. The ob- jectfolder benchmark: Multisensory learning with neural and real objects. InCVPR, 2023. 5
2023
-
[17]
Imagebind: One embedding space to bind them all
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind: One embedding space to bind them all. InCVPR, 2023. 2
2023
-
[18]
The represen- tation of extrapersonal space: A possible role for bimodal, visual-tactile neurons
Michael SA Graziano and Charles G Gross. The represen- tation of extrapersonal space: A possible role for bimodal, visual-tactile neurons. 1995. 1
1995
-
[19]
Cagri Gungor, Derek Eppinger, and Adriana Kovashka. To- wards generalization of tactile image generation: Reference- free evaluation in a leakage-free setting.arXiv preprint arXiv:2503.06860, 2025. 2, 11
-
[20]
Separating the” chirp” from the” chat”: Self-supervised visual grounding of sound and language
Mark Hamilton, Andrew Zisserman, John R Hershey, and William T Freeman. Separating the” chirp” from the” chat”: Self-supervised visual grounding of sound and language. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 13117–13127, 2024. 6
2024
-
[21]
Cvat: Computer vision annotation tool
Intel Corporation. Cvat: Computer vision annotation tool. https://www.cvat.ai/, 2025. 5
2025
-
[22]
Justin Kerr, Huang Huang, Albert Wilcox, Ryan Hoque, Jef- frey Ichnowski, Roberto Calandra, and Ken Goldberg. Self- supervised visuo-tactile pretraining to locate and follow gar- ment features.arXiv preprint arXiv:2209.13042, 2022. 2, 5
-
[23]
Segment any- thing
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InICCV, 2023. 5
2023
-
[24]
Vit-lens: Towards omni-modal representations
Weixian Lei, Yixiao Ge, Kun Yi, Jianfeng Zhang, Difei Gao, Dylan Sun, Yuying Ge, Ying Shan, and Mike Zheng Shou. Vit-lens: Towards omni-modal representations. InCVPR,
-
[25]
Connecting touch and vision via cross-modal predic- tion
Yunzhu Li, Jun-Yan Zhu, Russ Tedrake, and Antonio Tor- ralba. Connecting touch and vision via cross-modal predic- tion. InCVPR, 2019. 5
2019
-
[26]
Image segmentation using text and image prompts
Timo L ¨uddecke and Alexander Ecker. Image segmentation using text and image prompts. InCVPR, 2022. 6 9
2022
-
[27]
Yuanhuiyi Lyu, Xu Zheng, Dahun Kim, and Lin Wang. Om- nibind: Teach to build unequal-scale modality interaction for omni-bind of all.arXiv preprint arXiv:2405.16108, 2024. 16
-
[28]
Localizing visual sounds the easy way
Shentong Mo and Pedro Morgado. Localizing visual sounds the easy way. InEuropean Conference on Computer Vision, pages 218–234. Springer, 2022. 3
2022
-
[29]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InICML, 2021. 3, 5
2021
-
[30]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded sam: Assembling open-world models for diverse visual tasks.arXiv preprint arXiv:2401.14159,
work page internal anchor Pith review arXiv
-
[31]
Imagenet large scale visual recognition challenge.IJCV, 2015
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, San- jeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge.IJCV, 2015. 5
2015
-
[32]
Seeing speech and sound: Distinguishing and lo- cating audio sources in visual scenes
Hyeonggon Ryu, Seongyu Kim, Joon Son Chung, and Arda Senocak. Seeing speech and sound: Distinguishing and lo- cating audio sources in visual scenes. InCVPR, 2025. 3, 6
2025
-
[33]
Sound source local- ization is all about cross-modal alignment
Arda Senocak, Hyeonggon Ryu, Junsik Kim, Tae-Hyun Oh, Hanspeter Pfister, and Joon Son Chung. Sound source local- ization is all about cross-modal alignment. InProceedings of the IEEE/CVF international conference on computer vision, pages 7777–7787, 2023. 3
2023
-
[34]
Toward interac- tive sound source localization: Better align sight and sound! IEEE TPAMI, 2025
Arda Senocak, Hyeonggon Ryu, Junsik Kim, Tae-Hyun Oh, Hanspeter Pfister, and Joon Son Chung. Toward interac- tive sound source localization: Better align sight and sound! IEEE TPAMI, 2025. 7
2025
-
[35]
Materialistic: Se- lecting similar materials in images
Prafull Sharma, Julien Philip, Micha ¨el Gharbi, Bill Freeman, Fredo Durand, and Valentin Deschaintre. Materialistic: Se- lecting similar materials in images. InSIGGRAPH, 2023. 1, 3, 6, 8
2023
-
[36]
Oriane Sim ´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025. 5, 6, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
The development of em- bodied cognition: Six lessons from babies.Artificial life,
Linda Smith and Michael Gasser. The development of em- bodied cognition: Six lessons from babies.Artificial life,
-
[38]
A dense material segmenta- tion dataset for indoor and outdoor scene parsing
Paul Upchurch and Ransen Niu. A dense material segmenta- tion dataset for indoor and outdoor scene parsing. InECCV,
-
[39]
Mapillary street-level sequences: A dataset for lifelong place recognition
Frederik Warburg, Soren Hauberg, Manuel Lopez- Antequera, Pau Gargallo, Yubin Kuang, and Javier Civera. Mapillary street-level sequences: A dataset for lifelong place recognition. InCVPR, 2020. 5
2020
-
[40]
Un- supervised feature learning via non-parametric instance-level discrimination
Zhirong Wu, Yuanjun Xiong, Stella Yu, and Dahua Lin. Un- supervised feature learning via non-parametric instance-level discrimination. InCVPR, 2018. 3
2018
-
[41]
Segmenting transparent ob- jects in the wild
Enze Xie, Wenjia Wang, Wenhai Wang, Mingyu Ding, Chunhua Shen, and Ping Luo. Segmenting transparent ob- jects in the wild. InECCV, 2020. 17
2020
-
[42]
Touch and go: Learn- ing from human-collected vision and touch
Fengyu Yang, Chenyang Ma, Jiacheng Zhang, Jing Zhu, Wenzhen Yuan, and Andrew Owens. Touch and go: Learn- ing from human-collected vision and touch. InNeurIPS - Datasets and Benchmarks Track, 2022. 2, 3, 4, 5, 11, 16
2022
-
[43]
Binding touch to every- thing: Learning unified multimodal tactile representations
Fengyu Yang, Chao Feng, Ziyang Chen, Hyoungseob Park, Daniel Wang, Yiming Dou, Ziyao Zeng, Xien Chen, Rit Gan- gopadhyay, Andrew Owens, et al. Binding touch to every- thing: Learning unified multimodal tactile representations. InCVPR, 2024. 2, 3, 16
2024
-
[44]
Gel- sight: High-resolution robot tactile sensors for estimating ge- ometry and force.Sensors, 2017
Wenzhen Yuan, Siyuan Dong, and Edward H Adelson. Gel- sight: High-resolution robot tactile sensors for estimating ge- ometry and force.Sensors, 2017. 7
2017
-
[45]
Connecting look and feel: Associating the visual and tactile properties of physical materials
Wenzhen Yuan, Shaoxiong Wang, Siyuan Dong, and Edward Adelson. Connecting look and feel: Associating the visual and tactile properties of physical materials. InCVPR, 2017. 2
2017
-
[46]
Learning rich touch representa- tions through cross-modal self-supervision
Martina Zambelli, Yusuf Aytar, Francesco Visin, Yuxiang Zhou, and Raia Hadsell. Learning rich touch representa- tions through cross-modal self-supervision. InConference on Robot Learning, 2021. 2
2021
-
[47]
Jialiang Zhao, Yuxiang Ma, Lirui Wang, and Edward H Adelson. Transferable tactile transformers for representa- tion learning across diverse sensors and tasks.arXiv preprint arXiv:2406.13640, 2024. 16 10 Seeing Through Touch: Tactile-Driven Visual Localization of Material Regions Supplementary Material The contents in this supplementary material are as fol...
-
[48]
Implementation Details
-
[49]
Details on Evaluation
-
[50]
Comparison with Cascaded System
-
[51]
Material Classification on the Original Split
-
[52]
Ablation on Tactile Backbone
-
[53]
Additional Qualitative Results
-
[54]
Inconclusive
Clarifying Touch Instances in Touch-and-Go The Touch-and-Go (TG) [42] dataset consists of approxi- mately 246k visuo-tactile image pairs and 13.9k detected touches. The official split for visuo-tactile contrastive learn- ing is available on the official GitHub page and includes 91,982 training and 29,879 testing samples. This split ex- cludes samples labe...
-
[55]
Each object itself must be unique
Identify Objects: Generate a balanced set of 15–20 distinct objects characteristically made from the material {Category}. Each object itself must be unique
-
[56]
• Contexts may be reused across different objects if they naturally fit
Brainstorm Locations/Contexts: For each object, list 3 plausible and visually distinct locations or contexts. • Contexts may be reused across different objects if they naturally fit. Do not force all contexts to be unique. • Example: a Tile sink in a minimalist bathroom / in a trendy cafe / in an outdoor garden kitchen
-
[57]
in a rustic kitchen
Exclusion Rule: You will be provided with an existing keyword list. Do not repeat or generate any keyword that overlaps semantically or textually with this given list. • It is acceptable to reuse the same context phrases (e.g., “in a rustic kitchen”) as long as the object is new
-
[58]
{object} in a {location/context}
Combine and Format: Combine each object with its corresponding locations to create a final list of 60 new keywords. Keyword Style: The keywords must be natural, descriptive, and specific. Avoid overly generic terms. RULES • The final output must be a single line list of keywords. • Keywords must be separated by commas (,) in the format: keyword1, keyword2...
-
[59]
A close-up shot of{category}+{object}
Details on Our Web-Material Dataset 8.1. Dataset Construction 8.1.1. Image Collection For each tactile category in the TG dataset, we prompt an LLM [2] to generate richer queries beyond simple class names to obtain descriptive context queries, which are then used to retrieve relevant and diverse web images. Concept Query Generation.We generate concept que...
-
[60]
Figure 13 illustrates the data pairing strategies based on Touch Instance and Material Diversity, as proposed in Sections 3.2 and 3.3 of the main paper
Material Diversity-based Pairing We establish three pairing strategies by leveraging two datasets: Touch-and-Go, which consists of aligned visuo- tactile data, and Web-Material, a vision-only dataset captur- ing diverse visual contexts for corresponding material cate- gories. Figure 13 illustrates the data pairing strategies based on Touch Instance and Ma...
-
[61]
a photo of {Category}
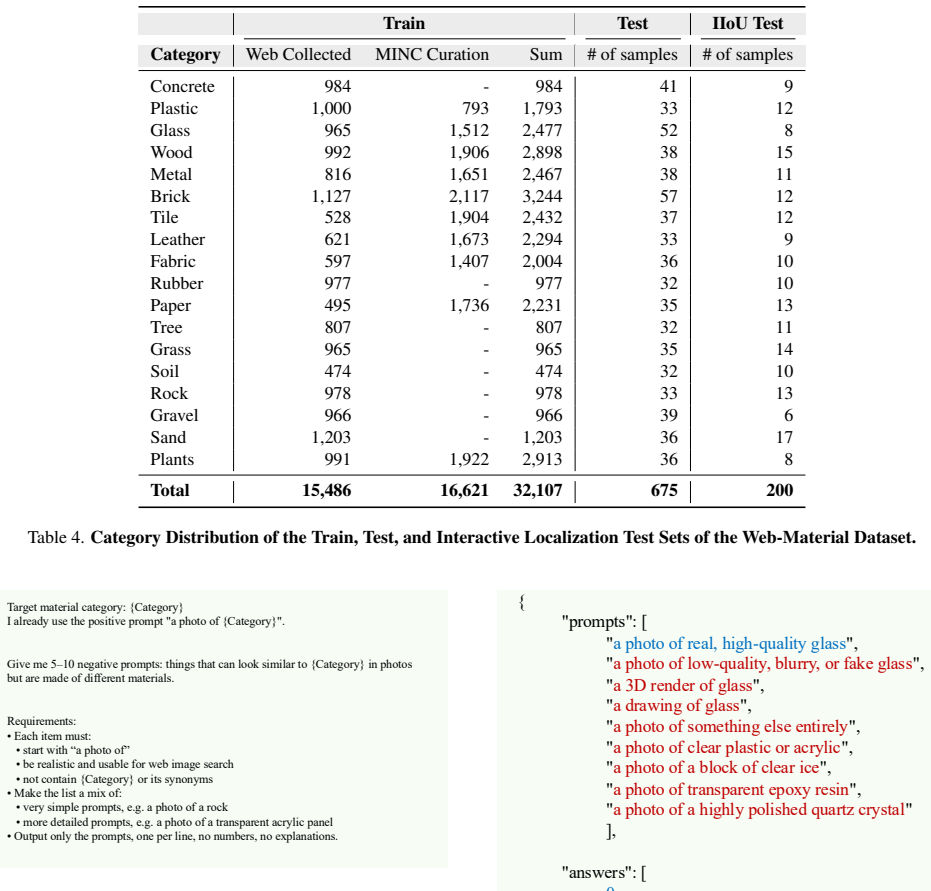
Implementation Details We train the model using the AdamW optimizer withβ= (0.9,0.95), a weight decay of0.05, and a base learning rate of1×10 −5, with an effective batch size of 64. Both en- 13 Train Test IIoU Test Category Web Collected MINC Curation Sum # of samples # of samples Concrete 984 - 984 41 9 Plastic 1,000 793 1,793 33 12 Glass 965 1,512 2,477...
-
[62]
Leather” T ouch Instance T ouch Instance … … Source“Metal
Details on Evaluation 11.1. Test Sets Touch-and-Go Dataset.As described in Section 7, the original TG dataset undergoes several refinement steps to remove any risk of information leakage. Afterward, Touch Instance chunks are extracted, and additional filtering is per- 14 T ouch-and-GoWeb-Material “Leather” T ouch Instance T ouch Instance … … Source“Metal”...
-
[63]
Comparison with Cascaded System Model Method mIoU UniTouch + Grounded-SAM Cascaded 69.40 STTEnd-to-End 76.82 Ground-Truth + Grounded-SAMCascaded 77.22 Table 5.Comparison of Cascaded and End-to-End Methods. Table 5 compares our method with a cascaded baseline that first classifies the tactile input using UniTouch [43] and then feeds the predicted category ...
-
[64]
In Table 6, we report material classification results ob- tained by training and evaluating on the original Touch- and-Go train-test split for fair comparison
Material Classification on the Original Split Model Material (%) VT CMC [42] 54.7 MViTac [10] 57.6 UniTouch [43] 61.3 VIT-LENS-2 [24] 63.0 TLV-Link [8] 67.2 OmniBind [27] 67.45 STT 67.77 Table 6.Material Classification Linear Probing Accuracy. In Table 6, we report material classification results ob- tained by training and evaluating on the original Touch...
-
[65]
Since the tactile signals are captured by vision-based tactile sensors, we can initialize the tactile backbone with either tactile or vision-pretrained models
Ablation on Tactile Backbone Method TG-Test Web-Material OpenSurfaces mAP mIoU mAP mIoU mAP mIoU T3(Local) 66.83 68.23 47.79 39.22 27.74 24.95 STT(Local) 85.12 76.79 67.72 52.34 37.25 29.47 T3(Out-domain) 85.66 74.55 69.83 54.03 38.91 30.19 STT(Out-domain)87.56 76.82 77.43 60.94 48.06 36.73 Table 7.Ablation on Tactile Backbone. Since the tactile signals a...
-
[66]
In this supplemen- tary material, we provide a comprehensive visualization to further demonstrate the generalization capability and ro- bustness of our model
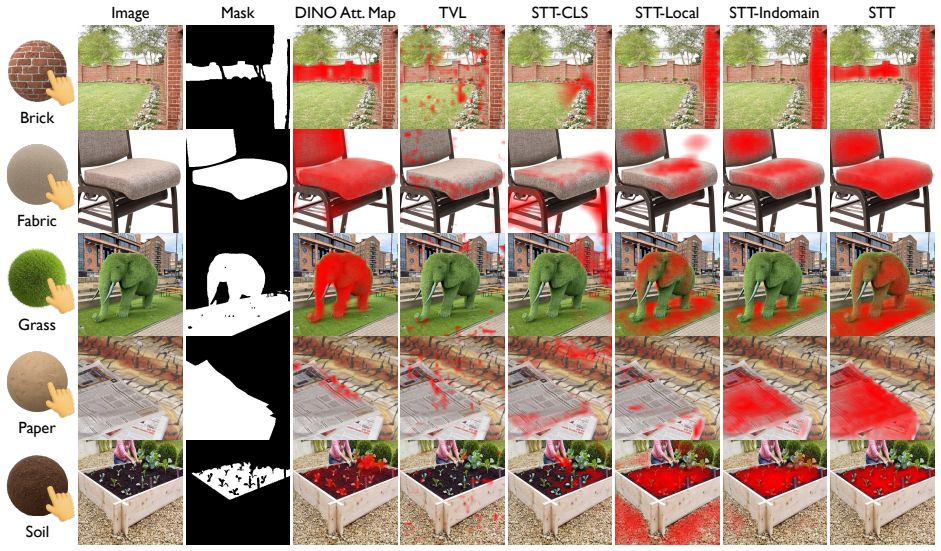
Additional Qualitative Results Due to space limitations in the main manuscript, we present a selected subset of qualitative results. In this supplemen- tary material, we provide a comprehensive visualization to further demonstrate the generalization capability and ro- bustness of our model. Localization Results on Test Sets.Figure 15, Figure 16, and Figur...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.