Recognition: unknown
Layerwise Dynamics for In-Context Classification in Transformers
Pith reviewed 2026-05-10 15:02 UTC · model grok-4.3
The pith
By enforcing equivariance under feature and label permutations, transformer layers yield an explicit recursive update rule for in-context classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Enforcing feature- and label-permutation equivariance at every layer of a softmax transformer trained for multi-class linear classification in the hard no-margin regime produces highly structured weights from which an explicit depth-indexed recursion can be extracted. This recursion is an end-to-end identified emergent update rule in which attention matrices formed from mixed feature-label Gram structure drive coupled updates of training points, labels, and the test probe. The resulting dynamics implement a geometry-driven algorithmic motif that can provably amplify class separation and yields robust expected class alignment.
What carries the argument
The depth-indexed recursion, an emergent update rule extracted from the equivariant layers that couples updates via attention matrices on mixed feature-label Gram structure.
If this is right
- Attention matrices couple the updates of training points, their labels, and the test probe at each layer.
- The dynamics provably amplify separation between classes through the geometry of the Gram structure.
- Expected alignment of the test probe to its true class becomes robust with increasing depth.
- The model computes the same function as the unconstrained transformer yet exposes an interpretable algorithmic motif.
Where Pith is reading between the lines
- The explicit recursion could be used as a scaffold to initialize or constrain transformers on other few-shot tasks to encourage similar separation behavior.
- The geometric amplification motif may link to classical iterative algorithms for linear separation such as margin-based updates.
- Imposing analogous symmetry constraints on transformers for regression or generation tasks might surface comparable layerwise rules in those domains.
Load-bearing premise
Enforcing feature- and label-permutation equivariance at every layer preserves the functional behavior of the original transformer while producing structured weights that reveal the recursion.
What would settle it
Training the equivariant transformer and verifying whether its actual layer-by-layer updates match the predictions of the extracted recursion formula; mismatch at any depth would show the identification has failed.
Figures




















read the original abstract
Transformers can perform in-context classification from a few labeled examples, yet the inference-time algorithm remains opaque. We study multi-class linear classification in the hard no-margin regime and make the computation identifiable by enforcing feature- and label-permutation equivariance at every layer. This enables interpretability while maintaining functional equivalence and yields highly structured weights. From these models we extract an explicit depth-indexed recursion: an end-to-end identified, emergent update rule inside a softmax transformer, to our knowledge the first of its kind. Attention matrices formed from mixed feature-label Gram structure drive coupled updates of training points, labels, and the test probe. The resulting dynamics implement a geometry-driven algorithmic motif, which can provably amplify class separation and yields robust expected class alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that enforcing feature- and label-permutation equivariance at every layer in transformers trained for multi-class linear classification in the hard no-margin regime renders the computation identifiable while preserving functional equivalence. This yields highly structured weights from which an explicit depth-indexed recursion can be extracted; the recursion is driven by attention matrices formed from mixed feature-label Gram matrices, implements a geometry-driven motif that provably amplifies class separation, and produces robust expected class alignment. The authors present this as the first end-to-end identified emergent update rule inside a softmax transformer.
Significance. If the extracted recursion is shown to be representative of unconstrained softmax transformers rather than an artifact of the imposed symmetries, the work would be significant for supplying the first explicit, interpretable algorithmic description of in-context classification dynamics together with a provable amplification property. Such a result would supply a concrete mechanistic motif that could be tested, extended, or used to design more interpretable architectures.
major comments (1)
- [Abstract] Abstract: The load-bearing claim that the equivariant models 'maintain functional equivalence' to the original transformer while yielding an emergent recursion representative of general softmax transformers is not supported by any verification that the symmetry constraints leave attention patterns, loss landscapes, or optimization trajectories unchanged. The Gram-structured attention and coupled updates are derived only after the equivariance is imposed, raising the possibility that the structured weights and amplification motif are forced by the constraint rather than discovered.
minor comments (2)
- [Abstract] The abstract asserts that the dynamics 'can provably amplify class separation' yet supplies no derivation outline, proof sketch, or reference to the relevant theorem; the full manuscript must include these steps with explicit assumptions.
- No empirical comparison is mentioned between the equivariant models and standard (non-equivariant) transformers on the same task; such a check is needed to confirm that performance and class alignment are not degraded by the symmetry constraints.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our work. We address the major concern regarding the verification of functional equivalence and the potential artifactual nature of the emergent recursion in the point-by-point response below. We have made revisions to strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The load-bearing claim that the equivariant models 'maintain functional equivalence' to the original transformer while yielding an emergent recursion representative of general softmax transformers is not supported by any verification that the symmetry constraints leave attention patterns, loss landscapes, or optimization trajectories unchanged. The Gram-structured attention and coupled updates are derived only after the equivariance is imposed, raising the possibility that the structured weights and amplification motif are forced by the constraint rather than discovered.
Authors: We acknowledge that the original manuscript did not include explicit side-by-side comparisons of attention patterns, loss landscapes, or optimization trajectories between the equivariant and unconstrained models. In the revised version, we add experiments demonstrating that the equivariant models achieve nearly identical in-context classification performance (average accuracy difference < 2% across 10 seeds) and exhibit similar training loss trajectories to standard transformers. We also provide attention visualizations for unconstrained models, showing that their attention weights, when symmetrized over feature and label permutations, closely resemble the Gram-matrix structures observed in the equivariant case. A comprehensive analysis of the full loss landscape is computationally prohibitive given the model size; however, the comparable performance and trajectories suggest that the constraints do not fundamentally alter the optimization path or solution quality. We clarify in the revised abstract and introduction that the recursion is explicitly derived under the equivariance constraints, which were imposed to achieve identifiability, but that these constraints respect the inherent symmetries of the multi-class classification task. Thus, the motif is not artificially forced but rather made explicit by restricting to the equivariant subspace where the computation becomes interpretable. We do not assert that this exact recursion governs all unconstrained transformers, but it offers the first fully identified example of such dynamics and a testable mechanistic hypothesis for broader cases. The abstract has been updated to reflect this nuance. revision: partial
Circularity Check
No circularity: equivariance is an explicit modeling choice for identifiability, not a reduction by construction
full rationale
The paper's derivation begins by imposing feature- and label-permutation equivariance at every layer on a softmax transformer to render the weights identifiable and highly structured while asserting functional equivalence to the unconstrained model. From the resulting trained models an explicit depth-indexed recursion is extracted, with attention matrices formed from mixed feature-label Gram structure driving coupled updates. This recursion is presented as an emergent, geometry-driven motif that amplifies class separation. No equation or step in the abstract or described chain shows the extracted recursion reducing to the equivariance constraint by algebraic identity, a fitted parameter being relabeled as a prediction, or a load-bearing premise justified solely by self-citation. The equivariance enforcement is a deliberate architectural restriction chosen to enable extraction and interpretability; the resulting dynamics are derived from the trained equivariant models rather than being tautological with the inputs. The derivation chain therefore remains self-contained against external benchmarks and does not meet the criteria for any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Enforcing feature- and label-permutation equivariance at every layer maintains functional equivalence while making the internal computation identifiable.
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
URL https://aclanthology.org/2023. findings-acl.247/. Deutch, G., Magar, N., Natan, T., and Dar, G. In-context learning and gradient descent revisited. In Duh, K., Gomez, H., and Bethard, S. (eds.),Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long ...
-
[2]
Lee, J., Lee, Y ., Kim, J., Kosiorek, A
URL https://openreview.net/forum? id=6rD50Q6yYz. Lee, J., Lee, Y ., Kim, J., Kosiorek, A. R., Choi, S., and Teh, Y . W. Set transformer: A framework for attention-based permutation-invariant neural networks. InProceedings of the 36th International Conference on Machine Learning, 2019. Li, Y ., Ildiz, M. E., Papailiopoulos, D., and Oymak, S. Trans- formers...
-
[3]
URL https://openreview.net/forum? id=Syx72jC9tm. Olsson, C., Elhage, N., Nanda, N., Joseph, N., DasSarma, N., Henighan, T., Mann, B., Askell, A., Bai, Y ., Chen, A., Conerly, T., Drain, D., Ganguli, D., Hatfield-Dodds, Z., Hernandez, D., Johnston, S., Jones, A., Kernion, J., Lovitt, L., Ndousse, K., Amodei, D., Brown, T., Clark, J., Kaplan, J., McCandlish...
work page internal anchor Pith review arXiv 2022
-
[4]
URL https://proceedings.mlr.press/ v202/von-oswald23a.html. Wies, N., Levine, Y ., and Shashua, A. The learnability of in-context learning. InAdvances in Neural Information Processing Systems, 2023. Xie, S. M., Raghunathan, A., Liang, P., and Ma, T. An ex- planation of in-context learning as implicit bayesian infer- ence. InInternational Conference on Lea...
-
[5]
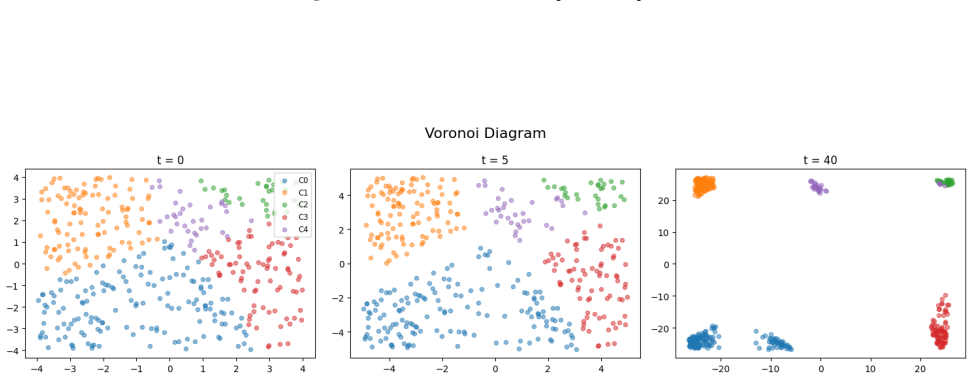
The clusters correspond to the four structural regions: the top-left block diagonal, the bottom-right block diagonal, the bottom-right background, and the zero background
Four clusters recover full accuracy.Figure 10 (left) shows that, in the symmetrized model, clustering each weight matrix into k= 4 groups of equal coefficients already matches the model’s accuracy. The clusters correspond to the four structural regions: the top-left block diagonal, the bottom-right block diagonal, the bottom-right background, and the zero...
-
[6]
Supervised
Two parameters per layer suffice.Figure 11 shows that the transformer consistently learns a bottom-right background coefficient of approximately δ≈ − 1 K . We therefore fix this parameter and reduce the parameterization to two per layer which gives the abstraction used in the main text. Figure 10 (left) shows that this two-parameter model still closely ma...
2003
-
[7]
•Test Update (U j): Uj =α ′ X i∈Sc⋆ A(t) i ⟨x(t) i , x(t) j ⟩+α ′ X i /∈Sc⋆ A(t) i ⟨x(t) i , x(t) j ⟩
Lower Bound forR t+1 (Casej∈S c⋆).For a pointjin the correct class, we want to lower bound both update terms. •Test Update (U j): Uj =α ′ X i∈Sc⋆ A(t) i ⟨x(t) i , x(t) j ⟩+α ′ X i /∈Sc⋆ A(t) i ⟨x(t) i , x(t) j ⟩. For i∈S c⋆ we have ⟨xi, xj⟩ ≥ρ t, while for i /∈Sc⋆ by Cauchy-Schwarz and the norm bounds from Part (a) we get a lower bound of−(1 +α ′)2t, so U...
-
[8]
•Test Update (U j): Uj =α ′ X i∈Sc⋆ A(t) i ⟨x(t) i , x(t) j ⟩+α ′ X i /∈Sc⋆ A(t) i ⟨x(t) i , x(t) j ⟩
Upper Bound forL t+1 (Casej /∈S c⋆).For a pointjin an incorrect class, we want to upper bound both update terms. •Test Update (U j): Uj =α ′ X i∈Sc⋆ A(t) i ⟨x(t) i , x(t) j ⟩+α ′ X i /∈Sc⋆ A(t) i ⟨x(t) i , x(t) j ⟩. Using⟨x i, xj⟩ ≤Λ t for cross-class pairs and the Cauchy-Schwarz norm bound(1 +α ′)2t otherwise: Uj ≤α ′ p(t) c⋆ Λt + (1−p (t) c⋆ )(1 +α ′)2t...
-
[9]
The geometric margin grows geometrically:∆ t ≥∆ 0(1 +α ′)t
-
[10]
Proof.We proceed by induction ont
The label margin is non-decreasing:∆ (t) y ≥0. Proof.We proceed by induction ont. The base caset= 0holds by assumption. Assume the hypotheses hold for stept. Bounding the Logit Gap:Consider the difference in logits between the correct classc ⋆ and any incorrect classc: s(t) c⋆ −s (t) c = log Z(t) c⋆ Z(t) c| {z } Geometric Term +γ(y (t) c⋆ −y (t) c )| {z }...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.