Recognition: unknown
ViLL-E: Video LLM Embeddings for Retrieval
Pith reviewed 2026-05-10 14:55 UTC · model grok-4.3
The pith
ViLL-E adds a flexible embedding mechanism to VideoLLMs so they match specialized retrieval models and gain zero-shot search skills.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
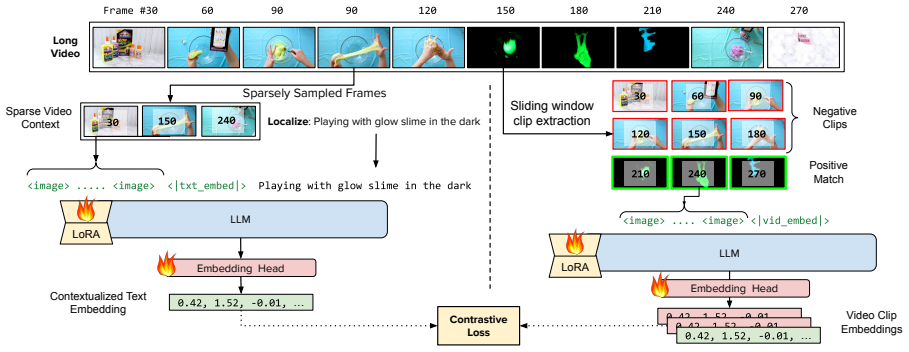
ViLL-E is a unified VideoLLM architecture with a novel embedding generation mechanism that allows the model to think longer for complex videos and stop early for easy ones. Trained via three-stage joint contrastive-generative learning on video-caption pairs, detailed captions, and a multi-task dataset, the model improves temporal localization by an average of 7 percent over other VideoLLMs, video retrieval by up to 4 percent over dual-encoder models, and reaches performance comparable to state-of-the-art specialized embedding models while staying competitive on VideoQA. The same training unlocks zero-shot composed video retrieval that beats prior methods by 5 percent and long-text retrieval
What carries the argument
The novel embedding generation mechanism that lets the model continue processing a video until it is ready to output an embedding vector.
If this is right
- Temporal localization accuracy rises by about 7 percent on average compared with other VideoLLMs.
- Video retrieval scores improve by as much as 4 percent over dual-encoder baselines and reach levels close to specialized embedding models.
- Zero-shot composed video retrieval exceeds prior state-of-the-art by 5 percent.
- Zero-shot retrieval from long text descriptions exceeds prior state-of-the-art by 2 percent.
- Video question-answering performance stays competitive with dedicated models.
Where Pith is reading between the lines
- One model could replace separate pipelines for video search and video understanding in practical systems.
- The same flexible processing idea might extend to audio or multimodal retrieval if the early-stopping logic generalizes.
- The three-stage schedule offers a reusable pattern for turning other large language models into strong embedding generators.
- If the mechanism scales, longer untrimmed videos could be handled without linear growth in compute per video.
Load-bearing premise
The three-stage training schedule together with the flexible embedding mechanism will produce the reported gains on new videos and tasks without overfitting to the chosen training and test sets.
What would settle it
Running the model on a fresh video retrieval benchmark drawn from sources never seen during any training stage and finding no gain over standard VideoLLMs or dual encoders would show the improvements do not generalize.
Figures










read the original abstract
Video Large Language Models (VideoLLMs) excel at video understanding tasks where outputs are textual, such as Video Question Answering and Video Captioning. However, they underperform specialized embedding-based models in Retrieval tasks, such as Text-toVideo Retrieval and Moment Retrieval. We introduce ViLL-E (Video-LLM-Embed), a unified VideoLLM architecture endowed with a novel embedding generation mechanism that allows the model to "think longer" for complex videos and stop early for easy ones. We train this model with a three-stage training methodology combining generative and contrastive learning: initial large-scale pre-training with video-caption pairs; followed by continual training on a smaller, detailed-caption dataset; and concluding with task-specific fine-tuning on a novel multi-task dataset covering Video QA, Temporal Localization, Video Retrieval, and Video-Text Matching. Our model significantly improves temporal localization (on avg. 7% over other VideoLLMs) and video retrieval (up to 4% over dual encoder models), achieving performance comparable to state-of-the-art specialized embedding models while remaining competitive on VideoQA tasks. Furthermore, our joint contrastive-generative training unlocks new zero-shot capabilities, significantly outperforming state-of-the-art methods in composed video retrieval (+5% over SotA) and retrieval from long text (+2% over SotA).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ViLL-E, a unified VideoLLM architecture with a novel adaptive embedding generation mechanism that permits the model to 'think longer' on complex videos and stop early on simple ones. It is trained via a three-stage pipeline (large-scale video-caption pre-training, detailed-caption continual training, and multi-task fine-tuning on VideoQA, temporal localization, retrieval, and matching) that combines generative and contrastive objectives. The authors report average 7% gains in temporal localization over other VideoLLMs, up to 4% gains in video retrieval over dual-encoder baselines, performance comparable to specialized embedding models, competitive VideoQA results, and new zero-shot capabilities in composed video retrieval (+5% over SotA) and long-text retrieval (+2% over SotA).
Significance. If the gains are shown to be robust and specifically attributable to the adaptive embedding mechanism rather than training volume alone, the work would be significant for unifying generative and retrieval capabilities in a single VideoLLM. The joint contrastive-generative training and variable-length thinking approach could reduce reliance on separate specialized models while enabling new zero-shot behaviors.
major comments (2)
- [Experiments section (Tables reporting main results and any ablation tables)] The central claims attribute the 7% temporal localization and 4% retrieval improvements (plus new zero-shot capabilities) to the combination of the adaptive 'think longer' embedding mechanism and the three-stage training. However, no ablation is presented that holds the training data, stages, and objectives fixed while removing or replacing the variable-length embedding mechanism with a standard fixed-length VideoLLM baseline. This control is load-bearing for the novelty and attribution claims in the abstract and experiments.
- [Abstract] The abstract states 'on avg. 7%' improvement and 'up to 4%' without specifying the exact metrics (e.g., R@1, mAP), number of datasets averaged, number of runs, or statistical significance. These details are required to assess whether the reported margins are reliable and generalizable.
minor comments (2)
- [Method section] Clarify the precise stopping criterion and implementation details of the adaptive embedding length (e.g., any learned threshold or entropy-based rule) so that the mechanism can be reproduced.
- [Experiments section] Add error bars or standard deviations to all quantitative tables and figures to support the percentage improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point-by-point below, indicating where revisions will be made to strengthen the paper's clarity and attribution of results.
read point-by-point responses
-
Referee: [Experiments section (Tables reporting main results and any ablation tables)] The central claims attribute the 7% temporal localization and 4% retrieval improvements (plus new zero-shot capabilities) to the combination of the adaptive 'think longer' embedding mechanism and the three-stage training. However, no ablation is presented that holds the training data, stages, and objectives fixed while removing or replacing the variable-length embedding mechanism with a standard fixed-length VideoLLM baseline. This control is load-bearing for the novelty and attribution claims in the abstract and experiments.
Authors: We agree that an ablation isolating the adaptive embedding mechanism while holding the training data, stages, and objectives fixed is necessary to robustly attribute the gains. In the revised manuscript, we will add this controlled comparison by training and evaluating a fixed-length VideoLLM baseline under the identical three-stage pipeline and report the results alongside the main tables in the Experiments section. This will directly address the load-bearing nature of the claim. revision: yes
-
Referee: [Abstract] The abstract states 'on avg. 7%' improvement and 'up to 4%' without specifying the exact metrics (e.g., R@1, mAP), number of datasets averaged, number of runs, or statistical significance. These details are required to assess whether the reported margins are reliable and generalizable.
Authors: We acknowledge the need for greater precision in the abstract. We will revise it to explicitly state the metrics (e.g., average mAP for temporal localization across the evaluated datasets and R@1 for retrieval), the number of datasets over which the averages are computed, and note that results are from single runs given the computational demands of VideoLLM training. We will also clarify the absence of statistical significance testing. revision: yes
Circularity Check
No circularity: empirical architecture and training claims with no derivation chain
full rationale
The paper introduces an architecture (adaptive embedding generation allowing variable 'thinking' time) and a three-stage training pipeline (pre-training, continual training, multi-task fine-tuning), then reports empirical gains on retrieval, localization, and zero-shot tasks. No equations, first-principles derivations, or predictions are described that could reduce to inputs by construction. Performance numbers are presented as experimental outcomes rather than derived quantities. Any self-citations (if present in full text) are not invoked to justify uniqueness theorems or ansatzes that would create load-bearing circularity. The central claims rest on comparative benchmarks, not on self-referential definitions or fitted parameters renamed as predictions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lisa Anne Hendricks, Oliver Wang, Eli Shechtman, Josef Sivic, Trevor Darrell, and Bryan Russell. 2017. Localizing moments in video with natural language. InProceedings of the IEEE international conference on computer vision, pages 5803–5812
2017
-
[2]
Anonymous. 2024. Auroracap: Efficient, performant video detailed captioning and a new benchmark. InSubmitted to The Thirteenth International Conference on Learning Representations. Under review
2024
-
[3]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jin- gren Zhou. 2023. Qwen-vl: A frontier large vision- language model with versatile abilities.arXiv preprint arXiv:2308.12966
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Max Bain, Arsha Nagrani, Gül Varol, and Andrew Zis- serman. 2021. Frozen in time: A joint video and image encoder for end-to-end retrieval. InIEEE International Conference on Computer Vision
2021
-
[5]
Gedas Bertasius, Heng Wang, and Lorenzo Torresani. 2021. Is space-time attention all you need for video understand- ing? InICML, volume 2, page 4
2021
-
[6]
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexan- der Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, and 1 others. 2024. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726
work page internal anchor Pith review arXiv 2024
-
[7]
Tom B Brown. 2020. Language models are few-shot learn- ers.arXiv preprint arXiv:2005.14165
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[8]
Dongsheng Chen, Chaofan Tao, Lu Hou, Lifeng Shang, Xin Jiang, and Qun Liu. 2022. Litevl: Efficient video-language learning with enhanced spatial-temporal modeling. InPro- ceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 7985–7997
2022
-
[9]
Feng Cheng, Xizi Wang, Jie Lei, David Crandall, Mohit Bansal, and Gedas Bertasius. 2023. Vindlu: A recipe for ef- fective video-and-language pretraining. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10739–10750
2023
-
[10]
Jiyang Gao, Chen Sun, Zhenheng Yang, and Ram Nevatia
-
[11]
InProceedings of the IEEE international conference on computer vision, pages 5267–5275
Tall: Temporal activity localization via language query. InProceedings of the IEEE international conference on computer vision, pages 5267–5275
-
[12]
Satya Krishna Gorti, Noël V ouitsis, Junwei Ma, Keyvan Golestan, Maksims V olkovs, Animesh Garg, and Guangwei Yu. 2022. X-pool: Cross-modal language-video attention for text-video retrieval. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5006–5015
2022
-
[13]
Bin Huang, Xin Wang, Hong Chen, Zihan Song, and Wenwu Zhu. 2024. Vtimellm: Empower llm to grasp video moments. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14271– 14280
2024
-
[14]
Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lam- ple, Lucile Saulnier, and 1 others. 2023. Mistral 7b.arXiv preprint arXiv:2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Ziyan Jiang, Rui Meng, Xinyi Yang, Semih Yavuz, Yingbo Zhou, and Wenhu Chen. 2025. VLM2vec: Train- ing vision-language models for massive multimodal em- bedding tasks. InThe Thirteenth International Conference on Learning Representations
2025
-
[16]
Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles. 2017. Dense-captioning events in videos. InProceedings of the IEEE international confer- ence on computer vision, pages 706–715
2017
-
[17]
Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. 2024. Nv-embed: Improved techniques for train- ing llms as generalist embedding models.arXiv preprint arXiv:2405.17428
work page internal anchor Pith review arXiv 2024
-
[18]
Jie Lei, Tamara L Berg, and Mohit Bansal. 2021. Detect- ing moments and highlights in videos via natural language queries.Advances in Neural Information Processing Sys- tems, 34:11846–11858
2021
- [19]
-
[20]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi
-
[21]
InInternational conference on machine learning, pages 19730–19742
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR
-
[22]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi
-
[23]
InInternational conference on machine learning, pages 12888–12900
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInternational conference on machine learning, pages 12888–12900. PMLR
-
[24]
KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao
-
[25]
Videochat: Chat-centric video understanding.arXiv preprint arXiv:2305.06355
work page internal anchor Pith review arXiv
-
[26]
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, and 1 others. 2024. Mvbench: A comprehensive multi-modal video understanding benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195–22206. 9
2024
-
[27]
Kunchang Li, Yali Wang, Yizhuo Li, Yi Wang, Yinan He, Limin Wang, and Yu Qiao. 2023. Unmasked teacher: Towards training-efficient video foundation models.2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 19891–19903
2023
-
[28]
Bin Lin, Bin Zhu, Yang Ye, Munan Ning, Peng Jin, and Li Yuan. 2023. Video-llava: Learning united visual repre- sentation by alignment before projection.arXiv preprint arXiv:2311.10122
work page internal anchor Pith review arXiv 2023
- [29]
-
[30]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2024. Visual instruction tuning.Advances in neural information processing systems, 36
2024
-
[31]
Xiaolong Liu, Qimeng Wang, Yao Hu, Xu Tang, Shiwei Zhang, Song Bai, and Xiang Bai. 2022. End-to-end tempo- ral action detection with transformer.IEEE Transactions on Image Processing, 31:5427–5441
2022
-
[32]
Huaishao Luo, Lei Ji, Ming Zhong, Yang Chen, Wen Lei, Nan Duan, and Tianrui Li. 2022. Clip4clip: An empir- ical study of clip for end to end video clip retrieval and captioning.Neurocomputing, 508:293–304
2022
-
[33]
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. 2023. Video-chatgpt: Towards de- tailed video understanding via large vision and language models.arXiv preprint arXiv:2306.05424
work page internal anchor Pith review arXiv 2023
-
[34]
WonJun Moon, Sangeek Hyun, SangUk Park, Dongchan Park, and Jae-Pil Heo. 2023. Query-dependent video rep- resentation for moment retrieval and highlight detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23023–23033
2023
- [35]
-
[36]
Long Qian, Juncheng Li, Yu Wu, Yaobo Ye, Hao Fei, Tat-Seng Chua, Yueting Zhuang, and Siliang Tang. 2024. Momentor: Advancing video large language model with fine-grained temporal reasoning. InForty-first Interna- tional Conference on Machine Learning
2024
-
[37]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, and 1 others
-
[38]
InInternational conference on machine learning, pages 8748–8763
Learning transferable visual models from natural lan- guage supervision. InInternational conference on machine learning, pages 8748–8763. PMLR
-
[39]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67
2020
-
[40]
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of the 2019 Conference on Empirical Meth- ods in Natural Language Processing and the 9th Inter- national Joint Conference on Natural Language Process- ing (EMNLP-IJCNLP), pages 3980–3990. Association for Computational Linguistics
2019
-
[41]
Shuhuai Ren, Linli Yao, Shicheng Li, Xu Sun, and Lu Hou
-
[42]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 14313–14323
Timechat: A time-sensitive multimodal large lan- guage model for long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 14313–14323
-
[43]
Mamshad Nayeem Rizve, Fan Fei, Jayakrishnan Unnikr- ishnan, Son Tran, Benjamin Z Yao, Belinda Zeng, Mubarak Shah, and Trishul Chilimbi. 2024. Vidla: Video-language alignment at scale. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 14043–14055
2024
-
[44]
Paul K Rubenstein, Chulayuth Asawaroengchai, Duc Dung Nguyen, Ankur Bapna, Zalán Borsos, Félix de Chaumont Quitry, Peter Chen, Dalia El Badawy, Wei Han, Eugene Kharitonov, and 1 others. 2023. Audiopalm: A large language model that can speak and listen.arXiv preprint arXiv:2306.12925
-
[45]
Hao Sun, Mingyao Zhou, Wenjing Chen, and Wei Xie
-
[46]
InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 4998–5007
Tr-detr: Task-reciprocal transformer for joint mo- ment retrieval and highlight detection. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 4998–5007
-
[47]
Shengbang Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Manoj Middepogu, Sai Charitha Akula, Jihan Yang, Shusheng Yang, Adithya Iyer, Xichen Pan, Austin Wang, Rob Fergus, Yann LeCun, and Saining Xie. 2024. Cambrian-1: A fully open, vision-centric exploration of multimodal llms.Preprint, arXiv:2406.16860
-
[48]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Bap- tiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, and 1 others. 2023. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Lucas Ventura, Antoine Yang, Cordelia Schmid, and Gül Varol. 2024. Covr: Learning composed video retrieval from web video captions. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 5270–5279
2024
-
[50]
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. 2022. Text embeddings by weakly-supervised con- trastive pre-training.arXiv preprint arXiv:2212.03533
work page internal anchor Pith review arXiv 2022
-
[51]
Xin Wang, Jiawei Wu, Junkun Chen, Lei Li, Yuan- Fang Wang, and William Yang Wang. 2019. Vatex: A large-scale, high-quality multilingual dataset for video-and- language research. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 4581–4591
2019
-
[52]
Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Guo Chen, Baoqi Pei, Rongkun Zheng, Zun Wang, Yansong Shi, and 1 others. 2024. Internvideo2: Scaling foundation models for multimodal video understanding. In European Conference on Computer Vision, pages 396–416. Springer
2024
- [53]
-
[54]
Dejing Xu, Zhou Zhao, Jun Xiao, Fei Wu, Hanwang Zhang, Xiangnan He, and Yueting Zhuang. 2017. Video question answering via gradually refined attention over ap- pearance and motion. InProceedings of the 25th ACM 10 International Conference on Multimedia, MM ’17, page 1645–1653, New York, NY , USA. Association for Comput- ing Machinery
2017
-
[55]
Hu Xu, Saining Xie, Xiaoqing Tan, Po-Yao Huang, Rus- sell Howes, Vasu Sharma, Shang-Wen Li, Gargi Ghosh, Luke Zettlemoyer, and Christoph Feichtenhofer. 2024. De- mystifying CLIP data. InThe Twelfth International Con- ference on Learning Representations
2024
-
[56]
Jun Xu, Tao Mei, Ting Yao, and Yong Rui. 2016. Msr- vtt: A large video description dataset for bridging video and language. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5288–5296
2016
-
[57]
Hongwei Xue, Yuchong Sun, Bei Liu, Jianlong Fu, Rui- hua Song, Houqiang Li, and Jiebo Luo. 2023. Clip-vip: Adapting pre-trained image-text model to video-language alignment. InThe Eleventh International Conference on Learning Representations
2023
-
[58]
Shen Yan, Xuehan Xiong, Arsha Nagrani, Anurag Arnab, Zhonghao Wang, Weina Ge, David Ross, and Cordelia Schmid. 2023. Unloc: A unified framework for video localization tasks. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 13623– 13633
2023
-
[59]
Antoine Yang, Arsha Nagrani, Paul Hongsuck Seo, An- toine Miech, Jordi Pont-Tuset, Ivan Laptev, Josef Sivic, and Cordelia Schmid. 2023. Vid2seq: Large-scale pretraining of a visual language model for dense video captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10714–10726
2023
-
[60]
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. 2023. Sigmoid loss for language image pre- training. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11975–11986
2023
-
[61]
Beichen Zhang, Pan Zhang, Xiaoyi Dong, Yuhang Zang, and Jiaqi Wang. 2025. Long-clip: Unlocking the long-text capability of clip. InComputer Vision – ECCV 2024, pages 310–325, Cham. Springer Nature Switzerland
2025
-
[62]
Chen-Lin Zhang, Jianxin Wu, and Yin Li. 2022. Action- former: Localizing moments of actions with transformers. InEuropean Conference on Computer Vision (ECCV)
2022
- [63]
-
[64]
Hang Zhang, Xin Li, and Lidong Bing. 2023. Video- llama: An instruction-tuned audio-visual language model for video understanding.arXiv preprint arXiv:2306.02858
work page internal anchor Pith review arXiv 2023
-
[65]
Xin Zhang, Yanzhao Zhang, Wen Xie, Mingxin Li, Ziqi Dai, Dingkun Long, Pengjun Xie, Meishan Zhang, Wenjie Li, and Min Zhang. 2024. Gme: Improving universal multimodal retrieval by multimodal llms.arXiv preprint arXiv:2412.16855
work page internal anchor Pith review arXiv 2024
-
[66]
thinks longer
Bin Zhu, Bin Lin, Munan Ning, Yang Yan, Jiaxi Cui, W ANG HongFa, Yatian Pang, Wenhao Jiang, Junwu Zhang, Zongwei Li, Cai Wan Zhang, Zhifeng Li, Wei Liu, and Li Yuan. 2024. Languagebind: Extending video-language pretraining to n-modality by language-based semantic alignment. InThe Twelfth International Conference on Learning Representations. 11 Overview of...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.