Recognition: unknown
Redefining Quality Criteria and Distance-Aware Score Modeling for Image Editing Assessment
Pith reviewed 2026-05-10 15:21 UTC · model grok-4.3
The pith
A framework automatically refines quality metrics for image edits and models score distances through probabilistic feedback and decoupled regression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
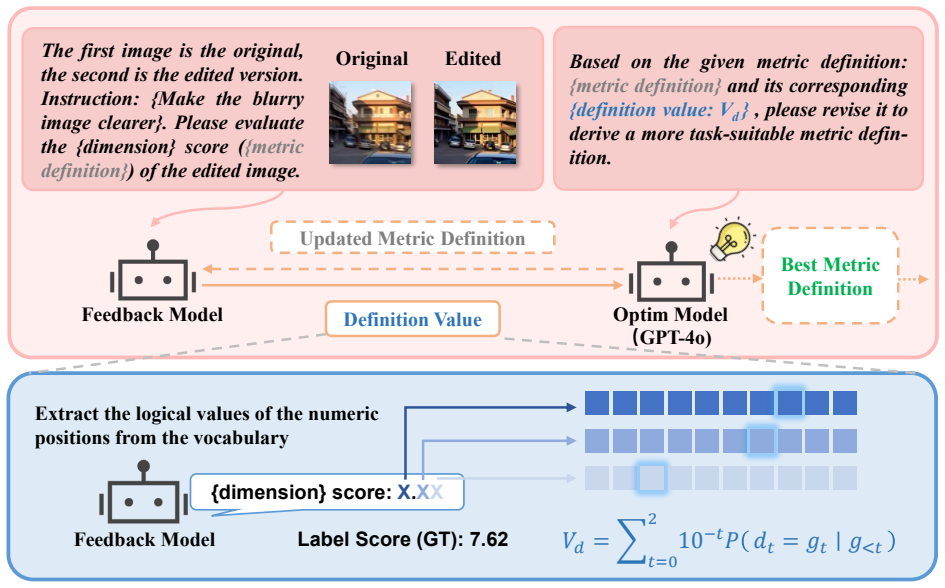
The paper claims that rigid metric prompting and distance-agnostic score modeling limit alignment with human criteria in image editing quality assessment. By introducing Feedback-Driven Metric Prompt Optimization to iteratively refine metric definitions from multimodal large language model probabilistic feedback and Token-Decoupled Distance Regression Loss to explicitly minimize expected score distances after decoupling numerical tokens, the unified DS-IEQA framework learns both evaluation criteria and score continuity in a single training process, yielding superior assessment performance.
What carries the argument
Feedback-Driven Metric Prompt Optimization (FDMPO) that iteratively updates metric prompts from probabilistic model outputs, paired with Token-Decoupled Distance Regression Loss (TDRL) that isolates numerical tokens to enforce continuous score modeling via expected-distance minimization.
If this is right
- Evaluation criteria become adaptive rather than fixed by human heuristics.
- Score predictions respect the continuous ordering and spacing of quality levels.
- Unified training of criteria definition and score regression improves overall assessment accuracy.
- Competitive ranking is achieved on image editing quality tracks without supplementary data.
- The method applies directly to multimodal inputs containing both original and edited images.
Where Pith is reading between the lines
- The same feedback loop for metric refinement could transfer to other subjective visual quality tasks such as video or 3-D rendering assessment.
- Distance-aware modeling may reduce inconsistencies when scores are aggregated across multiple evaluators or dimensions.
- Automatic criterion discovery lessens dependence on manually specified rubrics in broader AI evaluation pipelines.
- The token-decoupling technique might generalize to other regression problems embedded inside language-model outputs.
Load-bearing premise
Probabilistic feedback from the multimodal model produces metric definitions that match implicit human judgment standards, and the decoupled loss captures true score continuity without introducing new biases or overfitting.
What would settle it
Human ratings on a held-out set of edited images show no increase in correlation or ranking agreement with the new scores compared with rigid-prompt baselines, or the refined metrics diverge systematically from human descriptions of the same edits.
Figures


read the original abstract
Recent advances in image editing have heightened the need for reliable Image Editing Quality Assessment (IEQA). Unlike traditional methods, IEQA requires complex reasoning over multimodal inputs and multi-dimensional assessments. Existing MLLM-based approaches often rely on human heuristic prompting, leading to two key limitations: rigid metric prompting and distance-agnostic score modeling. These issues hinder alignment with implicit human criteria and fail to capture the continuous structure of score spaces. To address this, we propose Define-and-Score Image Editing Quality Assessment (DS-IEQA), a unified framework that jointly learns evaluation criteria and score representations. Specifically, we introduce Feedback-Driven Metric Prompt Optimization (FDMPO) to automatically refine metric definitions via probabilistic feedback. Furthermore, we propose Token-Decoupled Distance Regression Loss (TDRL), which decouples numerical tokens from language modeling to explicitly model score continuity through expected distance minimization. Extensive experiments show our method's superior performance; it ranks 4th in the 2026 NTIRE X-AIGC Quality Assessment Track 2 without any additional training data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Define-and-Score Image Editing Quality Assessment (DS-IEQA), a unified MLLM-based framework for Image Editing Quality Assessment (IEQA). It introduces Feedback-Driven Metric Prompt Optimization (FDMPO) to automatically refine metric definitions via probabilistic feedback from the model, and Token-Decoupled Distance Regression Loss (TDRL) to decouple numerical tokens from language modeling and explicitly capture continuous score structure through expected distance minimization. The central claim is that this joint learning of criteria and score representations overcomes rigid prompting and distance-agnostic modeling in prior MLLM approaches, yielding superior performance; the method ranks 4th in the 2026 NTIRE X-AIGC Quality Assessment Track 2 without any additional training data.
Significance. If the empirical claims hold, the work advances IEQA by automating the discovery of evaluation criteria and improving modeling of continuous scores, which could lead to better alignment with human judgments in assessing edited images. The data-efficient 4th-place competition result without extra training data is a notable strength, demonstrating practical applicability for generative AI pipelines. The approach builds on existing MLLM capabilities rather than introducing circular derivations, and the novel components (FDMPO and TDRL) address real limitations in current prompting-based methods.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): The central claim of superior performance and the 4th-place NTIRE ranking rests on 'extensive experiments,' yet the manuscript provides no baseline comparisons, ablation studies isolating FDMPO and TDRL, dataset details, quantitative tables, or statistical tests. This absence prevents verification of the outperformance and is load-bearing for the paper's main contribution.
- [§3.1] §3.1 (FDMPO): The Feedback-Driven Metric Prompt Optimization uses probabilistic feedback to refine metrics automatically; the exact procedure for generating and incorporating feedback, the stopping criteria, and safeguards against overfitting to model-specific biases or drifting from human criteria must be formalized with pseudocode or equations to confirm it genuinely learns implicit criteria rather than post-hoc fitting.
- [§3.2] §3.2 (TDRL): The Token-Decoupled Distance Regression Loss is defined to model score continuity by decoupling numerical tokens and minimizing expected distance; the precise loss formulation, how the expectation is computed over the token distribution, and its combination with the standard language modeling objective require explicit equations to verify it avoids introducing new discretization biases or overfitting to competition scores.
minor comments (2)
- All acronyms (MLLM, IEQA, FDMPO, TDRL, NTIRE) should be expanded on first use in the abstract and introduction for clarity.
- The title emphasizes 'Redefining Quality Criteria' but the abstract focuses on DS-IEQA; consider aligning the title more closely with the proposed framework name.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below, agreeing that additional details and formalizations are needed to support the claims. We will incorporate the requested elements in a revised manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The central claim of superior performance and the 4th-place NTIRE ranking rests on 'extensive experiments,' yet the manuscript provides no baseline comparisons, ablation studies, dataset details, quantitative tables, or statistical tests. This absence prevents verification of the outperformance and is load-bearing for the paper's main contribution.
Authors: We agree that the current version lacks sufficient experimental details to allow independent verification. In the revision, we will expand §4 with: (i) baseline comparisons against prior MLLM-based IEQA methods, (ii) ablation studies isolating FDMPO and TDRL, (iii) full dataset descriptions including the NTIRE X-AIGC Track 2 data splits and statistics, (iv) quantitative tables reporting all metrics, and (v) statistical significance tests (e.g., paired t-tests). The 4th-place ranking without extra training data provides external corroboration, but we recognize the need for transparent internal evidence. revision: yes
-
Referee: [§3.1] §3.1 (FDMPO): The Feedback-Driven Metric Prompt Optimization uses probabilistic feedback to refine metrics automatically; the exact procedure for generating and incorporating feedback, the stopping criteria, and safeguards against overfitting to model-specific biases or drifting from human criteria must be formalized with pseudocode or equations to confirm it genuinely learns implicit criteria rather than post-hoc fitting.
Authors: We acknowledge the need for greater formalization of FDMPO. The revised §3.1 will include: pseudocode for the full optimization loop, equations defining the probabilistic feedback generation and incorporation steps, explicit stopping criteria (e.g., convergence thresholds on metric stability or held-out validation), and safeguards such as bias-regularization terms and optional human validation checkpoints to ensure the learned criteria remain aligned with human judgments rather than model-specific artifacts. revision: yes
-
Referee: [§3.2] §3.2 (TDRL): The Token-Decoupled Distance Regression Loss is defined to model score continuity by decoupling numerical tokens and minimizing expected distance; the precise loss formulation, how the expectation is computed over the token distribution, and its combination with the standard language modeling objective require explicit equations to verify it avoids introducing new discretization biases or overfitting to competition scores.
Authors: We agree that the TDRL formulation requires explicit mathematical detail. The revised §3.2 will present: the complete loss equation showing token decoupling, the exact computation of the expected distance (via probability-weighted summation over numerical token logits), the combined training objective with the language-modeling loss (including the balancing hyperparameter), and a discussion of how the formulation mitigates discretization bias and competition-score overfitting. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's core contributions—FDMPO for refining metrics via probabilistic feedback and TDRL for token-decoupled regression—are introduced as novel extensions to existing MLLM capabilities rather than derivations that reduce to fitted parameters or self-defined quantities. Performance claims rest on external experiments and a competition ranking (4th in NTIRE Track 2 with no extra data), not on internal re-derivations or self-citation chains. No equations or steps equate predictions to inputs by construction, and the framework addresses stated limitations without smuggling ansatzes or renaming prior results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal large language models can supply reliable probabilistic feedback usable for iterative prompt refinement
invented entities (2)
-
Feedback-Driven Metric Prompt Optimization (FDMPO)
no independent evidence
-
Token-Decoupled Distance Regression Loss (TDRL)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Editval: Benchmarking diffusion based text-guided image editing methods
Samyadeep Basu, Mehrdad Saberi, Shweta Bhardwaj, Atoosa Malemir Chegini, Daniela Massiceti, Maziar San- jabi, Shell Xu Hu, and Soheil Feizi. Editval: Benchmarking diffusion based text-guided image editing methods.arXiv preprint arXiv:2310.02426, 2023. 1
-
[2]
Q-ponder: A unified train- ing pipeline for reasoning-based visual quality assessment,
Zhuoxuan Cai, Jian Zhang, Xinbin Yuan, Peng-Tao Jiang, Wenxiang Chen, Bowen Tang, Lujian Yao, Qiyuan Wang, Jinwen Chen, and Bo Li. Q-ponder: A unified train- ing pipeline for reasoning-based visual quality assessment,
-
[3]
M3-agiqa: multimodal, multi- round, multi-aspect ai-generated image quality assessment
Chuan Cui, Kejiang Chen, Zhihua Wei, Wen Shen, Weim- ing Zhang, and Nenghai Yu. M3-agiqa: multimodal, multi- round, multi-aspect ai-generated image quality assessment. arXiv preprint arXiv:2502.15167, 2025. 2
-
[4]
Zhen Han, Zeyinzi Jiang, Yulin Pan, Jingfeng Zhang, Chao- jie Mao, Chenwei Xie, Yu Liu, and Jingren Zhou. Ace: All- round creator and editor following instructions via diffusion transformer.arXiv preprint arXiv:2410.00086, 2024. 1
-
[5]
arXiv e-printsabs/2401.08276(2024) 16 T
Yipo Huang, Quan Yuan, Xiangfei Sheng, Zhichao Yang, Haoning Wu, Pengfei Chen, Yuzhe Yang, Leida Li, and Weisi Lin. Aesbench: An expert benchmark for multimodal large language models on image aesthetics perception.arXiv preprint arXiv:2401.08276, 2024. 2
-
[6]
Imagic: Text-based real image editing with diffusion models
Bahjat Kawar, Shiran Zada, Oran Lang, Omer Tov, Huiwen Chang, Tali Dekel, Inbar Mosseri, and Michal Irani. Imagic: Text-based real image editing with diffusion models. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6007–6017, 2023. 1
2023
-
[7]
Imagic: Text-based real image editing with diffusion models
Bahjat Kawar, Shiran Zada, Oran Lang, Omer Tov, Huiwen Chang, Tali Dekel, Inbar Mosseri, and Michal Irani. Imagic: Text-based real image editing with diffusion models. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6007–6017, 2023. 1
2023
-
[8]
Viescore: Towards explainable metrics for conditional image synthesis evaluation
Max Ku, Dongfu Jiang, Cong Wei, Xiang Yue, and Wenhu Chen. Viescore: Towards explainable metrics for conditional image synthesis evaluation. InProceedings of the 62nd An- nual Meeting of the Association for Computational Linguis- tics (Volume 1: Long Papers), pages 12268–12290, 2024. 1, 2, 3
2024
-
[9]
Prexme! large scale prompt exploration of open source llms for machine trans- lation and summarization evaluation
Christoph Leiter and Steffen Eger. Prexme! large scale prompt exploration of open source llms for machine trans- lation and summarization evaluation. InProceedings of the 2024 Conference on Empirical Methods in Natural Lan- guage Processing, pages 11481–11506, 2024. 3
2024
-
[10]
Text-visual semantic con- strained ai-generated image quality assessment
Qiang Li, Qingsen Yan, Haojian Huang, Peng Wu, Haokui Zhang, and Yanning Zhang. Text-visual semantic con- strained ai-generated image quality assessment. InProceed- ings of the 33rd ACM International Conference on Multime- dia, pages 6958–6966, 2025. 1
2025
-
[11]
Q-insight: Understanding image quality via visual reinforcement learning, 2025
Weiqi Li, Xuanyu Zhang, Shijie Zhao, Yabin Zhang, Junlin Li, Li Zhang, and Jian Zhang. Q-insight: Understanding image quality via visual reinforcement learning, 2025. 2
2025
-
[12]
Zhuoying Li, Zhu Xu, Yuxin Peng, and Yang Liu. Balancing preservation and modification: A region and semantic aware metric for instruction-based image editing.arXiv preprint arXiv:2506.13827, 2025. 1
-
[13]
NTIRE 2026 X- AIGC Quality Assessment Challenge: Methods and Results
Xiaohong Liu, Xiongkuo Min, Guangtao Zhai, Qiang Hu, Jiezhang Cao, Yu Zhou, Wei Sun, Farong Wen, Zitong Xu, Yingjie Zhou, Huiyu Duan, Lu Liu, Jiarui Wang, Siqi Luo, Chunyi Li, Li Xu, Zicheng Zhang, Yue Shi, Yubo Wang, Minghong Zhang, Chunchao Guo, Zhichao Hu, Mingtao Chen, Xiele Wu, Xin Ma, Zhaohe Lv, Yuanhao Xue, Jiaqi Wang, Xinxing Sha, Radu Timofte, et...
2026
-
[14]
Magicquill: An intelligent interactive image editing system
Zichen Liu, Yue Yu, Hao Ouyang, Qiuyu Wang, Ka Leong Cheng, Wen Wang, Zhiheng Liu, Qifeng Chen, and Yujun Shen. Magicquill: An intelligent interactive image editing system. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 13072–13082, 2025. 1
2025
-
[15]
Editscore: Unlocking online rl for image editing via high- fidelity reward modeling, 2026
Xin Luo, Jiahao Wang, Chenyuan Wu, Shitao Xiao, Xiyan Jiang, Defu Lian, Jiajun Zhang, Dong Liu, and Zheng liu. Editscore: Unlocking online rl for image editing via high- fidelity reward modeling, 2026. 6
2026
-
[16]
State of what art? a call for multi-prompt llm evaluation.Transactions of the As- sociation for Computational Linguistics, 12:933–949, 2024
Moran Mizrahi, Guy Kaplan, Dan Malkin, Rotem Dror, Dafna Shahaf, and Gabriel Stanovsky. State of what art? a call for multi-prompt llm evaluation.Transactions of the As- sociation for Computational Linguistics, 12:933–949, 2024. 3
2024
-
[17]
Evaluating the evaluator: Measur- ing llms’ adherence to task evaluation instructions
Bhuvanashree Murugadoss, Christian Poelitz, Ian Drosos, Vu Le, Nick McKenna, Carina Suzana Negreanu, Chris Parnin, and Advait Sarkar. Evaluating the evaluator: Measur- ing llms’ adherence to task evaluation instructions. InPro- ceedings of the AAAI Conference on Artificial Intelligence, pages 19589–19597, 2025. 3
2025
-
[18]
Towards scalable human-aligned bench- mark for text-guided image editing
Suho Ryu, Kihyun Kim, Eugene Baek, Dongsoo Shin, and Joonseok Lee. Towards scalable human-aligned bench- mark for text-guided image editing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18292–18301, 2025. 1, 3
2025
-
[19]
Re- iqa: Unsupervised learning for image quality assessment in the wild
Avinab Saha, Sandeep Mishra, and Alan C Bovik. Re- iqa: Unsupervised learning for image quality assessment in the wild. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5846–5855,
-
[20]
Surprisingly fragile: Assessing and addressing prompt instability in multimodal foundation models, 2025
Ian Stewart, Sameera Horawalavithana, Brendan Kennedy, Sai Munikoti, and Karl Pazdernik. Surprisingly fragile: Assessing and addressing prompt instability in multimodal foundation models, 2025. 1, 3
2025
-
[21]
Blindly assess image qual- ity in the wild guided by a self-adaptive hyper network
Shaolin Su, Qingsen Yan, Yu Zhu, Cheng Zhang, Xin Ge, Jinqiu Sun, and Yanning Zhang. Blindly assess image qual- ity in the wild guided by a self-adaptive hyper network. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 3667–3676, 2020. 1
2020
-
[22]
Revisiting mllm based image quality assessment: Errors and remedy.Proceedings of the AAAI Conference on Artificial Intelligence, 40(11):9475–9483, 2026
Zhenchen Tang, Songlin Yang, Bo Peng, Zichuan Wang, and Jing Dong. Revisiting mllm based image quality assessment: Errors and remedy.Proceedings of the AAAI Conference on Artificial Intelligence, 40(11):9475–9483, 2026. 2
2026
-
[23]
Revisiting mllm based image quality assessment: Errors and remedy
Zhenchen Tang, Songlin Yang, Bo Peng, Zichuan Wang, and Jing Dong. Revisiting mllm based image quality assessment: Errors and remedy. InProceedings of the AAAI Conference on Artificial Intelligence, pages 9475–9483, 2026. 2, 4
2026
-
[24]
Large multi-modality model assisted ai-generated image quality as- sessment
Puyi Wang, Wei Sun, Zicheng Zhang, Jun Jia, Yanwei Jiang, Zhichao Zhang, Xiongkuo Min, and Guangtao Zhai. Large multi-modality model assisted ai-generated image quality as- sessment. InProceedings of the 32nd ACM International Conference on Multimedia, pages 7803–7812, 2024. 1
2024
-
[25]
Genartist: Multimodal llm as an agent for unified image gen- eration and editing.Advances in Neural Information Pro- cessing Systems, 37:128374–128395, 2024
Zhenyu Wang, Aoxue Li, Zhenguo Li, and Xihui Liu. Genartist: Multimodal llm as an agent for unified image gen- eration and editing.Advances in Neural Information Pro- cessing Systems, 37:128374–128395, 2024. 1
2024
-
[26]
Q-bench: A benchmark for general-purpose foundation models on low-level vision
Haoning Wu, Zicheng Zhang, Erli Zhang, Chaofeng Chen, Liang Liao, Annan Wang, Chunyi Li, Wenxiu Sun, Qiong Yan, Guangtao Zhai, et al. Q-bench: A benchmark for general-purpose foundation models on low-level vision. arXiv preprint arXiv:2309.14181, 2023. 1, 2, 3
-
[27]
Q-Align: Teaching LMMs for Visual Scoring via Discrete Text-Defined Levels
Haoning Wu, Zicheng Zhang, Weixia Zhang, Chaofeng Chen, Liang Liao, Chunyi Li, Yixuan Gao, Annan Wang, Erli Zhang, Wenxiu Sun, et al. Q-align: Teaching lmms for visual scoring via discrete text-defined levels.arXiv preprint arXiv:2312.17090, 2023. 2, 4
work page internal anchor Pith review arXiv 2023
-
[28]
Visualquality-r1: Reasoning-induced image quality assess- ment via reinforcement learning to rank, 2025
Tianhe Wu, Jian Zou, Jie Liang, Lei Zhang, and Kede Ma. Visualquality-r1: Reasoning-induced image quality assess- ment via reinforcement learning to rank, 2025. 1
2025
-
[29]
Large language models are active critics in nlg evaluation, 2025
Shuying Xu, Junjie Hu, and Ming Jiang. Large language models are active critics in nlg evaluation, 2025. 1, 3
2025
-
[30]
Lmm4edit: Benchmarking and eval- uating multimodal image editing with lmms
Zitong Xu, Huiyu Duan, Bingnan Liu, Guangji Ma, Jiarui Wang, Liu Yang, Shiqi Gao, Xiaoyu Wang, Jia Wang, Xiongkuo Min, et al. Lmm4edit: Benchmarking and eval- uating multimodal image editing with lmms. InProceedings of the 33rd ACM International Conference on Multimedia, pages 6908–6917, 2025. 1, 2, 4, 6
2025
-
[31]
Zitong Xu, Huiyu Duan, Zhongpeng Ji, Xinyun Zhang, Yu- tao Liu, Xiongkuo Min, Ke Gu, Jian Zhang, Shusong Xu, Jinwei Chen, et al. Edithf-1m: A million-scale rich hu- man preference feedback for image editing.arXiv preprint arXiv:2603.14916, 2026. 1
-
[32]
Maniqa: Multi-dimension attention network for no-reference image quality assessment
Sidi Yang, Tianhe Wu, Shuwei Shi, Shanshan Lao, Yuan Gong, Mingdeng Cao, Jiahao Wang, and Yujiu Yang. Maniqa: Multi-dimension attention network for no-reference image quality assessment. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1191–1200, 2022. 1
2022
-
[33]
Teaching large language models to regress accurate image quality scores using score distribution
Zhiyuan You, Xin Cai, Jinjin Gu, Tianfan Xue, and Chao Dong. Teaching large language models to regress accurate image quality scores using score distribution. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14483–14494, 2025. 2, 4
2025
-
[34]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 586–595, 2018. 6
2018
-
[35]
Reasoning as representation: Rethinking visual reinforcement learning in image quality assessment, 2026
Shijie Zhao, Xuanyu Zhang, Weiqi Li, Junlin Li, Li Zhang, Tianfan Xue, and Jian Zhang. Reasoning as representation: Rethinking visual reinforcement learning in image quality assessment, 2026. 2
2026
-
[36]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonza- lez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023. 3
2023
-
[37]
Large lan- guage models are human-level prompt engineers
Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. Large lan- guage models are human-level prompt engineers. InThe eleventh international conference on learning representa- tions, 2022. 1, 3
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.