Recognition: unknown
Scaling Exposes the Trigger: Input-Level Backdoor Detection in Text-to-Image Diffusion Models via Cross-Attention Scaling
Pith reviewed 2026-05-10 15:28 UTC · model grok-4.3
The pith
Cross-attention scaling reveals divergent response patterns that distinguish backdoor inputs from benign ones in text-to-image diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Controlled scaling on cross-attention uncovers that benign and backdoor inputs exhibit systematically different response evolution patterns across denoising steps; SET leverages this by learning a benign response space from clean samples and detecting deviations via response-offset features.
What carries the argument
Cross-Attention Scaling Response Divergence (CSRD): the phenomenon where benign and backdoor inputs show different response patterns under controlled scaling perturbations on cross-attention, used to build detection features.
If this is right
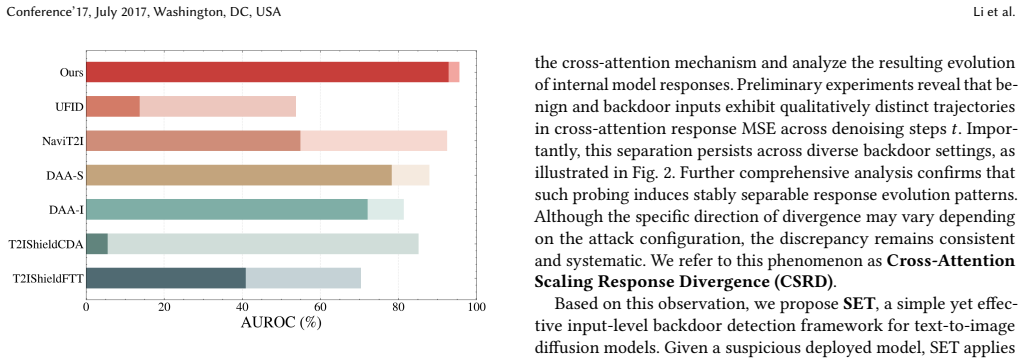
- SET achieves higher AUROC and accuracy than baselines, especially improving by 9.1% AUROC and 6.5% ACC on stealthy implicit-trigger attacks.
- Input-level detection works without prior attack knowledge or access to the model's training process.
- The approach applies across various attack methods, trigger types, and model settings in text-to-image diffusion.
- Learning the benign space requires only a small set of clean samples.
Where Pith is reading between the lines
- The divergence might stem from backdoors altering the attention mechanisms in ways scaling amplifies, suggesting similar probing could work on other model components.
- This method could extend to detecting backdoors in other generative models that use cross-attention, like video or audio diffusion.
- Testing on larger-scale models or real-world deployed T2I services would validate practical robustness beyond controlled experiments.
Load-bearing premise
The cross-attention scaling response divergence is a stable, trigger-agnostic signal that can be reliably captured by learning a compact benign response space from only a small set of clean samples without model training access.
What would settle it
Running SET on a set of known backdoored inputs with stealthy triggers and observing whether their response-offset features fall within the learned benign space or deviate as predicted.
Figures


read the original abstract
Text-to-image (T2I) diffusion models have achieved remarkable success in image synthesis, but their reliance on large-scale data and open ecosystems introduces serious backdoor security risks. Existing defenses, particularly input-level methods, are more practical for deployment but often rely on observable anomalies that become unreliable under stealthy, semantics-preserving trigger designs. As modern backdoor attacks increasingly embed triggers into natural inputs, these methods degrade substantially, raising a critical question: can more stable, implicit, and trigger-agnostic differences between benign and backdoor inputs be exploited for detection? In this work, we address this challenge from an active probing perspective. We introduce controlled scaling perturbations on cross-attention and uncover a novel phenomenon termed Cross-Attention Scaling Response Divergence (CSRD), where benign and backdoor inputs exhibit systematically different response evolution patterns across denoising steps. Building on this insight, we propose SET, an input-level backdoor detection framework that constructs response-offset features under multi-scale perturbations and learns a compact benign response space from a small set of clean samples. Detection is then performed by measuring deviations from this learned space, without requiring prior knowledge of the attack or access to model training. Extensive experiments demonstrate that SET consistently outperforms existing baselines across diverse attack methods, trigger types, and model settings, with particularly strong gains under stealthy implicit-trigger scenarios. Overall, SET improves AUROC by 9.1% and ACC by 6.5% over the best baseline, highlighting its effectiveness and robustness for practical deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SET, an input-level backdoor detection framework for text-to-image diffusion models. It identifies a phenomenon called Cross-Attention Scaling Response Divergence (CSRD) by applying controlled scaling perturbations to cross-attention layers during denoising, revealing systematic differences in response evolution between benign and backdoor inputs. SET constructs response-offset features under multi-scale perturbations, learns a compact benign response space from a small set of clean samples, and detects backdoors via deviation measurement without requiring attack knowledge or training data access. Experiments claim consistent outperformance over baselines across attack methods and trigger types, with gains of 9.1% AUROC and 6.5% ACC, especially on stealthy implicit triggers.
Significance. If the results hold, this provides a practical, deployable defense for backdoor risks in open T2I ecosystems by exploiting stable, trigger-agnostic signals through active probing rather than passive anomaly detection. The approach's lack of dependence on model internals or attack specifics strengthens its applicability, and the focus on implicit triggers addresses a growing limitation in prior defenses.
major comments (2)
- [Method] The central detection mechanism relies on the assumption that a compact benign response space learned from only a small set of clean samples adequately models natural variability in cross-attention responses (across prompts, random seeds, and denoising trajectories). This assumption is load-bearing for the claimed robustness under stealthy implicit triggers, yet the manuscript provides insufficient validation that benign variability does not exceed the modeled compactness, risking elevated false positives on unseen clean inputs.
- [Experiments] The reported performance gains (AUROC +9.1%, ACC +6.5%) are presented without accompanying details on the exact number of clean samples used to fit the benign space, the full list of baselines with their configurations, statistical significance testing, or controls for confounds such as prompt diversity and model scale. These omissions make it difficult to assess whether the improvements are attributable to CSRD or to experimental setup choices.
minor comments (2)
- [Abstract] The abstract introduces CSRD but does not provide its precise mathematical formulation (e.g., how response-offset features are computed from scaling perturbations); this should be stated explicitly in the method section for reproducibility.
- [Method] Notation for scaling perturbation magnitudes and deviation thresholds should be standardized and defined early to avoid ambiguity when describing the multi-scale feature construction.
Simulated Author's Rebuttal
We thank the referee for the insightful comments and the recommendation for major revision. We believe the points raised can be fully addressed by providing additional clarifications, details, and experiments in the revised manuscript. Our point-by-point responses are as follows.
read point-by-point responses
-
Referee: [Method] The central detection mechanism relies on the assumption that a compact benign response space learned from only a small set of clean samples adequately models natural variability in cross-attention responses (across prompts, random seeds, and denoising trajectories). This assumption is load-bearing for the claimed robustness under stealthy implicit triggers, yet the manuscript provides insufficient validation that benign variability does not exceed the modeled compactness, risking elevated false positives on unseen clean inputs.
Authors: We appreciate the referee pointing out the need for stronger validation of our core assumption. While the current manuscript demonstrates the effectiveness through experiments on held-out clean samples, we acknowledge that a more thorough analysis of benign variability is warranted. In the revised version, we will add a dedicated subsection under the method or experiments that quantifies the natural variability in cross-attention responses for benign inputs across a diverse set of prompts, multiple random seeds, and full denoising trajectories. We will show that the learned compact space captures this variability effectively, with empirical evidence of low deviation for clean inputs, thereby mitigating concerns about false positives on unseen data. This addition will reinforce the robustness claims, particularly for implicit triggers. revision: yes
-
Referee: [Experiments] The reported performance gains (AUROC +9.1%, ACC +6.5%) are presented without accompanying details on the exact number of clean samples used to fit the benign space, the full list of baselines with their configurations, statistical significance testing, or controls for confounds such as prompt diversity and model scale. These omissions make it difficult to assess whether the improvements are attributable to CSRD or to experimental setup choices.
Authors: We agree that the experimental details provided are insufficient for full assessment and reproducibility. We will revise the paper to include: the precise number of clean samples used to construct the benign response space; an expanded description of all baseline methods with their exact configurations and hyperparameters; statistical significance testing results (e.g., mean and standard deviation over 5 independent runs with different seeds, along with p-values); and controls for potential confounds including variations in prompt diversity (e.g., simple vs. complex prompts) and model scales (e.g., different diffusion model sizes). These enhancements will allow readers to better attribute the observed performance improvements (AUROC +9.1%, ACC +6.5%) to the CSRD phenomenon rather than experimental choices. revision: yes
Circularity Check
No significant circularity; detection uses external clean samples for reference space
full rationale
The paper's core contribution is an empirical anomaly-detection method: it applies controlled cross-attention scaling perturbations, observes CSRD patterns, constructs response-offset features, and fits a compact benign space solely from a small external set of clean samples before measuring deviations on test inputs. This construction does not reduce any claimed result to its own fitted parameters by definition, nor does it rely on self-citation chains or uniqueness theorems imported from the authors' prior work. The reported AUROC/ACC gains are presented as experimental outcomes rather than derived predictions, and the method explicitly avoids access to training data or attack knowledge. No load-bearing step equates a prediction to its input by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- scaling perturbation magnitudes
- deviation threshold for detection
axioms (1)
- domain assumption Benign and backdoor inputs exhibit systematically different cross-attention response evolution patterns under scaling perturbations across denoising steps.
invented entities (1)
-
Cross-Attention Scaling Response Divergence (CSRD)
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
Weixin Chen, Dawn Song, and Bo Li. 2023. TrojDiff: Trojan Attacks on Diffusion Models With Diverse Targets. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 4035–4044
2023
-
[3]
Leah Chong, I-Ping Lo, Jude Rayan, Steven Dow, Faez Ahmed, and Ioanna Lyk- ourentzou. 2025. Prompting for products: investigating design space exploration strategies for text-to-image generative models.Design Science11 (2025), e2. doi:10.1017/dsj.2024.51
-
[4]
Sheng-Yen Chou, Pin-Yu Chen, and Tsung-Yi Ho. 2023. How to Backdoor Diffusion Models?. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 4015–4024
2023
-
[5]
Sheng-Yen Chou, Pin-Yu Chen, and Tsung-Yi Ho. 2023. VillanDiffusion: A Unified Backdoor Attack Framework for Diffusion Models. InAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Glober- son, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curran Associates, Inc., 33912–33964. https://proceedings.neurips.cc/paper_files/paper/202...
2023
-
[6]
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit Haim Bermano, Gal Chechik, and Daniel Cohen-Or. 2023. An Image is Worth One Word: Per- sonalizing Text-to-Image Generation using Textual Inversion. InThe Eleventh International Conference on Learning Representations. https://openreview.net/ forum?id=NAQvF08TcyG
2023
-
[7]
Tianyu Gu, Brendan Dolan-Gavitt, and Siddharth Garg. 2019. BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain. arXiv:1708.06733 [cs.CR] https://arxiv.org/abs/1708.06733
work page internal anchor Pith review arXiv 2019
-
[8]
Zihan Guan, Mengxuan Hu, Sheng Li, and Anil Kumar Vullikanti. 2025. UFID: A Unified Framework for Black-box Input-level Backdoor Detection on Diffusion Models.Proceedings of the AAAI Conference on Artificial Intelligence39, 26 (Apr. 2025), 27312–27320. doi:10.1609/aaai.v39i26.34941
-
[9]
Junfeng Guo, Yiming Li, Xun Chen, Hanqing Guo, Lichao Sun, and Cong Liu
-
[10]
arXiv:2302.03251 [cs.CR] https://arxiv
SCALE-UP: An Efficient Black-box Input-level Backdoor Detection via Analyzing Scaled Prediction Consistency. arXiv:2302.03251 [cs.CR] https://arxiv. org/abs/2302.03251
-
[11]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising Diffusion Probabilis- tic Models. InAdvances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin (Eds.), Vol. 33. Curran Asso- ciates, Inc., 6840–6851. https://proceedings.neurips.cc/paper_files/paper/2020/ file/4c5bcfec8584af0d967f1ab10179ca4b-...
2020
-
[12]
Linshan Hou, Ruili Feng, Zhongyun Hua, Wei Luo, Leo Yu Zhang, and Yiming Li
-
[13]
InProceedings of the 41st International Conference on Machine Learn- ing (Proceedings of Machine Learning Research, Vol
IBD-PSC: Input-level Backdoor Detection via Parameter-oriented Scaling Consistency. InProceedings of the 41st International Conference on Machine Learn- ing (Proceedings of Machine Learning Research, Vol. 235), Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp (Eds.). PMLR, 18992–1902...
-
[14]
Yihao Huang, Felix Juefei-Xu, Qing Guo, Jie Zhang, Yutong Wu, Ming Hu, Tianlin Li, Geguang Pu, and Yang Liu. 2024. Personalization as a Shortcut for Few- Shot Backdoor Attack against Text-to-Image Diffusion Models.Proceedings of the AAAI Conference on Artificial Intelligence38, 19 (Mar. 2024), 21169–21178. doi:10.1609/aaai.v38i19.30110
- [15]
-
[16]
Yiming Li, Yong Jiang, Zhifeng Li, and Shu-Tao Xia. 2024. Backdoor Learning: A Survey.IEEE Transactions on Neural Networks and Learning Systems35, 1 (2024), 5–22. doi:10.1109/TNNLS.2022.3182979
-
[17]
Lawrence Zitnick
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. 2014. Microsoft COCO: Common Objects in Context. InComputer Vision – ECCV 2014, David Fleet, Tomas Pajdla, Bernt Schiele, and Tinne Tuytelaars (Eds.). Springer International Publishing, Cham, 740–755
2014
-
[18]
Yanru Lyu, Xinxin Wang, Rungtai Lin, and Jun Wu. 2022. Communication in Human–AI Co-Creation: Perceptual Analysis of Paintings Generated by Text-to- Image System.Applied Sciences12, 22 (2022). doi:10.3390/app122211312
-
[19]
Yichuan Mo, Hui Huang, Mingjie Li, Ang Li, and Yisen Wang. 2024. TERD: a unified framework for safeguarding diffusion models against backdoors. In Proceedings of the 41st International Conference on Machine Learning(Vienna, Austria)(ICML’24). JMLR.org, Article 1463, 18 pages
2024
-
[20]
Alexander Quinn Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob Mcgrew, Ilya Sutskever, and Mark Chen. 2022. GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models. InProceedings of the 39th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 162), K...
2022
-
[21]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. InProceedings of the 38th Inter- national Conference on Machine Learning (Proceedings of Machi...
2021
-
[22]
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen
-
[23]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Hierarchical Text-Conditional Image Generation with CLIP Latents. arXiv:2204.06125 [cs.CV] https://arxiv.org/abs/2204.06125
work page internal anchor Pith review arXiv
-
[24]
Amon Rapp, Chiara Di Lodovico, Federico Torrielli, and Luigi Di Caro. 2025. How do people experience the images created by generative artificial intelligence? An exploration of people’s perceptions, appraisals, and emotions related to a Gen-AI text-to-image model and its creations.International Journal of Human-Computer Studies193 (2025), 103375. doi:10.1...
-
[25]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-Resolution Image Synthesis With Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 10684–10695
2022
-
[26]
Lukas Ruff, Robert Vandermeulen, Nico Goernitz, Lucas Deecke, Shoaib Ahmed Siddiqui, Alexander Binder, Emmanuel Müller, and Marius Kloft. 2018. Deep One-Class Classification. InProceedings of the 35th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 80), Jennifer Dy and Andreas Krause (Eds.). PMLR, 4393–4402. ht...
2018
-
[27]
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. 2023. DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 22500–22510
2023
-
[28]
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Den- ton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. 2022. Photorealistic Text-to-Image Diffusion Models with Deep Lan- guage Understanding. arXiv:2205.11487 [cs.CV] https:/...
work page internal anchor Pith review arXiv 2022
-
[29]
Neural Computation , volume = 13, number = 7, pages =
Bernhard Schölkopf, John C. Platt, John Shawe-Taylor, Alex J. Smola, and Robert C. Williamson. 2001. Estimating the Sup- port of a High-Dimensional Distribution.Neural Computation13, 7 (07 2001), 1443–1471. arXiv:https://direct.mit.edu/neco/article- pdf/13/7/1443/814849/089976601750264965.pdf doi:10.1162/089976601750264965
-
[30]
Lukas Struppek, Dominik Hintersdorf, and Kristian Kersting. 2023. Rickrolling the Artist: Injecting Backdoors into Text Encoders for Text-to-Image Synthesis. In2023 IEEE/CVF International Conference on Computer Vision (ICCV). 4561–4573. doi:10.1109/ICCV51070.2023.00423 Conference’17, July 2017, Washington, DC, USA Li et al
-
[31]
Vu Tuan Truong, Luan Ba Dang, and Long Bao Le. 2025. Attacks and Defenses for Generative Diffusion Models: A Comprehensive Survey.ACM Comput. Surv. 57, 8, Article 216 (April 2025), 44 pages. doi:10.1145/3721479
-
[32]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. InAdvances in Neural Information Processing Systems, I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (Eds.), Vol. 30. Curran Associates, Inc. https://proc...
2017
-
[33]
Hao Wang, Shangwei Guo, Jialing He, Kangjie Chen, Shudong Zhang, Tianwei Zhang, and Tao Xiang. 2024. EvilEdit: Backdooring Text-to-Image Diffusion Models in One Second. InProceedings of the 32nd ACM International Conference on Multimedia(Melbourne VIC, Australia)(MM ’24). Association for Computing Machinery, New York, NY, USA, 3657–3665. doi:10.1145/36646...
-
[34]
Zhongqi Wang, Jie Zhang, Shiguang Shan, and Xilin Chen. 2025. T2IShield: Defending Against Backdoors on Text-to-Image Diffusion Models. InComputer Vision – ECCV 2024, Aleš Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and Gül Varol (Eds.). Springer Nature Switzerland, Cham, 107– 124
2025
-
[35]
Zhongqi Wang, Jie Zhang, Shiguang Shan, and Xilin Chen. 2026. Dynamic Attention Analysis for Backdoor Detection in Text-to-Image Diffusion Models. IEEE Transactions on Pattern Analysis and Machine Intelligence48, 3 (2026), 3652–
2026
-
[36]
doi:10.1109/TPAMI.2025.3644016
-
[37]
Shengfang Zhai, Yinpeng Dong, Qingni Shen, Shi Pu, Yuejian Fang, and Hang Su. 2023. Text-to-Image Diffusion Models can be Easily Backdoored through Multimodal Data Poisoning. InProceedings of the 31st ACM International Confer- ence on Multimedia(Ottawa ON, Canada)(MM ’23). Association for Computing Machinery, New York, NY, USA, 1577–1587. doi:10.1145/3581...
-
[38]
Shengfang Zhai, Jiajun Li, Yue Liu, Huanran Chen, Zhihua Tian, Wenjie Qu, Qingni Shen, Ruoxi Jia, Yinpeng Dong, and Jiaheng Zhang. 2025. Efficient Input- level Backdoor Defense on Text-to-Image Synthesis via Neuron Activation Varia- tion. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 15182–15193
2025
-
[39]
Chenyu Zhang, Mingwang Hu, Wenhui Li, and Lanjun Wang. 2025. Adversarial attacks and defenses on text-to-image diffusion models: A survey.Information Fusion114 (2025), 102701. doi:10.1016/j.inffus.2024.102701
- [40]
-
[41]
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. 2023. Adding Conditional Control to Text-to-Image Diffusion Models. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision (ICCV). 3836–3847. A Proof of Theorem 3.1 In this appendix, we spell out the regularity conditions used in Theorem 3.1 and give the full proof. Throughout, we fix a den...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.