Latent Planning Emerges with Scale
Pith reviewed 2026-05-10 14:51 UTC · model grok-4.3
The pith
Larger language models develop internal features that represent and prepare for specific future words.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
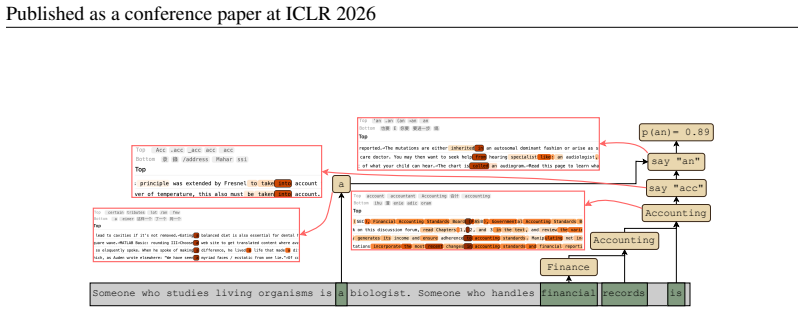
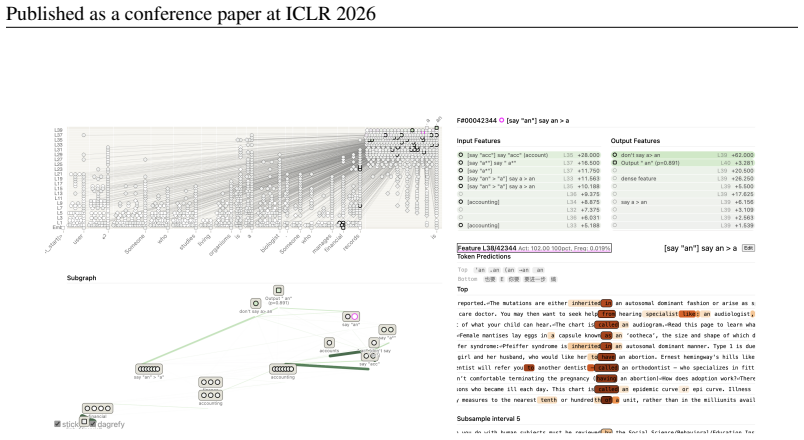
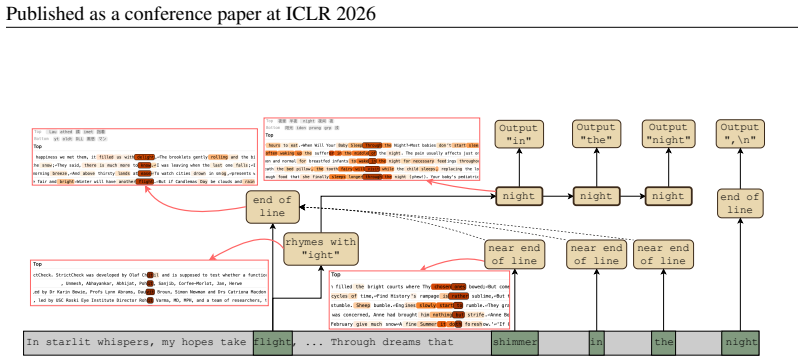
Latent planning occurs when models possess internal planning representations that cause the generation of a specific future token or concept and shape preceding context to license said future token or concept. In the Qwen-3 family on simple planning tasks, this ability increases with scale; models that plan contain features that represent a planned-for word like accountant and causally drive outputs such as an rather than a, while even the 4B-8B models exhibit nascent versions of these mechanisms. On rhyming couplets, models frequently identify a rhyme in advance but seldom plan many tokens ahead, although steering toward planned words in prose elicits additional planning that also grows in
What carries the argument
Internal features that encode a planned-for future token and causally influence the probability of earlier tokens to license it.
If this is right
- Scaling will produce stronger implicit planning in tasks such as story writing and code generation.
- Mid-sized models already contain basic planning representations that can be measured and potentially amplified.
- Steering interventions that point models toward planned words will yield larger planning gains in bigger models.
- Mechanistic inspection of these features can track how planning representations form during training.
Where Pith is reading between the lines
- The same measurement approach could be used to test whether other emergent behaviors also rest on identifiable internal representations.
- If the features can be located reliably, targeted editing might allow finer control over long-range coherence without explicit prompting.
- The pattern suggests planning is a general capacity that appears once models exceed a certain size threshold rather than a task-specific skill.
Load-bearing premise
The identified internal features and their token influences reflect genuine causal planning rather than surface correlations, and the chosen tasks validly capture the defined form of latent planning.
What would settle it
Intervening on or ablating the identified planning features and observing no corresponding change in the choice of future tokens or in the shaping of prior context would falsify the claim.
Figures





















read the original abstract
LLMs can perform seemingly planning-intensive tasks, like writing coherent stories or functioning code, without explicitly verbalizing a plan; however, the extent to which they implicitly plan is unknown. In this paper, we define latent planning as occurring when LLMs possess internal planning representations that (1) cause the generation of a specific future token or concept, and (2) shape preceding context to license said future token or concept. We study the Qwen-3 family (0.6B-14B) on simple planning tasks, finding that latent planning ability increases with scale. Models that plan possess features that represent a planned-for word like "accountant", and cause them to output "an" rather than "a"; moreover, even the less-successful Qwen-3 4B-8B have nascent planning mechanisms. On the more complex task of completing rhyming couplets, we find that models often identify a rhyme ahead of time, but even large models seldom plan far ahead. However, we can elicit some planning that increases with scale when steering models towards planned words in prose. In sum, we offer a framework for measuring planning and mechanistic evidence of how models' planning abilities grow with scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines latent planning as the presence of internal representations that both cause a specific future token/concept and shape preceding context to license it. It reports that this ability increases with scale in the Qwen-3 family (0.6B–14B) on simple planning tasks, with larger models possessing features that represent planned-for words (e.g., 'accountant') and drive correct article choice ('an' vs. 'a'); even 4B–8B models show nascent versions of these mechanisms. On rhyming-couplet completion, models identify rhymes ahead of time but plan only limited distance ahead, though steering toward planned words elicits more planning that scales with size.
Significance. If the causal claims hold, the work supplies a concrete framework for measuring implicit planning and mechanistic evidence that planning representations strengthen with scale. This could guide future interpretability and training efforts aimed at improving long-horizon reasoning in LLMs.
major comments (3)
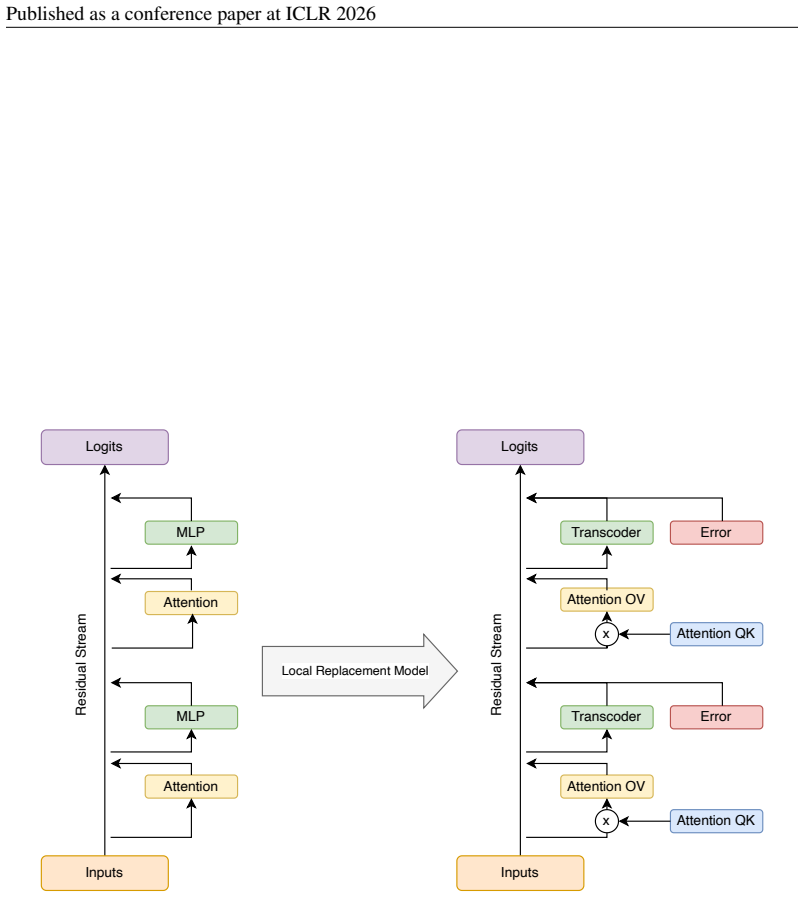
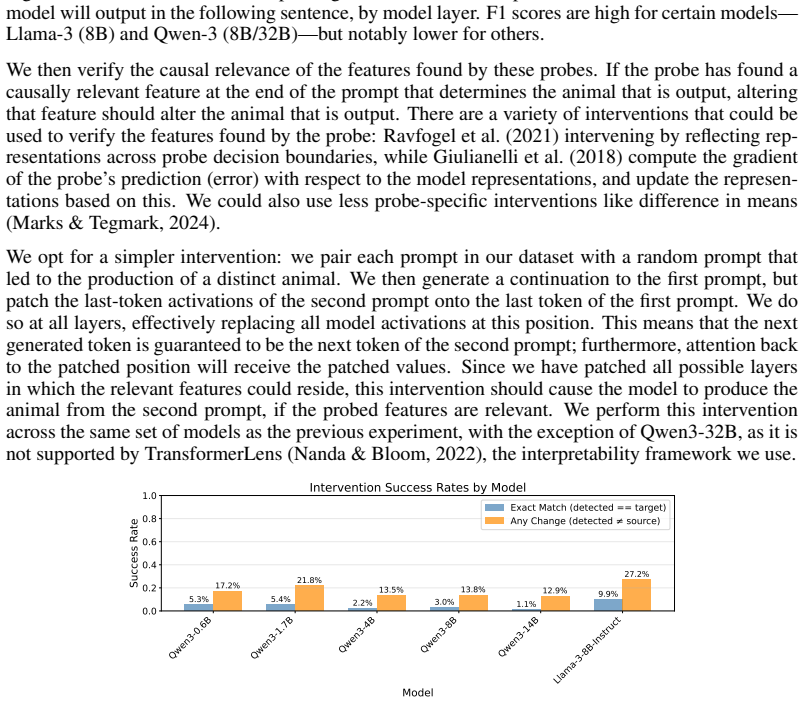
- [§4] §4 (feature identification for 'an'/'a' task): the central definition requires that the identified features 'cause' the future token, yet the reported evidence consists of correlational probes (feature activation similarity, logit inspection) without activation patching, steering, or counterfactual interventions on the planning direction during generation. This leaves open whether the features are doing the causal work or merely correlate with successful outputs.
- [§5] §5 (rhyming-couplet results and scaling claims): the statement that 'even the less-successful Qwen-3 4B-8B have nascent planning mechanisms' is load-bearing for the scaling narrative, but the manuscript provides no quantitative threshold, statistical test, or control condition that distinguishes nascent planning from task-specific correlations or memorization.
- [§3] §3 (task design): the simple planning and rhyming tasks are used to operationalize the definition, yet no ablation or control experiments are described that rule out the possibility that observed 'planning' features are downstream effects of surface-level token statistics rather than genuine future-oriented representations.
minor comments (2)
- [Abstract] The abstract states empirical findings without any mention of methods, controls, or statistical tests; a one-sentence summary of the experimental approach would improve readability.
- [§2] Notation for 'planned-for word' and 'planning feature' is introduced informally; a short definitions subsection or table would clarify the distinction between representation and causal effect.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify important gaps in causal evidence, quantification of nascent effects, and controls for alternative explanations. We address each point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (feature identification for 'an'/'a' task): the central definition requires that the identified features 'cause' the future token, yet the reported evidence consists of correlational probes (feature activation similarity, logit inspection) without activation patching, steering, or counterfactual interventions on the planning direction during generation. This leaves open whether the features are doing the causal work or merely correlate with successful outputs.
Authors: We agree that the definition of latent planning is causal and that our current probes (activation similarity and logit inspection) are primarily correlational. While the scaling trends and the link between feature presence and article choice provide suggestive functional evidence, direct interventions are needed for stronger claims. In the revised manuscript we will add activation patching and steering experiments that intervene on the identified planning features during generation, testing whether they causally drive the future token and the preceding context. revision: yes
-
Referee: [§5] §5 (rhyming-couplet results and scaling claims): the statement that 'even the less-successful Qwen-3 4B-8B have nascent planning mechanisms' is load-bearing for the scaling narrative, but the manuscript provides no quantitative threshold, statistical test, or control condition that distinguishes nascent planning from task-specific correlations or memorization.
Authors: We acknowledge that the phrasing 'nascent planning mechanisms' for the 4B–8B models requires more rigorous grounding. The revision will introduce explicit quantitative thresholds (e.g., minimum feature–token correlation and downstream accuracy gains), statistical tests against matched control conditions, and additional baselines that isolate planning representations from task-specific correlations or memorization. These changes will make the scaling claims more precise and defensible. revision: yes
-
Referee: [§3] §3 (task design): the simple planning and rhyming tasks are used to operationalize the definition, yet no ablation or control experiments are described that rule out the possibility that observed 'planning' features are downstream effects of surface-level token statistics rather than genuine future-oriented representations.
Authors: The tasks were constructed so that correct article choice or rhyme selection depends on a future noun or rhyme word that is not yet in the local context. Nevertheless, we agree that surface-level statistical explanations must be explicitly ruled out. The revised version will include ablation controls that preserve local token statistics while removing the need for future planning (and vice versa) to confirm that the identified features reflect genuine latent planning rather than downstream correlations. revision: yes
Circularity Check
No circularity: empirical scaling study with independent measurements
full rationale
The paper introduces a definition of latent planning and reports observational results on how internal representations and task performance scale across the Qwen-3 model family (0.6B–14B). No mathematical derivations, self-referential equations, or fitted parameters are present that would reduce any claimed prediction or scaling result to the inputs by construction. The analysis consists of measurements on planning and rhyming tasks, with findings stated as empirical observations rather than tautological outputs of the definition itself. No load-bearing self-citations or ansatzes imported from prior work by the same authors appear in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Zong, C., Xia, F., Li, W., Navigli, R
Association for Computational Linguistics. ISBN 979-8-89176-189-6. doi: 10.18653/v1/ 2025.naacl-long.312. URLhttps://aclanthology.org/2025.naacl-long.312/. 11 Published as a conference paper at ICLR 2026 Carnegie Mellon University. The carnegie mellon pronouncing dictionary, 2014. URLhttp: //www.speech.cs.cmu.edu/cgi-bin/cmudict. Version 0.7b. Tyler A. Ch...
-
[2]
TinyStories: How Small Can Language Models Be and Still Speak Coherent English?
URLhttps://openreview.net/forum?id=J6zHcScAo0. Ronen Eldan and Yuanzhi Li. Tinystories: How small can language models be and still speak coherent english?, 2023. URLhttps://arxiv.org/abs/2305.07759. Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn D...
work page internal anchor Pith review arXiv 2023
-
[3]
https://transformer-circuits.pub/2021/framework/index.html. Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. Toy models of super- position.Transformer C...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2021.acl-long.144 2021
-
[4]
Shauli Ravfogel, Grusha Prasad, Tal Linzen, and Yoav Goldberg
URLhttps://www.lesswrong.com/posts/9NqgYesCutErskdmu/ parascopes-do-language-models-plan-the-upcoming-paragraph. Shauli Ravfogel, Grusha Prasad, Tal Linzen, and Yoav Goldberg. Counterfactual interventions reveal the causal effect of relative clause representations on agreement prediction. In Arianna Bisazza and Omri Abend (eds.),Proceedings of the 25th Co...
-
[5]
Association for Computational Linguistics. doi: 10.18653/v1/2024.knowllm-1.1. URL https://aclanthology.org/2024.knowllm-1.1/. Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in GPT-2 small. In The Eleventh International Conference on Learnin...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.knowllm-1.1 2024
-
[6]
**Contains steered word **: Does the steered generation contain the exact word "{steered_word}"? (Look for exact match, case- insensitive)
-
[7]
**Coherence**: Is the steered generation coherent up to the target word. Is it natural, or does it show signs of breakdown such as: - Excessive repetition of words or phrases - Unnatural/nonsensical sentences - Abrupt topic changes that don’t make sense - Grammatical breakdown - IMPORTANT: Focus on coherence up to the point where the steered word appears ...
-
[8]
**Context adaptation **: Compare the steered generation to the baseline generation, starting from the input_prompt. Did the model modify the words immediately preceding where the steered word appears (or would appear) compared to the baseline? Look for changes like: - Adding/changing articles ("a", "the", "an") - Adding/changing prepositions ("in", "on", ...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.