Recognition: unknown
From Imitation to Discrimination: Progressive Curriculum Learning for Robust Web Navigation
Pith reviewed 2026-05-10 15:09 UTC · model grok-4.3
The pith
Progressive curriculum from imitation to discrimination lets 32B models surpass GPT-4.5 on web navigation
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
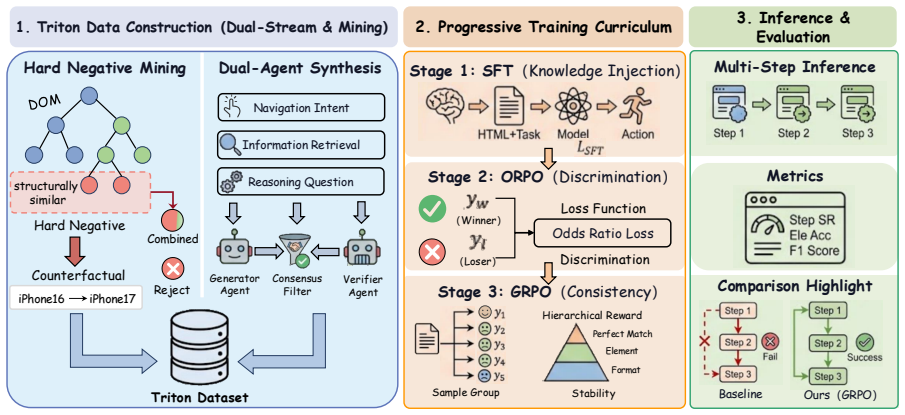
The Triton dataset built via Structural-Semantic Hard Negative Mining and Dual-Agent Consensus, combined with progressive training through SFT, ORPO, and GRPO stages, produces 32B models that reach 58.7% Step Success Rate on Mind2Web, exceeding the performance of GPT-4.5 at 42.4% and Claude-4.5 at 41.4%.
What carries the argument
Structural-Semantic Hard Negative Mining to generate topologically similar distractors and Dual-Agent Consensus for synthesizing verified cross-domain tasks, enabling the shift from imitation to robust discrimination in the curriculum.
If this is right
- Agents gain the ability to reject incorrect but plausible page elements in densely populated web pages.
- Training leads to improved generalization across unseen website layouts and domains.
- Long-horizon navigation consistency improves through the final optimization stage.
- Specialized data and curriculum design can outperform increases in raw model parameters for this task.
Where Pith is reading between the lines
- Applying the hard negative mining and consensus verification to other agent benchmarks could yield similar gains in robustness.
- The success suggests data quality and training progression are key levers for web agent development beyond scaling laws.
Load-bearing premise
The training examples generated by the hard negative mining and dual-agent consensus accurately represent the difficulty and noise distribution of real-world HTML without introducing biases that inflate measured performance.
What would settle it
Running the Triton-GRPO-32B model on a new collection of web pages where distractors are engineered to have different structural or semantic properties than those mined in the dataset, and observing if the step success rate drops below 42%.
Figures









read the original abstract
Text-based web agents offer computational efficiency for autonomous web navigation, yet developing robust agents remains challenging due to the noisy and heterogeneous nature of real-world HTML. Standard Supervised Fine-Tuning (SFT) approaches fail in two critical dimensions: they lack discrimination capabilities to reject plausible but incorrect elements in densely populated pages, and exhibit limited generalization to unseen website layouts. To address these challenges, we introduce the Triton dataset (590k instances) and a progressive training curriculum. Triton is constructed via Structural-Semantic Hard Negative Mining, which explicitly mines topologically similar distractors, and a Dual-Agent Consensus pipeline that synthesizes diverse cross-domain tasks with strict verification. Building upon this foundation, our progressive curriculum produces three models: Triton-SFT-32B for basic imitation, Triton-ORPO-32B for robust discrimination via Odds Ratio Preference Optimization, and Triton-GRPO-32B for long-horizon consistency through Group Relative Policy Optimization. Empirical evaluation on Mind2Web demonstrates that Triton-GRPO-32B achieves state-of-the-art performance among open-source models with 58.7% Step Success Rate, surpassing GPT-4.5 (42.4%) and Claude-4.5 (41.4%) by over 16%, validating that specialized data curriculum outweighs raw parameter scale for web navigation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Triton dataset (590k instances) constructed via Structural-Semantic Hard Negative Mining and a Dual-Agent Consensus pipeline for synthesizing verified web navigation tasks. It proposes a progressive curriculum of SFT for basic imitation, followed by ORPO for discrimination against hard negatives, and GRPO for long-horizon consistency, yielding Triton-GRPO-32B which reports 58.7% Step Success Rate on Mind2Web, outperforming GPT-4.5 (42.4%) and Claude-4.5 (41.4%).
Significance. If the results hold after proper validation, the work would demonstrate that targeted data curation and staged optimization can enable a 32B open-source model to substantially outperform larger proprietary models on web navigation, underscoring the value of curriculum design over raw scale. The Triton dataset construction approach could provide a reusable template for generating robust training data in noisy environments.
major comments (3)
- [Dataset Construction] Dataset construction: The Structural-Semantic Hard Negative Mining and Dual-Agent Consensus pipeline is described at a high level but supplies no quantitative validation (e.g., inter-agent agreement rates, human precision on held-out labels, or distributional divergence statistics vs. live HTML). This is load-bearing because the headline 16%+ SSR gain on Mind2Web could arise from synthetic artifacts rather than improved robustness if the mined negatives or consensus labels contain systematic errors.
- [Empirical Evaluation] Empirical evaluation: The reported 58.7% SSR for Triton-GRPO-32B lacks any description of the evaluation protocol, statistical significance tests, data-leakage checks between Triton and Mind2Web, or ablation results isolating the contribution of each curriculum stage (SFT, ORPO, GRPO). Without these, the central claim that the curriculum produces the observed gains cannot be assessed.
- [Training Curriculum] Training details: No analysis is provided on how the progressive stages incrementally improve discrimination or long-horizon behavior, nor are there controls showing that the performance edge is not simply due to the volume of 590k instances or model scale alone.
minor comments (1)
- [Abstract] The abstract would benefit from explicitly stating the exact model parameter counts and whether the GPT-4.5/Claude-4.5 baselines use the same prompting or tool-use setup as the Triton models.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below and will revise the manuscript to incorporate the requested details, analyses, and validations.
read point-by-point responses
-
Referee: [Dataset Construction] Dataset construction: The Structural-Semantic Hard Negative Mining and Dual-Agent Consensus pipeline is described at a high level but supplies no quantitative validation (e.g., inter-agent agreement rates, human precision on held-out labels, or distributional divergence statistics vs. live HTML). This is load-bearing because the headline 16%+ SSR gain on Mind2Web could arise from synthetic artifacts rather than improved robustness if the mined negatives or consensus labels contain systematic errors.
Authors: We agree that quantitative validation is essential for substantiating dataset quality. In the revised manuscript, we will add a new subsection reporting: inter-agent agreement rates from the Dual-Agent Consensus pipeline; human precision and recall on a held-out set of 500 instances; and distributional statistics (e.g., KL divergence on element frequencies and structural similarity) comparing Triton instances against live HTML samples. These additions will confirm the pipeline's reliability and rule out systematic labeling errors. revision: yes
-
Referee: [Empirical Evaluation] Empirical evaluation: The reported 58.7% SSR for Triton-GRPO-32B lacks any description of the evaluation protocol, statistical significance tests, data-leakage checks between Triton and Mind2Web, or ablation results isolating the contribution of each curriculum stage (SFT, ORPO, GRPO). Without these, the central claim that the curriculum produces the observed gains cannot be assessed.
Authors: We will expand the Experimental Setup and Results sections to fully specify the Mind2Web evaluation protocol, including prompting details, success criteria, and run counts. Statistical significance will be added via bootstrap confidence intervals and paired tests on the 58.7% SSR. Data-leakage checks will verify zero overlap in websites or pages between Triton and Mind2Web. Ablation tables will isolate gains from each stage (SFT to ORPO to GRPO). revision: yes
-
Referee: [Training Curriculum] Training details: No analysis is provided on how the progressive stages incrementally improve discrimination or long-horizon behavior, nor are there controls showing that the performance edge is not simply due to the volume of 590k instances or model scale alone.
Authors: We will add a dedicated curriculum analysis subsection showing incremental performance gains across SFT, ORPO, and GRPO stages on Mind2Web and internal sets, with metrics for discrimination accuracy and long-horizon consistency. Control experiments will compare against a 590k-instance standard SFT baseline and a larger-scale model to isolate the curriculum's contribution from data volume or parameter count. revision: yes
Circularity Check
No significant circularity; empirical results on external benchmark
full rationale
The paper's chain consists of constructing the Triton dataset (590k instances) via Structural-Semantic Hard Negative Mining and Dual-Agent Consensus, then applying a progressive curriculum (SFT → ORPO → GRPO) to produce models evaluated on the external Mind2Web benchmark. The central claim of 58.7% Step Success Rate is an empirical measurement on held-out external data rather than a quantity derived by construction from the training inputs or self-citations. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text that would reduce the reported performance to the dataset construction steps. The result is therefore self-contained against an external benchmark.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437. Evan Zheran Liu, Kelvin Guu, Panupong Pasupat, Tian- lin Shi, and Percy Liang. 2018. Reinforcement learn- ing on web interfaces using workflow-guided explo- ration.arXiv preprint arXiv:1802.08802. OpenAI. 2025. Introducing gpt-4.5: A re- search preview. https://openai.com/index/ introducing-gpt...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Seed-coder: Let the code model curate data for itself.arXiv preprint arXiv:2506.03524, 2025
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741. ByteDance Seed, Yuyu Zhang, Jing Su, Yifan Sun, Chenguang Xi, Xia Xiao, Shen Zheng, Anxiang Zhang, Kaibo Liu, Daoguang Zan, and 1 others. 2025. Seed-coder: Let the code model curate data for itself. arXiv prepri...
-
[3]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854. A Data Construction Details In this section, we provide detailed specifications for the dataset construction pipeline, including the mathematical formulation for hard negative mining and the automated synthesis workflow. A.1 Discriminative Trajectory Mini...
work page internal anchor Pith review arXiv
-
[4]
Click the ’Sign Up’ button at the top right
Tag Removal: We strip all non-visual and Generator Agent Prompts (MG) [System System] You are an expert web user specializing in creating realistic user interactions. [Shared Context] HTML Snippet:{HTML_CONTEXT} Target Element:{TARGET_ELEMENT_HTML} [Task-Specific Instructions] Type 1: Navigation Intent Generate a short, imperative command that directly op...
-
[5]
Generic attributes (e.g., style strings, tracking codes) are dis- carded
Attribute Filtering: To reduce noise, we retain only semantically relevant at- tributes: class, id, type, name, aria-label, placeholder, and value. Generic attributes (e.g., style strings, tracking codes) are dis- carded
-
[6]
Text Truncation: Long text nodes are trun- cated to the first 50 tokens to preserve the structural outline without exhausting the con- text window
-
[7]
ele- ment=42
ID Injection: Crucially, we inject a sequential numeric identifier (e.g., backend_node_id) into every interactive element. This allows the model to output a concise ID (e.g., "ele- ment=42") rather than generating a complex XPath. Multi-Task Input Format.We structure the in- put using the standard ChatML format. To support multi-step navigation, we also a...
-
[8]
Sampling: For each instruction x in the train- ing set, we sample N= 5 trajectories from the current SFT checkpoint MSFT using tem- peratureT= 1.0to encourage diversity
-
[9]
search-bar
Winner Selection (yw): The ground truth tra- jectory is always fixed as the winner. Formatted Model Input (ChatML style) <|im_start|>system You are a proficient web navigation agent. Given the HTML content and a user instruction, select the correct element and operation. Output format: Element ID and Operation. <|im_end|> <|im_start|>user Observation (Cle...
-
[10]
iPhone 13
Type "iPhone 13" into element [15] (Search Box) Current Instruction: "Click the search button to see results." <|im_end|> <|im_start|>assistant Element:43 Operation:Click <|im_end|> Figure 10: The flattened input representation. We inject explicit IDs (e.g., id="42") into the HTML to enable precise referencing. The History block enables the model to maint...
-
[11]
Hard- est Loser
Loser Selection ( yl): We select the "Hard- est Loser" to penalize. Among the generated trajectories that areincorrect(i.e., wrong ele- ment ID or wrong operation type), we select the one with thehighest log-probability. This selection strategy specifically targets the model’s "blind spots"—answers that the model is confident in but are factually wrong (e...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.