Cognition-Inspired Dual-Stream Semantic Enhancement for Vision-Based Dynamic Emotion Modeling
Pith reviewed 2026-05-10 14:50 UTC · model grok-4.3
The pith
DuSE models brain priming and conceptual knowledge integration in a dual-stream architecture to improve dynamic facial expression recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
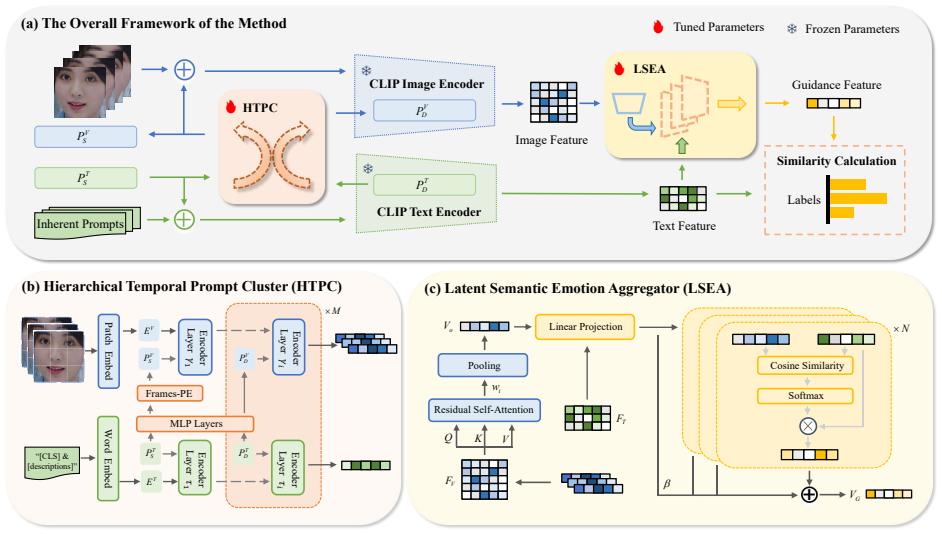
The central claim is that explicitly instantiating a dual-stream cognitive architecture, with the Hierarchical Temporal Prompt Cluster operationalizing the priming effect through textual-visual alignment and the Latent Semantic Emotion Aggregator modeling knowledge integration in the manner of Conceptual Act Theory, yields a more robust and neurally plausible system for dynamic facial expression recognition.
What carries the argument
The dual-stream architecture formed by the Hierarchical Temporal Prompt Cluster (HTPC), which pre-sensitizes visual processing via linguistic semantics, and the Latent Semantic Emotion Aggregator (LSEA), which synthesizes inputs with conceptual knowledge.
If this is right
- State-of-the-art accuracy is achieved on challenging in-the-wild dynamic facial expression recognition benchmarks.
- Model interpretability increases because internal representations align with known neuro-cognitive processes.
- The framework becomes more robust by explicitly integrating semantic context with visual dynamics.
Where Pith is reading between the lines
- Similar cognitive dual-stream designs could be tested on other video-based perception tasks such as action recognition.
- Direct comparison of the model's internal activations against human brain imaging data during emotion tasks would provide an external check on the claimed neural plausibility.
- The approach suggests that hybrid vision-language architectures may systematically outperform purely visual ones when the task requires constructing coherent perceptual categories.
Load-bearing premise
The performance gains arise specifically because HTPC and LSEA capture the cited cognitive processes rather than simply adding capacity or regularization available to any dual-stream model.
What would settle it
An ablation study in which a dual-stream model without the semantic prompting or knowledge-aggregation mechanisms matches or exceeds DuSE accuracy on the same benchmarks would indicate that the cognitive mechanisms are not the source of the gains.
Figures





read the original abstract
The human brain constructs emotional percepts not by processing facial expressions in isolation, but through a dynamic, hierarchical integration of sensory input with semantic and contextual knowledge. However, existing vision-based dynamic emotion modeling approaches often neglect emotion perception and cognitive theories. To bridge this gap between machine and human emotion perception, we propose cognition-inspired Dual-stream Semantic Enhancement (DuSE). Our model instantiates a dual-stream cognitive architecture. The first stream, a Hierarchical Temporal Prompt Cluster (HTPC), operationalizes the cognitive priming effect. It simulates how linguistic cues pre-sensitize neural pathways, modulating the processing of incoming visual stimuli by aligning textual semantics with fine-grained temporal features of facial dynamics. The second stream, a Latent Semantic Emotion Aggregator (LSEA), computationally models the knowledge integration process, akin to the mechanism described by the Conceptual Act Theory. It aggregates sensory inputs and synthesizes them with learned conceptual knowledge, reflecting the role of the hippocampus and default mode network in constructing a coherent emotional experience. By explicitly modeling these neuro-cognitive mechanisms, DuSE provides a more neurally plausible and robust framework for dynamic facial expression recognition (DFER). Extensive experiments on challenging in-the-wild benchmarks validate our cognition-centric approach, demonstrating that emulating the brain's strategies for emotion processing yields state-of-the-art performance and enhances model interpretability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DuSE, a cognition-inspired dual-stream architecture for dynamic facial expression recognition (DFER). The Hierarchical Temporal Prompt Cluster (HTPC) stream is presented as operationalizing the cognitive priming effect by aligning textual semantics with fine-grained temporal facial dynamics. The Latent Semantic Emotion Aggregator (LSEA) stream is presented as modeling knowledge integration per Conceptual Act Theory by synthesizing sensory inputs with learned conceptual knowledge. The authors claim that explicitly instantiating these neuro-cognitive mechanisms yields state-of-the-art performance on in-the-wild benchmarks while improving model interpretability.
Significance. If the performance gains and interpretability improvements are shown to arise specifically from the claimed cognitive correspondences rather than generic dual-stream capacity, the work could meaningfully advance brain-inspired approaches to emotion modeling in computer vision. The absence of quantitative results, ablations, or statistical details in the abstract, however, prevents assessment of whether the result would hold or represent a substantive advance.
major comments (2)
- Abstract: the central claim that emulating the priming effect and Conceptual Act Theory via HTPC and LSEA produces SOTA DFER performance and enhanced interpretability is asserted without any quantitative metrics, ablation studies, error bars, or implementation details, rendering the claims unevaluable from the provided text.
- Method descriptions of HTPC and LSEA: the manuscript does not demonstrate that these components uniquely instantiate the cited cognitive processes in a way that explains the gains; the architecture could be replicated by any dual-stream model with cross-modal fusion and clustering, leaving open the possibility that improvements stem from added capacity rather than the claimed neuro-cognitive mechanisms.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We have revised the manuscript to address the concerns regarding the abstract and the justification for the cognitive correspondences in our architecture. Below we respond point by point.
read point-by-point responses
-
Referee: Abstract: the central claim that emulating the priming effect and Conceptual Act Theory via HTPC and LSEA produces SOTA DFER performance and enhanced interpretability is asserted without any quantitative metrics, ablation studies, error bars, or implementation details, rendering the claims unevaluable from the provided text.
Authors: We agree that the abstract should include quantitative support to allow immediate evaluation of the claims. In the revised manuscript we have updated the abstract to report key results, including accuracy improvements with standard deviations on the in-the-wild benchmarks, a brief summary of the ablation outcomes, and reference to the interpretability analyses. This change directly addresses the evaluability issue while preserving the abstract's length constraints. revision: yes
-
Referee: Method descriptions of HTPC and LSEA: the manuscript does not demonstrate that these components uniquely instantiate the cited cognitive processes in a way that explains the gains; the architecture could be replicated by any dual-stream model with cross-modal fusion and clustering, leaving open the possibility that improvements stem from added capacity rather than the claimed neuro-cognitive mechanisms.
Authors: We acknowledge the importance of distinguishing our design from generic dual-stream capacity increases. In the revised manuscript we have expanded the method section with explicit mechanistic details: HTPC implements priming through hierarchical temporal prompt clustering that pre-activates semantic pathways using linguistic cues before visual feature extraction, a step absent from standard cross-modal fusion; LSEA performs knowledge integration via latent semantic aggregation that synthesizes inputs with concept-specific embeddings drawn from emotion theory, rather than generic clustering. We have added new ablations comparing DuSE against capacity-matched generic dual-stream baselines (same parameter count, cross-modal fusion, and clustering), showing statistically significant gains (with p-values) attributable to the cognitive alignments. Interpretability visualizations further link attention patterns to priming and conceptual integration. While we recognize that proving strict uniqueness to neuro-cognitive processes remains an interpretive challenge given the analogical basis of the inspiration, the targeted ablations and design specificity provide stronger empirical grounding for our claims. revision: partial
Circularity Check
No significant circularity in claimed derivation chain
full rationale
The paper proposes DuSE as a dual-stream architecture with HTPC and LSEA components explicitly designed to correspond to cognitive mechanisms (priming effect and Conceptual Act Theory), then reports empirical SOTA results on DFER benchmarks. No equations, fitted parameters, or mathematical predictions are described that reduce by construction to the inputs. The cognitive mapping serves as interpretive motivation for the design rather than a closed self-definitional loop, and no self-citations or uniqueness claims are invoked as load-bearing justification. Performance claims rest on external experimental validation, rendering the chain self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Neural systems for recognizing emotion,
R. Adolphs, “Neural systems for recognizing emotion,”Current opin- ion in neurobiology, vol. 12, no. 2, pp. 169–177, 2002
work page 2002
-
[2]
Emotion-aware connected health- care big data towards 5g,
M. S. Hossain and G. Muhammad, “Emotion-aware connected health- care big data towards 5g,”IEEE Internet of Things Journal, vol. 5, no. 4, pp. 2399–2406, 2017
work page 2017
-
[3]
Z. Zhao, Q. Liu, and S. Wang, “Learning deep global multi-scale and local attention features for facial expression recognition in the wild,”IEEE Transactions on Image Processing, vol. 30, pp. 6544– 6556, 2021
work page 2021
-
[4]
Emotion recognition from unimodal to multimodal analysis: A review,
K. Ezzameli and H. Mahersia, “Emotion recognition from unimodal to multimodal analysis: A review,”Information Fusion, vol. 99, p. 101847, 2023
work page 2023
-
[5]
All rivers run into the sea: Unified modality brain-inspired emotional central mechanism,
X. Mai, J. Lin, H. Wang, Z. Tao, Y . Wang, S. Yan, X. Tong, J. Yu, B. Wang, Z. Zhouet al., “All rivers run into the sea: Unified modality brain-inspired emotional central mechanism,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 632– 641
work page 2024
-
[6]
A systematic review on affective computing: Emotion models, databases, and recent advances,
Y . Wang, W. Song, W. Tao, A. Liotta, D. Yang, X. Li, S. Gao, Y . Sun, W. Ge, W. Zhanget al., “A systematic review on affective computing: Emotion models, databases, and recent advances,”Information Fusion, vol. 83, pp. 19–52, 2022
work page 2022
-
[7]
D. Gündem, J. Poto ˇcnik, F.-L. De Winter, A. El Kaddouri, D. Stam, R. Peeters, L. Emsell, S. Sunaert, L. Van Oudenhove, M. Vanden- bulckeet al., “The neurobiological basis of affect is consistent with psychological construction theory and shares a common neural basis across emotional categories,”Communications Biology, vol. 5, no. 1, p. 1354, 2022
work page 2022
-
[8]
A. B. Gerdes, M. J. Wieser, and G. W. Alpers, “Emotional pictures and sounds: a review of multimodal interactions of emotion cues in multiple domains,”Frontiers in psychology, vol. 5, p. 1351, 2014
work page 2014
-
[9]
The brain and its time: intrinsic neural timescales are key for input processing,
M. Golesorkhi, J. Gomez-Pilar, F. Zilio, N. Berberian, A. Wolff, M. C. Yagoub, and G. Northoff, “The brain and its time: intrinsic neural timescales are key for input processing,”Communications biology, vol. 4, no. 1, p. 970, 2021
work page 2021
-
[10]
The cognitive– affective social processing and emotion regulation (casper) model,
M. C. Camacho, E. Deshpande, and M. T. Perino, “The cognitive– affective social processing and emotion regulation (casper) model,” Neuropsychopharmacology, pp. 1–17, 2025
work page 2025
-
[11]
Y . Wang, S. Yan, Y . Liu, W. Song, J. Liu, Y . Chang, X. Mai, X. Hu, W. Zhang, and Z. Gan, “A survey on facial expression recognition of static and dynamic emotions,”arXiv preprint arXiv:2408.15777, 2024
-
[12]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
work page 2021
-
[13]
Cliper: A unified vision-language framework for in-the-wild facial expression recognition,
H. Li, H. Niu, Z. Zhu, and F. Zhao, “Cliper: A unified vision-language framework for in-the-wild facial expression recognition,” in2024 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2024, pp. 1–6
work page 2024
-
[14]
Exploring regional clues in clip for zero-shot semantic segmentation,
Y . Zhang, M.-H. Guo, M. Wang, and S.-M. Hu, “Exploring regional clues in clip for zero-shot semantic segmentation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2024, pp. 3270–3280
work page 2024
-
[15]
The unbearable automaticity of being
J. A. Bargh and T. L. Chartrand, “The unbearable automaticity of being.”American psychologist, vol. 54, no. 7, p. 462, 1999
work page 1999
-
[16]
The theory of constructed emotion: an active inference account of interoception and categorization,
L. F. Barrett, “The theory of constructed emotion: an active inference account of interoception and categorization,”Social cognitive and affective neuroscience, vol. 12, no. 1, pp. 1–23, 2017
work page 2017
-
[17]
Hierarchical process memory: memory as an integral component of information processing,
U. Hasson, J. Chen, and C. J. Honey, “Hierarchical process memory: memory as an integral component of information processing,”Trends in cognitive sciences, vol. 19, no. 6, pp. 304–313, 2015
work page 2015
-
[18]
The neurobiology of semantic memory,
J. R. Binder and R. H. Desai, “The neurobiology of semantic memory,” Trends in cognitive sciences, vol. 15, no. 11, pp. 527–536, 2011
work page 2011
-
[19]
S. R. Livingstone and F. A. Russo, “The ryerson audio-visual database of emotional speech and song (ravdess): A dynamic, multimodal set of facial and vocal expressions in north american english,”PloS one, vol. 13, no. 5, p. e0196391, 2018
work page 2018
-
[20]
Dfew: A large-scale database for recognizing dynamic facial expres- sions in the wild,
X. Jiang, Y . Zong, W. Zheng, C. Tang, W. Xia, C. Lu, and J. Liu, “Dfew: A large-scale database for recognizing dynamic facial expres- sions in the wild,” inProceedings of the 28th ACM international conference on multimedia, 2020, pp. 2881–2889
work page 2020
-
[21]
Ferv39k: A large-scale multi-scene dataset for facial expression recognition in videos,
Y . Wang, Y . Sun, Y . Huang, Z. Liu, S. Gao, W. Zhang, W. Ge, and W. Zhang, “Ferv39k: A large-scale multi-scene dataset for facial expression recognition in videos,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 20 922–20 931
work page 2022
-
[22]
Learning spatiotemporal features with 3d convolutional networks,
D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, “Learning spatiotemporal features with 3d convolutional networks,” inProceed- ings of the IEEE international conference on computer vision, 2015, pp. 4489–4497
work page 2015
-
[23]
The power of scale for parameter-efficient prompt tuning,
B. Lester, R. Al-Rfou, and N. Constant, “The power of scale for parameter-efficient prompt tuning,” inProceedings of the 2021 Con- ference on Empirical Methods in Natural Language Processing, 2021, pp. 3045–3059
work page 2021
-
[24]
Recent advancements and challenges of nlp- based sentiment analysis: A state-of-the-art review,
J. R. Jim, M. A. R. Talukder, P. Malakar, M. M. Kabir, K. Nur, and M. F. Mridha, “Recent advancements and challenges of nlp- based sentiment analysis: A state-of-the-art review,”Natural Language Processing Journal, p. 100059, 2024
work page 2024
-
[25]
Conditional prompt learning for vision-language models,
K. Zhou, J. Yang, C. C. Loy, and Z. Liu, “Conditional prompt learning for vision-language models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 16 816–16 825
work page 2022
-
[26]
M. Jia, L. Tang, B.-C. Chen, C. Cardie, S. Belongie, B. Hariharan, and S.-N. Lim, “Visual prompt tuning,” inEuropean conference on computer vision. Springer, 2022, pp. 709–727
work page 2022
-
[27]
Maple: Multi-modal prompt learning,
M. U. Khattak, H. Rasheed, M. Maaz, S. Khan, and F. S. Khan, “Maple: Multi-modal prompt learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 19 113–19 122
work page 2023
-
[28]
Knowledge transfer for cross-domain reinforcement learning: a systematic review,
S. A. Serrano, J. Martinez-Carranza, and L. E. Sucar, “Knowledge transfer for cross-domain reinforcement learning: a systematic review,” IEEE Access, 2024
work page 2024
-
[29]
J. Han, Z. Zhang, N. Cummins, and B. Schuller, “Adversarial training in affective computing and sentiment analysis: Recent advances and perspectives,”IEEE Computational Intelligence Magazine, vol. 14, no. 2, pp. 68–81, 2019
work page 2019
-
[30]
Disentangled representation learning for multimodal emotion recognition,
D. Yang, S. Huang, H. Kuang, Y . Du, and L. Zhang, “Disentangled representation learning for multimodal emotion recognition,” inPro- ceedings of the 30th ACM international conference on multimedia, 2022, pp. 1642–1651
work page 2022
-
[31]
Ceprompt: Cross-modal emotion-aware prompting for facial expression recognition,
H. Zhou, S. Huang, F. Zhang, and C. Xu, “Ceprompt: Cross-modal emotion-aware prompting for facial expression recognition,”IEEE Transactions on Circuits and Systems for Video Technology, 2024
work page 2024
-
[32]
Learning spatio-temporal representation with pseudo-3d residual networks,
Z. Qiu, T. Yao, and T. Mei, “Learning spatio-temporal representation with pseudo-3d residual networks,” inproceedings of the IEEE Inter- national Conference on Computer Vision, 2017, pp. 5533–5541
work page 2017
-
[33]
Quo vadis, action recognition? a new model and the kinetics dataset,
J. Carreira and A. Zisserman, “Quo vadis, action recognition? a new model and the kinetics dataset,” inproceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 6299–6308
work page 2017
-
[34]
A closer look at spatiotemporal convolutions for action recognition,
D. Tran, H. Wang, L. Torresani, J. Ray, Y . LeCun, and M. Paluri, “A closer look at spatiotemporal convolutions for action recognition,” in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2018, pp. 6450–6459
work page 2018
-
[35]
Former-dfer: Dynamic facial expression recog- nition transformer,
Z. Zhao and Q. Liu, “Former-dfer: Dynamic facial expression recog- nition transformer,” inProceedings of the 29th ACM international conference on multimedia, 2021, pp. 1553–1561
work page 2021
-
[36]
Nr-dfernet: Noise-robust network for dy- namic facial expression recognition,
H. Li, M. Sui, Z. Zhuet al., “Nr-dfernet: Noise-robust net- work for dynamic facial expression recognition,”arXiv preprint arXiv:2206.04975, 2022
-
[37]
Y . Wang, Y . Sun, W. Song, S. Gao, Y . Huang, Z. Chen, W. Ge, and W. Zhang, “Dpcnet: Dual path multi-excitation collaborative network for facial expression representation learning in videos,” inProceedings of the 30th ACM international conference on multimedia, 2022, pp. 101–110
work page 2022
-
[38]
Ex- pression snippet transformer for robust video-based facial expression recognition,
Y . Liu, W. Wang, C. Feng, H. Zhang, Z. Chen, and Y . Zhan, “Ex- pression snippet transformer for robust video-based facial expression recognition,”Pattern Recognition, vol. 138, p. 109368, 2023
work page 2023
-
[39]
Logo-former: Local-global spatio-temporal transformer for dynamic facial expression recognition,
F. Ma, B. Sun, and S. Li, “Logo-former: Local-global spatio-temporal transformer for dynamic facial expression recognition,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
work page 2023
-
[40]
Intensity-aware loss for dynamic facial expression recognition in the wild,
H. Li, H. Niu, Z. Zhu, and F. Zhao, “Intensity-aware loss for dynamic facial expression recognition in the wild,” inProceedings of the AAAI conference on artificial intelligence, vol. 37, no. 1, 2023, pp. 67–75
work page 2023
-
[41]
Multi-scale correlation module for video-based facial expression recognition in the wild,
T. Li, K.-L. Chan, and T. Tjahjadi, “Multi-scale correlation module for video-based facial expression recognition in the wild,”Pattern Recognition, vol. 142, p. 109691, 2023
work page 2023
-
[42]
Rethinking the learning paradigm for dynamic facial expression recognition,
H. Wang, B. Li, S. Wu, S. Shen, F. Liu, S. Ding, and A. Zhou, “Rethinking the learning paradigm for dynamic facial expression recognition,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 17 958–17 968
work page 2023
-
[43]
Frame level emotion guided dynamic facial expression recognition with emotion grouping,
B. Lee, H. Shin, B. Ku, and H. Ko, “Frame level emotion guided dynamic facial expression recognition with emotion grouping,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 5681–5691
work page 2023
-
[44]
Prompting visual-language models for dynamic facial expression recognition,
Z. Zhao and I. Patras, “Prompting visual-language models for dynamic facial expression recognition,” inBMVC, 2023
work page 2023
-
[45]
Mae-dfer: Efficient masked autoencoder for self-supervised dynamic facial expression recogni- tion,
L. Sun, Z. Lian, B. Liu, and J. Tao, “Mae-dfer: Efficient masked autoencoder for self-supervised dynamic facial expression recogni- tion,” inProceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 6110–6121
work page 2023
-
[46]
Emoclip: A vision-language method for zero-shot video facial expression recognition,
N. M. Foteinopoulou and I. Patras, “Emoclip: A vision-language method for zero-shot video facial expression recognition,” in2024 IEEE 18th International Conference on Automatic Face and Gesture Recognition (FG). IEEE, 2024, pp. 1–10
work page 2024
-
[47]
S. Yan, Y . Wang, X. Mai, Q. Zhao, W. Song, J. Huang, Z. Tao, H. Wang, S. Gao, and W. Zhang, “Empower smart cities with sampling-wise dynamic facial expression recognition via frame- sequence contrastive learning,”Computer Communications, vol. 216, pp. 130–139, 2024
work page 2024
-
[48]
Cdgt: Constructing diverse graph transformers for emotion recognition from facial videos,
D. Chen, G. Wen, H. Li, P. Yang, C. Chen, and B. Wang, “Cdgt: Constructing diverse graph transformers for emotion recognition from facial videos,”Neural Networks, vol. 179, p. 106573, 2024
work page 2024
-
[49]
A joint local spatial and global temporal cnn-transformer for dynamic facial expression recognition,
L. Wang, X. Kang, F. Ding, S. Nakagawa, and F. Ren, “A joint local spatial and global temporal cnn-transformer for dynamic facial expression recognition,”Applied Soft Computing, vol. 161, p. 111680, 2024
work page 2024
-
[50]
L. Sun, Z. Lian, B. Liu, and J. Tao, “Hicmae: Hierarchical contrastive masked autoencoder for self-supervised audio-visual emotion recog- nition,”Information Fusion, vol. 108, p. 102382, 2024. Appendix ADDITIONALVISUALIZATION We have supplemented DuSE’s t-SNE visualization results on DFEW in Figure 6 to demonstrate its overall performance on a real-world ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.