Recognition: no theorem link
Text-as-Signal: Quantitative Semantic Scoring with Embeddings, Logprobs, and Noise Reduction
Pith reviewed 2026-05-15 09:26 UTC · model grok-4.3
The pith
A pipeline turns text corpora into quantitative semantic signals using embeddings, logprob scoring, and manifold projection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Combining Qwen embeddings, logprob-based scoring over a positional dictionary, UMAP projection after noise reduction, and a three-stage anomaly-detection procedure yields an operational text-as-signal pipeline that supports document-level semantic positioning and corpus-level characterization for AI engineering applications such as corpus inspection and monitoring.
What carries the argument
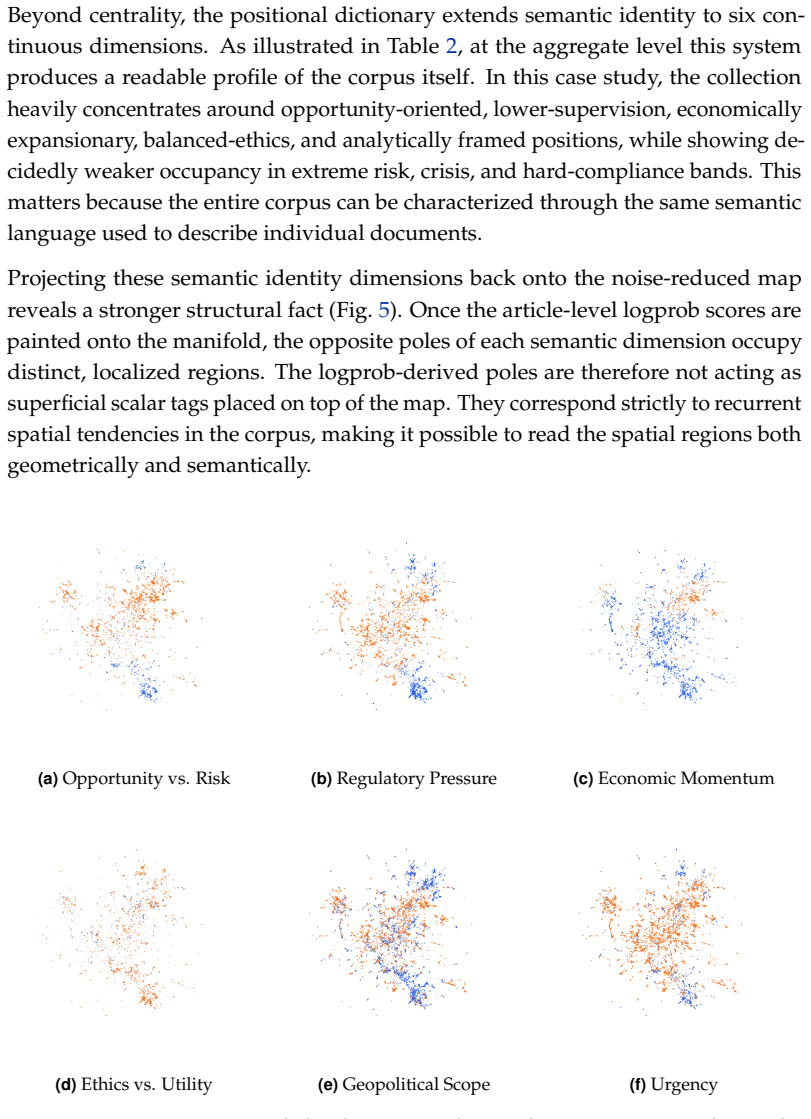
The text-as-signal workflow that scores full-document embeddings through logprobs on a configurable positional dictionary and projects the scores onto a low-dimensional manifold for structural interpretation.
Load-bearing premise
Logprob scores derived from the positional dictionary remain semantically meaningful and stable after projection onto the noise-reduced manifold without systematic bias from the language model.
What would settle it
Human raters independently scoring a sample of the same documents on the six semantic dimensions and finding low correlation with the pipeline outputs would show the signals are not semantically meaningful.
Figures




read the original abstract
This paper presents a practical pipeline for turning text corpora into quantitative semantic signals. Each news item is represented as a full-document embedding, scored through logprob-based evaluation over a configurable positional dictionary, and projected onto a noise-reduced low-dimensional manifold for structural interpretation. In the present case study, the dictionary is instantiated as six semantic dimensions and applied to a corpus of 11,922 Portuguese news articles about Artificial Intelligence. The resulting identity space supports both document-level semantic positioning and corpus-level characterization through aggregated profiles. We show how Qwen embeddings, UMAP, semantic indicators derived directly from the model output space, and a three-stage anomaly-detection procedure combine into an operational text-as-signal workflow for AI engineering tasks such as corpus inspection, monitoring, and downstream analytical support. Because the identity layer is configurable, the same framework can be adapted to the requirements of different analytical streams rather than fixed to a universal schema.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a practical pipeline for converting text corpora into quantitative semantic signals. Each document receives a full embedding from the Qwen model, is scored via log-probabilities against a configurable positional dictionary (instantiated here with six semantic dimensions), and is projected via UMAP onto a noise-reduced manifold; a three-stage anomaly-detection step then supports structural interpretation. The workflow is demonstrated on a corpus of 11,922 Portuguese news articles about artificial intelligence, yielding document-level positioning and aggregated corpus profiles intended for AI-engineering tasks such as inspection, monitoring, and downstream analysis. The framework is explicitly configurable rather than tied to a universal schema.
Significance. If the logprob-derived scores prove stable and semantically meaningful after projection, the approach supplies a reusable, training-free workflow that combines off-the-shelf embeddings, dictionary-based scoring, and standard dimensionality reduction for domain-specific corpus analysis. Its configurability is a practical strength for adapting the same pipeline to different analytical needs without retraining models.
major comments (3)
- [Case Study] Case Study section: the manuscript demonstrates the pipeline on a single corpus but supplies no quantitative validation metrics (e.g., correlation with human semantic judgments, inter-annotator agreement, or downstream task performance), error analysis of the logprob scores, or comparisons against baselines such as direct embedding clustering or TF-IDF. This absence is load-bearing for the central claim of operational utility.
- [Methodology] Methodology (pipeline description): the three-stage anomaly-detection procedure is described at a high level without specifying the exact statistical criteria, thresholds, or decision rules applied in each stage. These details are required to assess whether the procedure genuinely reduces noise or merely filters according to arbitrary cut-offs.
- [Abstract and Methodology] Abstract and Methodology: the claim that logprob scoring against the positional dictionary produces 'semantically meaningful and stable quantitative signals' is asserted without any empirical test for systematic bias introduced by the underlying language model or for stability across different dictionary instantiations.
minor comments (2)
- [Methodology] The notation for the six semantic dimensions and the exact construction of the positional dictionary should be formalized (e.g., as a table or explicit list) to improve reproducibility.
- Standard references for UMAP and the Qwen model family are missing from the bibliography.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and indicate where revisions will be incorporated to strengthen the manuscript.
read point-by-point responses
-
Referee: [Case Study] Case Study section: the manuscript demonstrates the pipeline on a single corpus but supplies no quantitative validation metrics (e.g., correlation with human semantic judgments, inter-annotator agreement, or downstream task performance), error analysis of the logprob scores, or comparisons against baselines such as direct embedding clustering or TF-IDF. This absence is load-bearing for the central claim of operational utility.
Authors: We acknowledge that the case study is primarily illustrative. To address the concern for quantitative support of operational utility, the revised manuscript will add baseline comparisons using TF-IDF and direct embedding clustering with metrics such as silhouette scores, plus a basic error analysis of logprob outliers. Full human judgment correlation is noted as a limitation for future work given resource constraints. revision: yes
-
Referee: [Methodology] Methodology (pipeline description): the three-stage anomaly-detection procedure is described at a high level without specifying the exact statistical criteria, thresholds, or decision rules applied in each stage. These details are required to assess whether the procedure genuinely reduces noise or merely filters according to arbitrary cut-offs.
Authors: We agree the description requires more precision. The revised Methodology section will specify the exact statistical criteria, thresholds (e.g., z-score thresholds and density parameters), and decision rules for each of the three stages to allow replication and evaluation of noise reduction. revision: yes
-
Referee: [Abstract and Methodology] Abstract and Methodology: the claim that logprob scoring against the positional dictionary produces 'semantically meaningful and stable quantitative signals' is asserted without any empirical test for systematic bias introduced by the underlying language model or for stability across different dictionary instantiations.
Authors: The claim follows from the direct use of model log-probabilities for alignment quantification. To address bias and stability concerns, the revision will add analysis of score stability across dictionary variants and qualitative discussion of potential LM biases with corpus examples. The abstract wording will be qualified to reflect the demonstrated case-study results. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper presents an operational pipeline that applies off-the-shelf components (Qwen embeddings, UMAP projection, logprob scoring over a user-supplied positional dictionary, and standard anomaly detection) to a corpus without any formal derivation, optimality proof, or self-referential fitting step. No equation reduces a claimed prediction to a fitted parameter by construction, no uniqueness theorem is imported from self-citation, and the dictionary itself is explicitly configurable rather than derived from the target data. The central claim is therefore a practical workflow whose validity rests on external model behavior and user-defined inputs, not on internal redefinition.
Axiom & Free-Parameter Ledger
free parameters (1)
- Number of semantic dimensions
axioms (2)
- domain assumption Qwen embeddings capture document-level semantics sufficiently for downstream scoring
- domain assumption Log probabilities from the model can be meaningfully aggregated against a positional dictionary
Reference graph
Works this paper leans on
-
[1]
BERTopic: Neural topic modeling with a class-based TF-IDF procedure
Maarten Grootendorst. “BERTopic: Neural topic modeling with a class-based TF-IDF procedure”. In:arXiv preprint arXiv:2203.05794(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Leland McInnes, John Healy, and James Melville. “UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction”. In:arXiv preprint arXiv:1802.03426(2018).URL:https://arxiv.org/abs/1802.03426
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
The Mean-Difference: A Simple and Effective Method for Zero-Shot Classification
Eric Wallace et al. “The Mean-Difference: A Simple and Effective Method for Zero-Shot Classification”. In:arXiv preprint arXiv:2403.14859(2024).URL: https://arxiv.org/abs/2403.14859
-
[4]
MTEB: Massive Text Embedding Benchmark
Niklas Muennighoff et al. “MTEB: Massive Text Embedding Benchmark”. In: arXiv preprint arXiv:2210.07316(2023).URL: https : / / arxiv . org / abs / 2210.07316
work page internal anchor Pith review arXiv 2023
-
[5]
Hugging Face.URL: https://huggingface.co/ spaces/mteb/leaderboard(visited on 03/07/2026)
MTEB.MTEB Leaderboard. Hugging Face.URL: https://huggingface.co/ spaces/mteb/leaderboard(visited on 03/07/2026)
work page 2026
-
[6]
Estimating the intrinsic dimension of datasets by a minimal neighborhood information
Elena Facco et al. “Estimating the intrinsic dimension of datasets by a minimal neighborhood information”. In:Scientific Reports7.1 (2017).ISSN: 2045-2322. DOI: 10.1038/s41598- 017- 11873- y.URL: http://dx.doi.org/10. 1038/s41598-017-11873-y. 13
-
[7]
Lukas Ruff et al. “Deep one-class classification”. In:International conference on machine learning. PMLR. 2018, pp. 4393–4402
work page 2018
-
[8]
Scan: a structural clustering algorithm for networks
Xiaowei Xu et al. “Scan: a structural clustering algorithm for networks”. In:Pro- ceedings of the 13th ACM SIGKDD international conference on Knowledge discovery and data mining. 2007, pp. 824–833. 14
work page 2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.