Recognition: no theorem link
Dental-TriageBench: Benchmarking Multimodal Reasoning for Hierarchical Dental Triage
Pith reviewed 2026-05-15 10:18 UTC · model grok-4.3
The pith
Current multimodal models fall short of junior dentists when building complete referral plans from patient complaints and X-rays.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Dental-TriageBench contains 246 de-identified cases drawn from authentic workflows, each annotated with expert golden reasoning trajectories and hierarchical triage labels that specify both broad categories and fine-grained treatment referrals. When 19 proprietary, open-source, and medical MLLMs are evaluated against junior-dentist baselines, models exhibit a substantial gap on treatment-level triage, producing overly narrow referral sets and omission-heavy errors precisely on cases that span multiple referral domains. Accurate performance requires joint use of complaint text and OPG images, confirming that the benchmark isolates the integration step that current models handle poorly.
What carries the argument
Dental-TriageBench, the dataset of 246 expert-annotated multimodal cases with hierarchical referral labels and golden reasoning trajectories that directly tests coverage and completeness of triage decisions.
If this is right
- Accurate dental triage requires models to jointly process complaint text and radiographic images rather than relying on either modality alone.
- Model errors concentrate on multi-domain cases, indicating that current systems under-generate referral options when several specialties are appropriate.
- The observed human-model gap at the fine-grained treatment level points to the need for explicit coverage mechanisms in referral generation.
- The benchmark supplies concrete targets for training or fine-tuning that aim to reduce omission errors in safety-critical routing.
Where Pith is reading between the lines
- Similar gaps are likely to appear in other medical specialties that combine text notes with imaging for layered referral decisions.
- The expert reasoning trajectories could serve as supervision signals to train models that explicitly list all appropriate domains before selecting treatments.
- Deployment tests that track downstream patient outcomes would reveal whether the benchmark's coverage metric predicts real-world safety.
- Extending the hierarchical label structure to time-sensitive or resource-limited settings could expose additional failure modes not captured in outpatient data.
Load-bearing premise
The 246 de-identified cases and their expert-authored labels faithfully represent the range of decisions made in real outpatient dental triage.
What would settle it
A follow-up evaluation on several hundred fresh, live clinical cases in which one or more tested models reach or exceed the junior-dentist referral coverage rate on the same hierarchical label set.
Figures











read the original abstract
Dental triage is a safety-critical clinical routing task that requires integrating multimodal clinical information (e.g., patient complaints and radiographic evidence) to determine complete referral plans. We present Dental-TriageBench, the first expert-annotated benchmark for reasoning-driven multimodal dental triage. Built from authentic outpatient workflows, it contains 246 de-identified cases annotated with expert-authored golden reasoning trajectories, together with hierarchical triage labels. We benchmark 19 proprietary, open-source, and medical-domain MLLMs against three junior dentists serving as the human baseline, and find a substantial human--model gap, on fine-grained treatment-level triage. Further analyses show that accurate triage requires both complaint and OPG information, and that model errors concentrate on cases with multiple referral domains, where MLLMs tend to produce overly narrow referral sets and omission-heavy errors. Dental-TriageBench provides a realistic testbed for developing multimodal clinical AI systems that are more clinically grounded, coverage-aware, and safer for downstream care.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Dental-TriageBench, the first expert-annotated benchmark for multimodal dental triage, comprising 246 de-identified outpatient cases with expert-authored golden reasoning trajectories and hierarchical triage labels. It evaluates 19 proprietary, open-source, and medical-domain MLLMs against a human baseline of three junior dentists, reporting a substantial performance gap on fine-grained treatment-level triage. Analyses indicate that accurate triage requires both complaint and OPG information, with model errors concentrating on multi-domain cases where MLLMs produce overly narrow referral sets and omission-heavy errors.
Significance. If the benchmark construction is shown to faithfully represent real outpatient workflows, the reported human-model gap and specific error patterns would provide a valuable, realistic testbed for developing safer, coverage-aware multimodal clinical AI systems. The work highlights concrete limitations in current MLLMs for integrating multimodal inputs in a safety-critical routing task and could inform targeted improvements in referral completeness.
major comments (2)
- [Benchmark construction] Benchmark construction section: No inter-annotator agreement statistics, explicit case-selection criteria, or quantitative comparison of referral-domain distributions against clinic-wide or published dental-triage statistics are reported for the 246 cases and expert-authored labels. This directly undermines the central claim that the observed gap (narrow referrals and omissions on multi-domain cases) generalizes beyond this specific set rather than reflecting an artifact of the chosen distribution.
- [Experiments and results] Experiments and results section: The human baseline consists of only three junior dentists with no reported error bars, confidence intervals, or statistical tests (e.g., significance of the gap on fine-grained triage metrics). This leaves the 'substantial human-model gap' finding only partially supported, especially given the small sample and the paper's emphasis on the gap as a key result.
minor comments (3)
- [Abstract] Abstract: The description of hierarchical triage labels and evaluation metrics could be expanded with one sentence specifying the exact hierarchy levels and primary scoring criteria used for the gap analysis.
- [Error analysis] Error analysis: The concentration of errors on multi-domain cases is noted, but a table or figure quantifying the distribution of single- vs. multi-domain cases in the benchmark (and model omission rates per domain) would improve clarity and reproducibility.
- [Related work] Related work: Consider adding citations to prior multimodal medical benchmarks (e.g., in radiology or general triage) to better situate Dental-TriageBench's novelty in hierarchical referral planning.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the presentation of Dental-TriageBench. We address each major comment below and will revise the manuscript to incorporate additional details and analyses where feasible.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction section: No inter-annotator agreement statistics, explicit case-selection criteria, or quantitative comparison of referral-domain distributions against clinic-wide or published dental-triage statistics are reported for the 246 cases and expert-authored labels. This directly undermines the central claim that the observed gap (narrow referrals and omissions on multi-domain cases) generalizes beyond this specific set rather than reflecting an artifact of the chosen distribution.
Authors: We acknowledge the absence of these details in the original submission. In revision, we will add inter-annotator agreement statistics (e.g., Cohen's kappa) computed during the expert annotation process for the hierarchical labels and reasoning trajectories. We will also expand the benchmark construction section with explicit case-selection criteria, including how the 246 de-identified outpatient cases were sampled from real workflows while preserving privacy. For referral-domain distributions, clinic-wide statistics are unavailable due to institutional data-access restrictions; however, we will include a quantitative comparison against published dental-triage studies to better support generalizability claims. These additions will directly address concerns about potential artifacts in the observed error patterns. revision: partial
-
Referee: [Experiments and results] Experiments and results section: The human baseline consists of only three junior dentists with no reported error bars, confidence intervals, or statistical tests (e.g., significance of the gap on fine-grained triage metrics). This leaves the 'substantial human-model gap' finding only partially supported, especially given the small sample and the paper's emphasis on the gap as a key result.
Authors: We agree that the human baseline is small and that variability measures and statistical tests were omitted. In the revised manuscript, we will report error bars (standard errors) and 95% confidence intervals for all human performance metrics on the hierarchical triage tasks. We will also conduct and report appropriate statistical tests (e.g., paired Wilcoxon signed-rank tests) to evaluate the significance of the model-human gaps, particularly on fine-grained treatment-level triage. While the sample of three junior dentists reflects practical constraints of recruiting domain experts for this safety-critical task, we will explicitly discuss this as a limitation and note that the gap remains directionally consistent across metrics. revision: yes
Circularity Check
No circularity; pure empirical benchmark with no derivations
full rationale
The paper constructs and releases an empirical benchmark dataset of 246 de-identified cases with expert-authored labels and reasoning trajectories, then directly evaluates 19 MLLMs against a human baseline of three junior dentists. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the derivation of any result. All reported gaps and error patterns are computed from explicit comparisons on the held-out cases. The representativeness of the 246 cases is an external-validity question, not a reduction of any claimed derivation to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert-authored golden reasoning trajectories and hierarchical triage labels are accurate and reliable representations of clinical decisions.
Reference graph
Works this paper leans on
-
[1]
InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
IPAD: Inverse prompt for AI detection - a robust and interpretable LLM-generated text detector. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. Zhihong Chen, Maya Varma, Justin Xu, Mag- dalini Paschali, Dave Van Veen, Andrew Johnston, Alaa Youssef, Louis Blankemeier, Christian Blueth- gen, Stephan Altmayer, and 1 others. 202...
-
[2]
Triageagent: Towards better multi-agents collab- orations for large language model-based clinical triage. InFindings of the Association for Computational Lin- guistics: EMNLP 2024, Miami, Florida, USA, Novem- ber 12-16, 2024, volume EMNLP 2024 ofFindings of ACL, pages 5747–5764. Association for Computational Linguistics. Lars Masanneck, Linea Schmidt, Ant...
-
[3]
Climedbench: A large-scale chinese benchmark for evaluating medical large language models in clini- cal scenarios. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Process- ing, EMNLP 2024, Miami, FL, USA, November 12-16, 2024, pages 8428–8438. Association for Computational Linguistics. Andrew Sellergren, Sahar Kazemzadeh, Tia...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Applications of artificial intelligence in the anal- ysis of dental panoramic radiographs: an overview of systematic reviews.Dentomaxillofacial Radiology, 52(7):20230284. N. van Nistelrooij, K. E. Ghoul, T. Xi, A. Saha, S. Kem- pers, M. Cenci, B. Loomans, T. Flügge, B. van Gin- neken, and S. Vinayahalingam. 2024. Combining public datasets for automated to...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
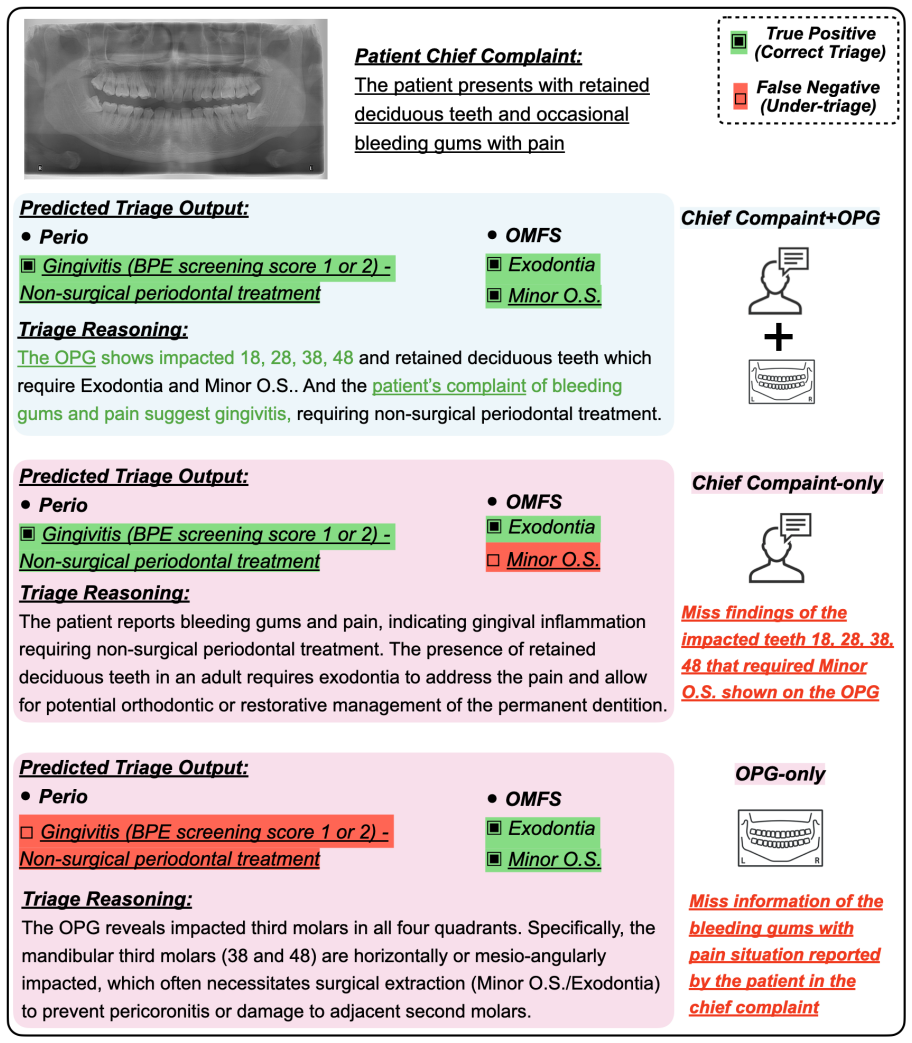
retained deciduous teeth and occasional bleeding gums with pain
Llmeval-med: A real-world clinical benchmark for medical llms with physician validation. InFind- ings of the Association for Computational Linguistics: EMNLP 2025, Suzhou, China, November 4-9, 2025, pages 4888–4914. Association for Computational Lin- guistics. Tianhong Zhou, Yin Xu, Yingtao Zhu, Chuxi Xiao, Haiyang Bian, Lei Wei, and Xuegong Zhang. 2025. ...
work page 2025
-
[6]
Other OMFS Consult includes the following items: Tumors, cysts, TMJ, fractures, mucosal lesions
-
[7]
Bear in mind that there could be multiple triage/treatment labels that are relevant to the patient, meaning that the patient has multiple conditions or needs multiple treatments
-
[8]
Your output should be a json object that is strictly formatted to the above json format, please do not add any other text or comments to the output or add any new keys to the json object. The chief complaint: {chief_complaint} And the OPG image is: Table 5: The task insturction prompt for model inference 22 Prompt for task instruction for model inference ...
-
[9]
The orginal model output might not contain all the keys in the json object, for those keys that are not present in the original model output, you should set the value to 0
-
[10]
Any other free text that is not related to the key-value pairs, you should convert them to the reasoning field if that makes sense
-
[11]
Analyze the patient's chief complaint, medical history, and OPG image
The orignial input to the model is:'You are a triage expert. Analyze the patient's chief complaint, medical history, and OPG image. Output the triage decision strictly in JSON format.' Now the original model output is: {model_output} Table 6: The prompt for standardizing model output 23 Prompt for llm as judge for failure analysis # Role You are an expert...
-
[12]
[Patient Input]: - Chief Complaint: {chief_complaint}
-
[13]
[Label Discrepancies] (Crucial for Evaluation): - Missing Labels (False Negatives - model failed to predict): {missing_labels} - Extra Labels (False Positives - model wrongly predicted): {extra_labels}
-
[14]
[Ground Truth (GT)]: - GT Reasoning: {gt_reasoning}
-
[15]
Do NOT use label discrepancies as the sole trigger for finding errors
[Model]: - Model Reasoning: {model_reasoning} # Core Evaluation Philosophy (Doctor's Workflow) **CRITICAL:** You must evaluate the model primarily based on its **[Model Reasoning]** compared to the **[GT Reasoning]**. Do NOT use label discrepancies as the sole trigger for finding errors. - Example: If the model fabricates a tooth in its reasoning, it is a...
-
[16]
**Did the model fabricate something? -> D5.** (e.g., mentions an impacted lower wisdom tooth that isn't there, or invents a symptom)
-
[17]
**Did the model completely ignore the core text symptom? -> D1.**
-
[18]
**Did the model completely fail to mention an important OPG finding? -> D2.** (e.g., GT mentions generalized bone loss or caries on tooth 11, but the model reasoning never mentions it)
-
[19]
**Did the model mention the correct finding but misjudge its physical severity/nature? -> D3.** (e.g., GT says "caries into pulp", but model says "superficial caries"; GT says "severe periodontitis", but model says "mild")
-
[20]
score", output strictly 1 or 0. For the
**Did the model perceive EVERYTHING correctly about a lesion (NO D1, D2, or D3 errors), but simply assigned the wrong final Triage label? -> ONLY THEN tag D4.** # The 5 Error Dimensions Definitions: **[Text] D1: Chief Complaint Neglect** - The model's reasoning completely ignores the core symptoms/requests in the [Patient Input]. **[OPG] D2: OPG Finding O...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.