Recognition: no theorem link
From Seeing it to Experiencing it: Interactive Evaluation of Intersectional Voice Bias in Human-AI Speech Interaction
Pith reviewed 2026-05-15 07:56 UTC · model grok-4.3
The pith
Voice conversion in interactive studies increases user trust in AI speech responses and highlights intersectional accent and gender biases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By combining judge-free metrics with an interactive setup where voice conversion lets participants hear identical AI outputs voiced as different accents and genders, the work finds that this experience raises trust and acceptability for neutral responses while promoting perspective-taking, and that automated metrics detect accent-by-gender differences in response alignment and verbosity.
What carries the argument
Voice conversion to let users experience the same content through different vocal identities, paired with automated prompt-response metrics for alignment and verbosity to detect quality-of-service disparities.
Load-bearing premise
The key assumption is that changing a voice to sound like a different accent or gender does not introduce other changes that affect how people judge the AI's response, and that the automatic measurements fully show the service quality differences that users experience.
What would settle it
A test where participants rate the naturalness of the voice-converted audio samples independently of the content to check for confounding artifacts, or where the automated alignment and verbosity scores are compared directly to human judgments of response quality.
Figures


read the original abstract
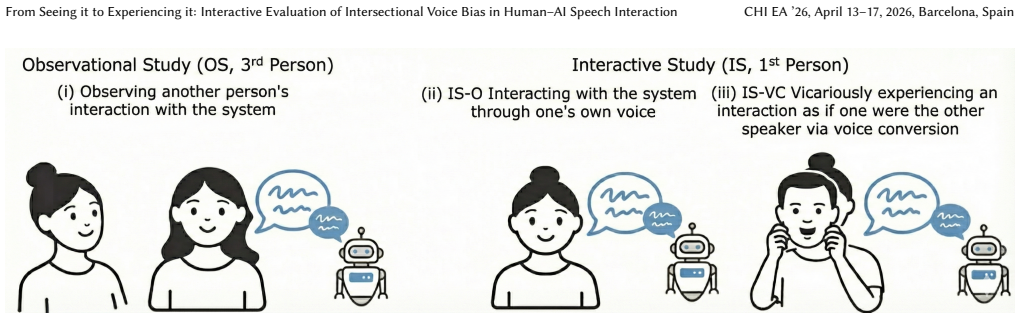
SpeechLLMs process spoken language directly from audio, but accent and vocal identity cues can lead to biased behaviour. Current bias evaluations often miss how such bias manifests in end-to-end speech interactions and how users experience it. We distinguish quality-of-service disparities (e.g., off-topic or low-effort responses) from content-level bias in coherent outputs, and examine intersectional effects of accent and perceived gender. In this work, we explore a two-part evaluation approach: (1) a controlled test cohort spanning six accents and two gender presentations, analysed with judge-free prompt-response metrics, and (2) an interactive study design using voice conversion to let users experience identical content through different vocal identities. Across two studies (Interactive, N=24; Observational, N=19), we find that voice conversion increases trust and acceptability for benign responses and encourages perspective-taking, while automated analysis in search of quality-of-service disparities, reveals {accent x gender} disparities in alignment and verbosity across SpeechLLMs. These results highlight voice conversion for probing and experiencing intersectional voice bias while our evaluation suite provides richer bias evaluations for spoken conversational AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that SpeechLLMs exhibit intersectional voice bias (accent x perceived gender) in end-to-end interactions, shown via (1) automated judge-free metrics revealing disparities in alignment and verbosity across a six-accent, two-gender cohort and (2) an interactive study (N=24) where voice conversion of identical benign responses increases user trust, acceptability, and perspective-taking, with a supporting observational study (N=19).
Significance. If the causal claims hold after addressing confounds, the work offers a novel interactive paradigm for users to experience rather than merely observe voice bias, plus a practical judge-free evaluation suite that separates quality-of-service disparities from content bias; this could meaningfully advance bias auditing for conversational speech AI beyond static text or single-accent tests.
major comments (3)
- [Interactive Study / Methods] Interactive study (N=24): the central claim that voice conversion increases trust/acceptability and encourages perspective-taking assumes converted voices isolate accent/gender identity without audible artifacts (unnatural prosody, timbre shifts, or intelligibility loss) that independently drive ratings; the manuscript appears to lack a control condition reporting naturalness/clarity ratings or artifact detection on the stimuli, directly threatening causal interpretation of the trust differences.
- [Observational Study / Automated Metrics] Automated analysis section: the reported {accent x gender} disparities in alignment and verbosity rest on judge-free prompt-response metrics whose exact definitions, aggregation rules, and statistical tests (including multiple-comparison correction and effect sizes) are not detailed in the abstract or visible methods summary; without these, it is impossible to verify whether the observed differences support the quality-of-service bias claims.
- [Results] Results and discussion: both studies use modest samples (N=24 and N=19) without reported power analysis or pre-registration; this weakens the generalizability of the intersectional disparity and perspective-taking findings, especially given the free parameters in accent/gender selection.
minor comments (2)
- [Abstract] The notation {accent x gender} is non-standard and should be defined explicitly on first use (e.g., 'accent-by-gender interaction').
- [Figures] Figure captions and axis labels for any automated metric plots should include the precise metric formulas and sample sizes per cell to improve readability.
Simulated Author's Rebuttal
Thank you for the detailed and constructive review. We appreciate the referee's focus on strengthening causal claims in the interactive study, clarifying the automated metrics, and addressing sample size limitations. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Interactive Study / Methods] Interactive study (N=24): the central claim that voice conversion increases trust/acceptability and encourages perspective-taking assumes converted voices isolate accent/gender identity without audible artifacts (unnatural prosody, timbre shifts, or intelligibility loss) that independently drive ratings; the manuscript appears to lack a control condition reporting naturalness/clarity ratings or artifact detection on the stimuli, directly threatening causal interpretation of the trust differences.
Authors: We acknowledge this concern as valid for strengthening causal interpretation. Our voice conversion used a high-quality model selected to minimize artifacts while preserving content, but the manuscript does not report explicit naturalness or clarity ratings. In the revision, we will add a supplementary control analysis with participant ratings of naturalness, clarity, and artifact detection on the stimuli to confirm that trust differences are attributable to vocal identity rather than audio quality. revision: yes
-
Referee: [Observational Study / Automated Metrics] Automated analysis section: the reported {accent x gender} disparities in alignment and verbosity rest on judge-free prompt-response metrics whose exact definitions, aggregation rules, and statistical tests (including multiple-comparison correction and effect sizes) are not detailed in the abstract or visible methods summary; without these, it is impossible to verify whether the observed differences support the quality-of-service bias claims.
Authors: The full methods section defines alignment as cosine similarity between prompt and response embeddings (using a fixed sentence transformer) and verbosity as response token count, with per-condition means and two-way ANOVA followed by post-hoc tests. To improve transparency as requested, the revision will expand the methods with exact formulas, aggregation procedures, confirmation of Bonferroni correction, and reporting of effect sizes (Cohen's d and partial eta-squared) alongside the results. revision: yes
-
Referee: [Results] Results and discussion: both studies use modest samples (N=24 and N=19) without reported power analysis or pre-registration; this weakens the generalizability of the intersectional disparity and perspective-taking findings, especially given the free parameters in accent/gender selection.
Authors: We agree that the exploratory sample sizes limit strong generalizability claims and that power analysis and pre-registration would be preferable. Pre-registration was not used for this initial work. In the revision, we will add a post-hoc power analysis based on observed effects, expand the limitations section to discuss generalizability constraints and accent/gender selection choices, and recommend pre-registration for follow-up studies with larger samples. revision: partial
Circularity Check
No circularity: empirical results from user studies and automated metrics
full rationale
The paper reports findings from two empirical studies (interactive N=24 and observational N=19) using voice conversion stimuli and judge-free prompt-response metrics to measure trust, acceptability, alignment, and verbosity. No equations, fitted parameters, self-referential definitions, or load-bearing self-citations appear in the derivation chain; claims derive directly from collected participant ratings and automated counts rather than reducing to prior inputs by construction. The evaluation is self-contained against external benchmarks of user perception and model output analysis.
Axiom & Free-Parameter Ledger
free parameters (1)
- selection of six accents and two gender presentations
Reference graph
Works this paper leans on
-
[1]
Amazon.com. 2025.Amazon Alexa Echo. https://www.amazon.com/b?ie=UTF8& node=210779651011
work page 2025
-
[2]
John Baugh. 2003. Linguistic profiling.Black linguistics: Language, society, and politics in Africa and the Americas(2003), 155–168
work page 2003
- [3]
-
[4]
Vineeta Chand. 2009. Social evaluations of accented Englishes: An Indian per- spective.Studies in the Linguistic Sciences: Illinois Working Papers(2009), 90–113
work page 2009
- [5]
-
[6]
Wenqian Cui, Dianzhi Yu, Xiaoqi Jiao, Ziqiao Meng, Guangyan Zhang, Qichao Wang, Yiwen Guo, and Irwin King. 2025. Recent advances in speech language models: a survey. doi:10.48550/arXiv.2410.03751 arXiv:2410.03751 [cs]
- [7]
-
[8]
Siyuan Feng, Bence Mark Halpern, Olya Kudina, and Odette Scharenborg. 2024. Towards inclusive automatic speech recognition.Computer Speech & Language 84 (2024), 101567
work page 2024
- [9]
-
[10]
Google. 2025. Manage Your Smart Home With Google Home. https://home. google.com/welcome/
work page 2025
-
[11]
Camille Harris, Chijioke Mgbahurike, Neha Kumar, and Diyi Yang. 2024. Modeling Gender and Dialect Bias in Automatic Speech Recognition. InFindings of the Association for Computational Linguistics: EMNLP 2024, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguistics, Miami, Florida, USA, 15166–15184. doi:10.18653/...
-
[12]
Ivona Hideg and Laura J Kray. 2024. Speaking with a non-native accent: Impli- cations for work and personal life.Annual Review of Organizational Psychology and Organizational Behavior11 (2024), 109–134
work page 2024
-
[13]
Valentin Hofmann, Pratyusha R Kalluri, Dan Jurafsky, and Sharese King. 2024. Dialect prejudice predicts AI decisions about people’s character, employability, and criminality.Nature633, 8029 (2024), 355–362
work page 2024
- [14]
-
[15]
Allison Koenecke, Andrew Nam, Emily Lake, Joe Nudell, Minnie Quartey, Zion Mengesha, Connor Toups, John R Rickford, Dan Jurafsky, and Sharad Goel. 2020. Racial disparities in automated speech recognition.Proceedings of the national academy of sciences117, 14 (2020), 7684–7689
work page 2020
- [16]
-
[17]
Shiri Lev-Ari and Boaz Keysar. 2010. Understanding of others’ mental states affects language processing in comprehension.Psychological Science21, 7 (2010), 1095–1102
work page 2010
- [18]
-
[19]
Jackson G Lu, Richard E Nisbett, and Michael W Morris. 2020. The bamboo ceiling: Exploring social psychological mechanisms for the underrepresentation of Asian Americans in leadership positions.Proceedings of the National Academy of Sciences117, 9 (2020), 4590–4596
work page 2020
-
[20]
I don’t think these devices are very culturally sensi- tive
Zion Mengesha, Courtney Heldreth, Michal Lahav, Juliana Sublewski, and El- yse Tuennerman. 2021. “I don’t think these devices are very culturally sensi- tive. ”—Impact of automated speech recognition errors on African Americans. Frontiers in Artificial Intelligence4 (2021), 725911
work page 2021
-
[21]
Meta. 2025. Meta AI Glasses. https://www.meta.com/ai-glasses/
work page 2025
-
[22]
Cade Metz. 2020. There Is a Racial Divide in Speech-Recognition Systems, Re- searchers Say.The New York Times(23 March 2020). https://www.nytimes.com/ 2020/03/23/technology/speech-recognition-bias-apple-amazon-google.html
work page 2020
-
[23]
2025.Voice conversations in ChatGPT
OpenAI. 2025.Voice conversations in ChatGPT. https://chatgpt.com/features/ voice/
work page 2025
-
[24]
Thomas Purnell, William Idsardi, and John Baugh. 1999. Perceptual and phonetic experiments on American English dialect identification.Journal of Language and Social Psychology18, 1 (1999), 10–30
work page 1999
-
[25]
Ramon Sanabria, Nikolay Bogoychev, Nina Markl, Andrea Carmantini, Ondrej Klejch, and Peter Bell. 2023. The Edinburgh International Accents of English Corpus: Towards the Democratization of English ASR. InICASSP 2023
work page 2023
-
[26]
Shree Harsha Bokkahalli Satish, Gustav Eje Henter, and Éva Székely. [n. d.]. Hear Me Out: Interactive evaluation and bias discovery platform for speech-to-speech conversational AI. ([n. d.])
-
[27]
Berrak Sisman, Junichi Yamagishi, Simon King, and Haizhou Li. 2020. An overview of voice conversion and its challenges: From statistical modeling to deep learning.IEEE/ACM Transactions on Audio, Speech, and Language Processing 29 (2020), 132–157
work page 2020
- [28]
-
[29]
Toyota. 2022. Toyota’s New In-House Intelligent Assistant Learns Voice Com- mands and Gets Smarter Over Time. https://pressroom.toyota.com/toyotas-new- in-house-intelligent-assistant-learns-voice-commands-and-gets-smarter- over-time/
work page 2022
-
[30]
Hao Wang, Luxi He, Rui Gao, and Flavio Calmon. 2023. Aleatoric and epistemic discrimination: Fundamental limits of fairness interventions.Advances in Neural Information Processing Systems36 (2023), 27040–27062
work page 2023
- [31]
- [32]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.