Recognition: 1 theorem link
· Lean TheoremEVE: A Domain-Specific LLM Framework for Earth Intelligence
Pith reviewed 2026-05-15 08:32 UTC · model grok-4.3
The pith
EVE-Instruct, a 24B model adapted from Mistral Small 3.2, outperforms comparable models on Earth Observation and Earth Sciences benchmarks while preserving general capabilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
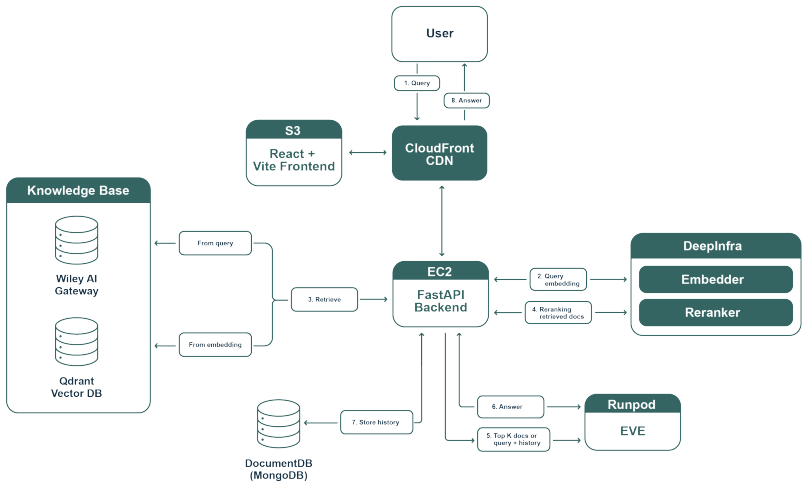
We introduce Earth Virtual Expert (EVE) as the first open-source end-to-end initiative for domain-specialized LLMs in Earth Intelligence. Its core component, EVE-Instruct, is a 24B model derived from Mistral Small 3.2 and optimized for reasoning and question answering in this domain. On newly constructed benchmarks covering Earth Observation and Earth Sciences, it outperforms comparable models in MCQA, open-ended QA, and factuality while preserving general capabilities. We also release the training corpora, systematic benchmarks, and integrate RAG with hallucination detection in a production API and GUI system.
What carries the argument
EVE-Instruct, the domain-adapted 24 billion parameter model built on Mistral Small 3.2 that performs reasoning and question answering for Earth-related tasks.
If this is right
- The release of curated training corpora and benchmarks allows other researchers to train and evaluate their own Earth domain models.
- Integration of RAG and hallucination detection creates a more reliable production system for end users.
- Preservation of general capabilities means the model remains useful for non-domain queries.
- The deployment to 350 pilot users validates the framework's practicality beyond research settings.
Where Pith is reading between the lines
- Similar domain adaptation techniques could be applied to create specialized models for other scientific fields such as astronomy or climate modeling.
- Connecting the LLM with satellite imagery processing tools might enable more advanced multimodal Earth analysis.
- The open benchmarks could serve as a standard for evaluating future AI systems in environmental sciences.
- Expanding the user base beyond pilots might reveal additional needs for customization in real operational settings.
Load-bearing premise
The newly constructed benchmarks provide an unbiased and leakage-free measure of true domain-specific reasoning and factuality.
What would settle it
If an independent evaluation using questions from recent peer-reviewed papers or operational Earth data sources shows no performance advantage for EVE-Instruct over the base Mistral model or other comparable LLMs, the superiority claim would not hold.
Figures






read the original abstract
We introduce Earth Virtual Expert (EVE), the first open-source, end-to-end initiative for developing and deploying domain-specialized LLMs for Earth Intelligence. At its core is EVE-Instruct, a domain-adapted 24B model built on Mistral Small 3.2 and optimized for reasoning and question answering. On newly constructed Earth Observation and Earth Sciences benchmarks, it outperforms comparable models while preserving general capabilities. We release curated training corpora and the first systematic domain-specific evaluation benchmarks, covering MCQA, open-ended QA, and factuality. EVE further integrates RAG and a hallucination-detection pipeline into a production system deployed via API and GUI, supporting 350 pilot users so far. All models, datasets, and code are ready to be released under open licenses as contributions to our field at huggingface.co/eve-esa and github.com/eve-esa.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Earth Virtual Expert (EVE) framework as the first open-source end-to-end system for domain-specialized LLMs in Earth Intelligence. Its core is EVE-Instruct, a 24B model fine-tuned from Mistral Small 3.2 for reasoning and QA in Earth Observation and Earth Sciences. The paper claims this model outperforms comparable models on newly constructed benchmarks (MCQA, open-ended QA, factuality) while preserving general capabilities, releases the training corpora and benchmarks, and deploys a production system with RAG and hallucination detection that has reached 350 pilot users.
Significance. If the performance claims hold after proper decontamination and statistical controls, the work would be significant for providing the first openly released domain-specific resources and evaluation suite in Earth Intelligence, enabling reproducible research on LLM adaptation for specialized scientific domains.
major comments (2)
- [Evaluation and Results] The central performance claim (outperformance on new Earth Observation and Earth Sciences benchmarks) rests on custom benchmarks whose construction, decontamination, and split methodology are not described. No n-gram overlap statistics, embedding similarity checks, or explicit train/test separation details are provided, leaving open the possibility of leakage from the released training corpora.
- [Results] No error bars, statistical significance tests, or controls for multiple comparisons are reported for the benchmark comparisons, making it impossible to assess whether the reported gains are reliable or could arise from variance.
minor comments (1)
- [Abstract] The abstract states that general capabilities are preserved but does not name the specific general-domain benchmarks or metrics used for this verification.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for highlighting important aspects of our evaluation methodology. We address each major comment below and will incorporate the suggested improvements in the revised manuscript.
read point-by-point responses
-
Referee: [Evaluation and Results] The central performance claim (outperformance on new Earth Observation and Earth Sciences benchmarks) rests on custom benchmarks whose construction, decontamination, and split methodology are not described. No n-gram overlap statistics, embedding similarity checks, or explicit train/test separation details are provided, leaving open the possibility of leakage from the released training corpora.
Authors: We agree that additional details on benchmark construction are required to fully address potential leakage concerns and support reproducibility. In the revised manuscript, we will add an expanded subsection under Evaluation that describes: the data sources and curation process for the MCQA, open-ended QA, and factuality benchmarks; explicit decontamination steps including n-gram overlap statistics and embedding similarity thresholds applied between the training corpora and test sets; and the train/test split methodology with verification that no overlap exists. We will also release the benchmark construction scripts and intermediate datasets to enable independent verification. revision: yes
-
Referee: [Results] No error bars, statistical significance tests, or controls for multiple comparisons are reported for the benchmark comparisons, making it impossible to assess whether the reported gains are reliable or could arise from variance.
Authors: We acknowledge the absence of these statistical controls in the current results presentation. In the revision, we will recompute all reported scores across multiple evaluation runs (minimum of five random seeds) to include error bars (standard deviation), apply appropriate statistical significance tests (e.g., paired t-tests or Wilcoxon signed-rank tests) between EVE-Instruct and the baseline models, and incorporate a multiple-comparison correction (Bonferroni) across the suite of benchmarks. These updates will be presented in updated tables and text in the Results section. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical introduction of the EVE framework and EVE-Instruct model, with performance claims resting on benchmark comparisons and released datasets rather than any mathematical derivation chain. No equations, fitted parameters, self-definitional constructs, or load-bearing self-citations for uniqueness theorems are present in the provided text. Central results are externally verifiable via released artifacts and do not reduce to inputs by construction. Benchmark construction concerns relate to evaluation validity, not circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Urbangpt: Spatio-temporal large language models. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Min- ing (KDD 2024), pages 5351–5362. Jessy Lin, Vincent-Pierre Berges, Xilun Chen, Wen-Tau Yih, Gargi Ghosh, and Barlas O˘guz. 2025. Learning facts at scale with active reading.arXiv preprint arXiv:2508.09494. Stephanie Lin, Ja...
-
[2]
Association for Computational Linguistics. Alexander H Liu, Kartik Khandelwal, Sandeep Sub- ramanian, Victor Jouault, Abhinav Rastogi, Adrien Sadé, Alan Jeffares, Albert Jiang, Alexandre Cahill, Alexandre Gavaudan, and 1 others. 2026. Ministral 3.arXiv preprint arXiv:2601.08584. Nicolas Longépé, Hamed Alemohammad, Anca Anghe- lea, Thomas Brunschwiler, Gus...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
HopWeaver: Cross-Document Synthesis of High-Quality and Authentic Multi-Hop Questions
Hopweaver: Synthesizing authentic multi- hop questions across text corpora.arXiv preprint arXiv:2505.15087. Luca Soldaini, Rodney Kinney, Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur, Ben Bo- gin, and 1 others. 2024. Dolma: An open corpus of three trillion tokens for language model pretraining research. InProceedings of the 62nd Annual M...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Nougat Artifact Removal (Blecher et al., 2023): we remove residual tags and arti- facts introduced during PDF parsing (e.g., <WARNING>,<ERROR>)
work page 2023
-
[5]
Merged Word Correction: we detect and correct tokenization errors where numeric prefixes are concatenated with words (e.g., 1Introduction→1 Introduction)
-
[6]
OCR Duplication Removal: we apply MinHash-based near-duplicate detection to identify repeated text segments. We further detect and remove OCR-induced duplicates via adjacency patterns (i.e., repeated spans with minimal or no intervening characters)
-
[7]
Rule-Based Filtering: we remove low- information lines (e.g., sequences of repeated symbols) and normalize formatting by collaps- ing excessive whitespace (e.g., replacing three or more consecutive newlines with two). Data Extraction.To select an OCR system for scientific document extraction, we first construct a benchmark of 1k PDFs and evaluate multiple...
-
[8]
Generate Questions: generate ~4 distinct, insightful questions answerable from the document, covering its key information and nuances
-
[9]
Devise Strategies: for EACH question, devise 2 diverse active learning strategies that help deeply internalize the *type* of knowledge required, not the answer itself. Example strategies: - Conceptual Visualization: diagram a processing chain (e.g., DEM generation from an InSAR pair). - Comparative Analysis: contrast C-band vs. L-band SAR for biomass esti...
-
[10]
paraphrastic_restatement: ONLY IF the document contains more than 100 words of dense technical information
-
[11]
Acronyms without this pattern or non-technical ones (e.g., USA, EU, AI, ML) do not count
acronym_glossary: ONLY IF at least 6 technical acronyms are explicitly defined using the pattern Full Name (Acronym). Acronyms without this pattern or non-technical ones (e.g., USA, EU, AI, ML) do not count. Acronyms must relate to Earth Observation
-
[12]
timeline_generation: ONLY IF the document contains at least 10 distinct dates, years, or time-related events
-
[13]
workflow_description: ONLY IF the document explicitly describes a complex procedural sequence or steps
-
[14]
From the strategies that pass these rules, select at most 2 of the most impactful ones
technical_tutorial: ONLY IF the document's primary focus is to explain a specific, named technique in detail. From the strategies that pass these rules, select at most 2 of the most impactful ones. Figure 6: Prompt used for predefined Active Reading. The model applies strict eligibility rules to select at most 2 strategies from a fixed predefined set. G.5...
-
[15]
Self-Contained Question: - Must NOT require the source document to be understood. - Do NOT use phrases like "in the text" or "according to the document". - Integrate necessary context directly. For example, transform "What is its resolution?" into "What is the spatial resolution of the Sentinel-2 MSI sensor?" - Must be clear and unambiguous on its own
-
[16]
High-Quality Answer: - Base the answer on the original answer and source document. Modify form, not content. - Must be correct, complete, and detailed. - Written in full, explanatory, pedagogical sentences. Figure 8: Prompt used to generate SelfQA samples. Context-grounded QA pairs are reformulated into self- contained questions that can be answered from ...
-
[17]
Hard Filters: if the sample is not relevant to EO, has poor SFT style (not conversational or detailed), contradicts the source document, or is too trivial, assign Wrong immediately
-
[18]
RATING SCALE: - Best (top ~1%): flawless
Quality Evaluation: if it passes, evaluate question quality and answer correctness and completeness. RATING SCALE: - Best (top ~1%): flawless. The question uncovers a deep or non-obvious aspect of the document. The answer is correct, complete, and exceptionally well-written with rich context, examples, or analogies. - Good (top ~5%): strong but not Best. ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.