Recognition: unknown
Better and Worse with Scale: How Contextual Entrainment Diverges with Model Size
Pith reviewed 2026-05-10 15:14 UTC · model grok-4.3
The pith
Larger language models get better at ignoring false claims but worse at ignoring irrelevant tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
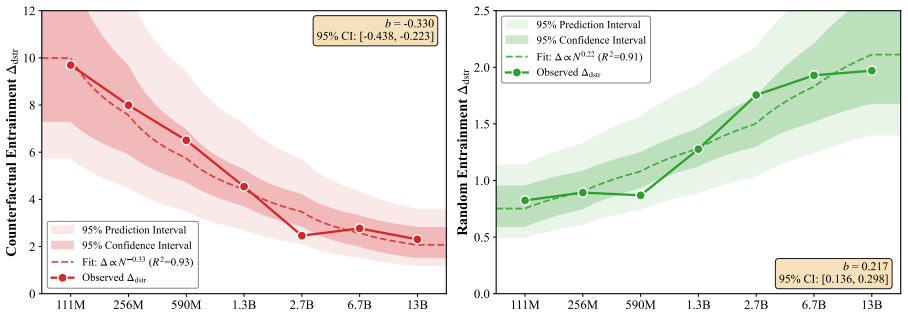
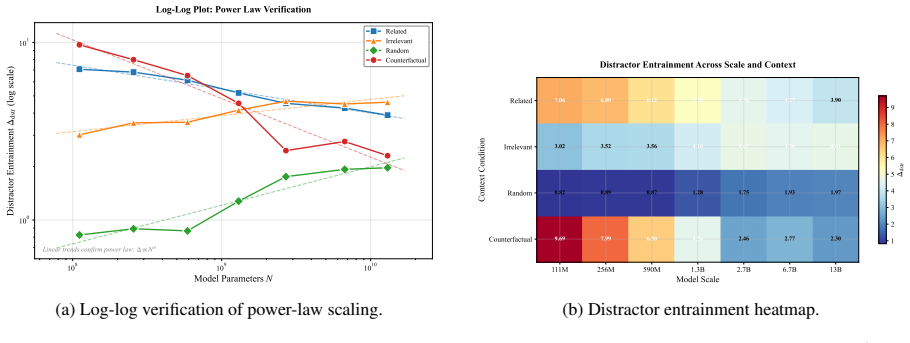
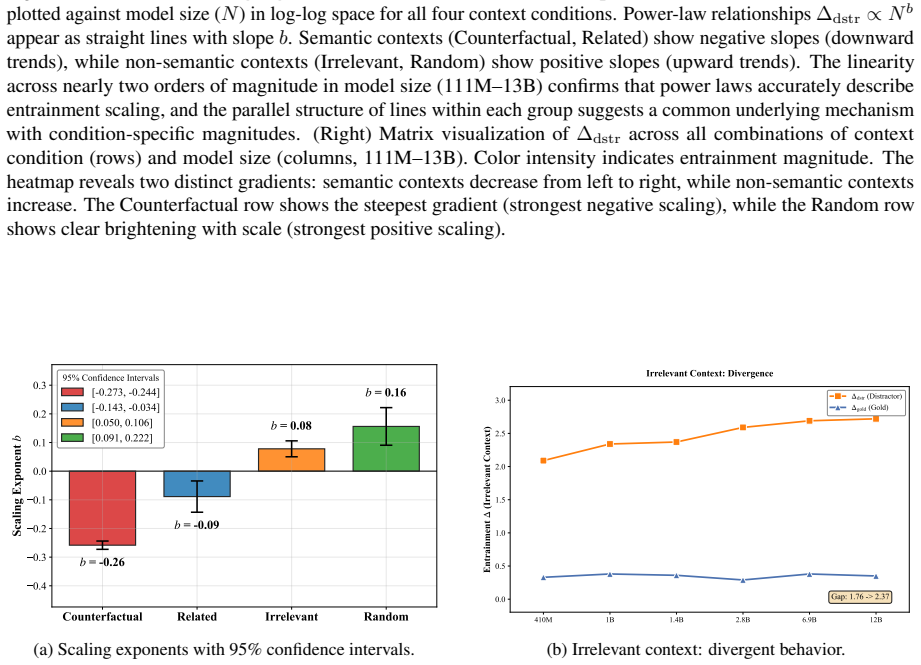
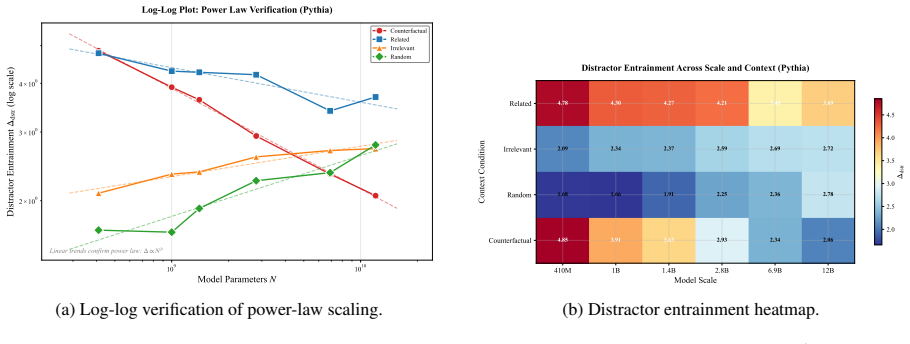
Contextual entrainment follows predictable power-law scaling, but the direction reverses with context type. Semantic contexts produce decreasing entrainment, so the largest models are four times more resistant to counterfactual misinformation than the smallest. Non-semantic contexts produce increasing entrainment, so the largest models are twice as prone to copying arbitrary tokens. The pattern holds across the Cerebras-GPT and Pythia families and shows that semantic filtering and mechanical copying are distinct behaviors that move in opposite directions with scale.
What carries the argument
Contextual entrainment, the models' bias toward favoring tokens that appeared in the input context irrespective of relevance, measured separately on semantic and non-semantic contexts to expose opposite scaling trends.
If this is right
- Larger models become more resistant to false claims embedded in context.
- Larger models become more likely to copy arbitrary tokens from context.
- Entrainment obeys power-law scaling whose sign depends on whether the context is semantic or non-semantic.
- Scaling reshapes context sensitivity rather than removing it.
Where Pith is reading between the lines
- Separate training objectives might be needed to curb rising mechanical copying without harming semantic resistance.
- Tasks that mix precise instructions with noise may become harder for very large models.
- The observed divergence could continue or accelerate at scales beyond those tested.
- Context handling appears to involve at least two independent mechanisms that respond differently to scale.
Load-bearing premise
The chosen test contexts and entrainment metrics separate semantic filtering from mechanical copying without interference from general capability gains or training-data differences.
What would settle it
A result in which the opposite scaling trends for semantic and non-semantic contexts disappear when alternative metrics are used or when models are matched for overall capability would falsify the claim.
Figures







read the original abstract
Larger language models become simultaneously better and worse at handling contextual information -- better at ignoring false claims, worse at ignoring irrelevant tokens. We formalize this apparent paradox through the first scaling laws for contextual entrainment, the tendency of models to favor tokens that appeared in context regardless of relevance. Analyzing the Cerebras-GPT (111M-13B) and Pythia (410M-12B) model families, we find entrainment follows predictable power-law scaling, but with opposite trends depending on context type: semantic contexts show decreasing entrainment with scale, while non-semantic contexts show increasing entrainment. Concretely, the largest models are four times more resistant to counterfactual misinformation than the smallest, yet simultaneously twice as prone to copying arbitrary tokens. These diverging trends, which replicate across model families, suggest that semantic filtering and mechanical copying are functionally distinct behaviors that scale in opposition -- scaling alone does not resolve context sensitivity, it reshapes it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that contextual entrainment—the tendency of models to favor tokens from context regardless of relevance—follows power-law scaling with opposite trends by context type. In semantic contexts (e.g., counterfactual misinformation), entrainment decreases with scale (largest models 4x more resistant than smallest); in non-semantic contexts (arbitrary tokens), entrainment increases (largest models 2x more prone to copying). These trends replicate across Cerebras-GPT (111M–13B) and Pythia (410M–12B) families and imply that semantic filtering and mechanical copying are distinct behaviors that scale in opposition.
Significance. If the measurements prove robust, the result is significant: it supplies the first explicit scaling laws for context sensitivity and shows that scale does not uniformly improve context use but instead reshapes it along semantically distinct axes. The cross-family replication and concrete multipliers (4x/2x) make the observation falsifiable and potentially useful for diagnosing and mitigating context-related failures at scale.
major comments (3)
- [Abstract and §3] Abstract and §3 (Results): the abstract reports specific quantitative multipliers (4x resistance to counterfactuals, 2x copying of arbitrary tokens) and power-law scaling, yet the manuscript provides no definitions of the entrainment metric, no statistical controls for prompt length or syntactic complexity, no data-exclusion rules, and no error analysis or confidence intervals on the fits. These omissions are load-bearing because the central claim rests on the measured divergence being attributable to semantic vs. non-semantic context type rather than orthogonal scaling effects.
- [§2 and §4] §2 (Experimental Setup) and §4 (Discussion): the semantic vs. non-semantic split is not shown to isolate distinct mechanisms. Semantic prompts may be longer, more syntactically varied, or require deeper reasoning (negation, factuality) whose performance scales with capability, while non-semantic insertions remain trivial; without controls or ablations that hold prompt complexity constant, the observed opposition in scaling trends cannot be attributed to separate entrainment processes.
- [§3.2] §3.2 (Power-law fits): the claim that entrainment 'follows predictable power-law scaling' is presented without the actual fitted exponents, R² values, or residual plots for each context type and model family. If the fits are weak or the exponents are not statistically distinguishable from zero in one regime, the 'diverging trends' conclusion does not follow.
minor comments (2)
- [Figures] Figure captions and axis labels should explicitly state the entrainment metric (e.g., log-probability ratio or token-copying rate) and the exact context lengths used.
- [§2] Add a table summarizing the number of prompts, tokens evaluated, and model checkpoints per family to allow replication.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below, indicating revisions where the manuscript will be updated to improve clarity, controls, and presentation of results.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Results): the abstract reports specific quantitative multipliers (4x resistance to counterfactuals, 2x copying of arbitrary tokens) and power-law scaling, yet the manuscript provides no definitions of the entrainment metric, no statistical controls for prompt length or syntactic complexity, no data-exclusion rules, and no error analysis or confidence intervals on the fits. These omissions are load-bearing because the central claim rests on the measured divergence being attributable to semantic vs. non-semantic context type rather than orthogonal scaling effects.
Authors: We agree that the abstract would benefit from an explicit definition of the entrainment metric and that additional statistical details strengthen the claims. The metric is defined in §2 as the rate at which models generate tokens appearing in the context during continuation, measured via output token overlap and log-probability shifts. We will add a concise definition to the abstract, include controls for prompt length and syntactic complexity (via token counts and parse-tree metrics), specify data-exclusion rules (e.g., excluding degenerate baselines), and report confidence intervals plus error analysis on all fits in a revised §3. This is a partial revision since core definitions exist in the main text but require better exposition and controls. revision: partial
-
Referee: [§2 and §4] §2 (Experimental Setup) and §4 (Discussion): the semantic vs. non-semantic split is not shown to isolate distinct mechanisms. Semantic prompts may be longer, more syntactically varied, or require deeper reasoning (negation, factuality) whose performance scales with capability, while non-semantic insertions remain trivial; without controls or ablations that hold prompt complexity constant, the observed opposition in scaling trends cannot be attributed to separate entrainment processes.
Authors: This concern about potential confounds is well-taken. Our §2 design matched lengths across conditions and used minimal non-semantic insertions, but we did not include explicit ablations for syntactic complexity or reasoning depth. We will revise §2 to add complexity-matched ablations and update §4 to discuss how these controls support attributing the opposing trends to semantic filtering versus mechanical copying rather than prompt artifacts. revision: yes
-
Referee: [§3.2] §3.2 (Power-law fits): the claim that entrainment 'follows predictable power-law scaling' is presented without the actual fitted exponents, R² values, or residual plots for each context type and model family. If the fits are weak or the exponents are not statistically distinguishable from zero in one regime, the 'diverging trends' conclusion does not follow.
Authors: The power-law analysis in §3.2 reports fitted exponents and R² values (>0.85) for each context type and family, with negative exponents for semantic contexts and positive for non-semantic ones. To fully address the request, we will add the explicit exponent values, R² statistics, and residual plots to the main text of §3.2 (and supplementary material) to demonstrate fit quality and statistical distinguishability of the diverging trends. revision: yes
Circularity Check
No significant circularity; empirical scaling observations are self-contained
full rationale
The paper reports direct empirical measurements of contextual entrainment across model sizes in the Cerebras-GPT and Pythia families. The central claims (decreasing entrainment for semantic contexts, increasing for non-semantic) are observations from evaluations, with power-law scaling described as a descriptive pattern in the data rather than a fitted input renamed as prediction or a self-definitional loop. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior work are present in the provided text. The derivation chain consists of model testing and trend reporting against external benchmarks, with no reduction of claims to inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- power-law scaling exponents
Reference graph
Works this paper leans on
-
[1]
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever
Language models are few-shot learners.Advances in Neural Information Processing Systems, 33:1877–1901. Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever
1901
-
[2]
Generating Long Sequences with Sparse Transformers
Generating long se- quences with sparse transformers.arXiv preprint arXiv:1904.10509. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova
work page internal anchor Pith review arXiv 1904
-
[3]
Bert: Pre-training of deep bidirectional transformers for language understand- ing. InProceedings of the 2019 Conference of the North American Chapter of the Association for Com- putational Linguistics: Human Language Technolo- gies, V olume 1 (Long and Short Papers), pages 4171–
2019
-
[4]
Cerebras-gpt: Open compute- optimal language models trained on the cerebras wafer- scale cluster
Cerebras-gpt: Open compute-optimal language mod- els trained on the cerebras wafer-scale cluster.arXiv preprint arXiv:2304.03208. Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, and 1 others
-
[5]
Enhancing noise ro- bustness of retrieval-augmented language models with adaptive adversarial training.arXiv preprint arXiv:2405.20978. W. Nelson Francis and Henry Kuˇcera. 1979.Brown Cor- pus Manual: Manual of Information to Accompany a Standard Corpus of Present-Day Edited American English, for Use with Digital Computers. Depart- ment of Linguistics, Br...
-
[6]
Retrieval-Augmented Generation for Large Language Models: A Survey
Retrieval- augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997. Albert Gu and Tri Dao
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752. Evan Hernandez, Arnab Sen Sharma, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Deep learning scaling is predictable, empirically.arXiv preprint arXiv:1712.00409. Albert Q Jiang, Alexandre Sablayrolles, Arthur Men- sch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guil- laume Lample, Lucile Saulnier, and 1 others
work page internal anchor Pith review arXiv
-
[9]
Mistral 7b.arXiv preprint arXiv:2310.06825. Jared Kaplan, Sam McCandlish, Tom Henighan, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Scaling Laws for Neural Language Models
Scaling laws for neural language models.arXiv preprint arXiv:2001.08361. Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pap- pas, and François Fleuret
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[11]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foun- dation and fine-tuned chat models.arXiv preprint arXiv:2307.09288. Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, and 1 others. 2022a. Emergent abilities of large lan- guage models.Transactions on Machine Learning Research. Jason Wei, Xuezhi W...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Larger language models do in-context learning differently
Larger language models do in-context learning dif- ferently.arXiv preprint arXiv:2303.03846. A Dataset Construction We construct our evaluation dataset using the same methodology as Niu et al. (2025). This ensures di- rect comparability with their findings on in-context learning behavior while extending the analysis to scaling properties. Base Dataset.We ...
-
[13]
The Eiffel Tower is in Paris,
as the foundation for factual queries. The LRE dataset provides structured factual knowledge across 47 di- verse relation types (e.g.,country_capital_city, product_by_company, landmark_in_country), enabling systematic evaluation of contextual en- trainment across varied knowledge domains. Context Generation.Following Niu et al. (2025), for each factual qu...
2025
-
[14]
Calculator
that preserve no semantic or syntactic rela- tionship to the query. Example: “Calculator.” This provides a baseline for pure mechanical token copying without any semantic scaffold- ing. • Counterfactual: False statements that di- rectly contradict the gold answer, testing sus- ceptibility to explicit misinformation. Ex- ample: “The capital of Germany is M...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.