Recognition: unknown
Figma2Code: Automating Multimodal Design to Code in the Wild
Pith reviewed 2026-05-10 13:15 UTC · model grok-4.3
The pith
Figma metadata helps models match designs visually yet still produces code with poor layout responsiveness and low maintainability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Incorporating Figma metadata alongside images advances design-to-code automation, yet even the strongest proprietary multimodal models remain limited in producing responsive layouts and maintainable code, largely because they directly map primitive visual attributes from the metadata rather than reasoning about UI structure.
What carries the argument
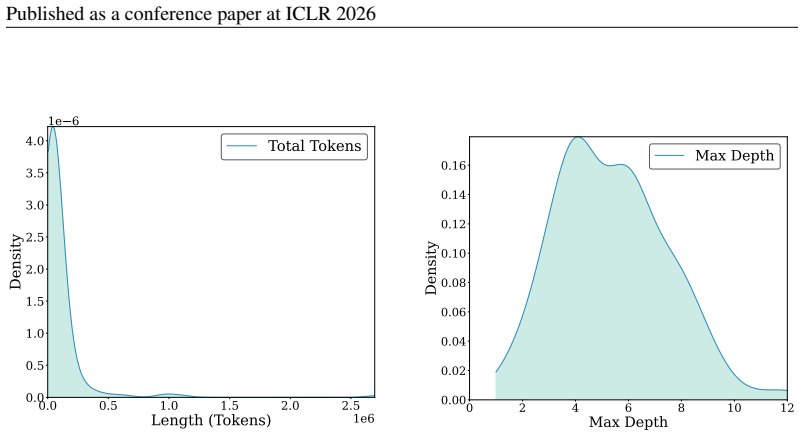
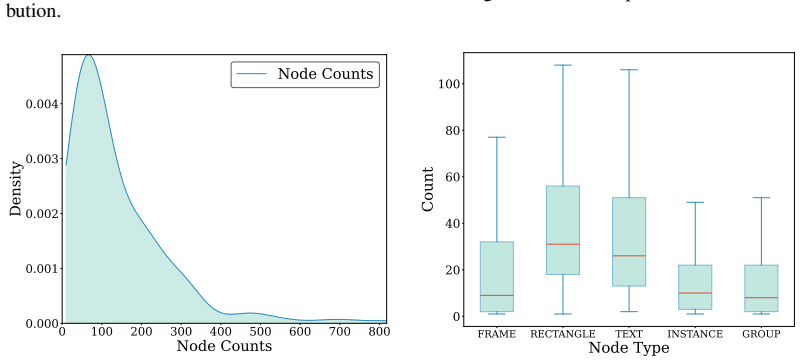
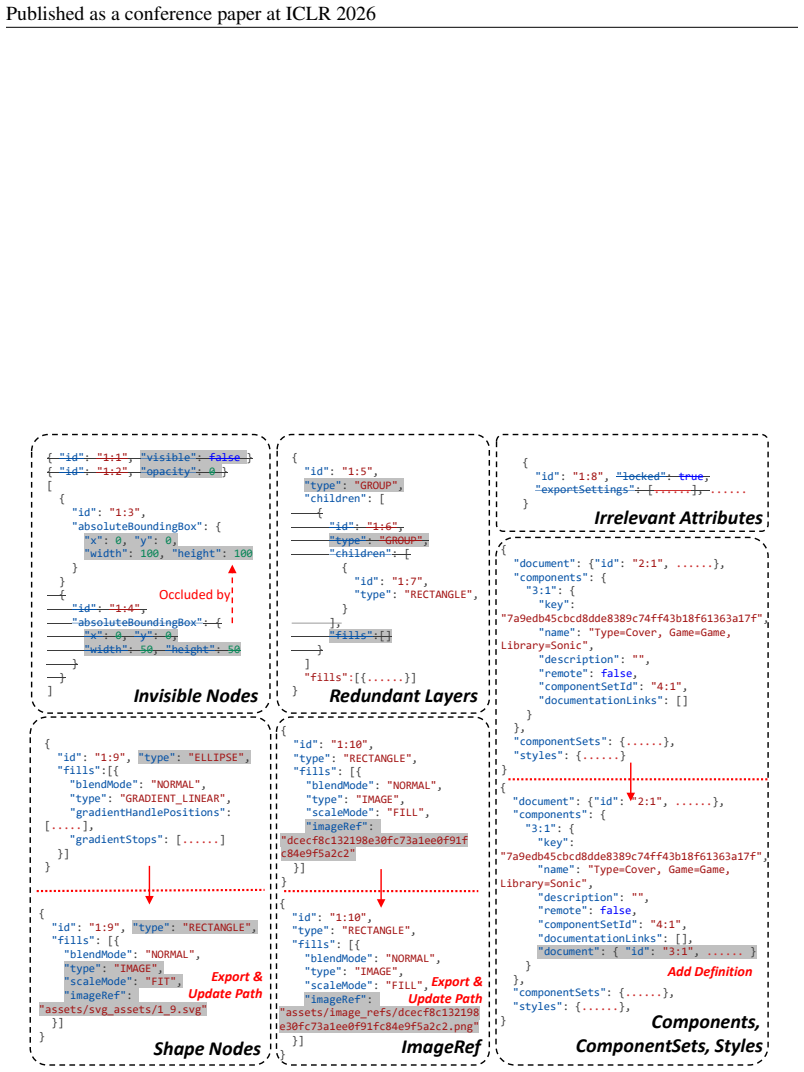
The Figma2Code task and its 213-case curated dataset, which pairs design images with metadata files and evaluates models on visual fidelity, layout responsiveness, and code maintainability.
Load-bearing premise
The 213 high-quality cases drawn from 3,055 processed Figma samples represent typical real-world usage and that judgments of layout responsiveness and code maintainability are consistent and reproducible.
What would settle it
Re-running the ten models on an independent set of 500 new Figma files from varied domains and measuring responsiveness with automated layout checks would falsify the claimed limitations if scores rise substantially.
Figures


























read the original abstract
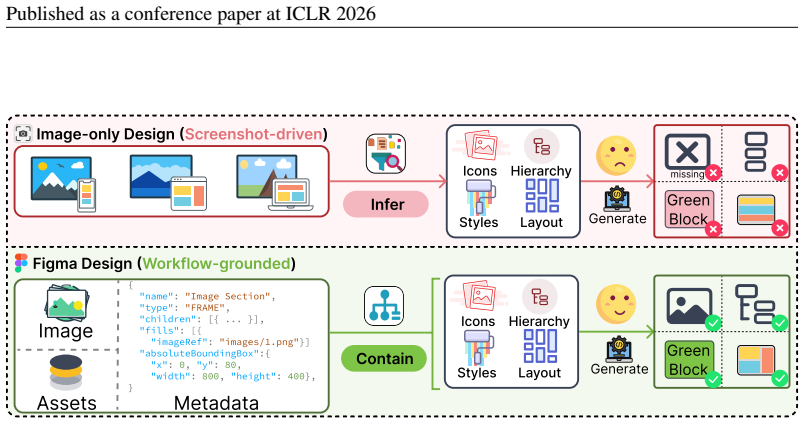
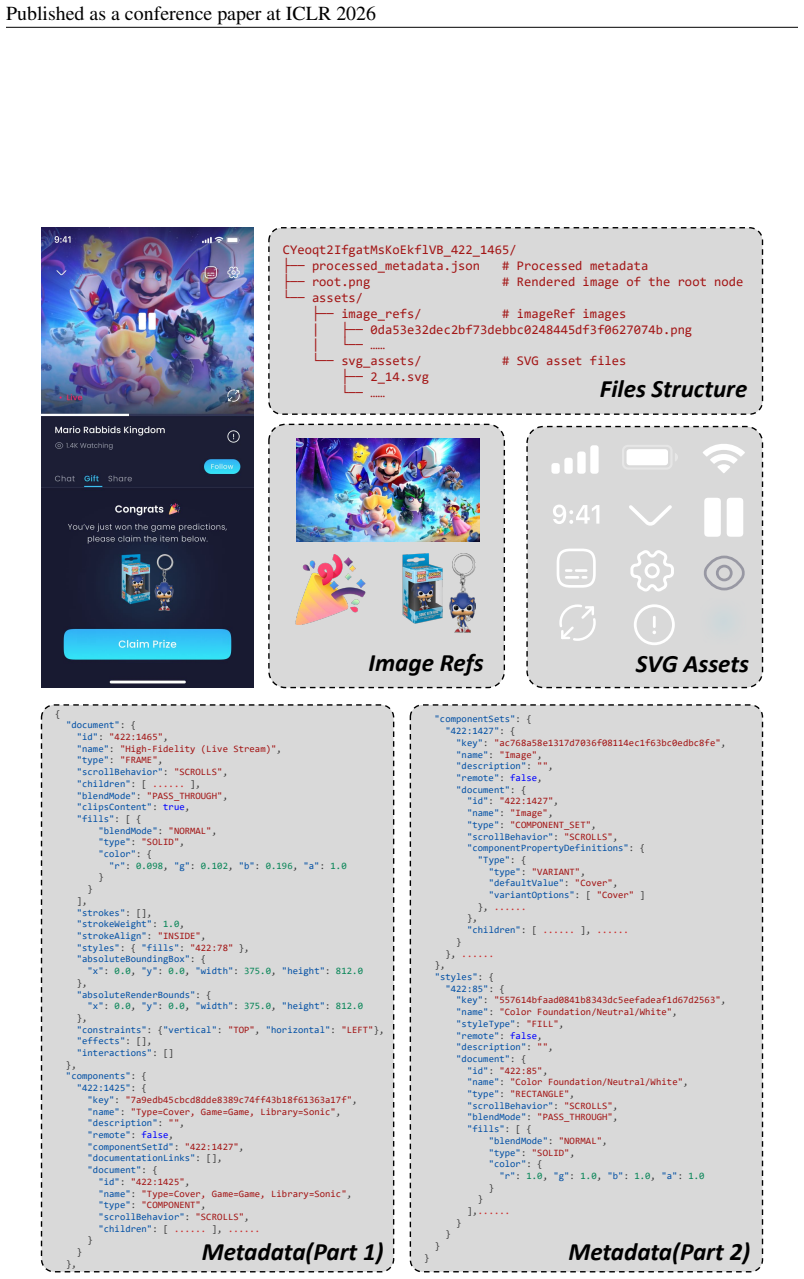
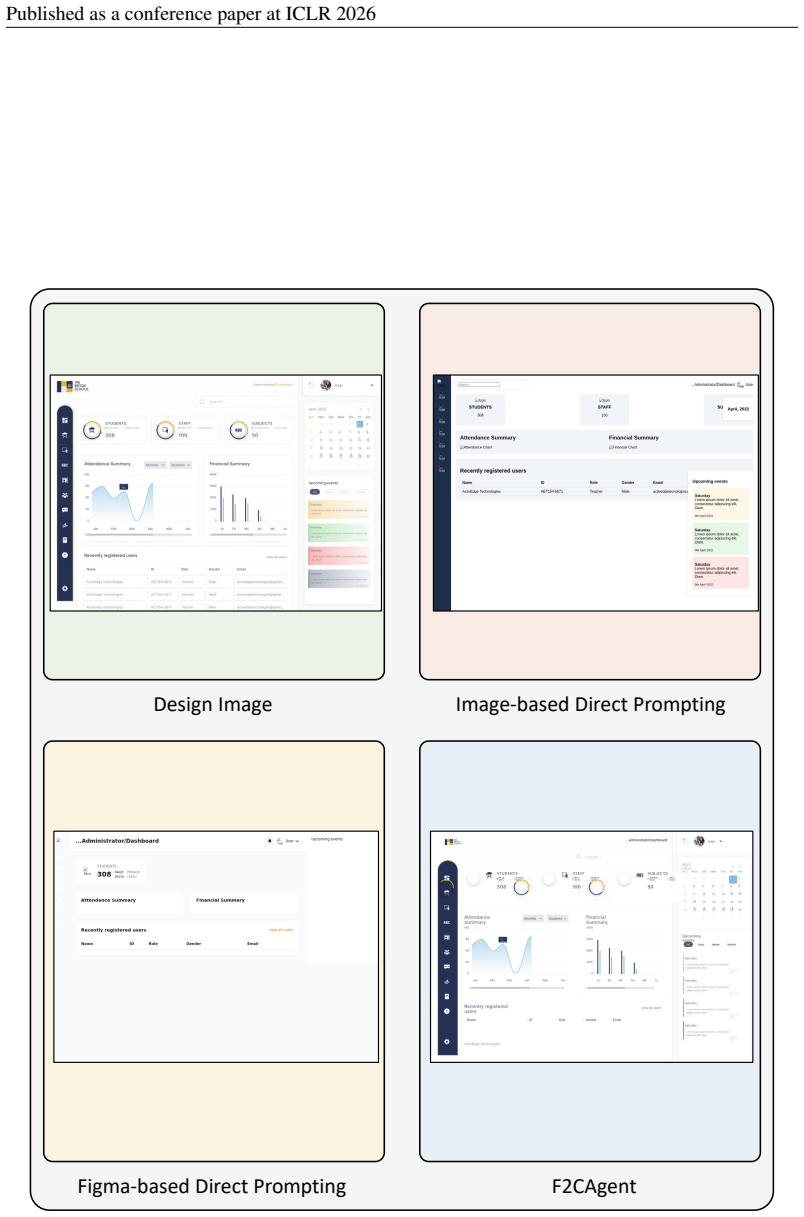
Front-end development constitutes a substantial portion of software engineering, yet converting design mockups into production-ready User Interface (UI) code remains tedious and costly. While recent work has explored automating this process with Multimodal Large Language Models (MLLMs), existing approaches typically rely solely on design images. As a result, they must infer complex UI details from images alone, often leading to degraded results. In real-world development workflows, however, design mockups are usually delivered as Figma files, a widely used tool for front-end design, that embed rich multimodal information (e.g., metadata and assets) essential for generating high-quality UI. To bridge this gap, we introduce Figma2Code, a new task that advances design-to-code into a multimodal setting and aims to automate design-to-code in the wild. Specifically, we collect paired design images and their corresponding metadata files from the Figma community. We then apply a series of processing operations, including rule-based filtering, human- and MLLM-based annotation and screening, and metadata refinement. This process yields 3,055 samples, from which designers curate a balanced dataset of 213 high-quality cases. Using this dataset, we benchmark ten state-of-the-art open-source and proprietary MLLMs. Our results show that while proprietary models achieve superior visual fidelity, they remain limited in layout responsiveness and code maintainability. Further experiments across modalities and ablation studies corroborate this limitation, partly due to models' tendency to directly map primitive visual attributes from Figma metadata.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper introduces the Figma2Code task to automate converting Figma design mockups (including images and metadata) to UI code using MLLMs. It describes collecting 3,055 samples from the Figma community, processing them with rule-based filtering, annotations, and human screening to create a curated dataset of 213 high-quality cases. The authors benchmark ten MLLMs on this dataset, concluding that proprietary models achieve better visual fidelity but are limited in layout responsiveness and code maintainability due to directly mapping primitive attributes from metadata. Modality experiments and ablations are used to support the findings.
Significance. The work is significant in shifting design-to-code from image-only to multimodal settings, which aligns better with real-world Figma workflows. The dataset curation and benchmarking provide a new resource and baseline for the field. If the limitations identified are confirmed with more rigorous metrics, it could influence the development of better MLLMs for UI generation tasks.
major comments (3)
- [Dataset Construction] The description of how the 213 cases were selected from 3,055 samples by designers does not include the specific criteria used for 'high-quality' or any measure of inter-annotator agreement for the screening process. Since the benchmark results and conclusions depend on this subset, this omission affects the reliability of the representativeness claim.
- [Experiments] The evaluation of layout responsiveness and code maintainability is described qualitatively without accompanying quantitative proxies (such as counts of media queries, relative CSS units, or code duplication metrics). This makes the central claim about model limitations difficult to assess objectively or reproduce.
- [Ablation Studies] The attribution of limitations to models 'directly map[ping] primitive visual attributes from Figma metadata' is not supported by specific measurements or examples from the ablation studies showing this behavior.
minor comments (2)
- [Abstract] The abstract states results show proprietary models are limited but does not provide any specific quantitative metrics or examples to illustrate the limitations.
- [References] Ensure all related work on design-to-code is cited, particularly recent MLLM applications in UI generation.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We value the suggestions for enhancing the rigor of our dataset description, experimental evaluations, and ablation analyses. We will update the paper to address these points and provide more detailed explanations and quantitative support where needed.
read point-by-point responses
-
Referee: [Dataset Construction] The description of how the 213 cases were selected from 3,055 samples by designers does not include the specific criteria used for 'high-quality' or any measure of inter-annotator agreement for the screening process. Since the benchmark results and conclusions depend on this subset, this omission affects the reliability of the representativeness claim.
Authors: We agree that explicit criteria and inter-annotator agreement would improve transparency. In the revised manuscript, we will expand the Dataset Construction section to detail the specific high-quality selection criteria used by the designers (including UI component diversity, visual complexity, real-world applicability, and code generation feasibility) and report inter-annotator agreement metrics from the human screening process to better substantiate the 213-case subset. revision: yes
-
Referee: [Experiments] The evaluation of layout responsiveness and code maintainability is described qualitatively without accompanying quantitative proxies (such as counts of media queries, relative CSS units, or code duplication metrics). This makes the central claim about model limitations difficult to assess objectively or reproduce.
Authors: We acknowledge the value of quantitative proxies for objectivity. In the revised Experiments section, we will introduce and report measurable proxies including average counts of media queries, proportion of relative CSS units (e.g., %, em, vw) versus fixed pixels, and code duplication metrics such as repeated style definitions or class overlaps. These will provide reproducible evidence supporting our claims on responsiveness and maintainability limitations. revision: yes
-
Referee: [Ablation Studies] The attribution of limitations to models 'directly map[ping] primitive visual attributes from Figma metadata' is not supported by specific measurements or examples from the ablation studies showing this behavior.
Authors: We recognize the need for more explicit linkage. In the revised Ablation Studies section, we will add concrete code examples demonstrating direct mapping of primitive Figma attributes (e.g., fixed pixel dimensions leading to non-responsive layouts) and include quantitative measurements such as correlations between metadata inclusion and absolute positioning usage across ablation variants to strengthen the attribution. revision: yes
Circularity Check
No circularity: empirical benchmarking with direct observations
full rationale
The paper presents an empirical task definition, dataset curation from Figma files, and benchmarking of ten MLLMs on visual fidelity, layout responsiveness, and code maintainability. No mathematical derivations, equations, fitted parameters, or predictions appear. Results are stated as direct observations from the 213 curated cases and ablation experiments. No self-citations are invoked as load-bearing premises, and no step reduces a claimed result to its own inputs by construction. The reduction from 3,055 to 213 samples and qualitative judgments are methodological choices, not circular derivations.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Figma2Code task
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Vision2Code: A Multi-Domain Benchmark for Evaluating Image-to-Code Generation
Vision2Code is a multi-domain benchmark that evaluates image-to-code generation via rendered outputs scored by a VLM rater with dataset-specific rubrics, revealing domain-dependent model performance and enabling impro...
Reference graph
Works this paper leans on
-
[1]
Accessed: 2025-09-11. Figma, Inc. Figma: The collaborative interface design tool. https://www.figma.com/ . Accessed: 2025-09-17. Golnaz Gharachorlu. Code smells in cascading style sheets : an empirical study and a predictive model. 2014. Google. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agen...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Examine the layout, text, colors, and all design elements carefully
-
[3]
Ensure every field in the JSON is present and contains a valid, non-empty value
-
[4]
For thecontentfield, if none of the reference categories are a good fit, create a new, appropriate category name
-
[5]
content":
Ensure the final output is a single, fully parsable JSON object. Examples: { "content": "Messaging", "description": "A mobile UI for a messaging app, showing a list of recent chats with profile pictures and last message snippets." } { "content": "Dashboard", "description": "A desktop admin dashboard in dark mode, displaying analytics charts, a side naviga...
2026
-
[7]
{imageRef}
Allowed Rendering for Image References:Prefer <img src="{imageRef}"> for placed/raster/SVG assets. Use CSS background-image only when the design explicitly uses the image as a background fill. When using Tailwind arbitrary values, escape properly, e.g.,bg-[url(’assets/foo.png’)]. 3.Path Integrity:Do not alter provided paths or their semantics. 4.No Halluc...
2026
-
[8]
This is a hard requirement
Mandatory Image Asset Binding:For every visible node whose fills include an IMAGE with a non-empty, case-sensitive imageRef value (already a local relative path), you must render that exact asset path in the HTML. This is a hard requirement
-
[9]
{imageRef}
Allowed Rendering for Image References:Prefer <img src="{imageRef}"> for placed/raster/SVG assets. Use CSS background-image only when the design explicitly uses the image as a background fill. When using Tailwind arbitrary values, escape properly, e.g.,bg-[url(’assets/foo.png’)]. 3.Path Integrity:Do not alter provided paths or their semantics. 4.No Halluc...
2026
-
[10]
Compare the visual rendering of the HTML with the provided screenshot to identify layout and style mismatches
-
[11]
Cross-reference the HTML against the Intermediate Representation (IR) to verify correct implementation of specified properties (e.g., colors, fonts, spacing)
-
[12]
For each identified issue, provide a precise description and a concrete suggestion for correction
-
[13]
critique
If the code is already perfect and requires no changes, return a JSON object with an emptycritiquearray. Example: { "critique": [ { "issue_type": "Styling", "description": "The primary action button’s background color is incorrect. It appears as a standard blue but should be a specific shade of purple as per the design.", "suggestion": "In the button’s cl...
2026
-
[14]
Carefully review the entire current HTML code
-
[15]
Apply the suggestions to correct the code
If acritiqueJSON is provided, systematically address every issue listed. Apply the suggestions to correct the code
-
[16]
Independently identify and fix any potential issues related to layout, styling, semantic correctness, or component structure
If no critique is provided, perform a general review of the code. Independently identify and fix any potential issues related to layout, styling, semantic correctness, or component structure
-
[17]
Ensure your final output is a single, complete, and valid HTML document that incorporates all necessary corrections. Example Output: 1<!DOCTYPE html> 2<html lang="en"> 3<head> 4<meta charset="UTF-8"> 5<meta name="viewport" content="width=device-width, initial-scale=1.0"> 6<script src="https://cdn.tailwindcss.com"></script> 7<title>Refined Page</title> 8</...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.