Recognition: no theorem link
Vision2Code: A Multi-Domain Benchmark for Evaluating Image-to-Code Generation
Pith reviewed 2026-05-13 05:53 UTC · model grok-4.3
The pith
Vision2Code benchmark shows image-to-code performance depends on visual domain.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Vision2Code contains 2,169 test examples from 15 source datasets spanning charts and plots, geometry, graphs, scientific imagery, documents, and 3D spatial scenes. Models generate executable programs that are rendered and scored against the source image by a VLM rater using dataset-specific rubrics and deterministic guardrails for severe semantic failures. Human validation shows this evaluation protocol aligns better with human judgments than generic visual rubrics or embedding-similarity baselines. Across nine open-weight and proprietary models, image-to-code performance is domain-dependent: leading models perform well on regular chart- and graph-like visuals but remain weak on spatial 3D,
What carries the argument
The Vision2Code evaluation framework that renders model-generated code and scores reconstruction quality with a VLM rater using dataset-specific rubrics and deterministic guardrails.
If this is right
- Image-to-code performance varies by domain, with chart-like visuals easier than spatial scenes, documents, chemistry, or circuit diagrams.
- A VLM rater with custom rubrics and guardrails produces scores that match human judgments more closely than generic rubrics or embedding similarity.
- Model outputs that pass the evaluator can be filtered and reused as training data to raise image-to-code scores without paired reference programs.
- Render-success diagnostics separate execution failures from reconstruction quality, allowing targeted diagnosis of model weaknesses.
- The benchmark supplies a reproducible testbed for measuring and improving image-to-code generation across multiple visual domains.
Where Pith is reading between the lines
- The same reference-free scoring approach could be applied to other multimodal generation tasks such as diagram-to-text or scene-to-code.
- Domain-specific gaps suggest that targeted training on underrepresented visuals like 3D scenes and circuits would be more efficient than uniform scaling.
- Embedding the VLM rater directly into a training loop might enable iterative self-improvement without additional human labels.
- Future benchmarks might add temporal or interactive code outputs to test whether models can handle dynamic rather than static visuals.
Load-bearing premise
A VLM rater equipped with dataset-specific rubrics and guardrails can serve as a reliable proxy for human judgment of reconstruction quality across all 15 domains.
What would settle it
A fresh human rating study on several hundred model outputs where the VLM rater scores show low or negative correlation with human scores, or where the reported alignment advantage over generic rubrics disappears.
Figures


















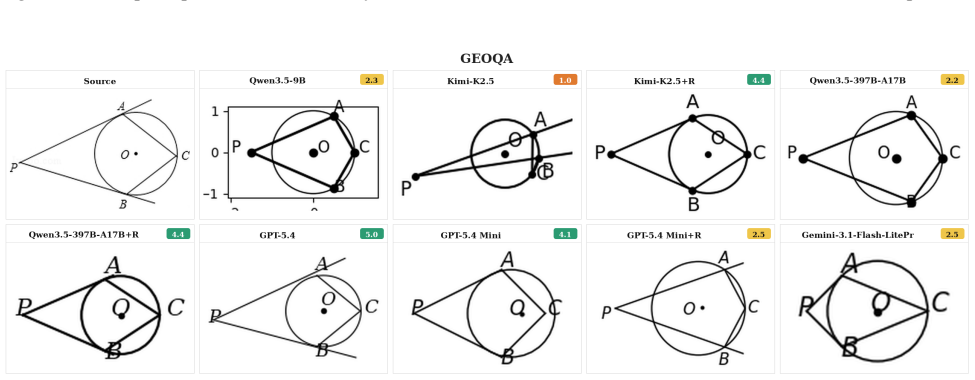



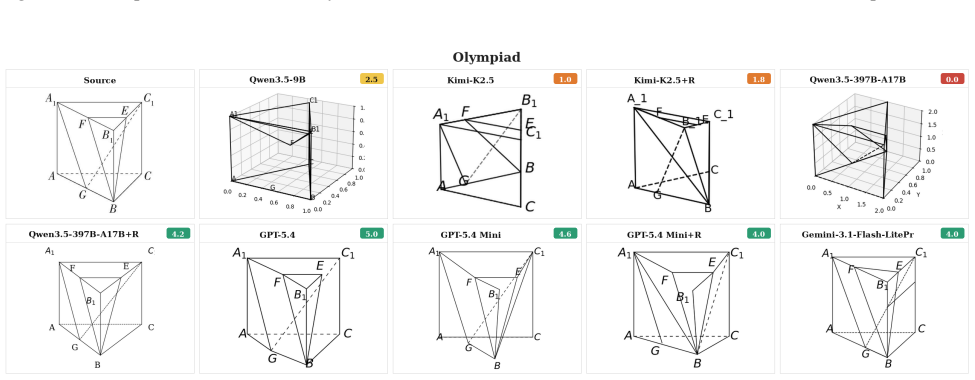





read the original abstract
Image-to-code generation tests whether a vision-language model (VLM) can recover the structure of an image enough to express it as executable code. Existing benchmarks either focus on narrow visual domains, depend on paired executable reference code, or rely on generic rubrics that miss domain-specific reconstruction errors. We introduce Vision2Code, a reference-code-free benchmark and evaluation framework for multi-domain image-to-code generation. Vision2Code contains 2,169 test examples from 15 source datasets that span charts and plots, geometry, graphs, scientific imagery, documents, and 3D spatial scenes. Models generate executable programs, which we render and score against the source image using a VLM rater with dataset-specific rubrics and deterministic guardrails for severe semantic failures. We report render-success diagnostics that separate code execution failures from reconstruction quality. Human validation shows that this evaluation protocol aligns better with human judgments than either a generic visual rubric or embedding-similarity baselines. Across nine open-weight and proprietary models, we find that image-to-code performance is domain-dependent: leading models perform well on regular chart- and graph-like visuals but remain weak on spatial scenes, chemistry, documents, and circuit-style diagrams. Finally, we show that evaluator-filtered model outputs can serve as training data to improve image-to-code capability, with Qwen3.5-9B improving from 1.60 to 1.86 on the benchmark without paired source programs. Vision2Code provides a reproducible testbed for measuring, diagnosing, and improving image-to-code generation. Our code and data are publicly available at https://image2code.github.io/vision2code/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Vision2Code, a reference-code-free benchmark and evaluation framework for image-to-code generation. It comprises 2,169 test examples drawn from 15 source datasets spanning charts/plots, geometry, graphs, scientific imagery, documents, and 3D spatial scenes. Models generate executable code that is rendered and scored by a VLM rater equipped with dataset-specific rubrics plus deterministic guardrails against severe semantic failures; render-success diagnostics separate execution from reconstruction quality. Human validation is reported to show superior alignment with human judgments relative to generic visual rubrics or embedding-similarity baselines. Experiments across nine open-weight and proprietary VLMs reveal domain-dependent performance (strong on regular charts/graphs, weak on spatial scenes, chemistry, documents, and circuits), and filtered model outputs are shown to improve a 9B model from 1.60 to 1.86 on the benchmark.
Significance. If the human-validated alignment of the VLM rater holds, the work supplies a reproducible, multi-domain testbed that directly addresses the narrow scope, reference-code dependence, and generic-metric limitations of prior image-to-code benchmarks. Public release of code and data, together with the self-improvement demonstration using evaluator-filtered outputs, adds practical value for the community. The domain-dependent performance findings are actionable for targeted model development.
major comments (2)
- [Human validation subsection] Human validation subsection: the claim that the protocol 'aligns better with human judgments' is central to the paper's contribution, yet the manuscript must report the exact sample size, number of raters, inter-rater agreement statistic (e.g., Cohen's kappa or Pearson r), and per-domain correlation values to allow readers to judge whether the superiority over baselines is statistically robust and generalizes across all 15 domains.
- [Evaluation framework section] Evaluation framework section (likely §3): the deterministic guardrails for semantic failures are load-bearing for the scoring reliability and render-success diagnostics; without explicit rules, pseudocode, or failure-mode examples, full reproduction of the reported scores is not guaranteed.
minor comments (3)
- [Results section] Table or figure presenting per-model, per-domain scores should include standard errors or confidence intervals to support the domain-dependence claim.
- [Abstract and results] The abstract states 'nine open-weight and proprietary models' but the main text should explicitly list all nine models and their exact benchmark scores in a single consolidated table for quick reference.
- [Benchmark description] Ensure all 15 source datasets are cited with original references in the benchmark description section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recommendation for minor revision. The two major comments highlight important aspects of reproducibility and statistical transparency that we will address directly in the revised manuscript.
read point-by-point responses
-
Referee: [Human validation subsection] Human validation subsection: the claim that the protocol 'aligns better with human judgments' is central to the paper's contribution, yet the manuscript must report the exact sample size, number of raters, inter-rater agreement statistic (e.g., Cohen's kappa or Pearson r), and per-domain correlation values to allow readers to judge whether the superiority over baselines is statistically robust and generalizes across all 15 domains.
Authors: We agree that these statistics are necessary to substantiate the central claim of superior alignment. Our human validation used a sample of 200 images (stratified to include at least 10 examples from each of the 15 domains), evaluated by 3 independent raters. Inter-rater agreement was 0.81 (average Cohen's kappa). Overall Pearson correlation between VLM rater scores and mean human scores was 0.87, exceeding both the generic visual rubric (0.62) and embedding baseline (0.71). Per-domain correlations ranged from 0.78 (3D scenes) to 0.93 (charts), with the VLM rater outperforming baselines in every domain. We will insert these details, including a summary table, into the Human validation subsection. revision: yes
-
Referee: [Evaluation framework section] Evaluation framework section (likely §3): the deterministic guardrails for semantic failures are load-bearing for the scoring reliability and render-success diagnostics; without explicit rules, pseudocode, or failure-mode examples, full reproduction of the reported scores is not guaranteed.
Authors: We acknowledge that the current description of the guardrails is insufficient for full reproducibility. In the revised manuscript we will expand §3 to include the complete set of deterministic rules (e.g., checks for missing axes, incorrect topology in graphs, and invalid chemical structures), pseudocode for the guardrail logic, and three annotated failure-mode examples with rendered outputs. These additions will be placed immediately after the description of the VLM rater and dataset-specific rubrics. revision: yes
Circularity Check
No significant circularity; evaluation validated against independent human judgments
full rationale
The paper introduces Vision2Code as a reference-code-free benchmark and validates its VLM-based scoring protocol (dataset-specific rubrics plus guardrails) directly against human judgments, showing better alignment than generic rubrics or embeddings. This external human validation step prevents any reduction of the central claim to self-defined inputs or fitted predictions. No equations, self-citation chains, or ansatzes are load-bearing; domain-dependent performance results follow from applying the externally checked protocol across models. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chartmimic: EvaluatingLMM’scross-modalreasoning capability via chart-to-code generation
Cheng Yang, Chufan Shi, Yaxin Liu, Bo Shui, Junjie Wang, Mohan Jing, Linran XU, Xinyu Zhu, Siheng Li, Yuxiang Zhang, GongyeLiu, XiaomeiNie, DengCai, andYujiuYang. Chartmimic: EvaluatingLMM’scross-modalreasoning capability via chart-to-code generation. InThe Thirteenth International Conference on Learning Representations, 2025a. URLhttps://openreview.net/f...
work page 2025
-
[2]
Jiajun Zhang, Yuying Li, Zhixun Li, Xingyu Guo, Jingzhuo Wu, Leqi Zheng, Yiran Yang, Jianke Zhang, Qingbin Li, Shannan Yan, et al. Realchart2code: Advancing chart-to-code generation with real data and multi-task evaluation.arXiv preprint arXiv:2603.25804, 2026a. URLhttps://arxiv.org/abs/2603.25804. Jiahao Tang, Henry Hengyuan Zhao, Lijian Wu, Zijian Zhang...
-
[3]
From Charts to Code: A Hierarchical Benchmark for Multimodal Models
URLhttps://arxiv.org/abs/2510.17932. Chenglei Si, Yanzhe Zhang, Ryan Li, Zhengyuan Yang, Ruibo Liu, and Diyi Yang. Design2Code: Benchmark- ing multimodal code generation for automated front-end engineering. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for C...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Association for Computational Linguistics. ISBN 979-8-89176-189-6. doi: 10.18653/v1/2025.naacl-long.199. URLhttps://aclanthology.org/2025.naacl-long.199/. Sukmin Yun, Haokun Lin, Rusiru Thushara, Mohammad Qazim Bhat, Yongxin Wang, Zutao Jiang, Mingkai Deng, Jinhong Wang, Tianhua Tao, Junbo Li, Haonan Li, Preslav Nakov, Timothy Baldwin, Zhengzhong Liu, Eri...
-
[5]
URLhttps://openreview.net/forum?id=hFVpqkRRH1. Cheng Zhang, Wenjing Wang, Hao Wang, Nuo Chen, Yinheng Chen, Qifan Wang, Tsung-Yi Ho Chen, and Xi- ang Ren. Widget2code: Benchmarking and developing code generation from visual widgets.arXiv preprint arXiv:2512.19918, 2026b. URLhttps://arxiv.org/abs/2512.19918. Jiawei Zhou, Chi Zhang, Xiang Feng, Qiming Zhang...
-
[6]
Fengji Zhang, Linquan Wu, Huiyu BAI, Guancheng Lin, Xiao Li, Xiao Yu, Yue Wang, Bei Chen, and Jacky Keung. Humaneval-v: Evaluating visual understanding and reasoning abilities of large multimodal models through coding tasks, 2024a. URLhttps://openreview.net/forum?id=KRdiRGSNc9. Kaixin Li, Yuchen Tian, Qisheng Hu, Ziyang Luo, Zhiyong Huang, and Jing Ma. Mm...
work page 2024
-
[7]
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji
URLhttps://proceedings.neurips.cc/ paper_files/paper/2023/file/871ed095b734818cfba48db6aeb25a62-Paper-Conference.pdf. Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. Executable code actions elicit better llm agents. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org,
work page 2023
-
[8]
Junhong Shen, Mu Cai, Bo Hu, Ameet Talwalkar, David A Ross, Cordelia Schmid, and Alireza Fathi. Recode: Reasoning through code generation for visual question answering.arXiv preprint arXiv:2510.13756,
-
[9]
11 Vision2Code: A Multi-Domain Benchmark for Evaluating Image-to-Code Generation Chengqi Duan, Kaiyue Sun, Rongyao Fang, Manyuan Zhang, Yan Feng, Ying Luo, Yufang Liu, Ke Wang, Peng Pei, Xunliang Cai, et al. Codeplot-cot: Mathematical visual reasoning by thinking with code-driven images.arXiv preprint arXiv:2510.11718,
-
[10]
arXiv preprint arXiv:2403.09029 (2024) 16 Zhilin Liu et al
Yushi Hu, Weijia Shi, Xingyu Fu, Dan Roth, Mari Ostendorf, Luke Zettlemoyer, Noah A Smith, and Ranjay Krishna. Visual sketchpad: Sketching as a visual chain of thought for multimodal language models.Advances in Neural Information Processing Systems, 37:139348–139379, 2024a. Yushi Hu, Otilia Stretcu, Chun-Ta Lu, Krishnamurthy Viswanathan, Kenji Hata, Enmin...
-
[11]
Figma2Code: Automating Multimodal Design to Code in the Wild
YiGui, JiawanZhang, YinaWang, TianranMa, YaoWan, ShilinHe, DongpingChen, ZhouZhao, WenbinJiang, Xuan- hua Shi, et al. Figma2code: Automating multimodal design to code in the wild.arXiv preprint arXiv:2604.13648,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Jinke Li, Jiarui Yu, Chenxing Wei, Hande Dong, Qiang Lin, Liangjing Yang, Zhicai Wang, and Yanbin Hao. Unisvg: A unified dataset for vector graphic understanding and generation with multimodal large language models. In Proceedings of the 33rd ACM International Conference on Multimedia, pages 13156–13163, 2025a. KevinQinghongLin,YuhaoZheng,HangyuRan,Danton...
-
[13]
Juan Rodriguez, Haotian Zhang, Abhay Puri, Tianyang Zhang, Rishav Pramanik, Meng Lin, Xiaoqing Xie, Marco Terral, Darsh Kaushik, Aly Shariff, et al. Vectorgym: A multitask benchmark for svg code generation, sketching, and editing.arXiv preprint arXiv:2603.29852,
-
[14]
Omnisvg: A unified scalable vector graphics generation model.arXiv preprint arXiv:2504.06263, 2025
Yiying Yang, Wei Cheng, Sijin Chen, Xianfang Zeng, Fukun Yin, Jiaxu Zhang, Liao Wang, Gang Yu, Xingjun Ma, and Yu-Gang Jiang. Omnisvg: A unified scalable vector graphics generation model.arXiv preprint arXiv:2504.06263, 2025b. Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mis...
-
[15]
Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque
URLhttps://openreview.net/forum?id=DEiNSfh1k7. Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. ChartQA: A benchmark for question answering about charts with visual and logical reasoning. InFindings of the Association for Computational Linguistics: ACL 2022, pages 2263–2279, Dublin, Ireland,
work page 2022
-
[16]
doi: 10.18653/v1/2022.findings-acl.177
Association for Computational Linguistics. doi: 10.18653/v1/2022.findings-acl.177. URLhttps://aclanthology.org/2022.findings-acl.177/. 12 Vision2Code: A Multi-Domain Benchmark for Evaluating Image-to-Code Generation Kushal Kafle, Brian Price, Scott Cohen, and Christopher Kanan. DVQA: Understanding data visualizations via question answering. InProceedings ...
-
[17]
doi: 10.1109/CVPR.2018.00592. URLhttps://openaccess.thecvf.com/content_ cvpr_2018/html/Kafle_DVQA_Understanding_Data_CVPR_2018_paper.html. Samira Ebrahimi Kahou, Vincent Michalski, Adam Atkinson, Ákos Kádár, Adam Trischler, and Yoshua Bengio. FigureQA:Anannotatedfiguredatasetforvisualreasoning. InInternationalConferenceonLearningRepresentations Workshop,
-
[18]
FigureQA: An Annotated Figure Dataset for Visual Reasoning
URLhttps://arxiv.org/abs/1710.07300. The Matplotlib Development Team. Matplotlib gallery.https://matplotlib.org/stable/gallery/index. html,
-
[19]
Accessed 2026-05-02. John D. Hunter. Matplotlib: A 2d graphics environment.Computing in Science & Engineering, 9(3):90–95,
work page 2026
-
[20]
D., 2007, @doi [Computing in Science Engineering] 10.1109/MCSE.2007.55 , 9, 90
doi: 10.1109/MCSE.2007.55. Jiarui Zhang, Ollie Liu, Tianyu Yu, Jinyi Hu, and Willie Neiswanger. Euclid: Supercharging multimodal llms with synthetic high-fidelity visual descriptions, 2024b. Jiaqi Chen, Jianheng Tang, Jinghui Qin, Xiaodan Liang, Lingbo Liu, Eric Xing, and Liang Lin. GeoQA: A geometric question answering benchmark towards multimodal numeri...
-
[21]
doi: 10.18653/v1/2021.findings-acl.46
Association for Computational Linguistics. doi: 10.18653/v1/2021.findings-acl.46. URLhttps://aclanthology.org/2021.findings-acl.46/. Lai Wei, Yuting Li, Chen Wang, Yue Wang, Linghe Kong, Weiran Huang, and Lichao Sun. First SFT, second RL, third UPT: Continual improving multi-modal LLM reasoning via unsupervised post-training,
-
[22]
Associated with the WaltonFuture GeoQA-8K-direct-synthesizing dataset release
URL https://arxiv.org/abs/2505.22453. Associated with the WaltonFuture GeoQA-8K-direct-synthesizing dataset release. Pan Lu, Ran Gong, Shibiao Jiang, Liang Qiu, Siyuan Huang, Xiaodan Liang, and Song-Chun Zhu. Inter-GPS: Interpretable geometry problem solving with formal language and symbolic reasoning. InProceedings of the 59th Annual Meeting of the Assoc...
-
[23]
doi: 10.18653/v1/2021.acl-long.528
Association for Computational Linguistics. doi: 10.18653/v1/2021.acl-long.528. URLhttps://aclanthology.org/2021. acl-long.528/. Ang Li, Charles L. Wang, Deqing Fu, Kaiyu Yue, Zikui Cai, Wang Bill Zhu, Ollie Liu, Peng Guo, Willie Neiswanger, Furong Huang, Tom Goldstein, and Micah Goldblum. Zebra-CoT: A dataset for interleaved vision-language reasoning. InI...
-
[24]
Dataset artifact; no verified academic parent publication identified; ac- cessed 2026-05-02
URLhttps://huggingface.co/datasets/ chandrabhuma/GraphVQA-Swift. Dataset artifact; no verified academic parent publication identified; ac- cessed 2026-05-02. Chandra Mohan Bhuma. ChemVQA-2K: A visual question answering dataset for molecular understanding. Hugging Face / IEEE DataPort dataset artifact,
work page 2026
-
[25]
URLhttps://aclanthology.org/ 2024.acl-long.211/
Association for Computational Linguistics. URLhttps://aclanthology.org/ 2024.acl-long.211/. Minesh Mathew, Dimosthenis Karatzas, and C. V. Jawahar. DocVQA: A dataset for vqa on document images. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2199–2208,
work page 2024
-
[26]
doi: 10.1109/WACV48630.2021.00225. URLhttps://openaccess.thecvf.com/content/WACV2021/html/ Mathew_DocVQA_A_Dataset_for_VQA_on_Document_Images_WACV_2021_paper.html. Litian2002. Synthetic spatial vision-language question answering dataset. Hugging Face dataset,
-
[27]
Dataset artifact; accessed 2026-05-
URL https://huggingface.co/datasets/Litian2002/spatialvlm_qa. Dataset artifact; accessed 2026-05-
work page 2026
-
[28]
Table 8:Cap profiles used by the rubric aggregator
Dataset-specific caps in Table 9 further prevent high final scores when a key semantic failure is present. Table 8:Cap profiles used by the rubric aggregator. A cap limits the final score to at most the listed value when its condition is met. Condition Strict Balanced Hard Any critical category≤threshold≤1.5⇒2.5≤1.5⇒2.8≤1.2⇒3.0 Both critical categories≤th...
work page 2022
-
[29]
Dataset Model Render % Image-only Image+text Raw Scaled Raw Scaled ChartQA Qwen3.5-9B 84.4 0.796 3.792 0.885 3.980 ChartQA Kimi-K2.5 100.0 0.870 4.676 0.921 4.803 ChartQA Qwen3.5-397B 95.6 0.768 4.223 0.857 4.436 ChemVQA-2K Qwen3.5-9B 34.9 0.622 1.416 0.819 1.588 ChemVQA-2K Kimi-K2.5 100.0 0.915 4.787 0.961 4.904 ChemVQA-2K Qwen3.5-397B 98.4 0.866 4.591 0...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.