Recognition: unknown
On the Effectiveness of Context Compression for Repository-Level Tasks: An Empirical Investigation
Pith reviewed 2026-05-10 12:56 UTC · model grok-4.3
The pith
Context compression improves repository-level code tasks by filtering noise, with continuous latent vector methods outperforming full context at 4x ratios.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Context compression is effective for repository-level code intelligence tasks. Continuous latent vector methods at 4x compression surpass full-context performance by up to 28.3 percent in BLEU score on code completion and generation, demonstrating that they filter noise rather than merely truncate. All three paradigms reduce inference cost, and visual plus text-based approaches achieve up to 50 percent end-to-end latency reduction at high ratios, nearing the expense of inference without repository context.
What carries the argument
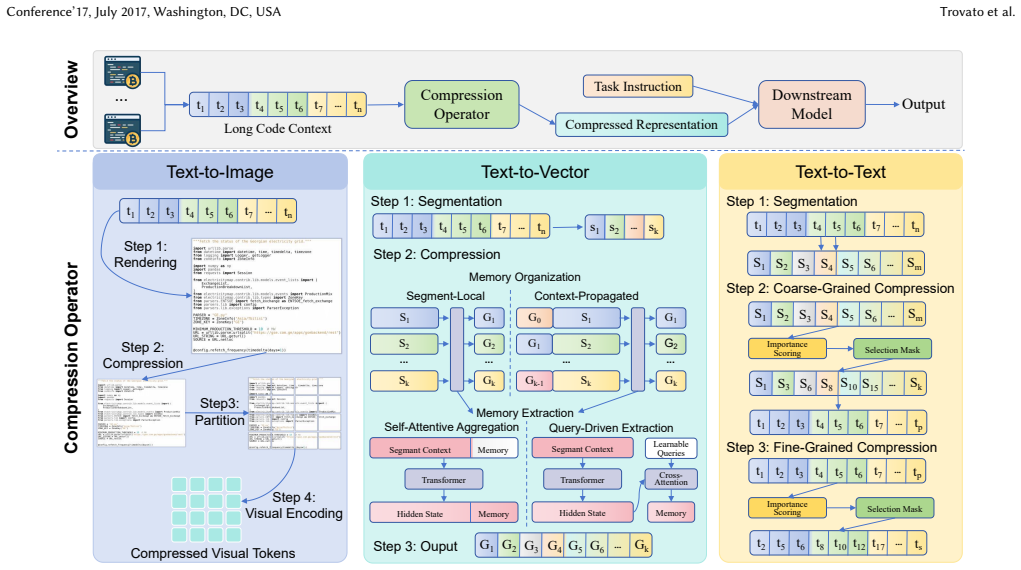
Three paradigms of context compression—discrete token sequences, continuous latent vectors, and visual tokens—applied to condense long multi-file repository inputs for language models performing code completion and generation.
If this is right
- Continuous latent vector compression can raise task accuracy instead of lowering it by removing noise from repository context.
- All compression paradigms lower inference costs relative to uncompressed full-context inputs.
- Visual and text-based methods can reduce end-to-end latency by up to 50 percent at high ratios while maintaining or exceeding full-context accuracy.
- Compressed inputs can approach the cost of running without any repository context while preserving or improving quality on the tested tasks.
Where Pith is reading between the lines
- The noise-filtering benefit observed here could apply to other repository-scale code activities such as bug localization or refactoring if similar irrelevant context patterns appear.
- Alternative evaluation measures beyond BLEU, such as execution success or human preference, would clarify whether the reported gains matter in actual development workflows.
- Hybrid systems that combine compression with selective retrieval might produce still larger efficiency or accuracy gains on very large repositories.
Load-bearing premise
That the chosen code completion and generation benchmarks together with BLEU scores adequately reflect real repository-level task difficulty and usefulness.
What would settle it
Evaluating the same compression methods on fresh repository tasks or with human developer judgments where higher BLEU scores do not translate into measurable improvements in task success or reduced developer effort.
Figures



read the original abstract
Repository-level code intelligence tasks require large language models (LLMs) to process long, multi-file contexts. Such inputs introduce three challenges: crucial context can be obscured by noise, truncated due to limited windows, and increased inference latency. Context compression mitigates these risks by condensing inputs. While studied in NLP, its applicability to code tasks remains largely unexplored. We present the first systematic empirical study of context compression for repository-level code intelligence, organizing eight methods into three paradigms: discrete token sequences, continuous latent vectors, and visual tokens. We evaluate them on code completion and generation, measuring performance and efficiency. Results show context compression is effective: at 4x compression, continuous latent vector methods surpass full-context performance by up to 28.3% in BLEU score, indicating they filter noise rather than just truncating. On efficiency, all paradigms reduce inference cost. Both visual and text-based compression achieve up to 50% reduction in end-to-end latency at high ratios, approaching the cost of inference without repository context. These findings establish context compression as a viable approach and provide guidance for paradigm selection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the first systematic empirical study of context compression for repository-level code intelligence tasks. It organizes eight methods into three paradigms (discrete token sequences, continuous latent vectors, and visual tokens) and evaluates them on code completion and generation benchmarks. Key results indicate that at 4x compression, continuous latent vector methods exceed full-context performance by up to 28.3% BLEU score (interpreted as noise filtering rather than truncation) while all paradigms reduce end-to-end latency by up to 50%.
Significance. If the results hold, this work is significant as the first systematic application of context compression to repository-level code tasks, providing evidence that compression can improve performance beyond efficiency gains and offering guidance on paradigm selection. Credit is due for the clear organization into paradigms and the joint reporting of performance (BLEU) and efficiency metrics.
major comments (2)
- [Abstract] Abstract: The claim that the 28.3% BLEU improvement at 4x compression demonstrates noise filtering (rather than mere truncation) is load-bearing for the central effectiveness conclusion, yet it relies solely on n-gram overlap without supporting analyses such as ablation on noise levels, information retention checks, or comparisons to random truncation baselines.
- [Results and Evaluation sections] Results and Evaluation sections: BLEU is used as the primary metric for code completion and generation, but it does not measure functional correctness, compilation, test passage, or semantic equivalence—metrics more relevant to repository-level tasks with cross-file dependencies. This weakens the interpretation that higher BLEU equates to better task usefulness or noise removal.
minor comments (2)
- [Experimental Setup] The manuscript would benefit from explicit details on benchmark selection criteria, data splits, and any statistical tests used to support the reported gains.
- Figure and table captions could more clearly label the three paradigms and compression ratios for easier cross-reference with the text.
Simulated Author's Rebuttal
Thank you for your thorough review of our manuscript. We appreciate the positive assessment of the work's significance and the constructive major comments. We address each point below and have made revisions to strengthen the paper where appropriate.
read point-by-point responses
-
Referee: [Abstract] The claim that the 28.3% BLEU improvement at 4x compression demonstrates noise filtering (rather than mere truncation) is load-bearing for the central effectiveness conclusion, yet it relies solely on n-gram overlap without supporting analyses such as ablation on noise levels, information retention checks, or comparisons to random truncation baselines.
Authors: We thank the referee for this observation. Our interpretation that the methods filter noise stems from the empirical result that compressed contexts achieve higher BLEU scores than the full context at 4x compression. This outperformance would be unlikely under simple truncation, as removing context should not improve n-gram overlap with the target. To address the request for additional support, we have added in the revised manuscript a baseline comparison with random truncation at equivalent compression rates, showing that our compression methods significantly outperform random selection. This provides evidence that the improvement is due to selective retention rather than truncation. We have also tempered the language in the abstract to present this as an indication rather than a definitive demonstration. revision: partial
-
Referee: [Results and Evaluation sections] BLEU is used as the primary metric for code completion and generation, but it does not measure functional correctness, compilation, test passage, or semantic equivalence—metrics more relevant to repository-level tasks with cross-file dependencies. This weakens the interpretation that higher BLEU equates to better task usefulness or noise removal.
Authors: We agree that BLEU has well-known limitations and does not directly evaluate functional correctness or semantic equivalence, which are indeed critical for repository-level code tasks. Our use of BLEU follows common practice in code generation research to enable quantitative comparison of generation quality via n-gram overlap. In the revised manuscript, we have added a dedicated paragraph in the Evaluation section discussing the choice of metrics, their limitations, and the implications for interpreting our results on noise filtering and task performance. We also highlight in the conclusion that future investigations should incorporate execution-based metrics to assess practical utility more comprehensively. revision: partial
Circularity Check
No circularity: purely empirical evaluation
full rationale
The paper is an empirical comparison of eight context compression methods across three paradigms on code completion and generation benchmarks. It reports direct measurements of BLEU scores and latency at varying compression ratios, with no derivation chain, first-principles predictions, fitted parameters renamed as predictions, or load-bearing self-citations. All claims rest on observable experimental outcomes rather than any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Cheng Cui, Ting Sun, Suyin Liang, Tingquan Gao, Zelun Zhang, Jiaxuan Liu, Xueqing Wang, Changda Zhou, Hongen Liu, Manhui Lin, Yue Zhang, Yubo Zhang, Handong Zheng, Jing Zhang, Jun Zhang, Yi Liu, Dianhai Yu, and Yanjun Ma. 2025. PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model. arXiv:2510.14528 [cs.CV] htt...
-
[3]
DeepSeek-AI. 2025. DeepSeek-V3 Technical Report. arXiv:2412.19437 [cs.CL] https://arxiv.org/abs/2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Mark Chen et al. 2021. Evaluating Large Language Models Trained on Code. arXiv:2107.03374 [cs.LG] https://arxiv.org/abs/2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Raymond Li et al. 2023. StarCoder: may the source be with you! arXiv:2305.06161 [cs.CL] https://arxiv.org/abs/2305.06161
work page internal anchor Pith review arXiv 2023
- [6]
-
[7]
Jia Feng, Jiachen Liu, Cuiyun Gao, Chun Yong Chong, Chaozheng Wang, Shan Gao, and Xin Xia. 2024. ComplexCodeEval: A Benchmark for Evaluating Large Code Models on More Complex Code. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (ASE ’24). ACM, 1895–1906. doi:10.1145/3691620.3695552
- [8]
-
[9]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, and Ming Zhou. 2020. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. arXiv:2002.08155 [cs.CL] https://arxiv.org/abs/2002.08155
work page internal anchor Pith review arXiv 2020
- [10]
-
[11]
Daya Guo, Shuai Lu, Nan Duan, Yanlin Wang, Ming Zhou, and Jian Yin
-
[12]
Unixcoder: Unified cross-modal pre-training for code representation,
UniXcoder: Unified Cross-Modal Pre-training for Code Representation. arXiv:2203.03850 [cs.CL] https://arxiv.org/abs/2203.03850
-
[13]
Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, Long Zhou, Nan Duan, Alexey Svyatkovskiy, Shengyu Fu, Michele Tufano, Shao Kun Deng, Colin Clement, Dawn Drain, Neel Sundaresan, Jian Yin, Daxin Jiang, and Ming Zhou. 2021. GraphCodeBERT: Pre-training Code Representations with Data Flow. arXiv:2009.08366 [cs.SE] https://arxiv.org/abs/2009.08366
-
[14]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y. Wu, Y. K. Li, Fuli Luo, Yingfei Xiong, and Wen- feng Liang. 2024. DeepSeek-Coder: When the Large Language Model Meets Programming – The Rise of Code Intelligence. arXiv:2401.14196 [cs.SE] https: //arxiv.org/abs/2401.14196
work page internal anchor Pith review arXiv 2024
- [15]
-
[16]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, Kai Dang, Yang Fan, Yichang Zhang, An Yang, Rui Men, Fei Huang, Bo Zheng, Yibo Miao, Shanghaoran Quan, Yunlong Feng, Xingzhang Ren, Xuancheng Ren, Jingren Zhou, and Junyang Lin. 2024. Conference’17, July 2017, Washington, DC, USA Trovato e...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [17]
- [18]
-
[19]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2026. A Survey on Large Language Models for Code Generation.ACM Transactions on Software Engineering and Methodology35, 2 (Jan. 2026), 1–72. doi:10.1145/3747588
-
[20]
Cornelius Lanczos. 1964. Evaluation of noisy data.Journal of the Society for Industrial and Applied Mathematics, Series B: Numerical Analysis1, 1 (1964), 76–85
1964
-
[21]
Yucheng Li, Bo Dong, Frank Guerin, and Chenghua Lin. 2023. Compressing Context to Enhance Inference Efficiency of Large Language Models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 6342–6353. doi:10.18653/v1...
- [22]
- [23]
-
[24]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the Middle: How Language Models Use Long Contexts.Transactions of the Association for Computational Linguistics 12 (2024), 157–173. doi:10.1162/tacl_a_00638
- [25]
-
[26]
OpenAI. 2024. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL] https://arxiv. org/abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Menglin Xia, Xufang Luo, Jue Zhang, Qingwei Lin, Victor Rühle, Yuqing Yang, Chin-Yew Lin, H. Vicky Zhao, Lili Qiu, and Dongmei Zhang. 2024. LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression. arXiv:2403.12968 [cs.CL] https: //arxiv.org/abs/2403.12968
-
[28]
Fei Qi, Yingnan Hou, Ning Lin, Shanshan Bao, and Nuo Xu. 2024. A Survey of Testing Techniques Based on Large Language Models. InProceedings of the 2024 International Conference on Computer and Multimedia Technology(Sanming, China)(ICCMT ’24). Association for Computing Machinery, New York, NY, USA, 280–284. doi:10.1145/3675249.3675298
-
[29]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiao- qing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cris- tian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, ...
work page internal anchor Pith review arXiv 2024
- [31]
- [32]
-
[33]
Gemini Team. 2025. Gemini: A Family of Highly Capable Multimodal Models. arXiv:2312.11805 [cs.CL] https://arxiv.org/abs/2312.11805
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Linformer: Self-Attention with Linear Complexity
Sinong Wang, Belinda Z. Li, Madian Khabsa, Han Fang, and Hao Ma. 2020. Linformer: Self-Attention with Linear Complexity. arXiv:2006.04768 [cs.LG] https://arxiv.org/abs/2006.04768
work page internal anchor Pith review arXiv 2020
- [35]
- [36]
-
[37]
Haoran Wei, Yaofeng Sun, and Yukun Li. 2025. DeepSeek-OCR: Contexts Optical Compression. arXiv:2510.18234 [cs.CV] https://arxiv.org/abs/2510.18234
work page internal anchor Pith review arXiv 2025
- [38]
-
[39]
Bissyandé, Yang Liu, and Haoye Tian
Boyang Yang, Zijian Cai, Fengling Liu, Bach Le, Lingming Zhang, Tegawendé F. Bissyandé, Yang Liu, and Haoye Tian. 2025. A Survey of LLM-based Au- tomated Program Repair: Taxonomies, Design Paradigms, and Applications. arXiv:2506.23749 [cs.SE] https://arxiv.org/abs/2506.23749
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.