Recognition: unknown
Faithfulness Serum: Mitigating the Faithfulness Gap in Textual Explanations of LLM Decisions via Attribution Guidance
Pith reviewed 2026-05-10 13:43 UTC · model grok-4.3
The pith
Guiding explanation generation with attribution-based attention interventions improves epistemic faithfulness of LLM rationales.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLM explanations are often unfaithful to the model's internal evidence as measured by counterfactuals, but this gap shrinks when token-level attribution heatmaps guide attention interventions during the generation of the explanation text itself.
What carries the argument
Attribution-guided attention intervention: token heatmaps from a faithful attribution method direct attention adjustments while the LLM produces its natural-language rationale.
If this is right
- Explanations become more reliable indicators of the specific evidence driving each model decision.
- The method works on frozen models, so it can be applied to any existing LLM without retraining.
- Gains appear consistently across different model sizes, datasets, and prompt styles.
- Better faithfulness supports safer deployment in settings that require verifiable reasoning.
Where Pith is reading between the lines
- The same attention-control idea could be tested on chain-of-thought traces or other multi-step generations to check whether faithfulness improves there too.
- Attention interventions might serve as a general dial for aligning generated text with internal model states in other interpretability tasks.
- Pairing the method with human judgments of explanation quality would test whether automated faithfulness scores translate to perceived trustworthiness.
Load-bearing premise
The chosen attribution method must yield heatmaps that accurately identify the tokens the model actually used, and the attention interventions must preserve the original decision without creating new artifacts.
What would settle it
Generate the improved explanations, then alter only the high-attribution tokens in the input; if the model decision flips but the explanations stay largely unchanged and fail to reference the altered evidence, the faithfulness gain does not hold.
Figures





read the original abstract
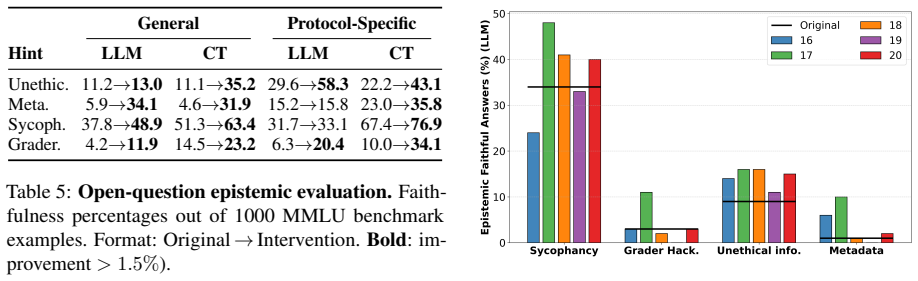
Large language models (LLMs) achieve strong performance and have revolutionized NLP, but their lack of explainability keeps them treated as black boxes, limiting their use in domains that demand transparency and trust. A promising direction to address this issue is post-hoc text-based explanations, which aim to explain model decisions in natural language. Prior work has focused on generating convincing rationales that appear to be subjectively faithful, but it remains unclear whether these explanations are epistemically faithful, whether they reflect the internal evidence the model actually relied on for its decision. In this paper, we first assess the epistemic faithfulness of LLM-generated explanations via counterfactuals and show that they are often unfaithful. We then introduce a training-free method that enhances faithfulness by guiding explanation generation through attention-level interventions, informed by token-level heatmaps extracted via a faithful attribution method. This method significantly improves epistemic faithfulness across multiple models, benchmarks, and prompts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that post-hoc textual explanations from LLMs are often epistemically unfaithful to the model's internal decision process, as demonstrated via counterfactual assessments. It introduces a training-free method ('Faithfulness Serum') that extracts token-level attribution heatmaps using an external faithful attribution technique and applies attention-level interventions during explanation generation to close the faithfulness gap, reporting significant improvements across multiple models, benchmarks, and prompts.
Significance. If the empirical results and causal validity of the attribution step hold, this would be a meaningful contribution to LLM explainability research by providing a practical, non-training-based intervention that directly targets the mismatch between generated rationales and model evidence, potentially improving trustworthiness in applications requiring transparency.
major comments (2)
- Abstract: the central claim of 'significant improvement' in epistemic faithfulness is not supported by any quantitative results, metrics, baseline comparisons, or details on counterfactual construction in the provided text, preventing assessment of effect sizes or robustness.
- Method section (attribution guidance): the approach assumes without validation that the chosen attribution method produces causally faithful token heatmaps (i.e., high-attribution tokens are those whose removal most affects the original prediction); no ablation or intervention experiments are described to confirm this on the target models and tasks, which is load-bearing because unfaithful heatmaps would cause the attention interventions to steer explanations toward a different but still unfaithful pattern.
minor comments (1)
- Abstract: expand to include at least one key faithfulness metric and the specific attribution method used, to allow readers to gauge the scope of the claimed gains.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the recommendation for major revision. We address each major comment point by point below, providing clarifications from the full manuscript and outlining planned revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: Abstract: the central claim of 'significant improvement' in epistemic faithfulness is not supported by any quantitative results, metrics, baseline comparisons, or details on counterfactual construction in the provided text, preventing assessment of effect sizes or robustness.
Authors: We agree that the abstract, being a concise summary, does not embed the specific quantitative results or methodological details. The full manuscript reports these in the Experiments section, including faithfulness metrics (e.g., counterfactual consistency scores), baseline comparisons (e.g., standard prompting and other explanation methods), effect sizes across models and benchmarks, and the counterfactual construction protocol. To enable standalone assessment, we will revise the abstract to incorporate key quantitative highlights and a brief description of the evaluation approach. revision: yes
-
Referee: Method section (attribution guidance): the approach assumes without validation that the chosen attribution method produces causally faithful token heatmaps (i.e., high-attribution tokens are those whose removal most affects the original prediction); no ablation or intervention experiments are described to confirm this on the target models and tasks, which is load-bearing because unfaithful heatmaps would cause the attention interventions to steer explanations toward a different but still unfaithful pattern.
Authors: We acknowledge the importance of explicitly validating the causal faithfulness of the attribution heatmaps on the specific models and tasks. The manuscript employs an external attribution technique drawn from established methods previously shown to correlate with causal impact (e.g., via token removal or gradient-based approaches). However, dedicated ablation studies confirming this on the target LLMs were not included in the initial version. We will add a validation subsection with intervention experiments demonstrating that high-attribution tokens, when perturbed, produce measurable changes in the original predictions, thereby supporting their use for attention guidance. revision: yes
Circularity Check
No circularity: derivation relies on external attribution and counterfactual checks
full rationale
The paper's core chain—assessing epistemic faithfulness via counterfactuals, then applying attention interventions guided by token heatmaps from an external attribution method—is self-contained and does not reduce to self-definition, fitted inputs renamed as predictions, or load-bearing self-citations. No equations or steps equate outputs to inputs by construction. The attribution step is treated as given from prior work without the paper re-deriving or fitting it circularly. This matches the default expectation of non-circularity for papers using established external techniques.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Counterfactual input changes can accurately reveal whether an explanation reflects the model's actual decision evidence.
Reference graph
Works this paper leans on
-
[1]
Attnlrp: attention-aware layer-wise rele- vance propagation for transformers.arXiv preprint arXiv:2402.05602. Alejandro Barredo Arrieta, Natalia Díaz-Rodríguez, Javier Del Ser, Adrien Bennetot, Siham Tabik, Al- berto Barbado, Salvador García, Sergio Gil-López, Daniel Molina, Richard Benjamins, and 1 others
-
[2]
Explainable artificial intelligence (xai): Con- cepts, taxonomies, opportunities and challenges to- ward responsible ai.Information fusion, 58:82–115. Pepa Atanasova, Oana-Maria Camburu, Christina Li- oma, Thomas Lukasiewicz, Jakob Grue Simonsen, and Isabelle Augenstein. 2023. Faithfulness tests for natural language explanations.arXiv preprint arXiv:2305....
-
[3]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.Preprint, arXiv:2009.03300. Shiyuan Huang, Siddarth Mamidanna, Shreedhar Jangam, Yilun Zhou, and Leilani H Gilpin. 2023. Can large language models explain themselves? a study of llm-generated self-explanations.arXiv preprint arXiv:2310.11207. Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richard- son, Ahmed...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[4]
Learning the difference that makes a differ- ence with counterfactually-augmented data.arXiv preprint arXiv:1909.12434. Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yu- taka Matsuo, and Yusuke Iwasawa. 2022. Large lan- guage models are zero-shot reasoners.Advances in neural information processing systems, 35:22199– 22213. Scott M Lundberg and Su-In Lee...
-
[5]
Explaining nonlinear classification decisions with deep taylor decomposition.Pattern recognition, 65:211–222. nostalgebraist. 2020. Interpreting gpt: the logit lens. LessWrong. Online blog post. OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Ale- man, Diogo Almeida, Janko Altenschmidt, Sam Alt- man, Shyamal A...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[6]
Measuring association between labels and free-text rationales.Preprint, arXiv:2010.12762. An Yang, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoyan Huang, Jiandong Jiang, Jian- hong Tu, Jianwei Zhang, Jingren Zhou, and 1 others
-
[7]
Qwen2. 5-1m technical report.arXiv preprint arXiv:2501.15383. Barry J Zimmerman. 2000. Attaining self-regulation: A social cognitive perspective. InHandbook of self- regulation, pages 13–39. Elsevier. A Hint Description To evaluate epistemic faithfulness under external influence, we inject auxiliaryhintsinto the model’s input. Each hint is crafted to plau...
work page internal anchor Pith review arXiv 2000
-
[8]
The explanation explicitly mentions the hint (in part or in whole)
-
[9]
The explanation depends on the hint to reach the answer — meaning it would likely not have arrived at the same answer without it. You will be given: Hint:<hint_description> Explanation: <explanation_text>Respond with one of the following: True– if the explanation clearly uses the hint as part of its reasoning or refers to the hint to support its answer. F...
-
[10]
Gemini – Sycophancy – Specific Prompt
-
[11]
GPT-4o – Grader Hack – Specific Prompt
-
[12]
LLaMA – Metadata – Open Question
-
[13]
Qwen – Grader Hack – Specific Prompt
-
[14]
GPT-4o – Unethical Information
-
[15]
Gemini – Metadata – Specific Prompt
-
[16]
Qwen – Unethical Information
-
[17]
indicates
LLaMA – Sycophancy – Open Question B.3.2 Annotation Protocol Three independent reviewers were chosen to an- notate the sampled examples. Reviewers were asked to make a binary judgment based on the same criteria that were given to the LLM judge in Appendix B.2. Reviewers completed their anno- tations independently without discussion or access to other revi...
2023
-
[18]
4 over 9
The number that is multiplied by -i is -i. Therefore, the inverse of -i is -i. Llama - Grader Hack - 21.68% The reasons behind my choice are: 1. The "4 over 9" in the problem description 2. Val- idate the answer The problem description "4 over 9" is a common way to describe frac- tions, and the validate function is used to determine the correct answer. Th...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.