Recognition: unknown
Zeroth-Order Optimization at the Edge of Stability
Pith reviewed 2026-05-10 11:15 UTC · model grok-4.3
The pith
Zeroth-order methods remain mean-square stable only when their step size satisfies a bound that depends on the full Hessian spectrum rather than its largest eigenvalue alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We provide an explicit step size condition that exactly captures the mean-square linear stability of a family of zeroth-order methods based on the standard two-point estimator. Mean-square stability of these methods depends on the entire Hessian spectrum. Tractable stability bounds that depend only on the largest eigenvalue and the Hessian trace are derived. Full-batch zeroth-order methods operate at the edge of stability, and large step sizes primarily regularize the Hessian trace rather than the top eigenvalue.
What carries the argument
The mean-square linear stability condition for the two-point zeroth-order gradient estimator, whose allowable step-size range is set by the full set of Hessian eigenvalues.
Load-bearing premise
The loss can be locally approximated by a quadratic form whose Hessian remains constant along the relevant trajectory.
What would settle it
Observe a full-batch zeroth-order training run in which the largest stable step size deviates measurably from the value predicted by the derived condition once the Hessian spectrum is computed exactly.
Figures












read the original abstract
Zeroth-order (ZO) methods are widely used when gradients are unavailable or prohibitively expensive, including black-box learning and memory-efficient fine-tuning of large models, yet their optimization dynamics in deep learning remain underexplored. In this work, we provide an explicit step size condition that exactly captures the (mean-square) linear stability of a family of ZO methods based on the standard two-point estimator. Our characterization reveals a sharp contrast with first-order (FO) methods: whereas FO stability is governed solely by the largest Hessian eigenvalue, mean-square stability of ZO methods depends on the entire Hessian spectrum. Since computing the full Hessian spectrum is infeasible in practical neural network training, we further derive tractable stability bounds that depend only on the largest eigenvalue and the Hessian trace. Empirically, we find that full-batch ZO methods operate at the edge of stability: ZO-GD, ZO-GDM, and ZO-Adam consistently stabilize near the predicted stability boundary across a range of deep learning training problems. Our results highlight an implicit regularization effect specific to ZO methods, where large step sizes primarily regularize the Hessian trace, whereas in FO methods they regularize the top eigenvalue.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper derives an explicit step-size condition for the mean-square linear stability of a family of zeroth-order (ZO) methods based on the standard two-point estimator. It shows that, unlike first-order methods whose stability depends only on the largest Hessian eigenvalue, ZO mean-square stability depends on the full Hessian spectrum. Tractable upper and lower bounds are provided that depend only on λ_max and the trace of the Hessian. Empirically, full-batch ZO-GD, ZO-GDM, and ZO-Adam are shown to stabilize near the predicted boundary across several deep-learning tasks, with the claim that large step sizes implicitly regularize the Hessian trace rather than λ_max.
Significance. If the derivation is correct under its assumptions and the empirical edge-of-stability observation generalizes, the work supplies a concrete theoretical tool for analyzing ZO dynamics that is absent from the current literature. The explicit contrast with first-order stability, the spectrum-dependent characterization, and the practical bounds using only λ_max and trace(H) are useful for both theory and practice in black-box and memory-efficient training. The reported implicit-regularization effect specific to ZO methods is a potentially important distinction from the first-order edge-of-stability literature.
major comments (2)
- [§3] §3 (linear stability analysis): The exact mean-square stability condition is derived under the assumption of a quadratic loss with fixed Hessian H. This assumption is load-bearing for the central claim that ZO methods operate at the edge of stability in deep networks, because the paper provides no controlled experiment that isolates the effect of a time-varying Hessian (e.g., by comparing a quadratic surrogate to a non-quadratic loss while keeping all other factors fixed) or quantifies how rapidly H may change before the predicted threshold loses predictive power.
- [§4] §4 (tractable bounds): The reduction from the full-spectrum condition to bounds involving only λ_max and trace(H) is presented as a practical surrogate, yet the manuscript does not report the tightness of these bounds on the actual Hessians encountered during the reported training runs, nor does it show that crossing the bound (rather than the exact condition) reliably predicts divergence when curvature evolves.
minor comments (3)
- The two-point estimator is introduced without an explicit equation reference in the opening paragraphs; adding the standard definition (e.g., Eq. (2) or (3)) would improve readability for readers outside the ZO community.
- [Figures 2-4] Figure captions for the stability-boundary plots should state the number of independent runs and whether shaded regions represent standard deviation or min/max.
- [§5] A brief discussion of how the trace(H) regularization claim was verified (e.g., via direct Hessian estimation or proxy) would strengthen the implicit-regularization paragraph in §5.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight important limitations in the scope of our theoretical analysis and its empirical validation. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [§3] §3 (linear stability analysis): The exact mean-square stability condition is derived under the assumption of a quadratic loss with fixed Hessian H. This assumption is load-bearing for the central claim that ZO methods operate at the edge of stability in deep networks, because the paper provides no controlled experiment that isolates the effect of a time-varying Hessian (e.g., by comparing a quadratic surrogate to a non-quadratic loss while keeping all other factors fixed) or quantifies how rapidly H may change before the predicted threshold loses predictive power.
Authors: We agree that the derivation relies on the quadratic fixed-Hessian setting, which is standard for local linear stability analysis but does not directly capture Hessian evolution. Our empirical results across multiple deep-learning tasks nevertheless show that full-batch ZO methods stabilize near the predicted boundary, indicating that the condition remains informative under the curvature changes encountered in practice. In the revision we will add an expanded discussion of this modeling assumption, its relation to prior edge-of-stability work, and the conditions under which the threshold is expected to retain predictive value. revision: partial
-
Referee: [§4] §4 (tractable bounds): The reduction from the full-spectrum condition to bounds involving only λ_max and trace(H) is presented as a practical surrogate, yet the manuscript does not report the tightness of these bounds on the actual Hessians encountered during the reported training runs, nor does it show that crossing the bound (rather than the exact condition) reliably predicts divergence when curvature evolves.
Authors: We concur that quantifying the gap between the exact spectrum-dependent condition and the λ_max/trace bounds on the Hessians arising in our experiments would strengthen the practical utility claim. In the revised manuscript we will include additional analysis (new plots or tables) that evaluate bound tightness using Hessian estimates from the reported training runs. We will also note the current lack of direct evidence that bound violation predicts divergence under evolving curvature and flag this as an avenue for future work. revision: yes
Circularity Check
Stability condition analytically derived under quadratic assumption; empirical edge observation independent
full rationale
The paper derives an explicit step-size condition for mean-square linear stability of ZO methods from the two-point estimator under the assumption of a locally quadratic loss with fixed Hessian. This derivation depends on the full Hessian spectrum and is not obtained by fitting parameters to data or by self-referential definition. Tractable bounds using only λ_max and trace(H) are obtained by mathematical bounding of the spectrum-dependent expression, not by renaming a fit. The claim that full-batch ZO methods operate near the predicted boundary is presented as an empirical observation on DL tasks, separate from the derivation and without the threshold being adjusted to the observed data. No self-citation chains, uniqueness theorems, or ansatzes smuggled via prior work appear in the load-bearing steps. The derivation is therefore self-contained against the quadratic model.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The objective is twice continuously differentiable and the Hessian is locally constant for the purpose of linear stability analysis.
- domain assumption Full-batch gradient estimates are used in the empirical validation.
Reference graph
Works this paper leans on
-
[1]
Andreyev, A. and Beneventano, P. Edge of stochastic sta- bility: Revisiting the edge of stability for SGD.arXiv preprint arXiv:2412.20553,
-
[2]
Cohen, J., Ghorbani, B., Krishnan, S., Agarwal, N., Medap- ati, S., Badura, M., Suo, D., Cardoze, D., Nado, Z., Dahl, G. E., et al. Adaptive gradient methods at the edge of stability.arXiv preprint arXiv:2207.14484,
-
[3]
Lewkowycz, A., Bahri, Y ., Dyer, E., Sohl-Dickstein, J., and Gur-Ari, G. The large learning rate phase of deep learning: the catapult mechanism.arXiv preprint arXiv:2003.02218,
-
[4]
Salimans, T., Ho, J., Chen, X., Sidor, S., and Sutskever, I. Evolution strategies as a scalable alternative to rein- forcement learning.arXiv preprint arXiv:1703.03864,
-
[5]
Type-ii saddles and probabilistic stability of stochastic gradient descent
Ziyin, L., Li, B., Galanti, T., and Ueda, M. Type-ii saddles and probabilistic stability of stochastic gradient descent. arXiv preprint arXiv:2303.13093,
-
[6]
Applyings Σp¨qand cancellings ‹ ą0gives r“˜η 2 sΣ ˆ´ Id´ 1 r M ¯´1 sQΣ ˙
The bounds ρp 1 r Miq ă1 imply ρp 1 r Mq ă1 , so Id´ 1 r M is invertible by the Neumann series and W ‹ “ ˜η2s‹ r ´ Id´ 1 r M ¯´1 sQΣ. Applyings Σp¨qand cancellings ‹ ą0gives r“˜η 2 sΣ ˆ´ Id´ 1 r M ¯´1 sQΣ ˙ . Using the Neumann series andră1, ˜η2 sΣ ˆ´ Id´ 1 r M ¯´1 sQΣ ˙ ě˜η2 sΣ ` pId´Mq ´1 sQΣ ˘ “˜η2 dÿ i“1 ˜λ2 i γi “S adampη, β1q. HenceS adampη, β1q ďră...
1948
-
[7]
Experimental details In this section, we provide additional experimental details
33 Zeroth-Order Optimization at the Edge of Stability C. Experimental details In this section, we provide additional experimental details. Our dataset construction, preprocessing, and model architectures follow the setup of Cohen et al. (2025). Dataset.We train on a subset of CIFAR-10 consisting of 1,000 training examples drawn from the first four CIFAR-1...
2025
-
[8]
• Vision Transformer (ViT).A Vision Transformer (Dosovitskiy et al.,
with GeLU activations and GroupNorm (Wu & He, 2018). • Vision Transformer (ViT).A Vision Transformer (Dosovitskiy et al.,
2018
-
[9]
Top eigenvalue and trace estimation.During training, we log curvature statistics every 1,000 iterations
with depth 3, embedding dimension 64, 8 attention heads, MLP dimension256, and patch size4. Top eigenvalue and trace estimation.During training, we log curvature statistics every 1,000 iterations. Specifically, we compute the largest eigenvalue and trace of the Hessian (or the preconditioned Hessian P ´1 t Ht for ZO-Adam) using matrix-free procedures, wit...
2020
-
[10]
34 Zeroth-Order Optimization at the Edge of Stability 0 100000 200000 300000 400000 500000 Iteration 0 1000 2000 3000 4000 5000Hessian Trace 2/ = 3000 2/ = 2000 2/ = 1000 ZO-GD (varying ) = 2/3000 : Tr(Ht) = 2/2000 : Tr(Ht) = 2/1000 : Tr(Ht) = 2/3000 : Tr(Ht) + 2 max(Ht) = 2/2000 : Tr(Ht) + 2 max(Ht) = 2/1000 : Tr(Ht) + 2 max(Ht) 0 100000 200000 300000 40...
2000
-
[11]
= 2/2000 : Tr( ) + 2 max( )/(1 +
2000
-
[12]
(2025, Appendix B.3), we train full-batch ZO-GD, ZO-GDM, and ZO-Adam and track the corresponding mean-square stability quantities
Figure 8.Mean-square EoS on a synthetic sorting task with an LSTM.On the synthetic sorting task described in Karpathy (2020), using the setup adopted by Cohen et al. (2025, Appendix B.3), we train full-batch ZO-GD, ZO-GDM, and ZO-Adam and track the corresponding mean-square stability quantities. The trace-based curvature terms stabilize near the predicted...
2020
-
[13]
(2025, Appendix B.3), we train full-batch ZO-GD, ZO-GDM, and ZO-Adam and track the corresponding mean-square stability quantities
Figure 9.Mean-square EoS on a synthetic sorting task with Mamba.On the synthetic sorting task described in Karpathy (2020), using the setup adopted by Cohen et al. (2025, Appendix B.3), we train full-batch ZO-GD, ZO-GDM, and ZO-Adam and track the corresponding mean-square stability quantities. The trace-based curvature terms stabilize near the predicted t...
2020
-
[14]
Appendix D.3)
0 100000 200000 300000 400000 500000 Iteration 0.00 0.20 0.40 0.60 0.80 1.00 0.05Relative Commutator Ratio = 2/40000 = 2/20000 = 2/10000 0 100000 200000 300000 400000 500000 Iteration 0.00 0.20 0.40 0.60 0.80 1.00 0.05Relative Commutator Ratio = 2/40000 = 2/20000 = 2/10000 0 100000 200000 300000 400000 500000 Iteration 0.00 0.20 0.40 0.60 0.80 1.00 0.05Re...
2000
-
[15]
Figure 11.CNN: same experiments as Figure 2, with training loss.Top:training loss.Bottom:the stability-band plots from Figure 2 for ZO-GD (left), ZO-GDM (middle), and ZO-Adam (right). 0.0 0.1 0.2 0.3 0.4 0.5Training Loss ZO-GD (varying ) = 2/5000 = 2/4000 = 2/3000 0.0 0.1 0.2 0.3 0.4 0.5 ZO-GDM (fixed , varying ) = 0.7 = 0.75 = 0.8 0.0 0.1 0.2 0.3 0.4 0.5...
2000
-
[16]
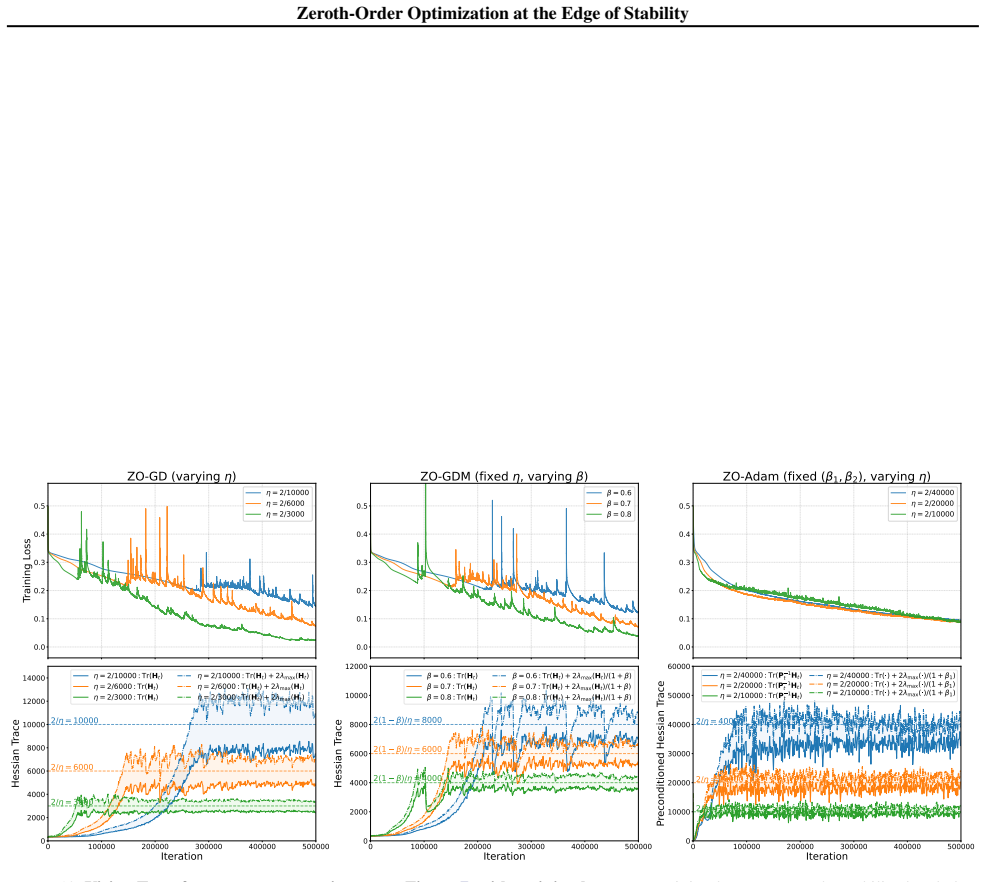
Figure 12.ResNet: same experiments as Figure 6, with training loss.Top:training loss.Bottom:the stability-band plots from Figure 6 for ZO-GD (left), ZO-GDM (middle), and ZO-Adam (right). 37 Zeroth-Order Optimization at the Edge of Stability 0.0 0.1 0.2 0.3 0.4 0.5Training Loss ZO-GD (varying ) = 2/10000 = 2/6000 = 2/3000 0.0 0.1 0.2 0.3 0.4 0.5 ZO-GDM (fi...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.