Recognition: unknown
Can LLMs Score Medical Diagnoses and Clinical Reasoning as well as Expert Panels?
Pith reviewed 2026-05-10 11:29 UTC · model grok-4.3
The pith
A calibrated LLM jury of frontier models scores medical diagnoses and clinical reasoning as reliably as expert clinician panels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A multi-model LLM jury composed of three frontier AI models, when calibrated with isotonic regression, serves as a trustworthy proxy for expert clinician panels. It scores real-world medical cases on four dimensions, preserves ordinal rankings, exhibits higher concordance with primary expert panels than independent human re-score panels, produces fewer severe safety errors, shows no self-preference bias, and enables targeted expert review of high-risk diagnoses.
What carries the argument
The LLM jury: an ensemble of three frontier models that scores diagnoses on four fixed dimensions, followed by isotonic regression calibration to match expert panel distributions.
If this is right
- The LLM jury can flag ward diagnoses at high risk of error for prioritized expert review, increasing panel efficiency.
- Uncalibrated LLM scores are systematically lower than clinician scores but preserve ordinal agreement and rankings.
- The jury exhibits no self-preference bias, scoring own-model or same-vendor diagnoses neither higher nor lower than others.
- Post-hoc calibration via isotonic regression measurably improves alignment with primary expert panel evaluations.
Where Pith is reading between the lines
- This proxy could cut the cost and turnaround time of medical AI benchmarking, allowing evaluation on much larger case sets than 300.
- The method might extend to ongoing quality monitoring inside deployed clinical AI systems rather than only offline benchmarking.
- Generalization to high-income country cases or different medical specialties remains untested and would need direct verification.
Load-bearing premise
The primary expert clinician panels represent an unbiased and sufficiently accurate ground truth, and the 300 middle-income country cases are representative enough for broader conclusions.
What would settle it
An independent replication on a new set of cases where the calibrated LLM jury's severe error rate exceeds that of human re-scoring panels or its agreement with a fresh expert panel falls below the reported levels.
Figures






read the original abstract
Evaluating medical AI systems using expert clinician panels is costly and slow, motivating the use of large language models (LLMs) as alternative adjudicators. Here, we evaluate an LLM jury composed of three frontier AI models scoring 3333 diagnoses on 300 real-world middle-income country (MIC) hospital cases. Model performance was benchmarked against expert clinician panel and independent human re-scoring panel evaluations. Both LLM and clinician-generated diagnoses are scored across four dimensions: diagnosis, differential diagnosis, clinical reasoning and negative treatment risk. For each of these, we assess scoring difference, inter-rater agreement, scoring stability, severe safety errors and the effect of post-hoc calibration. We find that: (i) the uncalibrated LLM jury scores are systematically lower than clinician panels scores; (ii) the LLM Jury preserves ordinal agreement and exhibits better concordance with the primary expert panels than the human expert re-score panels do; (iii) the probability of severe errors is lower in \lj models compared to the human expert re-score panels; (iv) the LLM Jury shows excellent agreement with primary expert panels' rankings. We find that the LLM jury combined with AI model diagnoses can be used to identify ward diagnoses at high risk of error, enabling targeted expert review and improved panel efficiency; (v) LLM jury models show no self-preference bias. They did not score diagnoses generated by their own underlying model or models from the same vendor more (or less) favourably than those generated by other models. Finally, we demonstrate that LLM jury calibration using isotonic regression improves alignment with human expert panel evaluations. Together, these results provide compelling evidence that a calibrated, multi-model LLM jury can serve as a trustworthy and reliable proxy for expert clinician evaluation in medical AI benchmarking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates an LLM jury of three frontier models scoring 3333 diagnoses across 300 real-world middle-income country hospital cases on four dimensions (diagnosis, differential diagnosis, clinical reasoning, negative treatment risk). Performance is benchmarked against primary expert clinician panels and independent human re-scoring panels using metrics of scoring difference, inter-rater agreement, stability, severe safety errors, and post-hoc calibration effects. Key findings are that uncalibrated LLM scores are systematically lower, the LLM jury shows better concordance with primaries than re-score panels, lower severe error rates than re-scores, excellent ranking agreement, no self-preference bias, and improved alignment after isotonic regression calibration. The authors conclude that a calibrated multi-model LLM jury can serve as a reliable proxy for expert clinician evaluation in medical AI benchmarking.
Significance. If the results hold under scrutiny, the work has substantial significance for medical AI benchmarking by offering a scalable, lower-cost alternative to expert panels. Strengths include the use of real clinical cases, a multi-model jury to mitigate single-model bias, explicit testing for self-preference, and the practical demonstration of using LLM scores to flag high-risk diagnoses for targeted review. The empirical head-to-head comparison with quantitative outcomes on agreement, errors, and calibration effects provides concrete data that could inform more efficient evaluation pipelines.
major comments (2)
- [Abstract] Abstract: The central claim that the LLM jury provides a trustworthy proxy for expert evaluation rests on primary clinician panels serving as a stable, unbiased ground truth. However, the reported result that the LLM jury exhibits better concordance with the primary panels than the independent human re-score panels do directly implies substantial inter-panel variability on the same cases. This variability (common in clinical judgment) undermines the reference standard without external anchors such as patient outcomes or additional blinded expert validation, risking that high LLM agreement reflects noise in the primaries rather than true reliability.
- [Results] Results (quantitative outcomes on agreement and errors): The abstract reports concrete metrics on concordance, severe error rates, and calibration effects, but without explicit details on primary panel inter-rater reliability statistics, data exclusion rules, or raw score distributions, it is not possible to rule out that post-hoc choices inflate the apparent superiority of the LLM jury over re-score panels.
minor comments (2)
- [Abstract] Abstract: The term 'MIC' is introduced without expansion on first use, which reduces accessibility for readers outside the medical domain.
- The manuscript would benefit from a summary table in the results section comparing key metrics (e.g., agreement coefficients, error probabilities) across LLM jury, primary panels, and re-score panels for direct visual comparison.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. The concerns about the stability of primary panels as ground truth and the need for greater transparency in quantitative reporting are well-taken. We address each major comment below, indicating revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the LLM jury provides a trustworthy proxy for expert evaluation rests on primary clinician panels serving as a stable, unbiased ground truth. However, the reported result that the LLM jury exhibits better concordance with the primary panels than the independent human re-score panels do directly implies substantial inter-panel variability on the same cases. This variability (common in clinical judgment) undermines the reference standard without external anchors such as patient outcomes or additional blinded expert validation, risking that high LLM agreement reflects noise in the primaries rather than true reliability.
Authors: We agree that the lower concordance between primary and re-score panels highlights known inter-panel variability in clinical judgment. The primary panels remain our reference standard because they performed the original evaluations with full clinical context and case discussion. The LLM jury's higher alignment with primaries (versus re-scores) indicates it better captures the primary panels' assessment patterns rather than simply echoing noise. We do not have patient outcome data available in this retrospective dataset for external anchoring, which is a genuine limitation. In revision we will add an explicit discussion of inter-panel variability, its implications for interpreting LLM performance, and quantitative inter-rater reliability metrics for the primary panels to contextualize the results. revision: partial
-
Referee: [Results] Results (quantitative outcomes on agreement and errors): The abstract reports concrete metrics on concordance, severe error rates, and calibration effects, but without explicit details on primary panel inter-rater reliability statistics, data exclusion rules, or raw score distributions, it is not possible to rule out that post-hoc choices inflate the apparent superiority of the LLM jury over re-score panels.
Authors: We will revise the Results section to include the requested details: inter-rater reliability statistics for the primary panels (e.g., Fleiss' kappa or ICC across the four dimensions), explicit data exclusion rules and handling of within-panel disagreements, and summary statistics or distributions of raw scores. These additions will improve transparency and allow readers to independently assess the comparisons. revision: yes
Circularity Check
Empirical benchmarking study with no circular derivation
full rationale
The paper reports direct empirical comparisons of LLM jury scores against primary expert clinician panels and independent human re-score panels across 300 MIC cases, measuring concordance, agreement, safety errors, and post-hoc isotonic calibration effects. No mathematical derivation chain, equations, or first-principles predictions exist that reduce by construction to parameters fitted on the same evaluated data. The central claims rest on external benchmarks (expert panels) rather than self-referential definitions, self-citations, or renamed fits. This is a standard held-out empirical evaluation and is self-contained against those benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- isotonic regression mapping
axioms (1)
- domain assumption Expert clinician panels constitute an unbiased ground truth for diagnosis quality, differential quality, reasoning quality, and treatment risk.
Forward citations
Cited by 1 Pith paper
-
Evaluating Multimodal LLMs for Inpatient Diagnosis: Real-World Performance, Safety, and Cost Across Ten Frontier Models
Multimodal LLMs performed similarly across models and better than standard care on diagnostic accuracy and patient safety in a real-world LMIC hospital dataset.
Reference graph
Works this paper leans on
-
[1]
G. Williams, S. Rutunda, F. Nzabakira, and B. A. Mateen, “Human Evaluators vs. LLM-as-a-Judge: Toward Scal- able, Real-Time Evaluation of GenAI in Global Health”, medRxiv, 2025. doi: 10.1101/2025.10.27.25338910
-
[2]
HealthBench: Evaluating Large Language Models Towards Improved Human Health
R. K. Arora et al., “Healthbench: Evaluating large lan- guage models towards improved human health”, arXiv preprint arXiv:2505.08775 , 2025
work page internal anchor Pith review arXiv 2025
-
[3]
Holistic evaluation of large language mod- els for medical tasks with MedHELM
S. Bedi et al., “Holistic evaluation of large language mod- els for medical tasks with MedHELM”, Nature Medicine , pp. 1–9, 2026
2026
-
[4]
Artificial Authority: The Promise and Perils of LLM Judges in Healthcare
A. Genovese et al., “Artificial Authority: The Promise and Perils of LLM Judges in Healthcare”, Bioengineer- ing, vol. 13, no. 1, 2026, issn: 2306-5354. doi: 10 . 3390 / bioengineering13010108
2026
-
[5]
Spatialagent: An autonomous ai agent for spatial biology.bioRxiv, pages 2025–04, 2025
E. Croxford et al., “Automating Evaluation of AI Text Generation in Healthcare with a Large Language Model (LLM)-as-a-Judge”, medRxiv, 2025. doi: 10.1101/2025.04. 22.25326219
-
[6]
arXiv preprint arXiv:2411.16594 (2024) Learning in Blocks15
D. Li et al., From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge , _eprint: 2411.16594,
-
[7]
A vailable: https : / / arxiv
[Online]. A vailable: https : / / arxiv . org / abs / 2411 . 16594
-
[8]
Can large language mod- els be an alternative to human evaluations?
C.-H. Chiang and H.-y. Lee, “Can large language mod- els be an alternative to human evaluations?”, in Proceed- ings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , 2023, pp. 15 607–15 631
2023
-
[9]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
L. Zheng et al., “Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena”, in Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, _eprint: 2306.05685, 2023. [Online]. A vailable: https: //arxiv.org/abs/2306.05685
work page internal anchor Pith review arXiv 2023
-
[10]
Evaluating clinical AI summaries with large language models as judges
E. Croxford et al., “Evaluating clinical AI summaries with large language models as judges”, npj Digital Medicine , vol. 8, no. 1, p. 640, 2025
2025
-
[11]
M. L. Reese, M. Zeneli, M. Ng, J. Haimes, A. Damien, and E. Stade, “Using LLM-as-a-Judge/Jury to Advance Scal- able, Clinically-Validated Safety Evaluations of Model Re- sponses to Users Demonstrating Psychosis”, arXiv preprint arXiv:2604.02359, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
B. A. Bassett et al., Multimodal Large Language Models for Inpatient Diagnosis: A Real-World Comparative Evalu- ation, 2026
2026
-
[13]
Likert scale: Explored and explained
A. Joshi, S. Kale, S. Chandel, and D. K. Pal, “Likert scale: Explored and explained”, British journal of applied science & technology, vol. 7, no. 4, p. 396, 2015
2015
-
[14]
The proof and measurement of association between two things
C. Spearman, “The proof and measurement of association between two things”, The American journal of psychology , vol. 100, no. 3/4, pp. 441–471, 1987
1987
-
[15]
A coefficient of agreement for nominal scales
J. Cohen, “A coefficient of agreement for nominal scales”, Educational and psychological measurement , vol. 20, no. 1, pp. 37–46, 1960
1960
-
[16]
The equivalence of weighted kappa and the intraclass correlation coefficient as measures of reliability
J. L. Fleiss and J. Cohen, “The equivalence of weighted kappa and the intraclass correlation coefficient as measures of reliability”, Educational and psychological measurement , vol. 33, no. 3, pp. 613–619, 1973
1973
-
[17]
Statistical inference under order restric- tions: The theory and application of isotonic regression
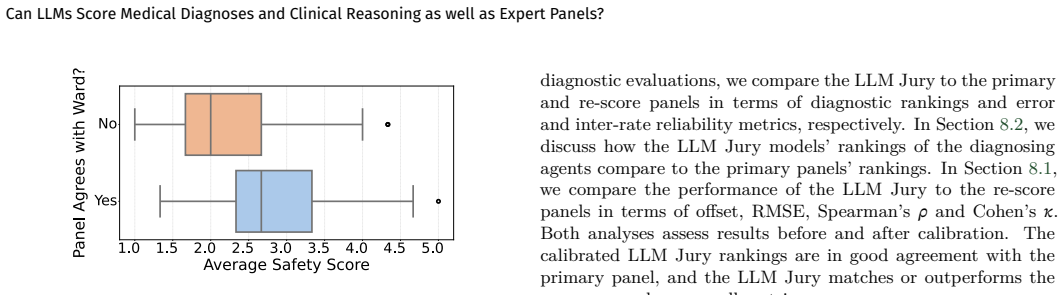
R. E. Barlow, “Statistical inference under order restric- tions: The theory and application of isotonic regression”, (No Title) , 1972. A. ADDITIONAL FIGURES AND TABLES 8–13 Can LLMs Score Medical Diagnoses and Clinical Reasoning as well as Expert Panels? Diagnostic agent Calibration Evaluation Vendor Name Primary Re-score Opus 4. 1 Gemini 2.5 Pro o3 Opus...
1972
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.