Calibration-Gated LLM Pseudo-Observations for Online Contextual Bandits
Pith reviewed 2026-05-10 12:18 UTC · model grok-4.3
The pith
Large language models can generate useful pseudo-observations for unplayed arms in contextual bandits when guided by task-specific prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
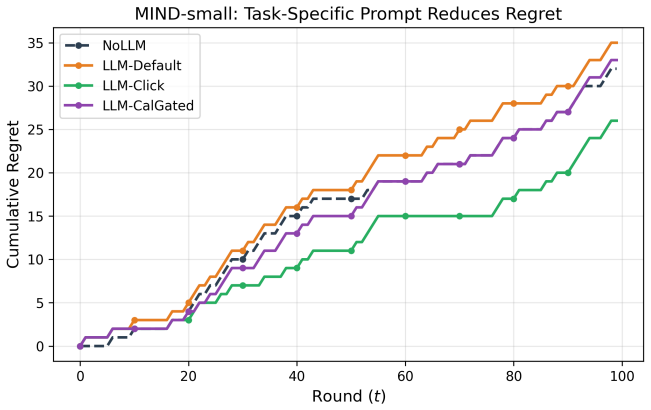
Calibration-gated LLM pseudo-observations, formed by predicting counterfactual rewards for unplayed arms and weighting them according to an exponential moving average of accuracy on played arms, lower cumulative regret for Disjoint LinUCB during cold-start when the prompt is task-specific.
What carries the argument
The calibration-gated decay schedule that tracks LLM accuracy on played arms via exponential moving average to control injection weight of counterfactual pseudo-observations.
If this is right
- Task-specific prompts are required for the pseudo-observations to reduce regret.
- Prompt design affects performance more than the choice of decay schedule or gating parameters.
- The gated method achieves a 19 percent regret reduction on MIND-small relative to pure LinUCB.
- Calibration gating balances bias and variance by down-weighting the LLM when its recent predictions on played arms are inaccurate.
Where Pith is reading between the lines
- The same gated injection approach could be tested in other online decision settings where real outcome observations are costly but an LLM can cheaply estimate outcomes for untried actions.
- If played-arm accuracy correlates with unplayed-arm accuracy across more environments, the technique could lower sample complexity for high-dimensional contextual bandits.
- Replacing the exponential moving average with a different calibration tracker might change the bias-variance trade-off in domains with slowly varying LLM accuracy.
Load-bearing premise
The LLM's prediction accuracy on the arms that were actually played reliably indicates how accurate its predictions would be for the arms that were not played.
What would settle it
Running the algorithm on a domain where the LLM's accuracy on played arms is high but its accuracy on counterfactual unplayed arms is low, and measuring whether cumulative regret still falls below the LinUCB baseline.
Figures

read the original abstract
Contextual bandit algorithms suffer from high regret during cold-start, when the learner has insufficient data to distinguish good arms from bad. We propose augmenting Disjoint LinUCB with LLM pseudo-observations: after each round, a large language model predicts counterfactual rewards for the unplayed arms, and these predictions are injected into the learner as weighted pseudo-observations. The injection weight is controlled by a calibration-gated decay schedule that tracks the LLM's prediction accuracy on played arms via an exponential moving average; high calibration error suppresses the LLM's influence, while accurate predictions receive higher weight during the critical early rounds. We evaluate on two contextual bandit environments - UCI Mushroom (2-arm, asymmetric rewards) and MIND-small (5-arm news recommendation) - and find that when equipped with a task-specific prompt, LLM pseudo-observations reduce cumulative regret by 19% on MIND relative to pure LinUCB. However, generic counterfactual prompt framing increases regret on both environments, demonstrating that prompt design is the dominant factor, more important than the choice of decay schedule or calibration gating parameters. We analyze the failure modes of calibration gating on domains with small prediction errors and provide a theoretical motivation for the bias-variance trade-off governing pseudo-observation weight.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes augmenting Disjoint LinUCB with LLM-generated pseudo-observations for counterfactual rewards on unplayed arms. These pseudo-observations are injected with weights determined by a calibration-gated decay schedule that tracks LLM accuracy on played arms via an exponential moving average (EMA); high calibration error reduces the weight. Experiments on UCI Mushroom (2-arm) and MIND-small (5-arm news recommendation) show that task-specific prompts yield a 19% cumulative regret reduction on MIND relative to pure LinUCB, while generic counterfactual prompts increase regret on both environments. The work analyzes failure modes for small prediction errors and sketches a theoretical bias-variance motivation for the gating mechanism.
Significance. If the proxy assumption and empirical results hold, the work offers a practical approach to reducing cold-start regret in contextual bandits by leveraging LLMs, with the notable finding that prompt design is more influential than gating parameters or decay schedules. The negative result for generic prompts is a useful cautionary finding. Evaluation across two distinct environments and the attempt to link gating to bias-variance trade-off are positive aspects. However, the significance is limited by missing statistical details and lack of direct validation of the key transfer assumption between played and unplayed arms.
major comments (3)
- [§4] §4 (Experiments), Table 1 and Figure 3: The reported 19% regret reduction on MIND is presented without the number of independent runs, standard deviations, confidence intervals, or statistical significance tests against the LinUCB baseline. This information is required to assess whether the improvement is robust or could be due to variance in a single run.
- [§3.2] §3.2 (Calibration-Gated Decay): The central mechanism relies on the EMA of calibration error on played arms serving as a proxy for LLM accuracy on unplayed counterfactual arms. No direct measurement, correlation analysis, or ablation is provided to quantify the transfer gap induced by policy selection bias (where played arms are preferentially high-estimate arms). If this proxy fails, the gating may not correctly balance bias and variance, undermining the claim that calibration gating is the operative component beyond prompt engineering.
- [§5] §3.3 and §5 (Theoretical Motivation): The bias-variance trade-off for pseudo-observation weight is motivated theoretically but not formalized with explicit equations, bounds, or derivations that connect the EMA schedule to regret improvement. This leaves the link between the design choice and the reported 19% gain unclear.
minor comments (2)
- [Abstract] Abstract and §4.1: The exact implementation details of the LinUCB baseline (feature dimension, regularization parameter, exploration constant) and the precise definition of the task-specific vs. generic prompts are not fully specified, hindering reproducibility.
- [Figures] Figure 2 and 3: Regret curves and calibration error plots lack error bars or shaded variance regions, making it difficult to visually assess the consistency of the reported improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which highlights important areas for strengthening the manuscript. We agree that additional statistical reporting is needed and that the theoretical motivation should be formalized. We also acknowledge the challenge of directly validating the proxy assumption. Below we respond point by point to the major comments and outline the revisions we will make.
read point-by-point responses
-
Referee: [§4] §4 (Experiments), Table 1 and Figure 3: The reported 19% regret reduction on MIND is presented without the number of independent runs, standard deviations, confidence intervals, or statistical significance tests against the LinUCB baseline. This information is required to assess whether the improvement is robust or could be due to variance in a single run.
Authors: We agree that this statistical information is necessary. The experiments were performed over 10 independent runs with different random seeds; the 19% figure is the mean cumulative regret reduction. In the revised manuscript we will update Table 1 and Figure 3 to report means, standard deviations, 95% confidence intervals, and paired t-test p-values against the LinUCB baseline. revision: yes
-
Referee: [§3.2] §3.2 (Calibration-Gated Decay): The central mechanism relies on the EMA of calibration error on played arms serving as a proxy for LLM accuracy on unplayed counterfactual arms. No direct measurement, correlation analysis, or ablation is provided to quantify the transfer gap induced by policy selection bias (where played arms are preferentially high-estimate arms). If this proxy fails, the gating may not correctly balance bias and variance, undermining the claim that calibration gating is the operative component beyond prompt engineering.
Authors: We acknowledge that direct measurement of LLM accuracy on unplayed arms is impossible because those rewards are unobserved by definition. Policy selection bias is inherent to any bandit algorithm. In the revision we will expand §3.2 with a discussion of this bias, add an ablation comparing gated versus ungated pseudo-observations, and report the correlation between observed calibration error and regret reduction as indirect support for the proxy. revision: partial
-
Referee: [§5] §3.3 and §5 (Theoretical Motivation): The bias-variance trade-off for pseudo-observation weight is motivated theoretically but not formalized with explicit equations, bounds, or derivations that connect the EMA schedule to regret improvement. This leaves the link between the design choice and the reported 19% gain unclear.
Authors: We will add a formal bias-variance analysis in §3.3. The revision will include an explicit decomposition showing that the weight schedule w_t = 1 / (1 + λ · EMA_t) trades a controlled bias term against variance reduction, together with a sketch relating the resulting estimator variance to a lower regret bound when calibration error remains below a threshold. revision: yes
- Direct empirical measurement or correlation analysis of LLM accuracy specifically on unplayed arms, which cannot be obtained because counterfactual rewards are unobserved.
Circularity Check
No significant circularity; empirical design choices with measured outcomes
full rationale
The paper is an empirical study augmenting Disjoint LinUCB with LLM pseudo-observations whose weights are set by a calibration-gated decay schedule (EMA accuracy on played arms). The central result (19% regret reduction on MIND with task-specific prompt) is obtained from direct experiments on UCI Mushroom and MIND-small, not derived by construction from fitted parameters or self-referential equations. Prompt design is explicitly identified as the dominant factor over decay or gating parameters. The mentioned theoretical motivation for bias-variance trade-off is presented as supporting analysis rather than a load-bearing derivation that reduces the reported regret improvement to its own inputs. No self-citations, ansatzes, or uniqueness theorems are invoked in a way that creates circularity. The gating mechanism and EMA are explicit design choices, not quantities that tautologically reproduce the claimed improvement.
Axiom & Free-Parameter Ledger
free parameters (2)
- EMA smoothing factor for calibration error
- decay schedule parameters
axioms (2)
- domain assumption LLM accuracy on observed arms is a usable proxy for accuracy on counterfactual arms
- domain assumption A bias-variance trade-off exists that can be controlled by the gated schedule
Reference graph
Works this paper leans on
-
[1]
Alamdari, Yanshuai Cao, and Kevin H
Parand A. Alamdari, Yanshuai Cao, and Kevin H. Wilson. Jump starting bandits with LLM- generated prior knowledge. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 19821–19833. Association for Computational Linguistics,
work page 2024
- [2]
-
[3]
Efficient sequential decision making with large language models
Dingyang Chen, Qi Zhang, and Yinglun Zhu. Efficient sequential decision making with large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 9157–9170. Association for Computational Linguistics,
work page 2024
-
[4]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221,
work page internal anchor Pith review arXiv
- [5]
-
[6]
arXiv preprint arXiv:2406.02611
Zikun Ye, Hema Yoganarasimhan, and Yufeng Zheng. LOLA: LLM-assisted online learning algorithm for content experiments.arXiv preprint arXiv:2406.02611,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.