Recognition: unknown
MambaSL: Exploring Single-Layer Mamba for Time Series Classification
Pith reviewed 2026-05-10 11:24 UTC · model grok-4.3
The pith
A minimally redesigned single-layer Mamba model outperforms 20 baselines on all 30 UEA time series classification datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MambaSL applies four TSC-specific hypotheses to minimally redesign the selective SSM block and the projection layers inside a single-layer Mamba. When evaluated against 20 strong baselines on all 30 UEA datasets under a single unified protocol, the model records the highest average accuracy with statistically significant gains and releases public checkpoints for every compared model. Visualizations further illustrate that the adapted single-layer structure functions effectively as a time series classification backbone.
What carries the argument
MambaSL, the single-layer selective state space model whose SSM and projection layers are altered according to four time series classification hypotheses.
If this is right
- Single-layer sequence models become competitive for time series classification once the selective mechanism and output projections are aligned with task demands.
- Unified protocols across the full set of UEA datasets become the minimum standard for claiming superiority among time series methods.
- Public release of trained checkpoints for every baseline allows direct verification and incremental improvement by later researchers.
- Shallow Mamba variants can serve as efficient starting points for other temporal pattern recognition tasks.
Where Pith is reading between the lines
- Similar hypothesis-driven tweaks could be tested on longer or irregularly sampled time series where computational cost grows quickly with depth.
- The selective state update in Mamba may prove especially useful for capturing class-discriminative temporal motifs without needing stacked layers.
- The approach invites direct comparison of single-layer Mamba against single-layer transformers on the same reproducible benchmark.
Load-bearing premise
The observed accuracy gains result from the four hypothesis-driven architectural changes rather than from hyperparameter choices or the particular unified protocol applied to the 30 datasets.
What would settle it
An independent run that uses the released public checkpoints but applies a different yet still unified evaluation protocol across the same 30 datasets and finds no statistically significant improvement.
Figures










read the original abstract
Despite recent advances in state space models (SSMs) such as Mamba across various sequence domains, research on their standalone capacity for time series classification (TSC) has remained limited. We propose MambaSL, a framework that minimally redesigns the selective SSM and projection layers of a single-layer Mamba, guided by four TSC-specific hypotheses. To address benchmarking limitations -- restricted configurations, partial University of East Anglia (UEA) dataset coverage, and insufficiently reproducible setups -- we re-evaluate 20 strong baselines across all 30 UEA datasets under a unified protocol. As a result, MambaSL achieves state-of-the-art performance with statistically significant average improvements, while ensuring reproducibility via public checkpoints for all evaluated models. Together with visualizations, these results demonstrate the potential of Mamba-based architectures as a TSC backbone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MambaSL, a single-layer Mamba architecture for time series classification that applies a minimal redesign to the selective SSM and projection layers guided by four TSC-specific hypotheses. To address prior benchmarking limitations, it re-evaluates 20 baselines across all 30 UEA datasets under a single unified protocol and reports state-of-the-art average performance with statistical significance, supported by public checkpoints for all models.
Significance. If the reported gains can be attributed to the architectural changes rather than protocol differences, the work would establish single-layer Mamba variants as a competitive and efficient TSC backbone, with the unified re-evaluation and public checkpoints providing a valuable reproducibility contribution to the field.
major comments (2)
- [Experiments section] The central SOTA claim (abstract and experimental results) attributes average improvements to the four TSC hypotheses' redesign of the selective SSM and projection layers, yet no ablation experiments isolate these changes from the unified protocol (e.g., fixed splits, optimizer, early stopping, or normalization). Without such controls, it is impossible to confirm that gains arise from the architecture rather than the new evaluation setup applied to baselines.
- [Methodology section] The method description states that the redesign is 'minimal' and 'guided by four TSC-specific hypotheses,' but provides no equations, pseudocode, or explicit mapping from each hypothesis to the concrete modifications in the SSM or projection layers. This omission is load-bearing for verifying the claim that the changes are both minimal and TSC-specific.
minor comments (2)
- [Abstract and Results] The abstract and results mention 'statistically significant average improvements' but do not specify the exact test (e.g., paired t-test, Wilcoxon), correction for multiple comparisons, or per-dataset breakdowns that would allow readers to assess robustness.
- [Figures] Figure captions and axis labels in the visualizations could be expanded to explicitly link observed patterns back to the four hypotheses.
Simulated Author's Rebuttal
Thank you for the detailed review. We appreciate the feedback on clarifying the contributions of our architectural redesigns and improving the methodological description. We address each major comment below.
read point-by-point responses
-
Referee: [Experiments section] The central SOTA claim (abstract and experimental results) attributes average improvements to the four TSC hypotheses' redesign of the selective SSM and projection layers, yet no ablation experiments isolate these changes from the unified protocol (e.g., fixed splits, optimizer, early stopping, or normalization). Without such controls, it is impossible to confirm that gains arise from the architecture rather than the new evaluation setup applied to baselines.
Authors: We agree that additional controls would strengthen the attribution of performance gains to the proposed redesigns. The unified protocol was introduced to enable fair and reproducible comparisons, and all baselines were re-evaluated under identical conditions. However, to directly address this concern, we will include ablation experiments in the revised manuscript. These will evaluate MambaSL variants with individual hypothesis-driven modifications disabled, all under the same unified protocol, to isolate their contributions. revision: yes
-
Referee: [Methodology section] The method description states that the redesign is 'minimal' and 'guided by four TSC-specific hypotheses,' but provides no equations, pseudocode, or explicit mapping from each hypothesis to the concrete modifications in the SSM or projection layers. This omission is load-bearing for verifying the claim that the changes are both minimal and TSC-specific.
Authors: We acknowledge that the current manuscript lacks sufficient detail in mapping the hypotheses to specific changes. In the revision, we will expand the Methodology section to include the mathematical formulations of the modified selective SSM and projection layers, pseudocode for the overall architecture, and a clear table or list explicitly linking each of the four TSC-specific hypotheses to the corresponding modifications. This will allow readers to verify the minimal and targeted nature of the redesigns. revision: yes
Circularity Check
No circularity; empirical claims rest on external benchmarks
full rationale
The manuscript contains no equations, derivations, or fitted parameters that could reduce to self-definitions or predictions by construction. The central claim is an empirical comparison of MambaSL against 20 baselines on the 30 UEA datasets under a unified protocol, supported by public checkpoints. No self-citation chains, ansatzes, or uniqueness theorems are invoked to justify the architecture or results. The four TSC hypotheses guide a minimal redesign, but this is presented as a design choice rather than a mathematical necessity that collapses into the inputs. This is the expected non-finding for an empirical architecture paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mamba selective SSM can be minimally adapted for TSC via four domain hypotheses
Reference graph
Works this paper leans on
-
[1]
TimeMachine: A time series is worth 4 mambas for long-term forecasting
Md Atik Ahamed and Qiang Cheng. TimeMachine: A time series is worth 4 mambas for long-term forecasting. InECAI 2024: 27th European Conference on Artificial Intelligence, volume 392, pp. 1688–1965,
2024
-
[2]
Anthony Bagnall, Hoang Anh Dau, Jason Lines, Michael Flynn, James Large, Aaron Bostrom, Paul Southam, and Eamonn Keogh
ISSN 2835-8856. Anthony Bagnall, Hoang Anh Dau, Jason Lines, Michael Flynn, James Large, Aaron Bostrom, Paul Southam, and Eamonn Keogh. The UEA multivariate time series classification archive, 2018,
2018
-
[3]
A., Lines, J., Flynn, M., Large, J., Bostrom, A.,
URLhttps://arxiv.org/abs/1811.00075. Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate,
-
[4]
Neural Machine Translation by Jointly Learning to Align and Translate
URLhttps://arxiv.org/abs/1409.0473. Ac- cepted at ICLR 2015 as oral presentation. Shaojie Bai, J. Zico Kolter, and Vladlen Koltun. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling,
work page internal anchor Pith review arXiv 2015
-
[5]
An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
URLhttps://arxiv.org/abs/ 1803.01271. Donald J Berndt and James Clifford. Using dynamic time warping to find patterns in time series. In Proceedings of the 3rd International Conference on Knowledge Discovery and Data Mining, pp. 359–370,
work page internal anchor Pith review arXiv
-
[6]
The UCR time series classification archive, July 2015.www.cs.ucr.edu/ ˜eamonn/time_series_data/
Yanping Chen, Eamonn Keogh, Bing Hu, Nurjahan Begum, Anthony Bagnall, Abdullah Mueen, and Gustavo Batista. The UCR time series classification archive, July 2015.www.cs.ucr.edu/ ˜eamonn/time_series_data/. Tri Dao and Albert Gu. Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality. InProceedings of the 41...
2015
-
[7]
Schmidt, and Geoffrey I
11 Published as a conference paper at ICLR 2026 Angus Dempster, Daniel F. Schmidt, and Geoffrey I. Webb. Minirocket: A very fast (almost) de- terministic transform for time series classification. InProceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining, pp. 248–257,
2026
-
[8]
InceptionTime: Finding alexnet for time series classification.Data Mining and Knowledge Discovery, 34(6):1936–1962,
Hassan Ismail Fawaz, Benjamin Lucas, Germain Forestier, Charlotte Pelletier, Daniel F Schmidt, Jonathan Weber, Geoffrey I Webb, Lhassane Idoumghar, Pierre-Alain Muller, and Franc ¸ois Petit- jean. InceptionTime: Finding alexnet for time series classification.Data Mining and Knowledge Discovery, 34(6):1936–1962,
1936
-
[9]
Residual LSTM: Design of a deep recurrent architecture for distant speech recognition
Jaeyoung Kim, Mostafa El-Khamy, and Jungwon Lee. Residual LSTM: Design of a deep recurrent architecture for distant speech recognition. InInterspeech 2017, pp. 1591–1595,
2017
-
[10]
VideoMamba: State space model for efficient video understanding
Kunchang Li, Xinhao Li, Yi Wang, Yinan He, Yali Wang, Limin Wang, and Yu Qiao. VideoMamba: State space model for efficient video understanding. InComputer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part XXVI, pp. 237–255,
2024
-
[11]
MTS-Mixer: Multivariate time series forecasting via factorized temporal and channel mixing,
12 Published as a conference paper at ICLR 2026 Zhe Li, Zhongwen Rao, Lujia Pan, and Zenglin Xu. MTS-Mixer: Multivariate time series forecasting via factorized temporal and channel mixing,
2026
-
[12]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
URLhttps://arxiv.org/abs/1802.03426. Harsh Mehta, Ankit Gupta, Ashok Cutkosky, and Behnam Neyshabur. Long range language model- ing via gated state spaces. InThe Eleventh International Conference on Learning Representations, 2023a. Harsh Mehta, Ankit Gupta, Ashok Cutkosky, and Behnam Neyshabur. Long range language model- ing via gated state spaces. InThe ...
work page internal anchor Pith review arXiv
-
[13]
k-Shape: Efficient and accurate clustering of time series
John Paparrizos and Luis Gravano. k-Shape: Efficient and accurate clustering of time series. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, pp. 1855–1870,
2015
-
[14]
MultiRocket: multiple pooling operators and transformations for fast and effective time series classification.Data Mining and Knowledge Discovery, 36:1623–1646,
13 Published as a conference paper at ICLR 2026 Chang Wei Tan, Angus Dempster, Christoph Bergmeir, and Geoffrey I Webb. MultiRocket: multiple pooling operators and transformations for fast and effective time series classification.Data Mining and Knowledge Discovery, 36:1623–1646,
2026
-
[15]
Deep Time Series Models: A Comprehensive Survey and Benchmark
Shiyu Wang, Jiawei LI, Xiaoming Shi, Zhou Ye, Baichuan Mo, Wenze Lin, Ju Shengtong, Zhixuan Chu, and Ming Jin. TimeMixer++: A general time series pattern machine for universal predictive analysis. InThe Thirteenth International Conference on Learning Representations, 2025a. Yihe Wang, Nan Huang, Taida Li, Yujun Yan, and Xiang Zhang. Medformer: A multi-gra...
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
URLhttps://arxiv.org/abs/ 2202.01381. Haixu Wu, Tengge Hu, Yong Liu, Hang Zhou, Jianmin Wang, and Mingsheng Long. TimesNet: Temporal 2d-variation modeling for general time series analysis. InThe Eleventh International Conference on Learning Representations,
-
[17]
URLhttps://arxiv. org/abs/2207.01186. Yunhao Zhang and Junchi Yan. Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting. InThe Eleventh International Conference on Learning Representations,
-
[18]
Most were run on NVIDIA GTX 1080 Ti (11GB), while a few required NVIDIA A100 (40GB) on Google Colab due to memory limits
14 Published as a conference paper at ICLR 2026 A EXPERIMENTAL SETUP EnvironmentAll experiments were implemented in Python 3.12.8 and PyTorch 2.5.1. Most were run on NVIDIA GTX 1080 Ti (11GB), while a few required NVIDIA A100 (40GB) on Google Colab due to memory limits. Classical baselines used theaeontoolkit (Middlehurst et al., 2024), and all deep model...
2026
-
[19]
AsTSLibhas become a widely used framework, a subset of 10 datasets (EC,FD,HW,HB,JV,PEMS,SRS1,SRS2,SAD, andUW) is commonly used in recent TSC benchmarking practices
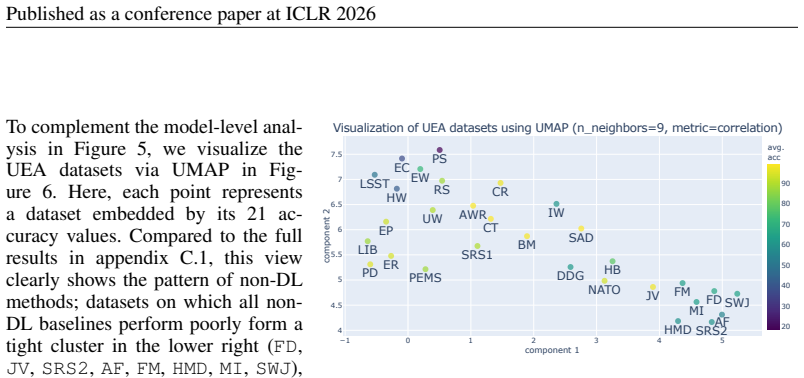
provides 30 multivariate TSC datasets with di- verse sample sizes, input dimensions, lengths, and class counts (Table 4). AsTSLibhas become a widely used framework, a subset of 10 datasets (EC,FD,HW,HB,JV,PEMS,SRS1,SRS2,SAD, andUW) is commonly used in recent TSC benchmarking practices. Table 4: Summary of the 30 UEA datasets used in our experiments Datase...
1945
-
[20]
•Train epochs: 100 •Patience: 10 •Dropout: 0.1 •Seed: 2021 (for DL models) Although this unified setting may deviate from model-specific defaults, extensive model-level grid searches compensated for potential performance degradation (see appendix C.3). B.2 MODEL HYPERPARAMETER SETTINGS FOR GRID SEARCH We primarily considered the hyperparameter settings th...
2021
-
[21]
1”, “13”, “5
–MTS-Mixer: 256 combinations * e layers: 2 * d model: 128, 256, 512, 1024 * d ff: 0, 2, 4, 8, 16, 32, 64, 128 * fac C: 0 (False) ifd ffis 0, else 1 (True) * down sampling window: 0, 1%, 2%, 3%, 5%, 7.5%, 10%, 12.5% of sequence length * fac T: 0 (False) ifdown sampling windowis 0, else 1 (True) * use norm: 1 (True) 16 Published as a conference paper at ICL...
2026
-
[22]
Also, note that only one hyperparameter combination was tested in our limited resource environment for TSCMamba (Ahamed & Cheng, 2025)–IWpair, since preprocessing took over 2 days and training took over 12 hours per epoch. Table 5: Classification accuracy (%) of TSC models on 30 datasets from the UEA archives. The best and the second-best are highlighted ...
-
[23]
For a clear comparison, we also performed the hyperparameter grid search for each ablated model. Model rankings were com- puted within the ablated variants, while additional experimental results are included for reference. Since removing H2 reduces the number of valid hyperparameter configurations to one-eighth, we extended the search space of Mamba’s hyp...
-
[24]
report≥ours
were used. Note that we approximated the reported values using the number of test samples since they were typically rounded to one or two decimal places. The metrics used in Table 7 are as follows: •report≤ours:Count of datasets on which our experimental results of grid search achieved higher or equal accuracy compared to the reported results. A value hig...
1994
-
[25]
Although using three layers yielded the highest average accuracy on the 10 datasets commonly evaluated inTSLib, this observation does not hold when extended to the full set of 30 UEA datasets. When examining the av- erage rank on these 10 datasets, we find that the single-layer configuration consistently outperforms the multi-layer variants, indicating th...
-
[26]
In contrast to Table 9, where HC2 and Hydra showed the strongest performance based on the best- performing trial, averaging across all trials indicates that MR+Hydra achieves the strongest mean performance and exhibits more consistent results. Nevertheless, MambaSL remains competitive, outperforming all conventional non-DL baselines in direct head-to-head...
2020
-
[27]
Table 11: Summary of ADFTD and FLAAP datasets Dataset Domain Samples Length Variables Classes File Size ADFTD (2023) EEG 69752 256 3 19 2.52GB FLAAP (2022) HAR 13123 100 10 6 60.2MB Preprocessing and experimental settings were aligned with the official Medformer implementation. We first evaluated MambaSL using the 240 hyperparameter configurations employe...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.