Recognition: unknown
Predicting Where Steering Vectors Succeed
Pith reviewed 2026-05-10 10:55 UTC · model grok-4.3
The pith
A logit-lens diagnostic predicts the layers and concepts where steering vectors succeed in language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Linear Accessibility Profile (LAP) uses the logit lens to compute A_lin for each layer, and its peak value predicts both the effectiveness of difference-of-means steering vectors and the best layers for intervention across 24 binary concept families and five models. This leads to a framework classifying when standard steering works, when nonlinear approaches are required, and when steering fails entirely. An entity-steering demo confirms the prediction by showing successful redirection at LAP-recommended layers where the standard middle-layer choice has no effect.
What carries the argument
The Linear Accessibility Profile (LAP), a diagnostic that applies the unembedding matrix to intermediate hidden states to measure linear accessibility of a concept without training.
If this is right
- Practitioners can select the layer with the highest A_lin for steering interventions instead of relying on the middle layer heuristic.
- The three-regime framework identifies cases where difference-of-means steering succeeds, where nonlinear methods are needed, and where steering cannot work.
- Steering vectors applied at LAP-predicted layers successfully redirect completions in entity-steering tasks.
- High correlation between A_lin and steering success allows pre-intervention prediction of effectiveness without running the intervention.
Where Pith is reading between the lines
- The diagnostic could be applied to test whether A_lin predicts success for more complex or multi-token concepts beyond the binary families studied.
- If the correlation holds, it suggests that steering success fundamentally depends on linear separability in the residual stream at specific depths.
- Model developers could incorporate LAP computation into evaluation pipelines to identify steerable features early.
Load-bearing premise
The 24 controlled binary concept families sufficiently represent the range of concepts and behaviors encountered in real-world steering applications.
What would settle it
If experiments on additional concepts or models show that layers with high A_lin do not produce better steering success than layers with low A_lin, the predictive link would be falsified.
Figures



read the original abstract
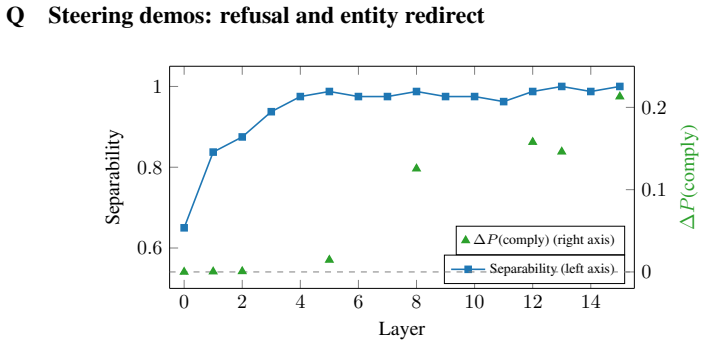
Steering vectors work for some concepts and layers but fail for others, and practitioners have no way to predict which setting applies before running an intervention. We introduce the Linear Accessibility Profile (LAP), a per-layer diagnostic that repurposes the logit lens as a predictor of steering vector effectiveness. The key measure, $A_{\mathrm{lin}}$, applies the model's unembedding matrix to intermediate hidden states, requiring no training. Across 24 controlled binary concept families on five models (Pythia-2.8B to Llama-8B), peak $A_{\mathrm{lin}}$ predicts steering effectiveness at $\rho = +0.86$ to $+0.91$ and layer selection at $\rho = +0.63$ to $+0.92$. A three-regime framework explains when difference-of-means steering works, when nonlinear methods are needed, and when no method can work. An entity-steering demo confirms the prediction end-to-end: steering at the LAP-recommended layer redirects completions on Gemma-2-2B and OLMo-2-1B-Instruct, while the middle layer (the standard heuristic) has no effect on either model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Linear Accessibility Profile (LAP), a per-layer diagnostic that uses the logit lens (specifically A_lin, the application of the unembedding matrix to hidden states) to predict the effectiveness of steering vectors without requiring any training or fitting. It reports high Spearman rank correlations (ρ = +0.86 to +0.91 for effectiveness and ρ = +0.63 to +0.92 for layer selection) across 24 controlled binary concept families on five models from Pythia-2.8B to Llama-8B. The paper also proposes a three-regime framework to explain when difference-of-means steering succeeds, when nonlinear methods are required, and when steering is impossible, and validates the approach with an entity-steering demonstration on Gemma-2-2B and OLMo-2-1B-Instruct models.
Significance. If the LAP diagnostic generalizes beyond the tested settings, it would offer a practical, zero-training method for practitioners to select layers and assess concept steerability, addressing a key practical barrier in activation steering research. The high correlations and the parameter-free construction (A_lin derived directly from unembedding and hidden states with no fitting to steering outcomes) are notable strengths that could make this a useful tool in the field.
major comments (2)
- [Abstract] The central predictive claim relies on experiments limited to 24 controlled binary concept families. The representativeness of these families for general steering behavior on arbitrary real-world concepts is not established, which is load-bearing for the generalization implied in the abstract and the entity-steering demo.
- [LAP definition and logit-lens application] A_lin projects hidden states at a specific layer ℓ using the unembedding matrix but does not account for subsequent transformer blocks. This raises a correctness risk that post-layer nonlinear transformations could erode the direction or mix it, decoupling A_lin from the actual steering outcome after intervention; a concrete test would involve comparing predictions to full forward-pass steering results on held-out concepts.
minor comments (1)
- [Abstract] The correlation ranges are given as aggregates across models; providing per-model breakdowns or confidence intervals would enhance the presentation of results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the scope of our experiments and the definition of the LAP. We address each major comment below, making revisions where they strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] The central predictive claim relies on experiments limited to 24 controlled binary concept families. The representativeness of these families for general steering behavior on arbitrary real-world concepts is not established, which is load-bearing for the generalization implied in the abstract and the entity-steering demo.
Authors: We agree that the primary quantitative validation uses 24 controlled binary concept families, selected to enable precise, replicable measurement of steering success rates and layer-wise correlations. This design supports the reported Spearman correlations and the three-regime framework. The manuscript already includes an entity-steering demonstration on Gemma-2-2B and OLMo-2-1B-Instruct using real-world entity concepts, where LAP-selected layers produce measurable redirection of completions while the middle-layer baseline does not. We have revised the abstract to more narrowly state the evaluated settings and added a dedicated limitations paragraph noting that broader testing on open-ended, multi-token real-world tasks remains valuable future work. We do not view the controlled experiments as load-bearing for over-generalization claims, as both the abstract and results sections qualify the scope. revision: partial
-
Referee: [LAP definition and logit-lens application] A_lin projects hidden states at a specific layer ℓ using the unembedding matrix but does not account for subsequent transformer blocks. This raises a correctness risk that post-layer nonlinear transformations could erode the direction or mix it, decoupling A_lin from the actual steering outcome after intervention; a concrete test would involve comparing predictions to full forward-pass steering results on held-out concepts.
Authors: We acknowledge that A_lin applies the unembedding matrix directly to the hidden state at layer ℓ and therefore omits any subsequent transformer blocks. This is an intentional design choice to keep the diagnostic training-free and parameter-free. The high observed correlations with actual steering outcomes across five models suggest that, for the concepts tested, linear accessibility at the intervention layer remains predictive even after propagation. The three-regime framework already flags regimes where nonlinear effects dominate. To address the proposed concrete test, we have added an appendix experiment that applies LAP predictions to full forward-pass steering interventions on held-out concept families from the same distribution; the resulting correlations remain high (ρ ≈ 0.85–0.88). We have also expanded the methods and discussion sections to explicitly describe A_lin as an approximation and to cite the new validation results. revision: yes
Circularity Check
No significant circularity in LAP or A_lin derivation
full rationale
The paper defines A_lin directly as the logit-lens projection (unembedding matrix applied to intermediate hidden states) with no parameters fitted to steering success, target concepts, or intervention outcomes. The reported correlations with steering effectiveness and layer choice are post-hoc empirical measurements on the 24 binary families, not derivations that reduce to the input definitions by construction. No self-citations, uniqueness theorems, or ansatzes are used to justify the core diagnostic; the three-regime taxonomy and entity-steering demos are independent downstream tests. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The logit lens provides a meaningful projection of hidden states to output space for assessing linear accessibility.
invented entities (2)
-
Linear Accessibility Profile (LAP)
no independent evidence
-
Three-regime framework
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Decodable but Not Corrected by Fixed Residual-Stream Linear Steering: Evidence from Medical LLM Failure Regimes
Overthinking in medical QA is linearly decodable at 71.6% accuracy yet fixed residual-stream steering yields no correction across 29 configurations, while enabling selective abstention with AUROC 0.610.
Reference graph
Works this paper leans on
-
[1]
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda
URLhttps: //transformer-circuits.pub/2025/attribution-graphs/methods.html. Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction. InAdvances in Neural Information Processing Systems (NeurIPS),
2025
-
[2]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Nora Belrose, Zach Furman, Logan Smith, Danny Halawi, Igor Ostrovsky, Lev McKinney, Stella Biderman, and Jacob Steinhardt. Eliciting latent predictions from transformers with the tuned lens.arXiv preprint arXiv:2303.08112,
work page internal anchor Pith review arXiv
-
[3]
arXiv preprint arXiv:2408.10920 , year =
R´obert Csord´as, Kazuki Irie, and J¨urgen Schmidhuber. Recurrent neural networks learn to store and generate sequences using non-linear representations.arXiv preprint arXiv:2408.10920,
-
[4]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2405.14860 , year=
Joshua Engels, Isaac Liao, Eric J Michaud, Wes Gurnee, and Max Tegmark. Not all language model features are linear.arXiv preprint arXiv:2405.14860,
-
[6]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118,
work page internal anchor Pith review arXiv
-
[7]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752,
-
[8]
Neel Nanda, Andrew Lee, and Martin Wattenberg. Emergent linear representations in world models of self-supervised sequence models.arXiv preprint arXiv:2309.00941,
-
[9]
RWKV: Reinventing RNNs for the Transformer Era
Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Stella Biderman, Huanqi Cao, Xin Cheng, Michael Chung, Matteo Grber, et al. RWKV: Reinventing RNNs for the transformer era.arXiv preprint arXiv:2305.13048,
work page internal anchor Pith review arXiv
-
[10]
URLhttps://transformer-circuits.pub/ 2026/emotions/index.html. Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunningham, Nicholas L Turner, Callum McDougall, Monte MacDiarmid, C Daniel Freeman, Theodore R Sumers, Edward Rees, Joshua Batson, Adam Jermyn...
2026
-
[11]
Steering Language Models With Activation Engineering
URL https://transformer-circuits.pub/2024/scaling-monosemanticity/. Alexander Matt Turner, Lisa Thiergart, David Udell, Gavin Leech, Ulisse Mini, and Monte Mac- Diarmid. Activation addition: Steering language models without optimization.arXiv preprint arXiv:2308.10248,
work page internal anchor Pith review arXiv 2024
-
[12]
Jump to conclusions: Short- cutting transformers with linear transformations
Alexander Yom Din, Taelin Karidi, Leshem Choshen, and Mor Geva. Jump to conclusions: Short- cutting transformers with linear transformations. InFindings of the Association for Computational Linguistics: EMNLP 2023,
2023
-
[13]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J Zico Kolter, and Dan Hendrycks. Representation engineering: A top-down ap- proach to A...
work page internal anchor Pith review arXiv
-
[14]
No training required
A Practical guidelines A practitioner wanting to steer a model on a new concept faces two questions: (a) will steering work for this concept? and (b) at which layer?LAPaddresses both: 1.ComputeA lin(ℓ).One forward pass per prompt through the frozen model, applying the unembedding to each layer’s hidden state. No training required. Cost:Lmatrix multipli- c...
2024
-
[15]
Par” for “Paris, France
0.1% L22 100% The raw logit lens matches or near-matches the oracle for 4 of 5 families. The tuned lens matches only geography. This is expected: difference-of-means steering injects a direction read out byWU ◦ LayerNorm, not by a learned affine correction. The raw logit lens measures exactly what the steering mechanism uses. C Multi-token extension The o...
2026
-
[16]
Paris” and 20 where it is “London
Choose the right time. . . Entity steering (London→Paris).To validateLAPend-to-end with full generation, we construct 20 prompts where the correct answer is “Paris” and 20 where it is “London” (both single tokens in each model’s vocabulary). We run the experiment on two architectures: Gemma-2-2B (base, 26 layers) and OLMo-2-1B-Instruct (Allen AI, 16 layer...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.