Recognition: unknown
The Metacognitive Monitoring Battery: A Cross-Domain Benchmark for LLM Self-Monitoring
Pith reviewed 2026-05-10 08:49 UTC · model grok-4.3
The pith
A new cross-domain battery shows that frontier LLMs display three metacognitive profiles matching human patterns: blanket confidence, blanket withdrawal, or selective sensitivity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
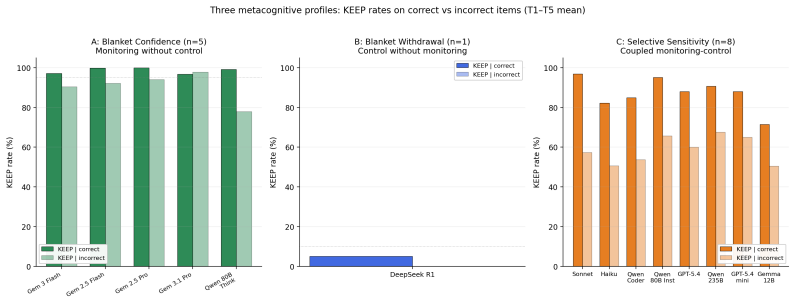
The central claim is that the Metacognitive Monitoring Battery, using a withdraw delta metric from dual KEEP/WITHDRAW and BET probes across 524 items in six domains, applied to 20 frontier LLMs, discriminates three profiles consistent with the Nelson-Narens architecture: blanket confidence, blanket withdrawal, and selective sensitivity. Accuracy rank and metacognitive sensitivity rank are largely inverted, retrospective monitoring and prospective regulation appear dissociable with low correlation, and scaling on metacognitive calibration varies by architecture while converging with an independent signal detection approach.
What carries the argument
The withdraw delta metric, calculated as the difference in withdrawal rate between incorrect and correct items, which quantifies selective monitoring-control coupling.
Load-bearing premise
The assumption that the adapted KEEP/WITHDRAW and BET probes, along with the withdraw delta, measure genuine metacognitive monitoring and control in LLMs rather than surface-level patterns from training.
What would settle it
If new LLMs produce the same three profiles and inverted accuracy-sensitivity ranks even after training data is filtered to remove any metacognition-related examples, or if all profiles collapse under neutral prompting, the validity of the discrimination would be challenged.
Figures


read the original abstract
We introduce a cross-domain behavioural assay of monitoring-control coupling in LLMs, grounded in the Nelson and Narens (1990) metacognitive framework and applying human psychometric methodology to LLM evaluation. The battery comprises 524 items across six cognitive domains (learning, metacognitive calibration, social cognition, attention, executive function, prospective regulation), each grounded in an established experimental paradigm. Tasks T1-T5 were pre-registered on OSF prior to data collection; T6 was added as an exploratory extension. After every forced-choice response, dual probes adapted from Koriat and Goldsmith (1996) ask the model to KEEP or WITHDRAW its answer and to BET or decline. The critical metric is the withdraw delta: the difference in withdrawal rate between incorrect and correct items. Applied to 20 frontier LLMs (10,480 evaluations), the battery discriminates three profiles consistent with the Nelson-Narens architecture: blanket confidence, blanket withdrawal, and selective sensitivity. Accuracy rank and metacognitive sensitivity rank are largely inverted. Retrospective monitoring and prospective regulation appear dissociable (r = .17, 95% CI wide given n=20; exemplar-based evidence is the primary support). Scaling on metacognitive calibration is architecture-dependent: monotonically decreasing (Qwen), monotonically increasing (GPT-5.4), or flat (Gemma). Behavioural findings converge structurally with an independent Type-2 SDT approach, providing preliminary cross-method construct validity. All items, data, and code: https://github.com/synthiumjp/metacognitive-monitoring-battery.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
No significant circularity; empirical benchmark with external grounding
full rationale
The paper reports results from a new behavioral battery applied to 20 LLMs, yielding empirical profiles, rank inversions, and a correlation (r=.17) between monitoring and regulation. The withdraw delta and KEEP/WITHDRAW+BET probes are defined directly from response data without any fitted parameters or equations that reduce the reported outcomes to quantities defined by the paper's own inputs. The Nelson-Narens framework is cited as external grounding rather than derived internally. No self-citation chains, uniqueness theorems, or ansatzes are invoked to force the central claims. All findings are data-driven observations against an independent psychological architecture, with no reduction of predictions to fitted inputs or self-definitional loops.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Nelson and Narens (1990) metacognitive framework and associated experimental paradigms can be directly applied to evaluate monitoring-control coupling in LLMs.
Forward citations
Cited by 4 Pith papers
-
The Compliance Trap: How Structural Constraints Degrade Frontier AI Metacognition Under Adversarial Pressure
Eight of eleven frontier models show up to 30 percentage point metacognitive accuracy drops under compliance-forcing instructions rather than threat content, with Constitutional AI showing near-immunity due to its ali...
-
Before You Interpret the Profile: Validity Scaling for LLM Metacognitive Self-Report
Validity indices adapted from clinical assessment classify four frontier LLMs as construct-level invalid on metacognitive probes, with valid models showing positive item-sensitive confidence (r=.18) while invalid ones...
-
The Compliance Trap: How Structural Constraints Degrade Frontier AI Metacognition Under Adversarial Pressure
Compliance-forcing instructions cause up to 30 percentage point drops in metacognitive accuracy across most frontier models, while removing the compliance element restores performance and Constitutional AI shows near-...
-
Verbal Confidence Saturation in 3-9B Open-Weight Instruction-Tuned LLMs: A Pre-Registered Psychometric Validity Screen
Seven 3-9B instruction-tuned LLMs produce verbal confidence that saturates at high values and fails psychometric validity criteria for Type-2 discrimination under minimal elicitation.
Reference graph
Works this paper leans on
-
[1]
Ackerman, C. (2025). Evidence for limited metacognition in LLMs.arXiv:2509.21545. Published as ICLR 2026 conference paper. Cacioli, J. P. (2026a). LLMs as signal detectors.arXiv:2603.14893. Cacioli, J. P. (2026b). Do LLMs know what they know?arXiv:2603.25112. Cacioli, J. P. (2026c). Exemplar retrieval without overhypothesis induction in large language mod...
-
[2]
Language Models (Mostly) Know What They Know
Fleming, S. M., Ryu, J., Golfinos, J. G., & Blackmon, K. E. (2014). Domain-specific impairment in metacognitive accuracy following anterior prefrontal lesions.Brain, 137, 2811–2822. Green, D. M., & Swets, J. A. (1966).Signal detection theory and psychophysics.Wiley. Hendrycks, D., et al. (2021). Measuring massive multitask language understanding. InProcee...
work page internal anchor Pith review arXiv 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.