Recognition: unknown
TTL: Test-time Textual Learning for OOD Detection with Pretrained Vision-Language Models
Pith reviewed 2026-05-10 08:44 UTC · model grok-4.3
The pith
TTL dynamically learns OOD textual semantics from unlabeled test streams via prompt updates, purification, and a knowledge bank to improve detection performance in pretrained VLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TTL consistently achieves state-of-the-art performance, highlighting the value of textual adaptation for robust test-time OOD detection.
Load-bearing premise
That pseudo-labeled test samples can be sufficiently purified to provide reliable updates to learnable prompts without introducing harmful noise, and that emerging OOD semantics can be effectively captured through prompt-based textual learning from unlabeled streams.
Figures




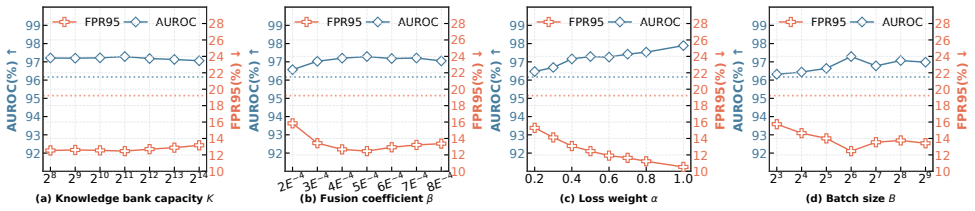


read the original abstract
Vision-language models (VLMs) such as CLIP exhibit strong Out-of-distribution (OOD) detection capabilities by aligning visual and textual representations. Recent CLIP-based test-time adaptation methods further improve detection performance by incorporating external OOD labels. However, such labels are finite and fixed, while the real OOD semantic space is inherently open-ended. Consequently, fixed labels fail to represent the diverse and evolving OOD semantics encountered in test streams. To address this limitation, we introduce Test-time Textual Learning (TTL), a framework that dynamically learns OOD textual semantics from unlabeled test streams, without relying on external OOD labels. TTL updates learnable prompts using pseudo-labeled test samples to capture emerging OOD knowledge. To suppress noise introduced by pseudo-labels, we introduce an OOD knowledge purification strategy that selects reliable OOD samples for adaptation while suppressing noise. In addition, TTL maintains an OOD Textual Knowledge Bank that stores high-quality textual features, providing stable score calibration across batches. Extensive experiments on two standard benchmarks with nine OOD datasets demonstrate that TTL consistently achieves state-of-the-art performance, highlighting the value of textual adaptation for robust test-time OOD detection. Our code is available at https://github.com/figec/TTL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TTL, a test-time textual learning framework for OOD detection using pretrained vision-language models. It updates learnable prompts with pseudo-labeled test samples from unlabeled streams, employs an OOD knowledge purification strategy to select reliable samples and reduce noise, and uses a Textual Knowledge Bank for calibration. It reports state-of-the-art results on two benchmarks involving nine OOD datasets, without using external OOD labels.
Significance. If the central claims are supported by the full experiments, this would represent a meaningful advance in handling open-ended OOD semantics through test-time textual adaptation. The approach's strength lies in its dynamic learning from test data, and code availability aids reproducibility.
major comments (2)
- [Abstract] The purification strategy is described as selecting 'reliable OOD samples' to suppress noise, but without specific criteria or validation (e.g., accuracy of selection or impact on prompt updates), it is unclear if it adequately addresses the risk of noise injection when OOD semantics are evolving and open-ended.
- [Method] The claim that the Textual Knowledge Bank provides stable score calibration across batches is central, yet the abstract does not detail how features are stored or retrieved, raising questions about its implementation and effectiveness.
minor comments (1)
- [Abstract] The specific benchmarks and OOD datasets used are not named, which would help contextualize the SOTA claims.
Simulated Author's Rebuttal
We are grateful to the referee for their detailed and constructive feedback on our paper. We have addressed the major comments point-by-point below, making revisions to enhance the clarity of the abstract and method descriptions where needed.
read point-by-point responses
-
Referee: [Abstract] The purification strategy is described as selecting 'reliable OOD samples' to suppress noise, but without specific criteria or validation (e.g., accuracy of selection or impact on prompt updates), it is unclear if it adequately addresses the risk of noise injection when OOD semantics are evolving and open-ended.
Authors: We thank the referee for raising this important point regarding the purification strategy. In the manuscript, the OOD knowledge purification strategy is detailed in the Method section, where reliable OOD samples are selected using a combination of prediction confidence and consistency with the evolving textual knowledge to reduce noise from pseudo-labels in open-ended settings. We acknowledge that the abstract could more explicitly state these criteria. Accordingly, we have revised the abstract to include a brief description of the selection mechanism and its role in suppressing noise. This revision should clarify how the approach handles the risks associated with evolving OOD semantics. revision: partial
-
Referee: [Method] The claim that the Textual Knowledge Bank provides stable score calibration across batches is central, yet the abstract does not detail how features are stored or retrieved, raising questions about its implementation and effectiveness.
Authors: We appreciate the referee's comment on the Textual Knowledge Bank. The details of how features are stored (as a bank of high-quality textual embeddings from purified samples) and retrieved (via similarity search for calibration) are provided in the Method section. The abstract summarizes this as providing stable score calibration across batches. To address the concern about implementation details in the abstract, we have updated the abstract to briefly explain the storage and retrieval process. We believe the existing experiments and ablations in the paper support its effectiveness, but the added abstract text improves accessibility. revision: partial
Circularity Check
No significant circularity; method is self-contained algorithmic proposal
full rationale
The paper introduces TTL as a new test-time adaptation framework that learns OOD textual semantics from unlabeled streams via pseudo-labeling, purification, and a knowledge bank. No equations, derivations, or self-referential definitions appear in the abstract or description that reduce any prediction or result to fitted inputs by construction. The approach builds on external pretrained VLMs (CLIP) with novel steps for prompt updating and calibration; claims rest on experimental benchmarks rather than self-citation chains or imported uniqueness theorems. This is the common case of an honest empirical method paper with no load-bearing circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Negrefine: Refining negative label-based zero-shot ood detection
Amirhossein Ansari, Ke Wang, and Pulei Xiong. Negrefine: Refining negative label-based zero-shot ood detection. In ICCV, 2025. 2, 5, 6
2025
-
[2]
Id-like prompt learning for few-shot out-of-distribution detection
Yichen Bai, Zongbo Han, Bing Cao, Xiaoheng Jiang, Qinghua Hu, and Changqing Zhang. Id-like prompt learning for few-shot out-of-distribution detection. InCVPR, 2024. 2, 3, 5, 6
2024
-
[3]
In or out? fixing imagenet out-of-distribution detection eval- uation
Julian Bitterwolf, Maximilian Mueller, and Matthias Hein. In or out? fixing imagenet out-of-distribution detection eval- uation. InICML, 2023. 2
2023
-
[4]
Improving information retention in large scale online continual learning
Zhipeng Cai, Vladlen Koltun, and Ozan Sener. Improving information retention in large scale online continual learning. CoRR, abs/2210.06401, 2022. 7
-
[5]
Noisy test-time adap- tation in vision-language models
Chentao Cao, Zhun Zhong, Zhanke Zhou, Tongliang Liu, Yang Liu, Kun Zhang, and Bo Han. Noisy test-time adap- tation in vision-language models. InICLR, 2025. 2, 4, 5, 6
2025
-
[6]
Fodfom: Fake outlier data by founda- tion models creates stronger visual out-of-distribution detec- tor
Jiankang Chen, Ling Deng, Zhiyong Gan, Wei-Shi Zheng, and Ruixuan Wang. Fodfom: Fake outlier data by founda- tion models creates stronger visual out-of-distribution detec- tor. InACM MM, 2024. 2
2024
-
[7]
Tagfog: Textual anchor guidance and fake outlier generation for visual out-of-distribution detection
Jiankang Chen, Tong Zhang, Wei-Shi Zheng, and Ruixuan Wang. Tagfog: Textual anchor guidance and fake outlier generation for visual out-of-distribution detection. InAAAI,
-
[8]
Con- jugated semantic pool improves OOD detection with pre- trained vision-language models
Mengyuan Chen, Junyu Gao, and Changsheng Xu. Con- jugated semantic pool improves OOD detection with pre- trained vision-language models. InNeurIPS, 2024. 2, 5, 6
2024
-
[9]
Describing textures in the wild
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. InCVPR, 2014. 5, 6, 2
2014
-
[10]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InCVPR, 2009. 5, 2
2009
-
[11]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR, 2021. 6, 1
2021
-
[12]
VOS: learning what you don’t know by virtual outlier synthesis
Xuefeng Du, Zhaoning Wang, Mu Cai, and Yixuan Li. VOS: learning what you don’t know by virtual outlier synthesis. In ICLR, 2022. 2
2022
-
[13]
Cachefx: A framework for evaluating cache security
Daniel Genkin, William Kosasih, Fangfei Liu, Anna Trikali- nou, Thomas Unterluggauer, and Yuval Yarom. Cachefx: A framework for evaluating cache security. InASIA CCS, 2023. 7
2023
-
[14]
A baseline for detect- ing misclassified and out-of-distribution examples in neural networks
Dan Hendrycks and Kevin Gimpel. A baseline for detect- ing misclassified and out-of-distribution examples in neural networks. InICLR, 2017. 1, 2
2017
-
[15]
Scaling out-of-distribution detection for real-world settings
Dan Hendrycks, Steven Basart, Mantas Mazeika, Andy Zou, Joseph Kwon, Mohammadreza Mostajabi, Jacob Steinhardt, and Dawn Song. Scaling out-of-distribution detection for real-world settings. InICML, 2022. 1
2022
-
[16]
Belongie
Grant Van Horn, Oisin Mac Aodha, Yang Song, Yin Cui, Chen Sun, Alexander Shepard, Hartwig Adam, Pietro Per- ona, and Serge J. Belongie. The inaturalist species classifi- cation and detection dataset. InCVPR, 2018. 5, 2
2018
-
[17]
Negative label guided OOD detec- tion with pretrained vision-language models
Xue Jiang, Feng Liu, Zhen Fang, Hong Chen, Tongliang Liu, Feng Zheng, and Bo Han. Negative label guided OOD detec- tion with pretrained vision-language models. InICLR, 2024. 1, 2, 5, 6
2024
-
[18]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InICLR, 2015. 6, 1
2015
-
[19]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. Technical Report TR- 2009, University of Toronto, 2009. 6, 2
2009
-
[20]
Gradient-based learning applied to document recog- nition.Proc
Yann LeCun, L ´eon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recog- nition.Proc. IEEE, 86(11):2278–2324, 1998. 2
1998
-
[21]
Concept matching with agent for out-of- distribution detection
Yuxiao Lee, Xiaofeng Cao, Jingcai Guo, Wei Ye, Qing Guo, and Yi Chang. Concept matching with agent for out-of- distribution detection. InAAAI, 2025. 2, 5, 6
2025
-
[22]
Learning transferable negative prompts for out-of- distribution detection
Tianqi Li, Guansong Pang, Xiao Bai, Wenjun Miao, and Jin Zheng. Learning transferable negative prompts for out-of- distribution detection. InCVPR, 2024. 2
2024
-
[23]
On the robust- ness of open-world test-time training: Self-training with dy- namic prototype expansion
Yushu Li, Xun Xu, Yongyi Su, and Kui Jia. On the robust- ness of open-world test-time training: Self-training with dy- namic prototype expansion. InICCV, 2023. 3, 2
2023
-
[24]
On the robust- ness of open-world test-time training: Self-training with dy- namic prototype expansion
Yushu Li, Xun Xu, Yongyi Su, and Kui Jia. On the robust- ness of open-world test-time training: Self-training with dy- namic prototype expansion. InICCV, 2023. 6, 1
2023
-
[25]
Shiyu Liang, Yixuan Li, and R. Srikant. Enhancing the re- liability of out-of-distribution image detection in neural net- works. InICLR, 2018. 2
2018
-
[26]
Owens, and Yixuan Li
Weitang Liu, Xiaoyun Wang, John D. Owens, and Yixuan Li. Energy-based out-of-distribution detection. InNeurIPS,
-
[27]
Fa: Forced prompt learning of vision-language models for out-of-distribution detection
Xinhua Lu, Runhe Lai, Yanqi Wu, Kanghao Chen, Wei-Shi Zheng, and Ruixuan Wang. Fa: Forced prompt learning of vision-language models for out-of-distribution detection. In ICCV, 2025. 2, 3, 5, 6
2025
-
[28]
Auxiliary prompt tuning of vision-language mod- els for few-shot out-of-distribution detection
Wenjun Miao, Guansong Pang, Zihan Wang, Jin Zheng, and Xiao Bai. Auxiliary prompt tuning of vision-language mod- els for few-shot out-of-distribution detection. InICCV, 2025. 2, 5, 6
2025
-
[29]
Delving into out-of-distribution detection with vision-language representations
Yifei Ming, Ziyang Cai, Jiuxiang Gu, Yiyou Sun, Wei Li, and Yixuan Li. Delving into out-of-distribution detection with vision-language representations. InNeurIPS, 2022. 2, 5, 6, 1
2022
-
[30]
How to exploit hyperspherical embeddings for out-of-distribution detection? InICLR, 2023
Yifei Ming, Yiyou Sun, Ousmane Dia, and Yixuan Li. How to exploit hyperspherical embeddings for out-of-distribution detection? InICLR, 2023. 2
2023
-
[31]
Locoop: Few-shot out-of-distribution detection via prompt learning
Atsuyuki Miyai, Qing Yu, Go Irie, and Kiyoharu Aizawa. Locoop: Few-shot out-of-distribution detection via prompt learning. InNeurIPS, 2023. 2, 5, 6
2023
-
[32]
Gl-mcm: Global and local maximum concept matching for zero-shot out-of-distribution detection.IJCV, 133(6):3586– 3596, 2025
Atsuyuki Miyai, Qing Yu, Go Irie, and Kiyoharu Aizawa. Gl-mcm: Global and local maximum concept matching for zero-shot out-of-distribution detection.IJCV, 133(6):3586– 3596, 2025. 2, 5, 6
2025
-
[33]
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bis- sacco, Bo Wu, and Andrew Y . Ng. Reading digits in nat- ural images with unsupervised feature learning. InNeurIPS,
-
[34]
Deep neu- ral networks are easily fooled: High confidence predictions for unrecognizable images
Anh Mai Nguyen, Jason Yosinski, and Jeff Clune. Deep neu- ral networks are easily fooled: High confidence predictions for unrecognizable images. InCVPR, 2015. 1
2015
-
[35]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InICML, 2021. 1, 2, 3, 6, 4
2021
-
[36]
Neural machine translation of rare words with subword units
Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural machine translation of rare words with subword units. In ACL, 2016. 4
2016
-
[37]
Test- time prompt tuning for zero-shot generalization in vision- language models
Manli Shu, Weili Nie, De-An Huang, Zhiding Yu, Tom Goldstein, Anima Anandkumar, and Chaowei Xiao. Test- time prompt tuning for zero-shot generalization in vision- language models. InNeurIPS, 2022. 1
2022
-
[38]
React: Out-of- distribution detection with rectified activations
Yiyou Sun, Chuan Guo, and Yixuan Li. React: Out-of- distribution detection with rectified activations. InNeurIPS,
-
[39]
Open-set recognition: A good closed-set classifier is all you need
Sagar Vaze, Kai Han, Andrea Vedaldi, and Andrew Zisser- man. Open-set recognition: A good closed-set classifier is all you need. InICLR, 2022. 2
2022
-
[40]
Vim: Out-of-distribution with virtual-logit matching
Haoqi Wang, Zhizhong Li, Litong Feng, and Wayne Zhang. Vim: Out-of-distribution with virtual-logit matching. In CVPR, 2022. 2
2022
-
[41]
Clipn for zero-shot ood detection: Teaching clip to say no
Hualiang Wang, Yi Li, Huifeng Yao, and Xiaomeng Li. Clipn for zero-shot ood detection: Teaching clip to say no. InCVPR, 2023. 1, 2, 5, 6
2023
-
[42]
Yanqi Wu, Qichao Chen, Runhe Lai, Xinhua Lu, Jia-Xin Zhuang, Zhilin Zhao, Wei-Shi Zheng, and Ruixuan Wang. Dcac: Dynamic class-aware cache creates stronger out-of- distribution detectors.arXiv preprint arXiv:2601.12468,
-
[43]
Ehinger, Aude Oliva, and Antonio Torralba
Jianxiong Xiao, James Hays, Krista A. Ehinger, Aude Oliva, and Antonio Torralba. SUN database: Large-scale scene recognition from abbey to zoo. InCVPR, 2010. 5
2010
-
[44]
TurkerGaze: Crowdsourcing Saliency with Webcam based Eye Tracking
Pingmei Xu, Krista A Ehinger, Yinda Zhang, Adam Finkel- stein, Sanjeev R Kulkarni, and Jianxiong Xiao. Turkergaze: Crowdsourcing saliency with webcam based eye tracking. arXiv preprint arXiv:1504.06755, 2015. 6
work page Pith review arXiv 2015
-
[45]
Overcoming short- cut problem in VLM for robust out-of-distribution detection
Zhuo Xu, Xiang Xiang, and Yifan Liang. Overcoming short- cut problem in VLM for robust out-of-distribution detection. InCVPR, 2025. 2, 5, 6
2025
-
[46]
Juncheng Yang, Yao Yue, and K. V . Rashmi. A large-scale analysis of hundreds of in-memory key-value cache clusters at twitter.TOS, 17(3):17:1–17:35, 2021. 7
2021
-
[47]
Openood: Benchmarking generalized out-of-distribution detection
Jingkang Yang, Pengyun Wang, Dejian Zou, Zitang Zhou, Kunyuan Ding, Wenxuan Peng, Haoqi Wang, Guangyao Chen, Bo Li, Yiyou Sun, Xuefeng Du, Kaiyang Zhou, Wayne Zhang, Dan Hendrycks, Yixuan Li, and Ziwei Liu. Openood: Benchmarking generalized out-of-distribution detection. In NeurIPS, 2022. 2
2022
-
[48]
Auto: Adap- tive outlier optimization for online test-time ood detection
Puning Yang, Jian Liang, Jie Cao, and Ran He. Auto: Adap- tive outlier optimization for online test-time ood detection. arXiv preprint arXiv:2303.12267, 2023. 2
-
[49]
OODD: test-time out-of-distribution detection with dynamic dictionary
Yifeng Yang, Lin Zhu, Zewen Sun, Hengyu Liu, Qinying Gu, and Nanyang Ye. OODD: test-time out-of-distribution detection with dynamic dictionary. InCVPR, 2025. 2, 5, 6, 7, 8, 1
2025
-
[50]
LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop
Fisher Yu, Ari Seff, Yinda Zhang, Shuran Song, Thomas Funkhouser, and Jianxiong Xiao. Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop.arXiv preprint arXiv:1506.03365, 2015. 6
work page internal anchor Pith review arXiv 2015
-
[51]
Self- calibrated tuning of vision-language models for out-of- distribution detection
Geng Yu, Jianing Zhu, Jiangchao Yao, and Bo Han. Self- calibrated tuning of vision-language models for out-of- distribution detection. InNeurIPS, 2024. 2
2024
-
[52]
Local-prompt: Extensible local prompts for few- shot out-of-distribution detection
Fanhu Zeng, Zhen Cheng, Fei Zhu, Hongxin Wei, and Xu- Yao Zhang. Local-prompt: Extensible local prompts for few- shot out-of-distribution detection. InICLR, 2025. 2, 3, 5, 6, 1
2025
-
[53]
Adaneg: Adaptive negative proxy guided OOD detection with vision-language models
Yabin Zhang and Lei Zhang. Adaneg: Adaptive negative proxy guided OOD detection with vision-language models. InNeurIPS, 2024. 2, 3, 5, 6, 7
2024
-
[54]
Equipping vision foundation model with mixture of experts for out-of-distribution detection
Shizhen Zhao, Jiahui Liu, Xin Wen, Haoru Tan, and Xiao- juan Qi. Equipping vision foundation model with mixture of experts for out-of-distribution detection. InICCV, 2025. 5, 6
2025
-
[55]
Places: A 10 million image database for scene recognition.IEEE TPAMI, 40(6):1452–1464, 2018
Bolei Zhou, `Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition.IEEE TPAMI, 40(6):1452–1464, 2018. 5, 6, 2
2018
-
[56]
forest” and
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models.IJCV, 130(9):2337–2348, 2022. 2, 3, 4 TTL: Test-time Textual Learning for OOD Detection with Pretrained Vision-Language Models Supplementary Material A. Basic statement A.1. The Use of Large Language Models Throughout the entire work, we use ChatGPT ...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.