Recognition: unknown
Aligning What Vision-Language Models See and Perceive with Adaptive Information Flow
Pith reviewed 2026-05-10 08:59 UTC · model grok-4.3
The pith
An inference-time technique that uses token activation dynamics to adaptively restrict text attention to important visual tokens, improving VLM accuracy on VQA, grounding, counting, OCR, and hallucination benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
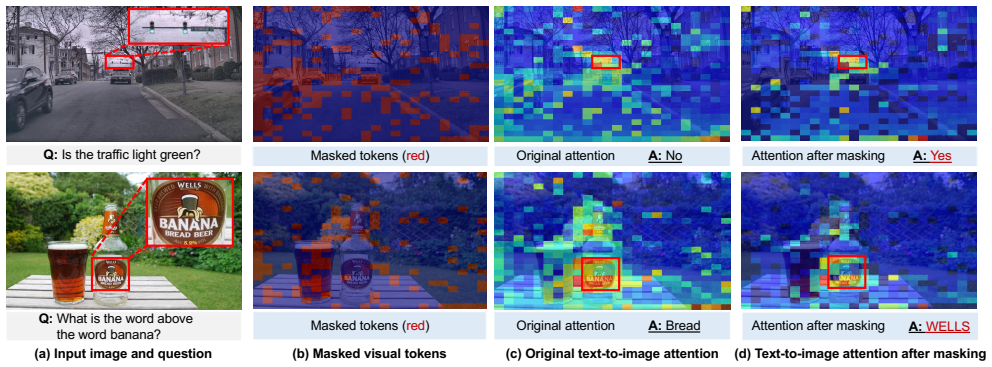
Modulating the information flow during inference by associating text tokens only with important visual tokens (determined by distinct activation patterns during different decoding stages) can improve the perception capability of VLMs.
Load-bearing premise
That visual tokens showing distinct activation patterns across decoding stages are precisely the ones required for correct answers and that suppressing the others removes only interference without discarding necessary information.
Figures






read the original abstract
Vision-Language Models (VLMs) have demonstrated strong capability in a wide range of tasks such as visual recognition, document parsing, and visual grounding. Nevertheless, recent work shows that while VLMs often manage to capture the correct image region corresponding to the question, they do not necessarily produce the correct answers. In this work, we demonstrate that this misalignment could be attributed to suboptimal information flow within VLMs, where text tokens distribute too much attention to irrelevant visual tokens, leading to incorrect answers. Based on the observation, we show that modulating the information flow during inference can improve the perception capability of VLMs. The idea is that text tokens should only be associated with important visual tokens during decoding, eliminating the interference of irrelevant regions. To achieve this, we propose a token dynamics-based method to determine the importance of visual tokens, where visual tokens that exhibit distinct activation patterns during different decoding stages are viewed as important. We apply our approach to representative open-source VLMs and evaluate on various datasets, including visual question answering, visual grounding and counting, optical character recognition, and object hallucination. The results show that our approach significantly improves the performance of baselines. Project page: https://cxliu0.github.io/AIF/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that VLMs often attend to correct image regions yet produce incorrect answers due to suboptimal information flow, where text tokens over-attend to irrelevant visual tokens. It proposes an inference-time method that identifies 'important' visual tokens via distinct activation patterns across decoding stages and modulates attention so text tokens associate only with these tokens, thereby reducing interference. The approach is applied to open-source VLMs and evaluated on VQA, visual grounding, counting, OCR, and object hallucination benchmarks, with reported consistent performance gains over baselines.
Significance. If the central results hold under rigorous controls, the work offers a training-free, model-agnostic intervention for improving VLM perception by dynamically aligning attention with token dynamics. This could have practical value for deployment on existing models and contributes to understanding attention misalignment in multimodal decoding. The breadth of tasks and models tested provides a reasonable basis for generality claims, though the absence of quantitative effect sizes and validation of the core heuristic limits immediate impact.
major comments (3)
- [Abstract and §3] Abstract and §3 (Method): The central assumption that visual tokens with distinct activation patterns across decoding stages are precisely those required for correct answers (and that suppressing others removes only interference) lacks direct validation. No experiments measure overlap between selected tokens and ground-truth relevant regions, human judgments, or counterfactuals (e.g., forcing attention to non-selected tokens and checking answer degradation). Without this, gains could stem from generic attention sparsification rather than targeted correction of the claimed misalignment.
- [Abstract] Abstract: The statement that the approach 'significantly improves the performance of baselines' is unsupported by any reported numbers, confidence intervals, statistical significance tests, or ablation controls on the activation-pattern threshold and modulation rule. This omission makes it impossible to judge effect size, robustness, or whether the method outperforms simpler baselines such as uniform attention reduction.
- [Evaluation] Evaluation sections: No ablation isolates the contribution of the token-dynamics criterion versus the mere act of restricting attention to a subset of visual tokens. A control that selects tokens randomly or by positional heuristics would be required to confirm that the distinct-activation-pattern rule is load-bearing for the observed gains.
minor comments (1)
- [§3] The exact procedure for computing 'distinct activation patterns' (e.g., distance metric, number of decoding stages compared, threshold value) is described only at a high level; a precise algorithmic description or pseudocode would aid reproducibility.
Circularity Check
No circularity; heuristic defined independently and validated on external benchmarks
full rationale
The paper's core proposal is a token-dynamics heuristic that flags visual tokens with distinct activation patterns across decoding stages as important, then modulates attention to suppress others during inference. This rule is stated directly from observation of internal activations and does not reduce to any fitted parameter, self-referential definition, or self-citation chain. Performance is measured on standard external datasets (VQA, grounding, OCR, hallucination) with no equations that equate the claimed gain to a quantity computed from the same test data. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Text tokens in VLMs distribute excessive attention to irrelevant visual tokens, causing incorrect answers despite correct region localization.
- ad hoc to paper Visual tokens with distinct activation patterns across decoding stages are the important ones needed for correct perception.
Reference graph
Works this paper leans on
-
[1]
Claude 3.5 sonnet.https : / / www
Anthropic. Claude 3.5 sonnet.https : / / www . anthropic . com / news / claude - 3 - 5 - sonnet,
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-VL technical report....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing multimodal llm’s referential dialogue magic.arXiv preprint arXiv: 2306.15195, 2023. 7
work page internal anchor Pith review arXiv 2023
-
[4]
Are we on the right way for evaluating large vision-language models? InNeurIPS, pages 27056–27087, 2024
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, and Feng Zhao. Are we on the right way for evaluating large vision-language models? InNeurIPS, pages 27056–27087, 2024. 1, 6
2024
-
[5]
An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InECCV, pages 19–35, 2025. 1, 2, 4
2025
-
[6]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhang- wei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test- time scaling.arXiv preprint arXiv: 2412.05271, 2024. 7
work page internal anchor Pith review arXiv 2024
-
[7]
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhang- wei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, Ji Ma, Jiaqi Wang, Xiaoyi Dong, Hang Yan, Hewei Guo, Conghui He, Botian Shi, Zhenjiang Jin, Chao Xu, Bin Wang, Xingjian Wei, Wei Li, Wenjian Zhang, Bo Zhang, Pinlong Cai, Licheng Wen, Xiangchao Yan, Min Dou, Lewei Lu, Xizhou Zhu, Tong ...
work page internal anchor Pith review arXiv 2024
-
[8]
InternVL: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. InternVL: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In CVPR, pages 24185–24198, 2024. 1, 2
2024
-
[9]
InstructBLIP: Towards general-purpose vision- language models with instruction tuning
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. InstructBLIP: Towards general-purpose vision- language models with instruction tuning. InNeurIPS, pages 49250–49267, 2023. 1, 2
2023
-
[10]
VLMEvalKit: An open-source toolkit for evaluating large multi-modality mod- els
Haodong Duan, Junming Yang, Yuxuan Qiao, Xinyu Fang, Lin Chen, Yuan Liu, Xiaoyi Dong, Yuhang Zang, Pan Zhang, Jiaqi Wang, Dahua Lin, and Kai Chen. VLMEvalKit: An open-source toolkit for evaluating large multi-modality mod- els. InACM MM, pages 11198–11201, 2024. 6
2024
-
[11]
Smith, Wei-Chiu Ma, and Ranjay Krishna
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A. Smith, Wei-Chiu Ma, and Ranjay Krishna. BLINK: Multimodal large language models can see but not perceive. InECCV, page 148–166, 2024. 1, 2
2024
-
[12]
Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al. Seed1. 5-VL technical report.arXiv preprint arXiv: 2505.07062, 2025. 1
work page internal anchor Pith review arXiv 2025
-
[13]
Automated model discovery via multi-modal & multi-step pipeline
Lee Jung-Mok, Nam Hyeon-Woo, Moon Ye-Bin, Junhyun Nam, and Tae-Hyun Oh. Automated model discovery via multi-modal & multi-step pipeline. InNeurIPS, 2025. 2
2025
-
[14]
What’s in the im- age? a deep-dive into the vision of vision language models
Omri Kaduri, Shai Bagon, and Tali Dekel. What’s in the im- age? a deep-dive into the vision of vision language models. InCVPR, pages 14549–14558, 2025. 1, 2
2025
-
[15]
Your large vision-language model only needs a few attention heads for visual grounding
Seil Kang, Jinyeong Kim, Junhyeok Kim, and Seong Jae Hwang. Your large vision-language model only needs a few attention heads for visual grounding. InCVPR, pages 9339– 9350, 2025. 7
2025
-
[16]
See what you are told: Visual attention sink in large multimodal models
Seil Kang, Jinyeong Kim, Junhyeok Kim, and Seong Jae Hwang. See what you are told: Visual attention sink in large multimodal models. InICLR, 2025. 1
2025
-
[17]
ReferItGame: Referring to objects in pho- tographs of natural scenes
Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. ReferItGame: Referring to objects in pho- tographs of natural scenes. InEMNLP, pages 787–798, 2014. 1, 2, 6
2014
-
[18]
mEOL: Training-free instruction-guided mul- timodal embedder for vector graphics and image retrieval
Kyeong Seon Kim, Baek Seong-Eun, Lee Jung-Mok, and Tae-Hyun Oh. mEOL: Training-free instruction-guided mul- timodal embedder for vector graphics and image retrieval. In WACV, pages 1191–1200, 2026. 2
2026
-
[19]
Mitigating object hal- lucinations in large vision-language models through visual contrastive decoding
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. Mitigating object hal- lucinations in large vision-language models through visual contrastive decoding. InCVPR, pages 13872–13882, 2024. 3
2024
-
[20]
Bohao Li, Yuying Ge, Yi Chen, Yixiao Ge, Ruimao Zhang, and Ying Shan. SEED-Bench-2-Plus: Benchmarking multi- modal large language models with text-rich visual compre- hension.arXiv preprint arXiv: 2404.16790, 2024. 1, 6
-
[21]
Contrastive decoding: Open-ended text gener- ation as optimization
Xiang Lisa Li, Ari Holtzman, Daniel Fried, Percy Liang, Jason Eisner, Tatsunori Hashimoto, Luke Zettlemoyer, and Mike Lewis. Contrastive decoding: Open-ended text gener- ation as optimization. InACL, pages 12286–12312, 2023. 3 9
2023
-
[22]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji rong Wen. Evaluating object hallucination in large vision-language models. InEMNLP, pages 292–305,
-
[23]
Lawrence Zitnick
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C. Lawrence Zitnick. Microsoft COCO: Common objects in context. In ECCV, pages 740–755, 2014. 6
2014
-
[24]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InCVPR, pages 26296–26306, 2024. 1, 2, 4, 6, 7
2024
-
[25]
Grounding DINO: Mar- rying dino with grounded pre-training for open-set object de- tection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding DINO: Mar- rying dino with grounded pre-training for open-set object de- tection. InECCV, page 38–55, 2024. 6, 7
2024
-
[26]
MMBench: Is your multi-modal model an all-around player? InECCV, page 216–233, 2024
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. MMBench: Is your multi-modal model an all-around player? InECCV, page 216–233, 2024. 1
2024
-
[27]
Unveiling the ignorance of mllms: Seeing clearly, answering incorrectly
Yexin Liu, Zhengyang Liang, Yueze Wang, Xianfeng Wu, Feilong Tang, Muyang He, Jian Li, Zheng Liu, Harry Yang, Sernam Lim, and Bo Zhao. Unveiling the ignorance of mllms: Seeing clearly, answering incorrectly. InCVPR, pages 9087–9097, 2025. 1, 7
2025
-
[28]
ChartQA: A benchmark for question answering about charts with visual and logical reasoning
Ahmed Masry, Do Long, Jia Qing Tan, Shafiq Joty, and Ena- mul Hoque. ChartQA: A benchmark for question answering about charts with visual and logical reasoning. InACL Find- ings, pages 2263–2279, 2022. 1, 2
2022
-
[29]
Mod- eling context between objects for referring expression under- standing
Varun K Nagaraja, Vlad I Morariu, and Larry S Davis. Mod- eling context between objects for referring expression under- standing. InECCV, pages 792–807, 2016. 1, 6
2016
-
[30]
Hello gpt-4o.https://openai.com/index/ hello-gpt-4o, 2024
openAI. Hello gpt-4o.https://openai.com/index/ hello-gpt-4o, 2024. 7
2024
-
[31]
Teaching CLIP to count to ten
Roni Paiss, Ariel Ephrat, Omer Tov, Shiran Zada, Inbar Mosseri, Michal Irani, and Tali Dekel. Teaching CLIP to count to ten. InICCV, pages 3170–3180, 2023. 2, 4, 6
2023
-
[32]
Rethinking causal mask attention for vision-language infer- ence
Xiaohuan Pei, Tao Huang, YanXiang Ma, and Chang Xu. Rethinking causal mask attention for vision-language infer- ence. InICLR, 2026. 3, 8
2026
-
[33]
Towards vqa models that can read
Amanpreet Singh, Vivek Natarjan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. InCVPR, pages 8317–8326, 2019. 1, 2, 4, 6
2019
-
[34]
A VHBench: A cross- modal hallucination benchmark for audio-visual large lan- guage models
Kim Sung-Bin, Oh Hyun-Bin, JungMok Lee, Arda Senocak, Joon Son Chung, and Tae-Hyun Oh. A VHBench: A cross- modal hallucination benchmark for audio-visual large lan- guage models. InICLR, 2025. 2
2025
-
[35]
Eyes wide shut? exploring the visual shortcomings of multimodal llms
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. Eyes wide shut? exploring the visual shortcomings of multimodal llms. InCVPR, pages 9568–9578, 2024. 1
2024
-
[36]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InNeurIPS, page 6000–6010, 2017. 3
2017
-
[37]
MLLM can see? dynamic correction decoding for hallucination mitiga- tion
Chenxi Wang, Xiang Chen, Ningyu Zhang, Bozhong Tian, Haoming Xu, Shumin Deng, and Huajun Chen. MLLM can see? dynamic correction decoding for hallucination mitiga- tion. InICLR, 2025. 1
2025
-
[38]
Towards understand- ing how knowledge evolves in large vision-language models
Sudong Wang, Yunjian Zhang, Yao Zhu, Jianing Li, Zizhe Wang, Yanwei Liu, and Xiangyang Ji. Towards understand- ing how knowledge evolves in large vision-language models. InCVPR, pages 29858–29868, 2025. 3
2025
-
[39]
Wei-Yao Wang, Zhao Wang, Helen Suzuki, and Yoshiyuki Kobayashi. Seeing is understanding: Unlocking causal at- tention into modality-mutual attention for multimodal llms. arXiv preprint arXiv: 2503.02597, 2025. 3
-
[40]
V*: Guided visual search as a core mechanism in multimodal llms
Penghao Wu and Saining Xie. V*: Guided visual search as a core mechanism in multimodal llms. InCVPR, pages 13084–13094, 2024. 2, 6
2024
-
[41]
Realworldqa: A benchmark for real-world spa- tial understanding.https : / / huggingface
xAI. Realworldqa: A benchmark for real-world spa- tial understanding.https : / / huggingface . co / datasets/xai-org/RealworldQA, 2024. 1, 2, 4, 6
2024
-
[42]
Mitigat- ing object hallucination via concentric causal attention
Yun Xing, Yiheng Li, Ivan Laptev, and Shijian Lu. Mitigat- ing object hallucination via concentric causal attention. In NeurIPS, pages 92012–92035, 2024. 1, 3, 6, 7
2024
-
[43]
BEAF: Observing before-after changes to evaluate hallucination in vision-language models
Moon Ye-Bin, Nam Hyeon-Woo, Wonseok Choi, and Tae- Hyun Oh. BEAF: Observing before-after changes to evaluate hallucination in vision-language models. InECCV, pages 232–248, 2024. 2
2024
-
[44]
Lifting the veil on visual information flow in mllms: Unlocking pathways to faster inference
Hao Yin, Gunagzong Si, and Zilei Wang. Lifting the veil on visual information flow in mllms: Unlocking pathways to faster inference. InCVPR, pages 9382–9391, 2025. 2
2025
-
[45]
StableMask: refining causal masking in decoder-only transformer
Qingyu Yin, Xuzheng He, Xiang Zhuang, Yu Zhao, Jianhua Yao, Xiaoyu Shen, and Qiang Zhang. StableMask: refining causal masking in decoder-only transformer. InICML, pages 57033–57052, 2024. 3
2024
-
[46]
Modeling context in referring expres- sions
Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg. Modeling context in referring expres- sions. InECCV, pages 69–85, 2016. 1, 2, 6
2016
-
[47]
MLLMs know where to look: Training-free perception of small visual details with multimodal LLMs
Jiarui Zhang, Mahyar Khayatkhoei, Prateek Chhikara, and Filip Ilievski. MLLMs know where to look: Training-free perception of small visual details with multimodal LLMs. In ICLR, 2025. 1, 2, 6, 7
2025
-
[48]
From redundancy to relevance: Information flow in lvlms across reasoning tasks
Xiaofeng Zhang, Yihao Quan, Chen Shen, Xiaosong Yuan, Shaotian Yan, Liang Xie, Wenxiao Wang, Chaochen Gu, Hao Tang, and Jieping Ye. From redundancy to relevance: Information flow in lvlms across reasoning tasks. InNAACL, pages 2289–2299, 2025. 1, 2
2025
-
[49]
Cross-modal information flow in multimodal large language models
Zhi Zhang, Srishti Yadav, Fengze Han, and Ekaterina Shutova. Cross-modal information flow in multimodal large language models. InCVPR, pages 19781–19791, 2025. 1, 2
2025
-
[50]
Mitigating object hallucination in large vision-language models via image-grounded guidance
Linxi Zhao, Yihe Deng, Weitong Zhang, and Quanquan Gu. Mitigating object hallucination in large vision-language models via image-grounded guidance. InICML, pages 77461 – 77486, 2025. 2
2025
-
[51]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. InternVL3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv: 2504.10479, 2025. 1, 2 10
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.