QuantSightBench: Evaluating LLM Quantitative Forecasting with Prediction Intervals
Pith reviewed 2026-05-10 08:53 UTC · model grok-4.3
The pith
No evaluated LLM reaches the 90% coverage target for prediction intervals in quantitative forecasting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
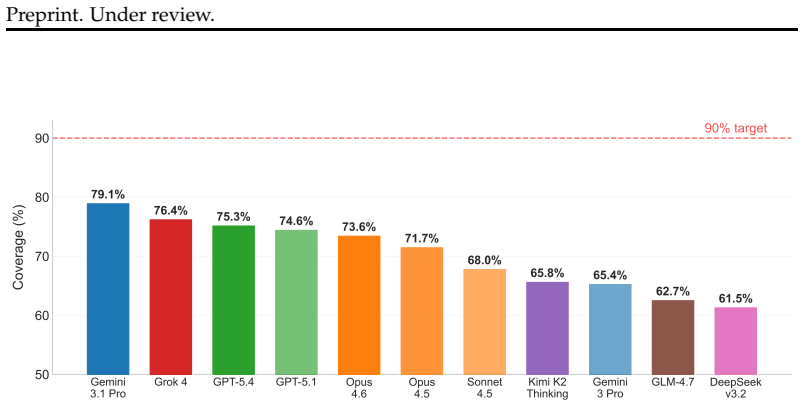
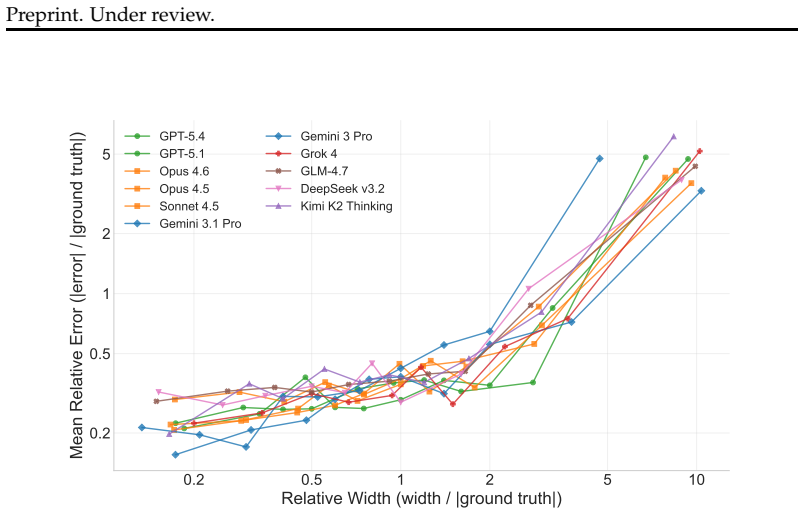
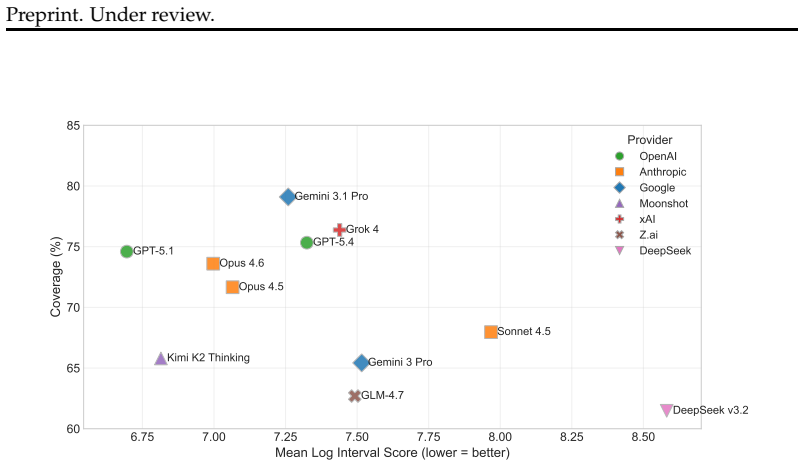
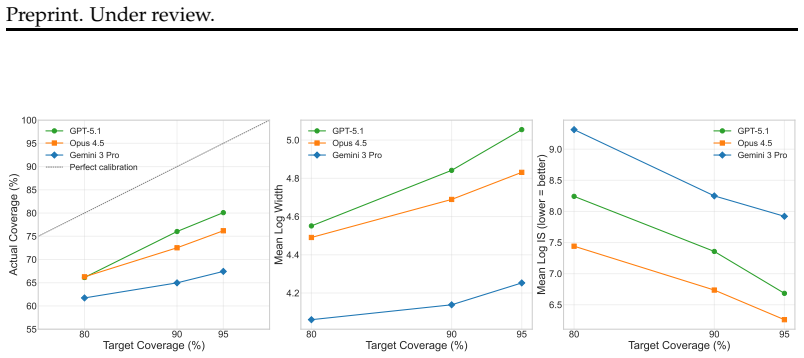
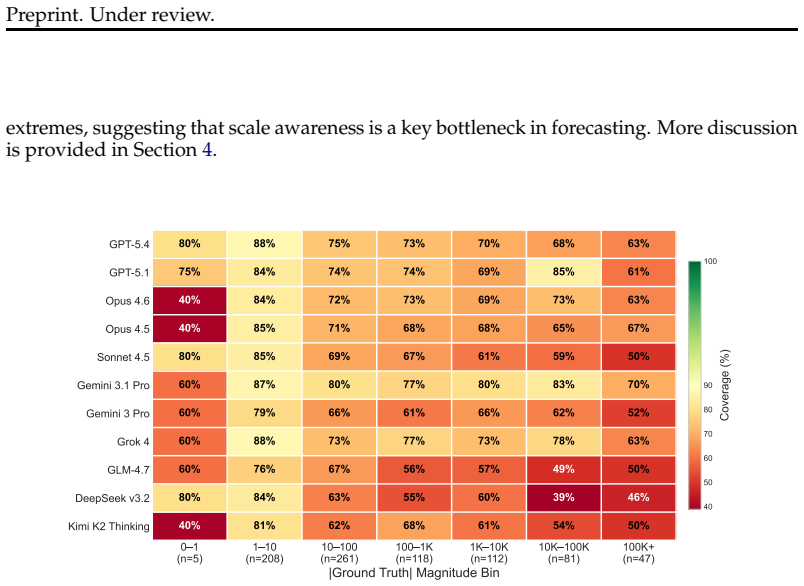
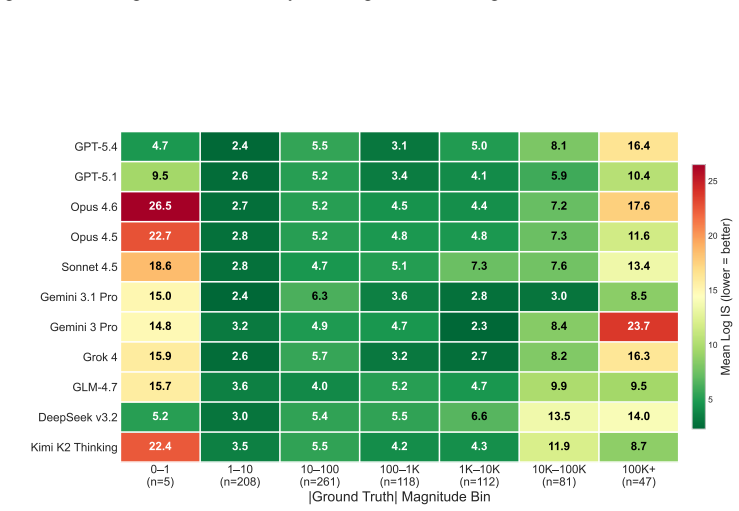
We propose prediction intervals as a natural and rigorous interface for evaluating LLM quantitative forecasting. To assess this capability, we introduce QuantSightBench and evaluate frontier models under multiple settings, assessing both empirical coverage and interval sharpness. Our results show that none of the 11 evaluated frontier and open-weight models achieves the 90% coverage target, with the top performers Gemini 3.1 Pro (79.1%), Grok 4 (76.4%), and GPT-5.4 (75.3%) all falling at least 10 percentage points short. Calibration degrades sharply at extreme magnitudes, revealing systematic overconfidence across all evaluated models.
What carries the argument
QuantSightBench benchmark, which uses prediction intervals to test empirical coverage, interval sharpness, and calibration across magnitudes for continuous quantitative forecasts.
If this is right
- All tested models exhibit systematic overconfidence when expressing uncertainty in numerical forecasts.
- Calibration accuracy declines sharply for forecasts involving extreme or large-magnitude values.
- Prediction intervals provide a stricter and more informative evaluation than point estimates for numerical reasoning.
- No frontier model yet demonstrates reliable calibration for continuous quantitative forecasting tasks.
Where Pith is reading between the lines
- Real-world applications that rely on LLM-generated forecasts would benefit from post-hoc calibration or human review to correct overconfidence.
- Future model training could incorporate explicit objectives that reward proper interval calibration rather than point accuracy alone.
- The observed pattern suggests that extending the benchmark to additional domains would likely reveal similar calibration gaps.
Load-bearing premise
The tasks and ground-truth values in QuantSightBench are representative of real-world quantitative forecasting and measured without error or selection bias.
What would settle it
Finding that any current or future model consistently achieves at least 90% empirical coverage across the full range of QuantSightBench tasks, including at extreme magnitudes, would directly contradict the reported shortfall.
Figures



read the original abstract
Forecasting has become a natural benchmark for reasoning under uncertainty. Yet existing evaluations of large language models remain limited to judgmental tasks in simple formats, such as binary or multiple-choice questions. In practice, however, forecasting spans a far broader scope. Across domains such as economics, public health, and social demographics, decisions hinge on numerical estimates over continuous quantities, a capability that current benchmarks do not capture. Evaluating such estimates requires a format that makes uncertainty explicit and testable. We propose prediction intervals as a natural and rigorous interface for this purpose. They demand scale awareness, internal consistency across confidence levels, and calibration over a continuum of outcomes, making them a more suitable evaluation format than point estimates for numerical forecasting. To assess this capability, we introduce a new benchmark QuantSightBench, and evaluate frontier models under multiple settings, assessing both empirical coverage and interval sharpness. Our results show that none of the 11 evaluated frontier and open-weight models achieves the 90\% coverage target, with the top performers Gemini 3.1 Pro (79.1\%), Grok 4 (76.4\%), and GPT-5.4 (75.3\%) all falling at least 10 percentage points short. Calibration degrades sharply at extreme magnitudes, revealing systematic overconfidence across all evaluated models.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
No significant circularity in empirical benchmark evaluation
full rationale
The paper introduces QuantSightBench and reports empirical coverage and calibration results for 11 LLMs on quantitative forecasting tasks using prediction intervals. All load-bearing claims consist of direct statistical comparisons between model outputs and held-out external ground-truth values. No equations, derivations, fitted parameters, ansatzes, or self-citations are invoked to produce the headline findings; the evaluation protocol is independent of the model responses being measured and does not reduce any result to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi: 10.18653/v1/2023.emnlp-main.330
Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.330. URLhttps://aclanthology.org/2023.emnlp-main.330/. Vladimir Vovk, Alex Gammerman, and Glenn Shafer.Algorithmic Learning in a Random World. Springer, 2005. Zhen Wang, Xi Zhou, Yating Yang, Bo Ma, Lei Wang, Rui Dong, and Azmat Anwar. Open- Forecast: A large-scale open-ended even...
-
[2]
Think about what data points would reduce uncertainty
Assess what information you need. Think about what data points would reduce uncertainty
-
[3]
If you need external data, use thesearch articlestool
-
[4]
Evaluate relevance foreachretrieved article: mark asRELEVANTorNOT RELEVANTwith justification
-
[5]
Decide whether additional searches are needed
-
[6]
Base predictiononlyon relevant articles; if none found, rely on prior knowledge with wide intervals. PREDICTION REQUIREMENTS: Provide a {probability level} prediction interval (lower, median, upper) in the same units as the resolution criteria. OUTPUT FORMAT: <lower>NUMBER</lower> <median>NUMBER</median> <upper>NUMBER</upper> Figure 10: Agentic forecastin...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.