Recognition: unknown
DENALI: A Dataset Enabling Non-Line-of-Sight Spatial Reasoning with Low-Cost LiDARs
Pith reviewed 2026-05-10 08:17 UTC · model grok-4.3
The pith
Low-cost LiDARs enable data-driven perception of hidden objects via their raw time-resolved histograms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
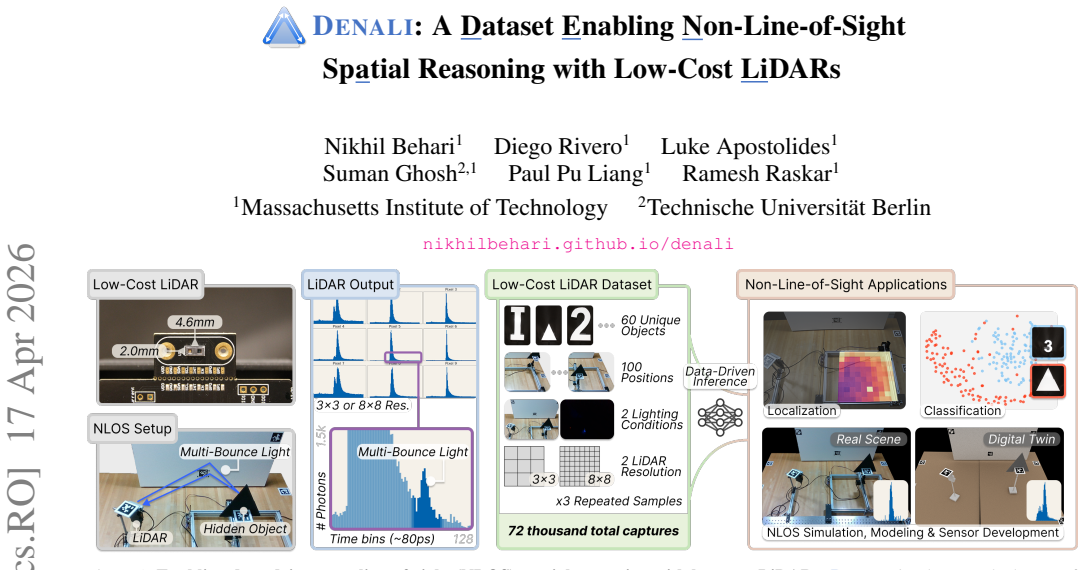
We present DENALI, the first large-scale real-world dataset of space-time histograms from low-cost LiDARs capturing hidden objects. Using our dataset, we show that consumer LiDARs can enable accurate, data-driven NLOS perception. We further identify key scene and modeling factors that limit performance, as well as simulation-fidelity gaps that hinder current sim-to-real transfer.
What carries the argument
DENALI dataset of space-time histograms from low-cost LiDARs encoding multi-bounce light returns for hidden objects.
If this is right
- Data-driven models trained on the histograms achieve accurate non-line-of-sight perception with consumer LiDARs.
- Scene factors including object shape, position, lighting conditions, and resolution affect model performance.
- Simulation-to-real gaps limit transfer, motivating more real-world data collection for better models.
- Scalable non-line-of-sight vision systems become feasible for mobile devices and robots.
Where Pith is reading between the lines
- Robots and mobile phones could gain the ability to sense hidden objects without extra hardware.
- Algorithms might combine these NLOS cues with direct depth measurements for improved scene understanding.
- Collecting similar datasets for dynamic or outdoor environments could extend the approach to new applications.
Load-bearing premise
Data-driven models trained on the captured histograms can generalize to achieve accurate NLOS perception across unseen scenes despite the severe hardware limitations of consumer LiDARs.
What would settle it
Testing a trained model on a collection of new hidden-object scenes not included in the 72,000 training examples shows low accuracy in predicting object presence or location.
Figures







read the original abstract
Consumer LiDARs in mobile devices and robots typically output a single depth value per pixel. Yet internally, they record full time-resolved histograms containing direct and multi-bounce light returns; these multi-bounce returns encode rich non-line-of-sight (NLOS) cues that can enable perception of hidden objects in a scene. However, severe hardware limitations of consumer LiDARs make NLOS reconstruction with conventional methods difficult. In this work, we motivate a complementary direction: enabling NLOS perception with low-cost LiDARs through data-driven inference. We present DENALI, the first large-scale real-world dataset of space-time histograms from low-cost LiDARs capturing hidden objects. We capture time-resolved LiDAR histograms for 72,000 hidden-object scenes across diverse object shapes, positions, lighting conditions, and spatial resolutions. Using our dataset, we show that consumer LiDARs can enable accurate, data-driven NLOS perception. We further identify key scene and modeling factors that limit performance, as well as simulation-fidelity gaps that hinder current sim-to-real transfer, motivating future work toward scalable NLOS vision with consumer LiDARs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DENALI, the first large-scale real-world dataset of 72,000 space-time histograms captured from low-cost consumer LiDARs across diverse hidden-object scenes varying in shape, position, lighting, and resolution. It argues that the multi-bounce returns in these histograms enable data-driven NLOS perception of hidden objects, demonstrates this feasibility, and analyzes key limiting factors along with simulation-to-real gaps that hinder transfer.
Significance. If the empirical results hold, the dataset would be a valuable resource for NLOS research by shifting from simulation-only training to real captured histograms, potentially enabling practical hidden-object perception on commodity hardware in robotics and mobile devices. Explicitly identifying hardware constraints and sim-to-real discrepancies provides concrete directions for future model and sensor improvements.
major comments (3)
- [Abstract] Abstract: The central claim that 'consumer LiDARs can enable accurate, data-driven NLOS perception' is asserted without any quantitative support such as accuracy, IoU, or error metrics, baselines (e.g., direct-return only or simulation-trained models), or test-set details. This absence makes it impossible to assess whether the learned mapping extracts usable multi-bounce signals or merely exploits dataset biases.
- [Experiments] Experimental evaluation (assumed §4 or equivalent): No description of train/test splits, cross-scene generalization tests, or ablations isolating NLOS histogram components versus direct returns or scene correlations is provided. Without these, the skeptic concern that performance may collapse on unseen object placements or lighting cannot be evaluated.
- [Dataset] Dataset capture description (assumed §3): The paper notes severe hardware limitations (low temporal resolution, single-photon noise) yet claims the histograms encode rich NLOS cues; however, no quantitative characterization of signal-to-noise ratios or multi-bounce visibility across the 72k scenes is given to ground this.
minor comments (2)
- Clarify the exact LiDAR model, histogram bin count, and capture protocol (e.g., integration time, laser power) so that the dataset can be reproduced or extended by others.
- The abstract mentions 'identifying key scene and modeling factors that limit performance' but does not list them explicitly; a table or enumerated list in the main text would improve readability.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. We address each major comment below and agree that the manuscript would benefit from additional quantitative details and clarifications. We have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'consumer LiDARs can enable accurate, data-driven NLOS perception' is asserted without any quantitative support such as accuracy, IoU, or error metrics, baselines (e.g., direct-return only or simulation-trained models), or test-set details. This absence makes it impossible to assess whether the learned mapping extracts usable multi-bounce signals or merely exploits dataset biases.
Authors: We agree that the abstract would be strengthened by including quantitative support. The manuscript body demonstrates feasibility through experimental results, but we will revise the abstract to incorporate key metrics (accuracy, IoU, error rates), baseline comparisons, and test-set details to better substantiate the claim and allow immediate assessment of multi-bounce signal utility versus biases. revision: yes
-
Referee: [Experiments] Experimental evaluation (assumed §4 or equivalent): No description of train/test splits, cross-scene generalization tests, or ablations isolating NLOS histogram components versus direct returns or scene correlations is provided. Without these, the skeptic concern that performance may collapse on unseen object placements or lighting cannot be evaluated.
Authors: We acknowledge that more explicit experimental protocols are needed to evaluate generalization and rule out biases. While the manuscript includes results showing dataset utility for NLOS perception, we will expand the experimental section to detail train/test splits, add cross-scene generalization tests, and include ablations isolating NLOS multi-bounce components from direct returns and scene correlations. revision: yes
-
Referee: [Dataset] Dataset capture description (assumed §3): The paper notes severe hardware limitations (low temporal resolution, single-photon noise) yet claims the histograms encode rich NLOS cues; however, no quantitative characterization of signal-to-noise ratios or multi-bounce visibility across the 72k scenes is given to ground this.
Authors: We agree that quantitative characterization of SNR and multi-bounce visibility would better support the claims regarding NLOS cues despite the noted hardware constraints. We will add this analysis to the dataset capture section, including SNR measurements and visibility statistics across the 72,000 scenes. revision: yes
Circularity Check
Empirical dataset release with no derivation chain
full rationale
The paper's core contribution is the collection and release of 72,000 real-world space-time histogram scenes from low-cost LiDARs, followed by a feasibility demonstration that data-driven models can perform NLOS perception on this data. No equations, fitted parameters, uniqueness theorems, or predictive claims are advanced that could reduce to the inputs by construction. The abstract and described content contain no self-citation load-bearing steps, no ansatz smuggling, and no renaming of known results as novel derivations. The work is self-contained as an empirical benchmark and does not invoke any internal mathematical reduction that would trigger circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
TMF882X Datasheet.https:// ams-osram.com/, n.d
AMS OSRAM AG. TMF882X Datasheet.https:// ams-osram.com/, n.d. 2, 3, 4
-
[2]
ARKitScenes: A Diverse Real-World Dataset For 3D Indoor Scene Understanding Using Mobile RGB-D Data
Gilad Baruch, Zhuoyuan Chen, Afshin Dehghan, Tal Dimry, Yuri Feigin, Peter Fu, Thomas Gebauer, Brandon Joffe, Daniel Kurz, Arik Schwartz, et al. Arkitscenes: A diverse real-world dataset for 3d indoor scene understanding using mobile rgb-d data.arXiv preprint arXiv:2111.08897, 2021. 2
work page internal anchor Pith review arXiv 2021
-
[3]
Blurred lidar for sharper 3d: Robust handheld 3d scanning with diffuse lidar and rgb
Nikhil Behari, Aaron Young, Siddharth Somasundaram, Tzofi Klinghoffer, Akshat Dave, and Ramesh Raskar. Blurred lidar for sharper 3d: Robust handheld 3d scanning with diffuse lidar and rgb. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26954– 26964, 2025. 2, 3
2025
-
[4]
Se- mantickitti: A dataset for semantic scene understanding of lidar sequences
Jens Behley, Martin Garbade, Andres Milioto, Jan Quen- zel, Sven Behnke, Cyrill Stachniss, and Jurgen Gall. Se- mantickitti: A dataset for semantic scene understanding of lidar sequences. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 9297–9307,
-
[5]
Lidar system architectures and cir- cuits.IEEE Communications Magazine, 55(10):135–142,
Behnam Behroozpour, Phillip AM Sandborn, Ming C Wu, and Bernhard E Boser. Lidar system architectures and cir- cuits.IEEE Communications Magazine, 55(10):135–142,
-
[6]
nuscenes: A multi- modal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom. nuscenes: A multi- modal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020. 2
2020
-
[7]
Low-cost spad sensing for non-line-of-sight tracking, material classification and depth imaging.ACM Transactions on Graphics (TOG), 40(4):1–12, 2021
Clara Callenberg, Zheng Shi, Felix Heide, and Matthias B Hullin. Low-cost spad sensing for non-line-of-sight tracking, material classification and depth imaging.ACM Transactions on Graphics (TOG), 40(4):1–12, 2021. 2, 3
2021
-
[8]
Learned feature embed- dings for non-line-of-sight imaging and recognition.ACM Transactions on Graphics (ToG), 39(6):1–18, 2020
Wenzheng Chen, Fangyin Wei, Kiriakos N Kutulakos, Szy- mon Rusinkiewicz, and Felix Heide. Learned feature embed- dings for non-line-of-sight imaging and recognition.ACM Transactions on Graphics (ToG), 39(6):1–18, 2020. 3
2020
-
[9]
Non-line-of-sight imaging.Nature Reviews Physics, 2(6): 318–327, 2020
Daniele Faccio, Andreas Velten, and Gordon Wetzstein. Non-line-of-sight imaging.Nature Reviews Physics, 2(6): 318–327, 2020. 3
2020
-
[10]
Nlos-neus: Non-line-of-sight neural im- plicit surface
Yuki Fujimura, Takahiro Kushida, Takuya Funatomi, and Ya- suhiro Mukaigawa. Nlos-neus: Non-line-of-sight neural im- plicit surface. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10532–10541, 2023. 3
2023
-
[11]
Are we ready for autonomous driving? the kitti vision benchmark suite
Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In2012 IEEE conference on computer vision and pat- tern recognition, pages 3354–3361. IEEE, 2012. 2
2012
-
[12]
Multi-modal sensor fusion for auto driving perception: A survey,
Keli Huang, Botian Shi, Xiang Li, Xin Li, Siyuan Huang, and Yikang Li. Multi-modal sensor fusion for auto driv- ing perception: A survey.arXiv preprint arXiv:2202.02703,
-
[13]
Depth Camera D435i Specifications
Intel RealSense. Depth Camera D435i Specifications. https : / / www . intel . com / content / www / us / en/products/sku/190004/intel- realsense- depth - camera - d435i / specifications . html, n.d. 4
-
[14]
Optical non-line-of-sight physics-based 3d human pose estimation
Mariko Isogawa, Ye Yuan, Matthew O’Toole, and Kris M Ki- tani. Optical non-line-of-sight physics-based 3d human pose estimation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7013–7022,
-
[15]
Mitsuba 3 renderer, 2022.https://mitsuba-renderer.org
Wenzel Jakob, S ´ebastien Speierer, Nicolas Roussel, Merlin Nimier-David, Delio Vicini, Tizian Zeltner, Baptiste Nicolet, Miguel Crespo, Vincent Leroy, and Ziyi Zhang. Mitsuba 3 renderer, 2022.https://mitsuba-renderer.org. 5, 8
2022
-
[16]
Looking around the corner using transient imaging
Ahmed Kirmani, Tyler Hutchison, James Davis, and Ramesh Raskar. Looking around the corner using transient imaging. In2009 IEEE 12th International Conference on Computer Vision, pages 159–166. IEEE, 2009. 3
2009
-
[17]
Pointpillars: Fast encoders for object detection from point clouds
Alex H Lang, Sourabh V ora, Holger Caesar, Lubing Zhou, Jiong Yang, and Oscar Beijbom. Pointpillars: Fast encoders for object detection from point clouds. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12697–12705, 2019. 2
2019
-
[18]
Nlost: Non-line-of-sight imaging with transformer
Yue Li, Jiayong Peng, Juntian Ye, Yueyi Zhang, Feihu Xu, and Zhiwei Xiong. Nlost: Non-line-of-sight imaging with transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13313– 13322, 2023. 3
2023
-
[19]
Toward dynamic non-line-of- sight imaging with mamba enforced temporal consistency
Yue Li, Yi Sun, Shida Sun, Juntian Ye, Yueyi Zhang, Feihu Xu, and Zhiwei Xiong. Toward dynamic non-line-of- sight imaging with mamba enforced temporal consistency. Advances in Neural Information Processing Systems, 37: 126452–126473, 2024. 3
2024
-
[20]
Hand- held mapping of specular surfaces using consumer-grade flash lidar
Tsung-Han Lin, Connor Henley, Siddharth Somasundaram, Akshat Dave, Moshe Laifenfeld, and Ramesh Raskar. Hand- held mapping of specular surfaces using consumer-grade flash lidar. In2024 IEEE International Conference on Com- putational Photography (ICCP), pages 1–12. IEEE, 2024. 2
2024
-
[21]
Towards 3d vision with low-cost single-photon cameras
Fangzhou Mu, Carter Sifferman, Sacha Jungerman, Yiquan Li, Mark Han, Michael Gleicher, Mohit Gupta, and Yin Li. Towards 3d vision with low-cost single-photon cameras. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 5302–5311, 2024. 2, 3
2024
-
[22]
A light transport model for mitigating multipath interference in time-of-flight sensors
Nikhil Naik, Achuta Kadambi, Christoph Rhemann, Shahram Izadi, Ramesh Raskar, and Sing Bing Kang. A light transport model for mitigating multipath interference in time-of-flight sensors. InProceedings of the IEEE Con- ference on Computer Vision and Pattern Recognition, pages 73–81, 2015. 2
2015
-
[23]
A review of single-photon avalanche diode time-of-flight imaging sensor arrays.IEEE Sensors Journal, 21(11):12654–12666, 2020
Franc ¸ois Piron, Daniel Morrison, Mehmet Rasit Yuce, and Jean-Michel Redout´e. A review of single-photon avalanche diode time-of-flight imaging sensor arrays.IEEE Sensors Journal, 21(11):12654–12666, 2020. 2
2020
-
[24]
Computational imaging based on single-photon detection: a survey.Artificial Intelli- gence Review, 58(8):251, 2025
Yanyun Pu, Chengyuan Zhu, Gongxin Yao, Chao Li, Yu Pan, Kaixiang Yang, and Qinmin Yang. Computational imaging based on single-photon detection: a survey.Artificial Intelli- gence Review, 58(8):251, 2025. 2
2025
-
[25]
3d object detection for autonomous driving: A survey.Pattern Recognition, 130: 108796, 2022
Rui Qian, Xin Lai, and Xirong Li. 3d object detection for autonomous driving: A survey.Pattern Recognition, 130: 108796, 2022. 2
2022
-
[26]
Automotive lidar technology: A survey.IEEE Transactions on Intelligent Transportation Systems, 23(7):6282–6297, 2021
Ricardo Roriz, Jorge Cabral, and Tiago Gomes. Automotive lidar technology: A survey.IEEE Transactions on Intelligent Transportation Systems, 23(7):6282–6297, 2021. 2
2021
-
[27]
mitran- sient: Transient light transport in mitsuba 3.arXiv preprint arXiv:2510.25660, 2025
Diego Royo, Jorge Garcia-Pueyo, Miguel Crespo, ´Oscar Pueyo-Ciutad, Guillermo Enguita, and Diego Bielsa. mitran- sient: Transient light transport in mitsuba 3.arXiv preprint arXiv:2510.25660, 2025. 8
-
[28]
All photons imaging through volumetric scattering
Guy Satat, Barmak Heshmat, Dan Raviv, and Ramesh Raskar. All photons imaging through volumetric scattering. Scientific reports, 6(1):33946, 2016. 2
2016
-
[29]
Towards photography through realistic fog
Guy Satat, Matthew Tancik, and Ramesh Raskar. Towards photography through realistic fog. In2018 IEEE Interna- tional Conference on Computational Photography (ICCP), pages 1–10. IEEE, 2018. 2
2018
-
[30]
Non-line-of- sight imaging via neural transient fields.IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(7):2257– 2268, 2021
Siyuan Shen, Zi Wang, Ping Liu, Zhengqing Pan, Ruiqian Li, Tian Gao, Shiying Li, and Jingyi Yu. Non-line-of- sight imaging via neural transient fields.IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(7):2257– 2268, 2021. 3
2021
-
[31]
Effi- cient detection of objects near a robot manipulator via minia- ture time-of-flight sensors.IEEE Robotics and Automation Letters, 2025
Carter Sifferman, Mohit Gupta, and Michael Gleicher. Effi- cient detection of objects near a robot manipulator via minia- ture time-of-flight sensors.IEEE Robotics and Automation Letters, 2025. 3
2025
-
[32]
Recovering parametric scenes from very few time-of-flight pixels
Carter Sifferman, Yiquan Li, Yiming Li, Fangzhou Mu, Michael Gleicher, Mohit Gupta, and Yin Li. Recovering parametric scenes from very few time-of-flight pixels. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 27989–27999, 2025. 3
2025
-
[33]
VL53L8CX Product Overview
STMicroelectronics. VL53L8CX Product Overview. https : / / www . st . com / en / imaging - and - photonics-solutions/vl53l8cx.html, n.d. 2, 3
-
[34]
Material classification using raw time-of-flight measure- ments
Shuochen Su, Felix Heide, Robin Swanson, Jonathan Klein, Clara Callenberg, Matthias Hullin, and Wolfgang Heidrich. Material classification using raw time-of-flight measure- ments. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3503–3511, 2016. 2
2016
-
[35]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2446–2454, 2020. 2
2020
-
[36]
Data-driven non-line-of-sight imaging with a tradi- tional camera
Matthew Tancik, Tristan Swedish, Guy Satat, and Ramesh Raskar. Data-driven non-line-of-sight imaging with a tradi- tional camera. InImaging Systems and Applications, pages IW2B–6. Optica Publishing Group, 2018. 3
2018
-
[37]
Apriltag: Detection and pose estimation li- brary for c, c++ and python.https://github.com/ Tinker-Twins/AprilTag, 2023
Tinker-Twins. Apriltag: Detection and pose estimation li- brary for c, c++ and python.https://github.com/ Tinker-Twins/AprilTag, 2023. Accessed: 2025-11-
2023
-
[38]
Recovering three-dimensional shape around a corner using ultrafast time-of-flight imaging.Nature communications, 3 (1):745, 2012
Andreas Velten, Thomas Willwacher, Otkrist Gupta, Ashok Veeraraghavan, Moungi G Bawendi, and Ramesh Raskar. Recovering three-dimensional shape around a corner using ultrafast time-of-flight imaging.Nature communications, 3 (1):745, 2012. 3
2012
-
[39]
arXiv preprint arXiv:2008.08063 (2020)
Xinshuo Weng, Jianren Wang, David Held, and Kris Kitani. Ab3dmot: A baseline for 3d multi-object tracking and new evaluation metrics.arXiv preprint arXiv:2008.08063, 2020. 2
-
[40]
Batagoda, Harry Zhang, Akshat Dave, Adithya Pediredla, Dan Negrut, and Ramesh Raskar
Aaron Young, Nevindu M. Batagoda, Harry Zhang, Akshat Dave, Adithya Pediredla, Dan Negrut, and Ramesh Raskar. Enhancing Autonomous Navigation by Imaging Hidden Ob- jects using Single-Photon LiDAR, 2025. arXiv:2410.03555 [cs]. 3
-
[41]
Lidar-based slam for robotic mapping: state of the art and new frontiers.Industrial Robot: the international journal of robotics research and applica- tion, 51(2):196–205, 2024
Xiangdi Yue, Yihuan Zhang, Jiawei Chen, Junxin Chen, Xu- anyi Zhou, and Miaolei He. Lidar-based slam for robotic mapping: state of the art and new frontiers.Industrial Robot: the international journal of robotics research and applica- tion, 51(2):196–205, 2024. 2
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.