Recognition: no theorem link
Annotation Entropy Predicts Per-Example Learning Dynamics in LoRA Fine-Tuning
Pith reviewed 2026-05-15 12:30 UTC · model grok-4.3
The pith
LoRA fine-tuning produces rising loss on high-annotator-disagreement examples, unlike full fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
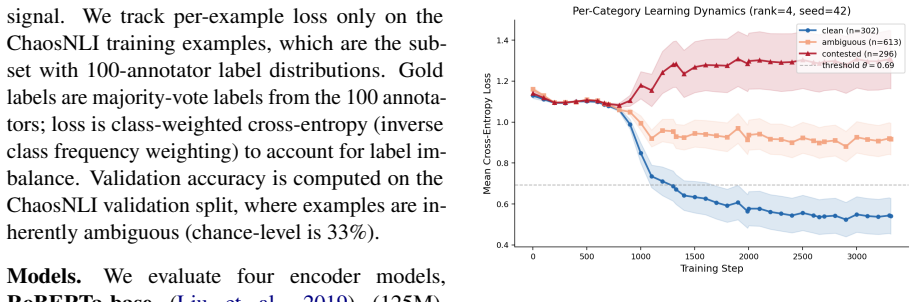
LoRA fine-tuning exhibits un-learning on contested examples: items with high annotator disagreement show increasing loss during training, a qualitatively distinct pattern largely absent under full fine-tuning and consistent across all six models tested (four encoder, two decoder-only). This discovery emerges from correlating annotation entropy, computed from ChaosNLI's 100 labels per example, with per-example area under the loss curve (AULC) on SNLI and MNLI.
What carries the argument
Annotation entropy, derived from the label distribution over 100 annotators per example, correlated with each example's area under the loss curve during adaptation.
If this is right
- Positive Spearman correlation between annotation entropy and AULC holds in every one of the 25 tested conditions.
- Decoder-only models display stronger correlations than encoder models at matched LoRA rank.
- The entropy-AULC relationship survives partial-correlation controls and replicates across random seeds and datasets.
- A noise-injection experiment produces loss trajectories consistent with the entropy-driven pattern.
Where Pith is reading between the lines
- Practitioners facing ambiguous labels may obtain more stable adaptation by switching from LoRA to full fine-tuning on the same data.
- The restricted parameter space of LoRA could make its updates more vulnerable to label noise than full-rank updates.
- Similar entropy-based diagnostics could be applied to other low-rank adaptation techniques to test whether the un-learning pattern generalizes beyond LoRA.
Load-bearing premise
The observed rise in loss on high-entropy items is produced by un-learning driven by annotation disagreement rather than by other training dynamics or dataset artifacts.
What would settle it
If a controlled experiment that equalizes annotator labels on the same examples eliminates the loss increase under LoRA while preserving the same training schedule, the claimed link between entropy and un-learning would be falsified.
Figures







read the original abstract
We find that LoRA fine-tuning exhibits un-learning on contested examples: items with high annotator disagreement show increasing loss during training, a qualitatively distinct pattern largely absent under full fine-tuning and consistent across all six models tested (four encoder, two decoder-only). This discovery emerges from correlating annotation entropy, computed from ChaosNLI's 100 labels per example, with per-example area under the loss curve (AULC) on SNLI and MNLI. The correlation is positive in all 25 conditions tested (Spearman $\rho = 0.06$-$0.43$), with decoder-only models showing stronger correlations than encoders at matched LoRA rank. The effect survives partial-correlation controls and replicates across seeds and datasets. A preliminary noise-injection experiment is consistent with these findings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LoRA fine-tuning on SNLI/MNLI exhibits a distinct 'un-learning' pattern on high-entropy examples from ChaosNLI: per-example area under the loss curve (AULC) shows positive Spearman correlations (ρ = 0.06–0.43) with annotation entropy across all 25 tested conditions, six models (four encoder, two decoder-only), and two datasets. This pattern is largely absent under full fine-tuning, survives partial-correlation controls, replicates across seeds, and is supported by a preliminary noise-injection check.
Significance. If the central empirical correlation holds, the work provides a concrete, replicable link between annotator disagreement and per-example loss dynamics that differentiates LoRA from full fine-tuning. This has potential value for understanding parameter-efficient adaptation, designing noise-robust training schedules, and prioritizing data curation for contested examples. The use of public ChaosNLI labels and standard loss curves makes the finding falsifiable and extensible.
major comments (3)
- [Experimental Setup / Methods] The manuscript reports consistent positive correlations but provides insufficient methodological detail on AULC computation (e.g., exact integration limits, handling of early-stopping or epoch boundaries), example exclusion criteria, and whether loss curves are normalized per example. These omissions are load-bearing for interpreting the reported ρ values and the 'un-learning' claim.
- [Results] The partial-correlation controls are described only at a high level; the specific covariates, the resulting controlled ρ values, and any multiple-testing correction are not reported. Without these numbers it is impossible to assess whether annotation entropy retains independent explanatory power over simpler proxies such as example length or initial loss.
- [Results / Figures] Error bars, confidence intervals, or per-condition p-values are absent from the correlation tables and figures. Given the modest effect sizes (ρ down to 0.06) and the claim of replication across 25 conditions, statistical characterization is required to evaluate robustness.
minor comments (2)
- [Experimental Setup] Decoder-only models are reported to show stronger correlations than encoders at matched LoRA rank, but the precise rank values, adapter placement, and learning-rate schedules used for each model family are not tabulated.
- [Results] The noise-injection experiment is described as 'preliminary' and 'consistent'; a brief quantitative summary (e.g., change in ρ after noise injection) would strengthen the causal interpretation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will revise the manuscript to provide the requested methodological clarifications, numerical details, and statistical characterizations.
read point-by-point responses
-
Referee: [Experimental Setup / Methods] The manuscript reports consistent positive correlations but provides insufficient methodological detail on AULC computation (e.g., exact integration limits, handling of early-stopping or epoch boundaries), example exclusion criteria, and whether loss curves are normalized per example. These omissions are load-bearing for interpreting the reported ρ values and the 'un-learning' claim.
Authors: We agree that the current description of AULC is insufficiently precise. In the revised manuscript we will add an explicit subsection in Methods that states: AULC is computed via trapezoidal integration of the raw per-example cross-entropy loss from the first to the final training step; training uses a fixed number of epochs with no early stopping; loss curves are not normalized per example; and example exclusion is limited to the small fraction of items that produce NaN losses after tokenization (reported in the appendix). These additions will directly support interpretation of the reported correlations. revision: yes
-
Referee: [Results] The partial-correlation controls are described only at a high level; the specific covariates, the resulting controlled ρ values, and any multiple-testing correction are not reported. Without these numbers it is impossible to assess whether annotation entropy retains independent explanatory power over simpler proxies such as example length or initial loss.
Authors: We will expand the partial-correlation section to list the exact covariates (sequence length in tokens, initial loss at epoch 0, and original SNLI/MNLI label entropy), report the controlled Spearman ρ values for each of the 25 conditions, and describe the multiple-testing correction applied. These numbers and the full procedure will appear in a new table and accompanying text in the revised Results. revision: yes
-
Referee: [Results / Figures] Error bars, confidence intervals, or per-condition p-values are absent from the correlation tables and figures. Given the modest effect sizes (ρ down to 0.06) and the claim of replication across 25 conditions, statistical characterization is required to evaluate robustness.
Authors: We acknowledge the absence of statistical detail in the current tables and figures. The revision will add 95% bootstrap confidence intervals (1,000 resamples) and per-condition p-values (with FDR correction) to all reported ρ values, and will include error bars on the relevant figures. This will allow readers to assess robustness given the observed effect-size range. revision: yes
Circularity Check
Empirical correlation with no self-referential derivation
full rationale
The paper reports an observed positive Spearman correlation between annotation entropy (computed directly from ChaosNLI's 100 labels per example) and per-example area under the loss curve (AULC) during LoRA fine-tuning on SNLI/MNLI. AULC is a standard integral of training loss trajectories with no fitted parameters or equations that reduce the reported statistic to its inputs by construction. The analysis replicates across models, datasets, and controls without invoking self-citations, uniqueness theorems, or ansatzes as load-bearing steps. The central claim is therefore a descriptive empirical pattern rather than a derived result that collapses to its own definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions underlying Spearman rank correlation and partial correlation controls
Reference graph
Works this paper leans on
-
[1]
Decoupling the Effect of Chain-of-Thought Reasoning: A Human Label Variation Perspective
LoRA learns less and forgets less.Transac- tions on Machine Learning Research (TMLR). Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D. Manning. 2015. A large anno- tated corpus for learning natural language inference. InProceedings of the Conference on Empirical Meth- ods in Natural Language Processing (EMNLP). Beiduo Chen, Tiancheng ...
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[2]
Suchin Gururangan, Swabha Swayamdipta, Omer Levy, Roy Schwartz, Samuel R
Robustness beyond known groups with low- rank adaptation.arXiv preprint arXiv:2602.06924. Suchin Gururangan, Swabha Swayamdipta, Omer Levy, Roy Schwartz, Samuel R. Bowman, and Noah A. Smith. 2018. Annotation artifacts in natural language inference data. InProceedings of the Conference of the North American Chapter of the Association for Computational Ling...
-
[3]
InProceedings of the 37th International Conference on Machine Learning (ICML)
Let’s agree to agree: Neural networks share classification order on real datasets. InProceedings of the 37th International Conference on Machine Learning (ICML). Pengcheng He, Jianfeng Gao, and Weizhu Chen
-
[4]
InProceedings of the International Conference on Learning Repre- sentations (ICLR)
DeBERTaV3: Improving DeBERTa us- ing ELECTRA-style pre-training with gradient- disentangled embedding sharing. InProceedings of the International Conference on Learning Repre- sentations (ICLR). Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-rank adaptation of large language m...
-
[5]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning. InAd- vances in Neural Information Processing Systems (NeurIPS). Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Man- dar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. RoBERTa: A robustly optimized BERT pretraining approach.arX...
work page internal anchor Pith review Pith/arXiv arXiv 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.