Training for Compositional Sensitivity Reduces Dense Retrieval Generalization
Pith reviewed 2026-05-15 09:41 UTC · model grok-4.3
The pith
Training dense retrievers to detect compositional edits reduces their zero-shot generalization on new datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
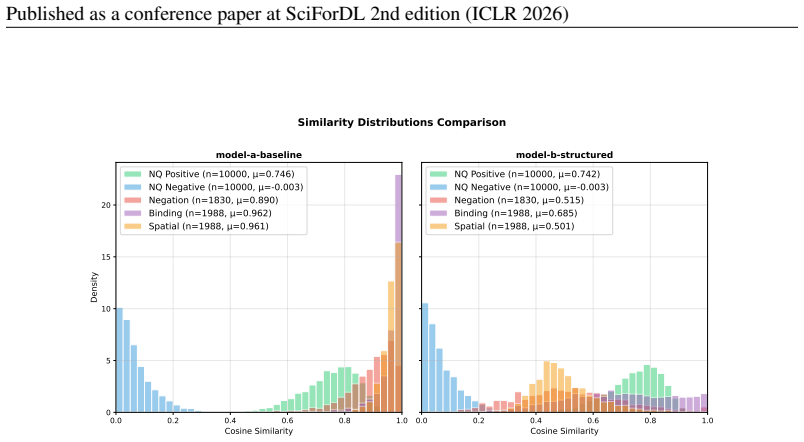
Across four dual-encoder backbones, adding structure-targeted negatives consistently reduces zero-shot NanoBEIR retrieval (8-9% mean nDCG@10 drop on small backbones; up to 40% on medium ones), while only partially improving pooled-space separation. Treating pooled cosine as a recall interface, verifiers scoring token-token cosine maps show that MaxSim excels at reranking but fails to reject structural near-misses, whereas a small Transformer over similarity maps reliably separates near-misses under end-to-end training.
What carries the argument
structure-targeted negatives that force dual encoders to distinguish compositional edits such as negation and role swaps
If this is right
- Dense retrieval remains brittle to identity-level meaning changes even after targeted training.
- Pooled cosine similarity works for initial recall but requires separate verification for compositional precision.
- MaxSim late-interaction reranking improves ranking yet cannot reject structural near-misses.
- A small transformer over token similarity maps separates structural near-misses when trained end-to-end.
Where Pith is reading between the lines
- Current embedding spaces appear to trade surface similarity useful for retrieval against deeper structural distinctions.
- Hybrid systems that keep dense retrieval for recall and add explicit structure checkers may avoid the observed generalization loss.
- Geometric properties derived for unit-sphere cosine spaces may not translate directly to the dynamics of trained text embeddings.
- Training objectives for robustness and generalization may need explicit balancing rather than sequential addition of negatives.
Load-bearing premise
That structure-targeted negatives increase compositional sensitivity without other side effects on the embedding space or training dynamics.
What would settle it
Finding no nDCG@10 drop on NanoBEIR when structure-targeted negatives are added under identical training budgets and data volume.
Figures


read the original abstract
Dense retrieval compresses texts into single embeddings ranked by cosine similarity. While efficient for recall, this interface is brittle for identity-level matching: minimal compositional edits (negation, role swaps) flip meaning yet retain high similarity. Motivated by geometric results for unit-sphere cosine spaces (Kang et al., 2025), we test this retrieval-composition tension in text-only retrieval. Across four dual-encoder backbones, adding structure-targeted negatives consistently reduces zero-shot NanoBEIR retrieval (8-9% mean nDCG@10 drop on small backbones; up to 40% on medium ones), while only partially improving pooled-space separation. Treating pooled cosine as a recall interface, we then benchmark verifiers scoring token--token cosine maps. MaxSim (late interaction) excels at reranking but fails to reject structural near-misses, whereas a small Transformer over similarity maps reliably separates near-misses under end-to-end training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that training dense dual-encoder retrievers with structure-targeted negatives to increase compositional sensitivity produces consistent drops in zero-shot NanoBEIR retrieval performance (8-9% mean nDCG@10 on small backbones, up to 40% on medium ones) across four backbones, while only partially improving pooled-space separation. It further shows that MaxSim late interaction fails to reject structural near-misses on similarity maps, whereas a small Transformer verifier succeeds under end-to-end training.
Significance. If the causal attribution holds, the work supplies concrete empirical evidence of a generalization-composition trade-off in cosine-based dense retrieval, extending geometric analyses of unit-sphere spaces to practical text encoders and motivating hybrid verification layers. The reproducible benchmark drops and verifier comparisons constitute a falsifiable prediction that can guide future training objectives.
major comments (2)
- [Abstract] Abstract: the central claim that structure-targeted negatives increase compositional sensitivity and thereby cause the reported NanoBEIR nDCG@10 drops is not supported by direct measurements; no results are shown on held-out edit sets (negation, role swaps) quantifying improved rejection of compositional near-misses before versus after training.
- [Abstract] Abstract: the assumption that geometric results for unit-sphere cosine spaces (Kang et al., 2025) transfer directly to trained text dual-encoders is used to motivate the experiment but receives no empirical check, such as measuring whether the learned embeddings remain in the regime where small edits produce large cosine changes.
minor comments (2)
- The four dual-encoder backbones should be named explicitly (model sizes, pre-training corpora) in the abstract or first experimental section to allow immediate assessment of the scale-dependent drops.
- The phrase 'partially improving pooled-space separation' is vague; a quantitative metric (e.g., margin between positive and compositional-negative pairs) should be reported alongside the qualitative statement.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that structure-targeted negatives increase compositional sensitivity and thereby cause the reported NanoBEIR nDCG@10 drops is not supported by direct measurements; no results are shown on held-out edit sets (negation, role swaps) quantifying improved rejection of compositional near-misses before versus after training.
Authors: We agree that direct before-and-after measurements on held-out compositional edit sets would provide stronger support for the increase in compositional sensitivity. The manuscript reports only partial improvement in pooled-space separation of structural variants after training, which is consistent with but does not directly quantify rejection of near-misses. We will add experiments measuring rejection rates on held-out negation and role-swap edit sets before versus after training. revision: yes
-
Referee: [Abstract] Abstract: the assumption that geometric results for unit-sphere cosine spaces (Kang et al., 2025) transfer directly to trained text dual-encoders is used to motivate the experiment but receives no empirical check, such as measuring whether the learned embeddings remain in the regime where small edits produce large cosine changes.
Authors: The geometric results from Kang et al. (2025) serve as motivation for expecting brittleness under compositional edits in cosine-based retrieval. While the observed NanoBEIR performance drops align with this intuition, we acknowledge the absence of a direct empirical check on whether the trained embeddings remain in the small-edit-large-cosine-change regime. We will include additional analysis measuring cosine sensitivity to small compositional edits in the learned embeddings before and after training. revision: yes
Circularity Check
No circularity: purely empirical benchmark study
full rationale
The manuscript reports training experiments on dual-encoder models with added structure-targeted negatives, followed by zero-shot evaluation on NanoBEIR and reranking benchmarks. No equations, derivations, or fitted parameters are used to generate the reported nDCG@10 drops; performance numbers are direct measurements from held-out test sets. The single external citation to Kang et al. 2025 supplies geometric motivation but is not invoked as a uniqueness theorem or to define any quantity inside the present results. All central claims remain falsifiable against external benchmarks and do not reduce to self-definition or self-citation chains.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Geometric results for unit-sphere cosine spaces (Kang et al., 2025) apply to the embedding spaces of text dual-encoder models.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
work page 1976
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.