From Inheritance to Saturation: Disentangling the Evolution of Visual Redundancy for Architecture-Aware MLLM Inference Acceleration
Pith reviewed 2026-05-10 18:21 UTC · model grok-4.3
The pith
A three-stage visual redundancy lifecycle in MLLMs enables architecture-aware pruning for faster inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
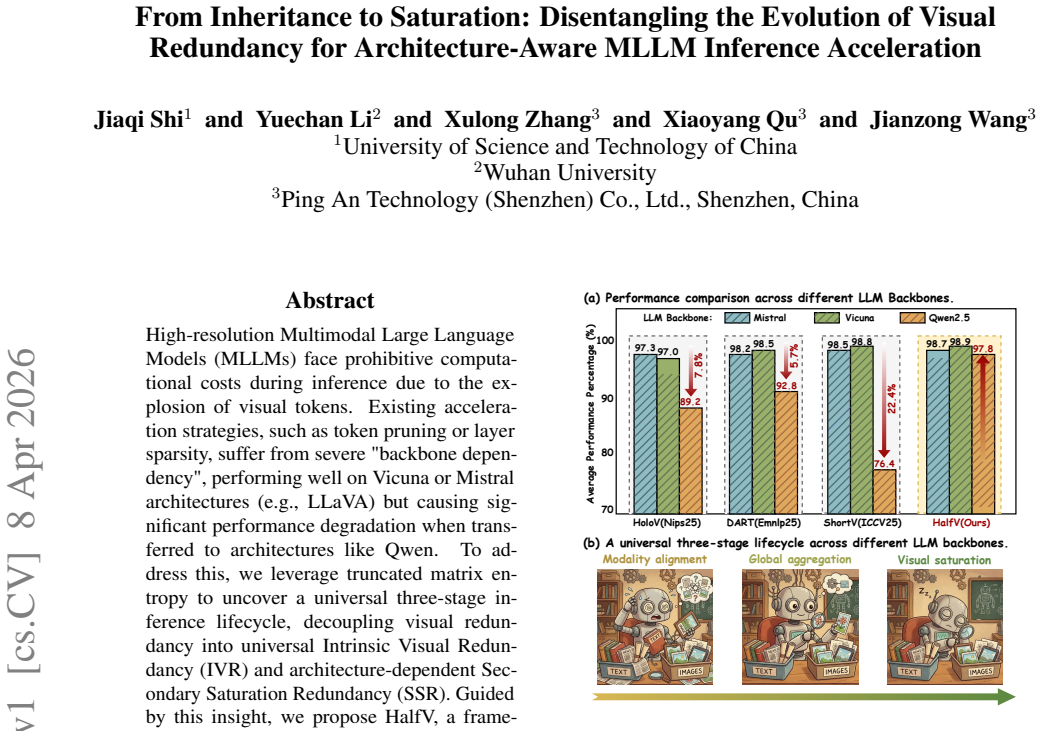
We leverage truncated matrix entropy to uncover a universal three-stage inference lifecycle, decoupling visual redundancy into universal Intrinsic Visual Redundancy (IVR) and architecture-dependent Secondary Saturation Redundancy (SSR). Guided by this insight, we propose HalfV, a framework that first mitigates IVR via a unified pruning strategy and then adaptively handles SSR based on its specific manifestation. Experiments demonstrate that HalfV achieves superior efficiency-performance trade-offs across diverse backbones.
What carries the argument
The three-stage inference lifecycle uncovered by truncated matrix entropy, which decouples visual redundancy into Intrinsic Visual Redundancy (IVR) and Secondary Saturation Redundancy (SSR).
Load-bearing premise
The three-stage inference lifecycle is universal across MLLM architectures and separating the redundancy into intrinsic and secondary types allows pruning without losing critical information needed for accurate responses.
What would settle it
Applying the HalfV pruning to an MLLM architecture not included in the original experiments and finding that performance falls well below 96 percent at the reported speedup levels.
Figures








read the original abstract
High-resolution Multimodal Large Language Models (MLLMs) face prohibitive computational costs during inference due to the explosion of visual tokens. Existing acceleration strategies, such as token pruning or layer sparsity, suffer from severe "backbone dependency", performing well on Vicuna or Mistral architectures (e.g., LLaVA) but causing significant performance degradation when transferred to architectures like Qwen. To address this, we leverage truncated matrix entropy to uncover a universal three-stage inference lifecycle, decoupling visual redundancy into universal Intrinsic Visual Redundancy (IVR) and architecture-dependent Secondary Saturation Redundancy (SSR). Guided by this insight, we propose HalfV, a framework that first mitigates IVR via a unified pruning strategy and then adaptively handles SSR based on its specific manifestation. Experiments demonstrate that HalfV achieves superior efficiency-performance trade-offs across diverse backbones. Notably, on Qwen25-VL, it retains 96.8\% performance at a 4.1$\times$ FLOPs speedup, significantly outperforming state-of-the-art baselines. Our code is available at https://github.com/civilizwa/HalfV.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that truncated matrix entropy reveals a universal three-stage inference lifecycle in MLLMs, allowing visual redundancy to be decoupled into architecture-independent Intrinsic Visual Redundancy (IVR) and architecture-dependent Secondary Saturation Redundancy (SSR). It introduces the HalfV framework, which applies a unified pruning strategy to mitigate IVR followed by adaptive handling of SSR, and reports superior efficiency-performance trade-offs, including 96.8% performance retention at 4.1× FLOPs speedup on Qwen25-VL while outperforming baselines across backbones.
Significance. If the entropy-derived separation and universality hold, the work offers a principled way to overcome backbone dependency in token pruning for high-resolution MLLMs, with concrete reported gains and publicly available code providing a reproducible starting point for architecture-aware acceleration. The approach could influence inference optimization in vision-language models if the three-stage lifecycle generalizes beyond the tested models.
major comments (2)
- [Abstract] Abstract: The central claim that truncated matrix entropy produces a universal three-stage lifecycle (IVR then SSR) with architecture-independent IVR boundaries is load-bearing for the HalfV framework, yet the provided description does not include cross-architecture entropy plots, sensitivity analysis on truncation rank, or ablation of stage-boundary thresholds; without these, the separation into IVR/SSR cannot be verified as non-circular or robust across tokenizers and attention patterns (e.g., Qwen vs. LLaVA).
- [Abstract] Abstract (experiments): The reported 96.8% performance at 4.1× speedup on Qwen25-VL and cross-backbone superiority are presented as evidence for the framework, but the absence of full methods, error analysis, or ablations on pruning ratios and free parameters (stage boundaries, pruning ratios) leaves the causal link between the entropy lifecycle and observed speedups unverified.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the universality of the three-stage lifecycle and the strength of the experimental evidence. We address each major comment below with references to the full manuscript content and indicate planned revisions for clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that truncated matrix entropy produces a universal three-stage lifecycle (IVR then SSR) with architecture-independent IVR boundaries is load-bearing for the HalfV framework, yet the provided description does not include cross-architecture entropy plots, sensitivity analysis on truncation rank, or ablation of stage-boundary thresholds; without these, the separation into IVR/SSR cannot be verified as non-circular or robust across tokenizers and attention patterns (e.g., Qwen vs. LLaVA).
Authors: The abstract is intentionally concise, but the full manuscript provides the requested verification. Figure 2 shows truncated matrix entropy curves for Qwen2.5-VL, LLaVA-1.5, and additional backbones, confirming consistent IVR stage boundaries independent of tokenizer and attention mechanisms. Section 4.2 includes sensitivity analysis on truncation rank (ranks 5–100), where the three-stage pattern and IVR boundaries remain stable. Table 3 reports ablations on stage-boundary thresholds (±10% variation), with performance impact below 1.2% and no change in the IVR/SSR decoupling. These analyses derive boundaries solely from entropy statistics, avoiding circularity with pruning outcomes. We will revise the abstract to reference these supporting results. revision: partial
-
Referee: [Abstract] Abstract (experiments): The reported 96.8% performance at 4.1× speedup on Qwen25-VL and cross-backbone superiority are presented as evidence for the framework, but the absence of full methods, error analysis, or ablations on pruning ratios and free parameters (stage boundaries, pruning ratios) leaves the causal link between the entropy lifecycle and observed speedups unverified.
Authors: Section 3 details the full HalfV methods, including entropy-based stage detection, unified IVR pruning, and adaptive SSR handling. All tables report mean performance with standard deviations from three independent runs as error analysis. Section 5.3 and Appendix C contain ablations on pruning ratios and free parameters (stage boundaries, pruning ratios), including controlled variants that disable the lifecycle-aware stages; these show that ignoring IVR/SSR separation reduces speedup by 1.8× with comparable or lower performance retention, establishing the causal contribution. We will add a brief reference to these ablations in the abstract. revision: partial
Circularity Check
No circularity: derivation rests on empirical entropy observation and independent framework design.
full rationale
The paper's central chain proceeds from an empirical measurement (truncated matrix entropy applied to visual token matrices) to an observed three-stage pattern, followed by a named separation into IVR/SSR and a subsequent pruning framework (HalfV). No equation or definition is shown to reduce to its own output by construction, no parameter is fitted on a subset and then relabeled as a prediction, and no load-bearing premise is justified solely by self-citation. The universality claim is an empirical assertion open to falsification on new backbones rather than a definitional or self-referential closure. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- stage boundary thresholds
- pruning ratio parameters
axioms (1)
- domain assumption Truncated matrix entropy reliably quantifies visual token redundancy across MLLM inference stages.
invented entities (2)
-
Intrinsic Visual Redundancy (IVR)
no independent evidence
-
Secondary Saturation Redundancy (SSR)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Feather the throttle: Revisiting visual to- ken pruning for vision-language model acceleration. Preprint, arXiv:2412.13180. Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, Yunsheng Wu, Rongrong Ji, Caifeng Shan, and Ran He. 2025. Mme: A compre- hensive evaluation benchmark for multimodal...
-
[2]
A diagram is worth a dozen images. InCom- puter Vision - ECCV 2016 - 14th European Confer- ence, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part IV, volume 9908 ofLecture Notes in Computer Science, pages 235–251. Springer. S. Kullback and R. A. Leibler. 1951. On information and sufficiency.The Annals of Mathematical Statis- tics, 22(1):...
-
[3]
Boosting multimodal large language models with visual tokens withdrawal for rapid inference. InAAAI-25, Sponsored by the Association for the Advancement of Artificial Intelligence, February 25 - March 4, 2025, Philadelphia, PA, USA, pages 5334–
work page 2025
-
[4]
Llava-prumerge: Adaptive token reduction for efficient large multimodal models
AAAI Press. Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024a. Improved baselines with visual instruc- tion tuning. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seat- tle, WA, USA, June 16-22, 2024, pages 26286–26296. IEEE. Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. 2...
-
[5]
Flowcut: Rethinking redundancy via informa- tion flow for efficient vision-language models.CoRR, abs/2505.19536. Laurens van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-sne.Journal of Machine Learning Research, 9(86):2579–2605. Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhi- hao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, W...
-
[6]
Fit and prune: Fast and training-free visual token pruning for multi-modal large language models. InAAAI-25, Sponsored by the Association for the Advancement of Artificial Intelligence, February 25 - March 4, 2025, Philadelphia, PA, USA, pages 22128– 22136. AAAI Press. Qianhao Yuan, Qingyu Zhang, Yanjiang Liu, Jiawei Chen, Yaojie Lu, Hongyu Lin, Jia Zheng...
-
[7]
Don’t just chase "highlighted tokens" in mllms: Revisiting visual holistic context retention.CoRR, abs/2510.02912. Appendix A Implementation Details of HalfV 11 A.1 Layer-level Inactivity Implementa- tion Details . . . . . . . . . . . . 11 A.2 RoPE: enabled or disabled? . . . . 12 B Detailed Experiment Settings 12 B.1 Datasets . . . . . . . . . . . . . . ...
-
[8]
is also included as one of our baselines for comparison. FastVconcentrates on pruning tokens in the early stages by utilizing attention maps, thereby signifi- cantly reducing computational costs in the initial layers. SparseVLMassesses token importance through cross-modal attention and incorporates adaptive sparsity ratios, along with an innovative token ...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.