Recognition: unknown
Spike-driven Large Language Model
Pith reviewed 2026-05-10 15:25 UTC · model grok-4.3
The pith
A spike-driven large language model replaces dense matrix multiplications with sparse additions while preserving task performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
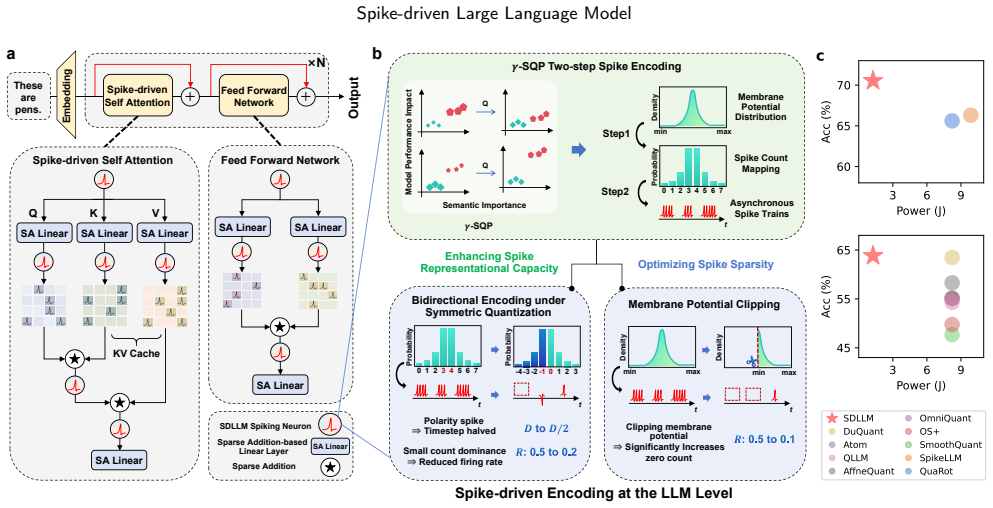
SDLLM is a spike-driven large language model that eliminates all dense matrix multiplications by relying solely on sparse addition operations. It achieves this through a plug-and-play gamma-SQP two-step spike encoding that keeps quantization aligned with semantic space, combined with bidirectional encoding, symmetric quantization, and membrane potential clipping to produce low-firing spike trains. Experiments show the resulting model reduces energy consumption by a factor of seven and raises accuracy by 4.2 percent relative to prior spike-based LLMs while attaining state-of-the-art performance under the spike-based paradigm.
What carries the argument
The gamma-SQP two-step spike encoding method, which aligns the quantization process with the model's semantic space to limit representation loss from binary spikes; it operates together with bidirectional encoding under symmetric quantization and membrane potential clipping to generate sparse spike trains with low or zero firing counts.
If this is right
- Inference energy drops sharply because every operation becomes a sparse addition instead of a dense multiplication.
- Spike-based models can now reach the parameter counts and task performance of conventional LLMs.
- The number of time steps is halved while the overall spike rate remains low, directly lowering latency and power.
- The architecture supplies a concrete template for designing next-generation event-driven neuromorphic chips.
Where Pith is reading between the lines
- The same encoding approach could be tested on non-LLM transformer models to check whether the efficiency gains generalize.
- Hardware simulators that count only sparse additions would be needed to verify the claimed energy numbers beyond software estimates.
- Extending the method to models with even larger parameter counts would test whether the semantic alignment still holds.
- Combining this spike scheme with other low-precision techniques might produce further reductions in both energy and time steps.
Load-bearing premise
The encoding schemes preserve the original LLM's semantic representational capacity at scale even after conversion to binary spikes.
What would settle it
A direct comparison on the same benchmarks where SDLLM accuracy falls below the non-spiking baseline by more than a few percent, or where measured energy on neuromorphic hardware fails to show the reported sevenfold reduction.
Figures





read the original abstract
Current Large Language Models (LLMs) are primarily based on large-scale dense matrix multiplications. Inspired by the brain's information processing mechanism, we explore the fundamental question: how to effectively integrate the brain's spiking-driven characteristics into LLM inference. Spiking Neural Networks (SNNs) possess spike-driven characteristics, and some works have attempted to combine SNNs with Transformers. However, achieving spike-driven LLMs with billions of parameters, relying solely on sparse additions, remains a challenge in the SNN field. To address the issues of limited representational capacity and sparsity in existing spike encoding schemes at the LLM level, we propose SDLLM, a spike-driven large language model that eliminates dense matrix multiplications through sparse addition operations. Specifically, we use the plug-and-play gamma-SQP two-step spike encoding method to ensure that the quantization process aligns with the model's semantic space, mitigating representation degradation caused by binary spikes. Furthermore, we introduce bidirectional encoding under symmetric quantization and membrane potential clipping mechanisms, leading to spike trains with no or low firing counts dominating, significantly reducing the model's spike firing rate, while halving the number of time steps. Experimental results show that SDLLM not only significantly reduces inference costs but also achieves state-of-the-art task performance under the spike-based paradigm. For example, compared to previous spike-based LLMs, SDLLM reduces energy consumption by 7x and improves accuracy by 4.2%. Our model provides inspiration for the architecture design of the next generation of event-driven neuromorphic chips.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SDLLM, a spike-driven large language model that replaces dense matrix multiplications with sparse additions by integrating spiking neural network principles. It proposes a gamma-SQP two-step spike encoding method to align quantization with semantic space and mitigate binary-spike degradation, combined with bidirectional encoding under symmetric quantization and membrane potential clipping to lower firing rates and halve time steps. The central experimental claim is that SDLLM achieves state-of-the-art task performance in the spike-based paradigm while reducing energy consumption by 7x and improving accuracy by 4.2% relative to prior spike-based LLMs.
Significance. If the performance and efficiency claims are rigorously validated, the work would represent a meaningful advance toward scalable, event-driven neuromorphic LLMs. It directly tackles the open problem of maintaining representational fidelity in billion-parameter SNN-Transformer hybrids, with potential implications for low-power inference hardware. The plug-and-play nature of the encoding and the reported sparsity gains are strengths that could influence subsequent architecture designs, provided the evidence for semantic preservation is strengthened.
major comments (2)
- [Abstract] Abstract: The reported gains (7x energy reduction and 4.2% accuracy improvement over previous spike-based LLMs) are presented without any description of the baselines, datasets, number of runs, statistical tests, or the precise metric used to quantify representation degradation. This absence leaves the central performance claims unsupported by visible evidence and prevents assessment of whether the results are load-bearing for the SOTA assertion.
- [Method] Proposed encoding method: The claim that the gamma-SQP two-step spike encoding plus bidirectional mechanisms and membrane clipping preserve semantic capacity at LLM scale without significant degradation rests on an unverified assumption. No direct supporting measurements (e.g., embedding cosine similarities, layer-wise KL divergence between dense and spike activations, or ablation removing the two-step process) are referenced, so it is unclear whether the alignment with semantic space actually holds or merely correlates with the observed gains.
minor comments (2)
- [Abstract] The abstract introduces the term 'gamma-SQP' without a brief inline definition or citation, which reduces immediate readability for readers outside the narrow SNN subfield.
- [Method] The description of 'spike trains with no or low firing counts dominating' would benefit from a quantitative definition (e.g., average firing rate threshold or histogram) to make the sparsity claim precise.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported gains (7x energy reduction and 4.2% accuracy improvement over previous spike-based LLMs) are presented without any description of the baselines, datasets, number of runs, statistical tests, or the precise metric used to quantify representation degradation. This absence leaves the central performance claims unsupported by visible evidence and prevents assessment of whether the results are load-bearing for the SOTA assertion.
Authors: We agree that the abstract would benefit from additional context on the experimental setup. In the revised manuscript we will expand the abstract to briefly specify the baselines (prior spike-based LLMs), the evaluation datasets (standard language-modeling and downstream NLP benchmarks), that results are averaged over multiple runs, and that energy is measured via average synaptic operations. Representation degradation is quantified by the observed task-accuracy difference relative to the dense model. Full details, including any statistical reporting, remain in the Experiments section; the abstract revision will make the central claims self-contained. revision: yes
-
Referee: [Method] Proposed encoding method: The claim that the gamma-SQP two-step spike encoding plus bidirectional mechanisms and membrane clipping preserve semantic capacity at LLM scale without significant degradation rests on an unverified assumption. No direct supporting measurements (e.g., embedding cosine similarities, layer-wise KL divergence between dense and spike activations, or ablation removing the two-step process) are referenced, so it is unclear whether the alignment with semantic space actually holds or merely correlates with the observed gains.
Authors: The primary evidence in the current manuscript is the end-to-end SOTA accuracy under the spike-based paradigm together with the measured reduction in firing rate. We acknowledge that direct metrics such as embedding cosine similarity or layer-wise KL divergence were not reported. In the revision we will add (1) an ablation that removes the two-step gamma-SQP component, (2) average cosine similarity between dense and spike-encoded embeddings on a held-out validation set, and (3) a short layer-wise comparison of activation distributions. These additions will supply the requested direct measurements of semantic alignment. revision: yes
Circularity Check
No significant circularity: claims rest on proposed encoding methods and reported experimental outcomes
full rationale
The paper proposes a new gamma-SQP two-step spike encoding, bidirectional mechanisms, and membrane clipping to enable spike-driven LLM inference. These are presented as novel plug-and-play components whose effectiveness is then validated through experiments showing energy reduction and accuracy gains. No derivation step reduces a claimed prediction or result to a fitted parameter or self-citation by construction; the central performance claims are tied to external benchmarks and ablation-style comparisons rather than being tautological with the inputs. The derivation chain is self-contained against the reported results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Spiking neural networks can approximate transformer computations at scale when provided with suitable spike encoding.
invented entities (2)
-
gamma-SQP two-step spike encoding method
no independent evidence
-
bidirectional encoding under symmetric quantization with membrane potential clipping
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Training verifiers to solve math word problems, in: Proceedings of the NeurIPS 2021 Datasets and Benchmarks Track (Round 1). Davies, M., Srinivasa, N., Lin, T.H., Chinya, G., Cao, Y., Choday, S.H., Dimou, G., Joshi, P., Imam, N., Jain, S., et al., 2018. Loihi: A neuromorphic manycore processor with on-chip learning. IEEE Micro 38, 82–99. Frenkel, C., Bol,...
-
[2]
https://download.intel.com/newsroom/2021/neuromorphic-computing -loihi-2-brief.pdf. Accessed: 2026-01-13. Li, Y., Deng, S., Dong, X., Gong, R., Gu, S., 2021. A free lunch from ann: Towards efficient, accurate spiking neural networks calibration, in: International conference on machine learning (ICML), PMLR. pp. 6316–6325. Lin, H., Xu, H., Wu, Y., Cui, J.,...
-
[3]
A million spiking-neuron integrated circuit with a scalable communication network and interface. Science 345, 668–673. Mirzadeh, S.I., Alizadeh-Vahid, K., Mehta, S., Mundo, C.C.d., Tuzel, O., Samei, G., Rastegari, M., Farajtabar, M., 2024. ReLU Strikes Back: Exploiting Activation Sparsity in Large Language Models, in: The Twelfth International Conference ...
work page internal anchor Pith review doi:10.48550/arxiv.2306.01116 2024
-
[4]
Omniquant: Omnidirectionally calibrated quantization for large language models
Opportunities for neuromorphic computing algorithms and ap- plications. Nature Computational Science 2, 10–19. doi: 10.1038/ s43588-021-00174-0. Shao,W.,Chen,M.,Zhang,Z.,Xu,P.,Zhao,L.,Li,Z.,Zhang,K.,Gao,P., Qiao,Y.,Luo,P.,2023. Omniquant:Omnidirectionallycalibratedquan- tization for large language models. arXiv preprint arXiv:2308.13137 . Shen, J., Ni, W....
-
[5]
Towards energy-preserving natural language understanding with spiking neural networks. IEEE/ACM Transactions on Audio, Speech, and Language Processing 31, 439–447. Xing,X.,Gao,B.,Zhang,Z.,Clifton,D.A.,Xiao,S.,Du,L.,Li,G.,Zhang, J.,2024a. Spikellm:Scalingupspikingneuralnetworktolargelanguage models via saliency-based spiking. arXiv preprint arXiv:2407.0475...
-
[6]
Lead federated neuromorphic learning for wireless edge artificial intelligence. Nature Communications 13. Yao, M., Hu, J., Hu, T., Xu, Y., Zhou, Z., Tian, Y., Li, G., 2024a. Spike- driven transformer v2: Meta spiking neural network architecture inspir- ing the design of next-generation neuromorphic chips. arXiv preprint arXiv:2404.03663 . Yao, M., Qiu, X....
-
[7]
to evaluate the performance of SDLLM under the membrane potential clipping method. We train on 8 A800 GPUs with approximately 10 million tokens and use the AdamWoptimizerwithafixedlearningrateof 1.5×10−5.To improve training efficiency and reduce memory consump- tion,weadopttheZeROStage2optimizationstrategy(Rajb- handari et al., 2020) provided by DeepSpeed...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.