Recognition: unknown
Dynamic Eraser for Guided Concept Erasure in Diffusion Models
Pith reviewed 2026-05-10 15:08 UTC · model grok-4.3
The pith
Dynamic Semantic Steering erases sensitive concepts in diffusion models with 91 percent success while preserving image fidelity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Dynamic Semantic Steering (DSS) introduces Sensitive Semantic Boundary Modeling to discover safe semantic anchors and Sensitive Semantic Guidance to detect sensitive content via cross-attention features and apply a closed-form correction from a well-posed objective. This suppresses sensitive content optimally while preserving benign semantics, leading to an average erasure rate of 91.0% that outperforms state-of-the-art methods from 18.6% to 85.9% with minimal impact on output fidelity.
What carries the argument
Sensitive Semantic Guidance (SSG), which performs precise detection using cross-attention features and correction via a closed-form solution derived from a well-posed objective to suppress sensitive content.
If this is right
- Concept erasure becomes more reliable and controllable in inference-time settings for diffusion models.
- The method maintains high output quality, avoiding the semantic drift common in prior correction approaches.
- Automation of safe anchor discovery reduces the need for manual intervention in concept removal tasks.
- Lightweight nature allows deployment without additional computational overhead from training.
Where Pith is reading between the lines
- Such steering could be adapted for other generative models beyond images, like audio or text.
- Future work might explore combining this with user-specified safety preferences for personalized generation.
- Evaluating performance on edge cases like ambiguous prompts could highlight strengths or gaps in the boundary modeling.
- The closed-form solution might inspire similar analytical fixes in other editing tasks within generative AI.
Load-bearing premise
That the Sensitive Semantic Boundary Modeling can reliably identify safe semantic anchors and the closed-form correction suppresses sensitive content without causing semantic drift or representation collapse in varied contexts.
What would settle it
A test set of prompts where applying the method results in either failed erasure (erasure rate below 50%) or visible semantic changes in non-sensitive elements of the generated images.
Figures



















read the original abstract
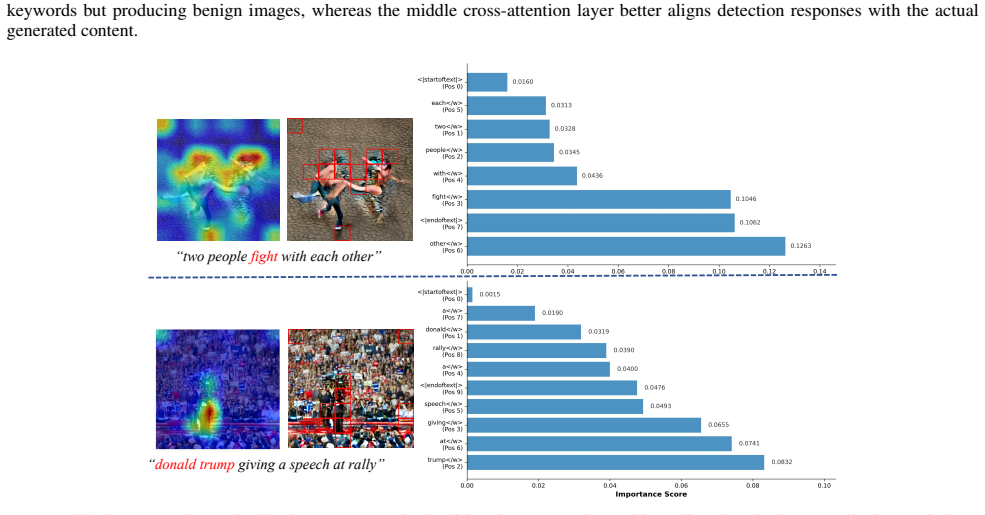
Concept erasure in Text-To-Image (T2I) diffusion models is vital for safe content generation, but existing inference-time methods face significant limitations. Feature-correction approaches often cause uncontrolled over-correction, while token-level interventions struggle with semantic granularity and context. Moreover, both types of methods are prone to severe semantic drift or even complete representation collapse. To address these challenges, we present Dynamic Semantic Steering (DSS), a lightweight, training-free framework for interpretable and controllable concept erasure. DSS introduces: 1) Sensitive Semantic Boundary Modeling (SSBM) to automate the discovery of safe semantic anchors, and 2) Sensitive Semantic Guidance (SSG), which leverages cross-attention features for precise detection and performs correction via a closed-form solution derived from a well-posed objective. This ensures optimal suppression of sensitive content while preserving benign semantics. DSS achieves an average erasure rate of 91.0\%, significantly outperforming SOTA methods (from 18.6\% to 85.9\%) with minimal impact on output fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Dynamic Semantic Steering (DSS), a lightweight training-free framework for concept erasure in text-to-image diffusion models. It introduces Sensitive Semantic Boundary Modeling (SSBM) to automate discovery of safe semantic anchors and Sensitive Semantic Guidance (SSG) that uses cross-attention features for detection followed by a closed-form correction derived from a well-posed objective. The central claim is that this achieves an average erasure rate of 91.0%, significantly outperforming SOTA methods (reported range 18.6% to 85.9%) while having minimal impact on output fidelity and avoiding semantic drift or representation collapse.
Significance. If the empirical results and the properties of the closed-form correction hold, the work would be significant for safe generative modeling by providing an interpretable inference-time alternative to training-based or over-correcting methods. The automation of anchor discovery via SSBM and the use of cross-attention for precise guidance represent potential strengths if they prove robust and generalizable.
major comments (3)
- Abstract: The central empirical claim of 91.0% average erasure rate and outperformance over SOTA (18.6% to 85.9%) with minimal fidelity impact is load-bearing but presented without any reference to datasets, metrics, baselines, number of trials, or error bars, preventing verification of the reported gains.
- Abstract / Method description: The closed-form solution for SSG is asserted to come from a well-posed objective that optimally suppresses sensitive content without drift or collapse, but no objective function, derivation steps, or equations are supplied, making it impossible to assess whether the correction is parameter-free or guaranteed to hold across timesteps and contexts.
- Abstract: The weakest assumption—that SSBM reliably identifies safe semantic anchors and SSG avoids representation collapse—is stated as solved by construction, yet no failure cases, ablation on anchor quality, or cross-prompt stability analysis is referenced, which is load-bearing for the claim of controllable erasure.
minor comments (1)
- Abstract: The acronyms SSBM and SSG are introduced without prior expansion of the full names on first use.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments identify key areas where the abstract and method overview can be strengthened for better verifiability and transparency. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract: The central empirical claim of 91.0% average erasure rate and outperformance over SOTA (18.6% to 85.9%) with minimal fidelity impact is load-bearing but presented without any reference to datasets, metrics, baselines, number of trials, or error bars, preventing verification of the reported gains.
Authors: We agree that the abstract, as a concise summary, should provide minimal context for the central claims to aid verification. In the revised version we will update the abstract to briefly reference the evaluation datasets (standard concept-erasure benchmarks), the metrics (erasure rate together with fidelity measures such as CLIP similarity), the SOTA baselines, and the fact that results are averaged over multiple prompts and random seeds with reported standard deviations. Full experimental details remain in Section 4. revision: yes
-
Referee: Abstract / Method description: The closed-form solution for SSG is asserted to come from a well-posed objective that optimally suppresses sensitive content without drift or collapse, but no objective function, derivation steps, or equations are supplied, making it impossible to assess whether the correction is parameter-free or guaranteed to hold across timesteps and contexts.
Authors: The objective function and its closed-form derivation are presented in Section 3.2 (Equations 3–6), where we formulate a quadratic program that minimizes deviation on sensitive cross-attention features subject to a fidelity constraint on benign features; the resulting linear system yields a parameter-free correction applied independently at each timestep. We will add an explicit pointer to these equations in both the abstract and the method overview paragraph so readers can locate the derivation immediately. revision: yes
-
Referee: Abstract: The weakest assumption—that SSBM reliably identifies safe semantic anchors and SSG avoids representation collapse—is stated as solved by construction, yet no failure cases, ablation on anchor quality, or cross-prompt stability analysis is referenced, which is load-bearing for the claim of controllable erasure.
Authors: Section 4.3 already contains quantitative ablations on anchor quality and cross-prompt stability, and the supplementary material shows qualitative failure cases. We will add explicit forward references to these results in the abstract and insert a short dedicated paragraph on limitations and observed failure modes to make the supporting evidence more visible. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The provided abstract and description present DSS as introducing SSBM for anchor discovery and SSG as a closed-form correction derived from a well-posed objective, with performance claims framed as direct empirical results rather than derived predictions. No equations, self-citations, or ansatz adoptions are quoted that reduce any load-bearing step to its own inputs by construction. The central claims remain independent of the reported metrics and do not exhibit self-definitional, fitted-input, or uniqueness-imported patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cross-attention features enable precise detection of sensitive semantics without drift
invented entities (2)
-
Sensitive Semantic Boundary Modeling (SSBM)
no independent evidence
-
Sensitive Semantic Guidance (SSG)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Not only text: Exploring compositionality of visual representations in vision-language models
Berasi, D., Farina, M., Mancini, M., Ricci, E., and Strisci- uglio, N. Not only text: Exploring compositionality of visual representations in vision-language models. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11- 15, 2025, pp. 24917–24927. Computer Vision Foundation / IEEE,
2025
-
[3]
P., and Lakkaraju, H
Bhalla, U., Oesterling, A., Srinivas, S., Calmon, F. P., and Lakkaraju, H. Interpreting CLIP with sparse linear con- cept embeddings (splice). In Globersons, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J. M., and Zhang, C. (eds.),Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing System...
2024
-
[4]
Multimodal datasets: misog- yny, pornography, and malignant stereotypes
Birhane, A., Prabhu, V . U., and Kahembwe, E. Multimodal datasets: misogyny, pornography, and malignant stereo- types.CoRR, abs/2110.01963,
-
[5]
Biswas, S. D., Roy, A., and Roy, K. CURE: concept un- learning via orthogonal representation editing in diffusion models.CoRR, abs/2505.12677,
-
[6]
Salun: Empowering machine unlearning via gradient- based weight saliency in both image classification and generation
Fan, C., Liu, J., Zhang, Y ., Wong, E., Wei, D., and Liu, S. Salun: Empowering machine unlearning via gradient- based weight saliency in both image classification and generation. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11,
2024
-
[7]
H., Chechik, G., and Cohen-Or, D
Gal, R., Alaluf, Y ., Atzmon, Y ., Patashnik, O., Bermano, A. H., Chechik, G., and Cohen-Or, D. An image is worth one word: Personalizing text-to-image generation using textual inversion. InThe Eleventh International Confer- ence on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5,
2023
-
[8]
Erasing concepts from diffusion models
Gandikota, R., Materzynska, J., Fiotto-Kaufman, J., and Bau, D. Erasing concepts from diffusion models. In IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pp. 2426–
2023
-
[9]
Unified concept editing in diffusion models
Gandikota, R., Orgad, H., Belinkov, Y ., Materzynska, J., and Bau, D. Unified concept editing in diffusion models. InIEEE/CVF Winter Conference on Applications of Com- puter Vision, WACV 2024, Waikoloa, HI, USA, January 3-8, 2024, pp. 5099–5108. IEEE,
2024
-
[10]
Eraseanything: Enabling concept erasure in rectified flow transformers
Gao, D., Lu, S., Zhou, W., Chu, J., Zhang, J., Jia, M., Zhang, B., Fan, Z., and Zhang, W. Eraseanything: Enabling concept erasure in rectified flow transformers. InForty- second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19,
2025
-
[11]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., and Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Guyon, I., von Luxburg, U., Bengio, S., Wallach, H. M., Fergus, R., Vishwanathan, S. V . N., and Garnett, R. (eds.),Advances in Neural Information Processing Systems 30: Annual Conference on Neura...
2017
-
[12]
Kim, G., Kwon, T., and Ye, J. C. Diffusionclip: Text- guided diffusion models for robust image manipulation. InIEEE/CVF Conference on Computer Vision and Pat- tern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pp. 2416–2425. IEEE,
2022
-
[13]
Ablating concepts in text-to-image dif- fusion models
Kumari, N., Zhang, B., Wang, S., Shechtman, E., Zhang, R., and Zhu, J. Ablating concepts in text-to-image dif- fusion models. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pp. 22634–22645. IEEE,
2023
-
[14]
One image is worth a thousand words: A usability preservable text-image collaborative erasing framework
Li, F., Xu, Q., Bao, S., Yang, Z., Cao, X., and Huang, Q. One image is worth a thousand words: A usability preservable text-image collaborative erasing framework. InForty- second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19,
2025
-
[15]
Li, F., Zhang, M., Sun, Y ., and Yang, M
OpenReview.net, 2025a. Li, F., Zhang, M., Sun, Y ., and Yang, M. Detect-and- guide: Self-regulation of diffusion models for safe text- to-image generation via guideline token optimization. In 9 Dynamic Eraser for Guided Concept Erasure in Diffusion Models IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 1...
-
[16]
Diffusion models for image restora- tion and enhancement: A comprehensive survey.Int
Li, X., Ren, Y ., Jin, X., Lan, C., Wang, X., Zeng, W., Wang, X., and Chen, Z. Diffusion models for image restora- tion and enhancement: A comprehensive survey.Int. J. Comput. Vis., 133(11):8078–8108, 2025d. Li, Y ., Zhang, Y ., Liu, S., and Lin, X. Pruning then reweight- ing: Towards data-efficient training of diffusion models. In2025 IEEE International ...
2025
-
[17]
Latent guard: A safety framework for text-to-image generation
Liu, R., Khakzar, A., Gu, J., Chen, Q., Torr, P., and Pizzati, F. Latent guard: A safety framework for text-to-image generation. In Leonardis, A., Ricci, E., Roth, S., Rus- sakovsky, O., Sattler, T., and Varol, G. (eds.),Computer Vision - ECCV 2024 - 18th European Conference, Mi- lan, Italy, September 29-October 4, 2024, Proceedings, Part XXVI, volume 150...
2024
-
[18]
Dpm-solver: A fast ODE solver for diffusion probabilis- tic model sampling in around 10 steps
Lu, C., Zhou, Y ., Bao, F., Chen, J., Li, C., and Zhu, J. Dpm-solver: A fast ODE solver for diffusion probabilis- tic model sampling in around 10 steps. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.),Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, Neu...
2022
-
[19]
Lu, S., Wang, Z., Li, L., Liu, Y ., and Kong, A. W. MACE: mass concept erasure in diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pp. 6430–6440. IEEE,
2024
-
[20]
Meng, Z., Peng, B., Jin, X., Jiang, Y ., Dong, J., and Wang, W. Dark miner: Defend against undesired generation for text-to-image diffusion models.CoRR, abs/2409.17682,
-
[21]
Q., Dhariwal, P., Ramesh, A., Shyam, P., Mishkin, P., McGrew, B., Sutskever, I., and Chen, M
Nichol, A. Q., Dhariwal, P., Ramesh, A., Shyam, P., Mishkin, P., McGrew, B., Sutskever, I., and Chen, M. GLIDE: towards photorealistic image generation and edit- ing with text-guided diffusion models. In Chaudhuri, K., Jegelka, S., Song, L., Szepesv´ari, C., Niu, G., and Sabato, S. (eds.),International Conference on Machine Learn- ing, ICML 2022, 17-23 Ju...
2022
-
[22]
W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., and Sutskever, I
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., and Sutskever, I. Learning transferable visual models from natural language supervision. In Meila, M. and Zhang, T. (eds.),Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Vir...
2021
-
[23]
An art-centric perspective on ai-based content moderation of nudity
Riccio, P., Curto, G., Hofmann, T., and Oliver, N. An art-centric perspective on ai-based content moderation of nudity. In Bue, A. D., Canton, C., Pont-Tuset, J., and Tommasi, T. (eds.),Computer Vision - ECCV 2024 Workshops - Milan, Italy, September 29-October 4, 2024, Proceedings, Part V, pp. 121–138. Springer,
2024
-
[24]
Version 1.4
URL https://github.com/CompVis/ stable-diffusion/blob/main/Stable_ Diffusion_v1_Model_Card.md. Version 1.4. Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. High-resolution image synthesis with latent diffusion models. InIEEE/CVF Conference on Com- puter Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pp....
2022
-
[25]
10 Dynamic Eraser for Guided Concept Erasure in Diffusion Models Schramowski, P., Tauchmann, C., and Kersting, K. Can machines help us answering question 16 in datasheets, and in turn reflecting on inappropriate content? InFAccT ’22: 2022 ACM Conference on Fairness, Accountability, and Transparency, Seoul, Republic of Korea, June 21 - 24, 2022, pp. 1350–1...
2022
-
[26]
Safe latent diffusion: Mitigating inappropriate degener- ation in diffusion models
Schramowski, P., Brack, M., Deiseroth, B., and Kersting, K. Safe latent diffusion: Mitigating inappropriate degener- ation in diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pp. 22522– 22531. IEEE,
2023
-
[27]
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
Schuhmann, C., Vencu, R., Beaumont, R., Kaczmarczyk, R., Mullis, C., Katta, A., Coombes, T., Jitsev, J., and Komat- suzaki, A. LAION-400M: open dataset of clip-filtered 400 million image-text pairs.CoRR, abs/2111.02114,
work page internal anchor Pith review arXiv
-
[28]
LAION-5B: an open large-scale dataset for training next generation image-text models
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., Schramowski, P., Kundurthy, S., Crow- son, K., Schmidt, L., Kaczmarczyk, R., and Jitsev, J. LAION-5B: an open large-scale dataset for training next generation image-text models. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, ...
2022
-
[29]
Efficient fine-tuning and concept suppres- sion for pruned diffusion models
Shirkavand, R., Yu, P., Gao, S., Somepalli, G., Goldstein, T., and Huang, H. Efficient fine-tuning and concept suppres- sion for pruned diffusion models. InIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pp. 18619– 18629. Computer Vision Foundation / IEEE,
2025
-
[30]
Attentive eraser: Unleashing diffusion model’s object removal potential via self-attention redirection guidance
Sun, W., Dong, X., Cui, B., and Tang, J. Attentive eraser: Unleashing diffusion model’s object removal potential via self-attention redirection guidance. In Walsh, T., Shah, J., and Kolter, Z. (eds.),AAAI-25, Sponsored by the As- sociation for the Advancement of Artificial Intelligence, February 25 - March 4, 2025, Philadelphia, PA, USA, pp. 20734–20742. ...
2025
-
[31]
Tsai, Y ., Hsu, C., Xie, C., Lin, C., Chen, J., Li, B., Chen, P., Yu, C., and Huang, C. Ring-a-bell! how reliable are concept removal methods for diffusion models? InThe Twelfth International Conference on Learning Represen- tations, ICLR 2024, Vienna, Austria, May 7-11,
2024
-
[32]
Precise, fast, and low-cost concept erasure in value space: Orthogonal complement matters
Wang, Y ., Li, O., Mu, T., Hao, Y ., Liu, K., Wang, X., and He, X. Precise, fast, and low-cost concept erasure in value space: Orthogonal complement matters. InIEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pp. 28759–28768. Computer Vision Foundation / IEEE,
2025
-
[33]
Univer- sal prompt optimizer for safe text-to-image generation
Wu, Z., Gao, H., Wang, Y ., Zhang, X., and Wang, S. Univer- sal prompt optimizer for safe text-to-image generation. In Duh, K., G´omez-Adorno, H., and Bethard, S. (eds.),Pro- ceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), NAACL 2024, Mexic...
2024
-
[34]
SAFREE: training-free and adaptive guard for safe text-to-image and video generation
Yoon, J., Yu, S., Patil, V ., Yao, H., and Bansal, M. SAFREE: training-free and adaptive guard for safe text-to-image and video generation. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28,
2025
-
[35]
Yuan, L., Li, X., Xu, C., Tao, G., Jia, X., Huang, Y ., Dong, W., Liu, Y ., Wang, X., and Li, B. Promptguard: Soft prompt-guided unsafe content moderation for text-to- image models.CoRR, abs/2501.03544,
work page internal anchor Pith review arXiv
-
[36]
To generate or not? safety-driven unlearned diffusion models are still easy to generate un- safe images
Zhang, Y ., Jia, J., Chen, X., Chen, A., Zhang, Y ., Liu, J., Ding, K., and Liu, S. To generate or not? safety-driven unlearned diffusion models are still easy to generate un- safe images ... for now. In Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., and Varol, G. (eds.),Com- puter Vision - ECCV 2024 - 18th European Conference, Milan, I...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.