Recognition: unknown
Geometry-Aware CLIP Retrieval via Local Cross-Modal Alignment and Steering
Pith reviewed 2026-05-10 16:25 UTC · model grok-4.3
The pith
CLIP retrieval improves when treated as local neighborhood alignment instead of pointwise similarity, using Hungarian re-ranking and query steering at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CLIP retrieval is typically framed as a pointwise similarity problem in a shared embedding space. While CLIP achieves strong global cross-modal alignment, many retrieval failures arise from local geometric inconsistencies: nearby items are incorrectly ordered, leading to systematic confusions and diffuse result sets. The work introduces neighborhood-level re-ranking via Hungarian matching, which rewards structural consistency, and query-conditioned local steering, where directions derived from contrastive neighborhoods around the query reshape retrieval. These techniques improve retrieval performance on attribute-binding and compositional retrieval tasks and show that retrieval quality and 0
What carries the argument
Neighborhood-level re-ranking via Hungarian matching to reward structural consistency, together with query-conditioned local steering that derives and applies direction vectors from contrastive neighborhoods to control local geometry.
If this is right
- Retrieval accuracy rises on attribute-binding tasks that require matching specific object properties.
- Retrieval accuracy rises on compositional tasks that combine multiple attributes or relations.
- Re-ranking rewards alignment while local steering separately controls neighborhood structure.
- Both methods run at inference time with no retraining or fine-tuning of the base CLIP model.
- Overall retrieval quality and controllability depend on exploiting local geometric structure in the embedding space.
Where Pith is reading between the lines
- The same local-alignment idea could be tested on other cross-modal models whose embeddings show similar neighborhood distortions.
- Steering neighborhoods might be combined with generative pipelines to make output sets more predictable without changing the generator.
- If local geometry fixes suffice for fine-grained tasks, then further scaling of global alignment may not be the only path to better retrieval.
- The distinction between rewarding alignment and controlling structure suggests a modular way to tune retrieval behavior per query type.
Load-bearing premise
Local geometric inconsistencies in the CLIP embedding space are the main source of retrieval failures, and they can be corrected by neighborhood alignment and steering without introducing new errors or degrading global alignment.
What would settle it
Applying the Hungarian re-ranking and local steering methods produces no gain or a loss in accuracy on attribute-binding and compositional tasks, or causes measurable degradation in global cross-modal alignment metrics.
Figures








read the original abstract
CLIP retrieval is typically framed as a pointwise similarity problem in a shared embedding space. While CLIP achieves strong global cross-modal alignment, many retrieval failures arise from local geometric inconsistencies: nearby items are incorrectly ordered, leading to systematic confusions (e.g., pentagon vs. hexagon) and produces diffuse, weakly controlled result sets. Prior work largely optimizes for point wise relevance or finetuning to mitigate these problems. We instead view retrieval as a problem of neighborhood alignment. Our work introduces (1) neighborhood-level re-ranking via Hungarian matching, which rewards structural consistency; (2) query-conditioned local steering, where directions derived from contrastive neighborhoods around the query reshape retrieval. We show that these techniques improve retrieval performance on attribute-binding and compositional retrieval tasks. Together, these methods operate on local neighborhoods but serve different roles: re-ranking rewards alignment whereas local steering controls neighborhood structure. This shows that retrieval quality and controllability depend critically on local structure, which can be exploited at inference time without retraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes viewing CLIP retrieval as a neighborhood alignment problem rather than pointwise similarity. It introduces two inference-time methods: (1) re-ranking via Hungarian matching on local neighborhoods to reward structural consistency, and (2) query-conditioned local steering using directions derived from contrastive neighborhoods to control the result set structure. The authors claim these techniques improve performance on attribute-binding and compositional retrieval tasks without retraining, highlighting the importance of local geometric structure in the embedding space.
Significance. If validated, the approach could provide a lightweight, training-free way to enhance retrieval quality and controllability in multimodal models by correcting local inconsistencies, which is significant for practical applications where fine-tuning is costly or undesirable. It shifts focus from global alignment to exploitable local geometry.
major comments (2)
- [Abstract] The abstract asserts that the techniques improve retrieval performance on attribute-binding and compositional retrieval tasks but supplies no quantitative results, baselines, ablation studies, or error analysis, leaving the central claim without visible empirical support.
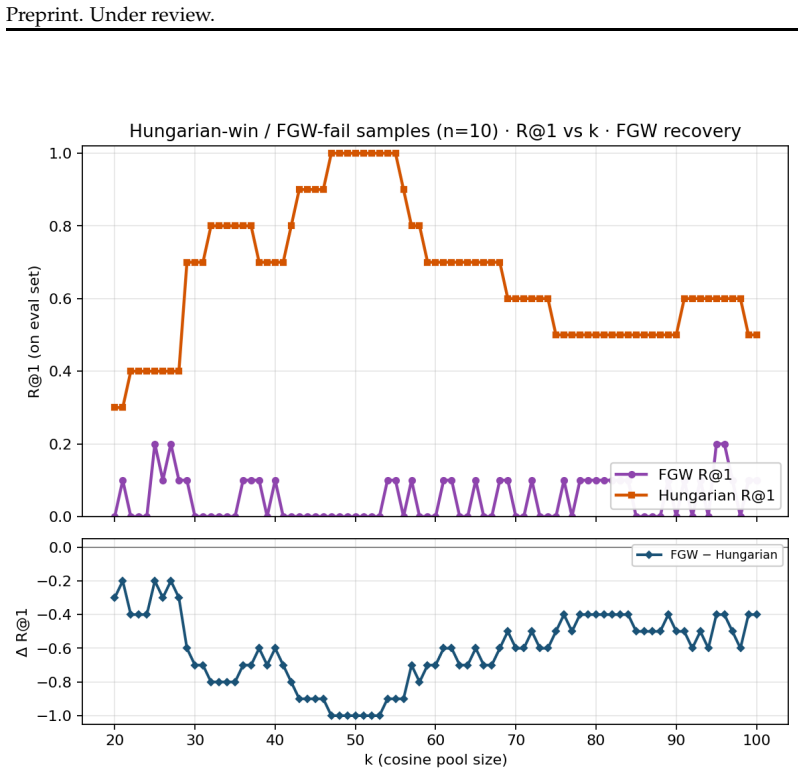
- [Methods (local steering and Hungarian re-ranking)] The central claim requires that contrastive neighborhoods around a query reliably encode true compositional structure. However, if the initial top-k retrieval has low precision (common in attribute-binding failures), the local operations may propagate errors rather than correct them, reinforcing incorrect orderings or introducing new confusions while preserving only superficial geometry. The manuscript does not analyze behavior under low-precision initial neighborhoods or verify preservation of global alignment.
minor comments (1)
- The abstract mentions 'pentagon vs. hexagon' as an example of confusion but does not elaborate on how the methods specifically address such geometric issues.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments on our manuscript. We address each major comment point by point below, providing clarifications on the empirical support and methodological assumptions while outlining planned revisions to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] The abstract asserts that the techniques improve retrieval performance on attribute-binding and compositional retrieval tasks but supplies no quantitative results, baselines, ablation studies, or error analysis, leaving the central claim without visible empirical support.
Authors: We agree that the abstract, being a concise summary, does not include specific quantitative details. The full manuscript contains the supporting experiments, including quantitative improvements on attribute-binding and compositional tasks, baseline comparisons, component ablations, and error analysis. To make the central claim more immediately supported, we will revise the abstract to briefly reference key quantitative results such as the observed gains in retrieval metrics. revision: yes
-
Referee: [Methods (local steering and Hungarian re-ranking)] The central claim requires that contrastive neighborhoods around a query reliably encode true compositional structure. However, if the initial top-k retrieval has low precision (common in attribute-binding failures), the local operations may propagate errors rather than correct them, reinforcing incorrect orderings or introducing new confusions while preserving only superficial geometry. The manuscript does not analyze behavior under low-precision initial neighborhoods or verify preservation of global alignment.
Authors: This concern about error propagation in low-precision initial neighborhoods is valid and merits explicit discussion. Our approach relies on contrastive neighborhoods to extract structural directions even when the initial set mixes relevant and irrelevant items, and the reported experiments show that both re-ranking and steering improve local consistency while maintaining or enhancing standard retrieval metrics. Nevertheless, the manuscript does not include a dedicated robustness study for very low initial precision or explicit verification of global alignment preservation. We will add this analysis, including controlled experiments with degraded initial retrievals and before/after comparisons of global metrics such as mean average precision. revision: yes
Circularity Check
No significant circularity; methods are standard inference-time procedures
full rationale
The paper introduces neighborhood re-ranking via Hungarian matching and query-conditioned local steering as inference-time operations on CLIP embeddings. These rely on the standard Hungarian algorithm for bipartite matching and derived steering vectors from contrastive neighborhoods, without any equations, fitted parameters, or derivations that reduce to the inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing for the central claims. The improvements are presented as empirical outcomes of applying these known techniques to local geometry, making the derivation chain self-contained against external benchmarks like standard matching algorithms.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption CLIP provides a shared embedding space in which cross-modal similarity is captured by proximity
- domain assumption Local neighborhoods in the embedding space encode semantically meaningful structure
- domain assumption Hungarian matching can be used to align neighborhoods without distorting global relevance
Reference graph
Works this paper leans on
-
[1]
Mothilal Asokan, Kebin Wu, and Fatima Albreiki. Finelip: Extending clip’s reach via fine-grained alignment with longer text inputs.arXiv preprint arXiv:2504.01916,
-
[2]
A clip-hitchhiker’s guide to long video retrieval.arXiv preprint arXiv:2205.08508,
Max Bain, Arsha Nagrani, G ¨ul Varol, and Andrew Zisserman. A clip-hitchhiker’s guide to long video retrieval.arXiv preprint arXiv:2205.08508,
-
[3]
Attribute diversity determines the systematicity gap in vqa
Ian Berlot-Attwell, Kumar Krishna Agrawal, Annabelle Michael Carrell, Yash Sharma, and Naomi Saphra. Attribute diversity determines the systematicity gap in vqa. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 9576–9611,
2024
-
[4]
Fabian Gr¨oger, Shuo Wen, and Maria Brbi´c. Revisiting the platonic representation hypothe- sis: An aristotelian view.arXiv preprint arXiv:2602.14486, 2026a. Fabian Gr¨oger, Shuo Wen, and Maria Brbi´c. Revisiting the platonic representation hypothe- sis: An aristotelian view.arXiv preprint arXiv:2602.14486, 2026b. Geonmo Gu, Sanghyuk Chun, Wonjae Kim, Yoo...
-
[5]
Seeing through words, speaking through pixels: Deep representational alignment between vision and language models
Zoe Wanying He, Sean Trott, and Meenakshi Khosla. Seeing through words, speaking through pixels: Deep representational alignment between vision and language models. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (eds.),Proceedings of the 2025 Conference on Empirical Methods in Natural Language Process- ing, pp. 35657–356...
2025
-
[6]
Association for Computational Linguistics. ISBN 979-8-89176-332-6. doi: 10.18653/v1/2025.emnlp-main.1806. URL https://aclanthology.org/2025.emnlp-main.1806/. Cheng-Yu Hsieh, Jieyu Zhang, Zixian Ma, Aniruddha Kembhavi, and Ranjay Krishna. Sugarcrepe: Fixing hackable benchmarks for vision-language compositionality.Advances in neural information processing s...
-
[7]
Hailang Huang, Zhijie Nie, Ziqiao Wang, and Ziyu Shang. Cross-modal and uni-modal soft-label alignment for image-text retrieval.arXiv preprint arXiv:2403.05261,
-
[8]
The Platonic Representation Hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. The platonic representa- tion hypothesis.arXiv preprint arXiv:2405.07987,
-
[9]
Zheyuan Liu, Weixuan Sun, Damien Teney, and Stephen Gould. Candidate set re-ranking for composed image retrieval with dual multi-modal encoder.arXiv preprint arXiv:2305.16304,
-
[10]
Jianglin Lu, Simon Jenni, Kushal Kafle, Jing Shi, Handong Zhao, and Yun Fu. Seeing through words: Controlling visual retrieval quality with language models.arXiv preprint arXiv:2602.21175,
-
[11]
Quari: Query adaptive retrieval improvement.arXiv preprint arXiv:2505.21647,
Eric Xing, Abby Stylianou, Robert Pless, and Nathan Jacobs. Quari: Query adaptive retrieval improvement.arXiv preprint arXiv:2505.21647,
-
[12]
Wenliang Zhong, Weizhi An, Feng Jiang, Hehuan Ma, Yuzhi Guo, and Junzhou Huang. Compositional image retrieval via instruction-aware contrastive learning.arXiv preprint arXiv:2412.05756,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.