Medical thinking with multiple images
Pith reviewed 2026-05-10 14:51 UTC · model grok-4.3
The pith
AI models fail at medical diagnosis with multiple images because they cannot reliably extract, align, and combine evidence across views.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the dominant failure mode in multi-image medical reasoning is not insufficient reasoning length but the absence of reliable mechanisms for grounding, aligning, and composing distributed visual evidence, shown by the error distribution in the expert-annotated benchmark and by the differential effect of providing versus withholding human-provided cross-view summaries.
What carries the argument
MedThinkVQA benchmark with its dense multi-image cases, expert step-level labels, and controlled provision of single-image cues versus model-generated intermediates that isolate the grounding bottleneck.
If this is right
- Providing expert single-image cues and cross-image summaries raises accuracy while self-generated intermediates lower it.
- Additional inference-time computation improves results only after visual grounding is already reliable.
- When early evidence extraction is weak, longer reasoning chains yield limited or unstable gains and can amplify initial misreads.
- Even the strongest current models remain far below expert levels on cases that require dense cross-view integration.
Where Pith is reading between the lines
- Progress will likely require new model components that explicitly perform cross-view alignment before higher-level reasoning begins.
- The same grounding difficulties may appear in other multi-view clinical tasks such as longitudinal imaging or multi-modal pathology slides.
- Training regimes that use step-level visual supervision could be tested on existing single-image medical benchmarks to measure transfer.
- Dataset creators in adjacent domains could adopt similar dense-image, step-labeled designs to quantify grounding failures.
Load-bearing premise
The expert annotations and step-level labels accurately capture genuine clinical reasoning demands rather than reflecting artifacts from dataset construction or evaluation design.
What would settle it
A follow-up experiment in which every model is given perfect expert single-image interpretations and explicit cross-view alignments, after which diagnostic accuracy remains below 70 percent or the original 70-plus percent error share in image reading does not shrink substantially.
Figures



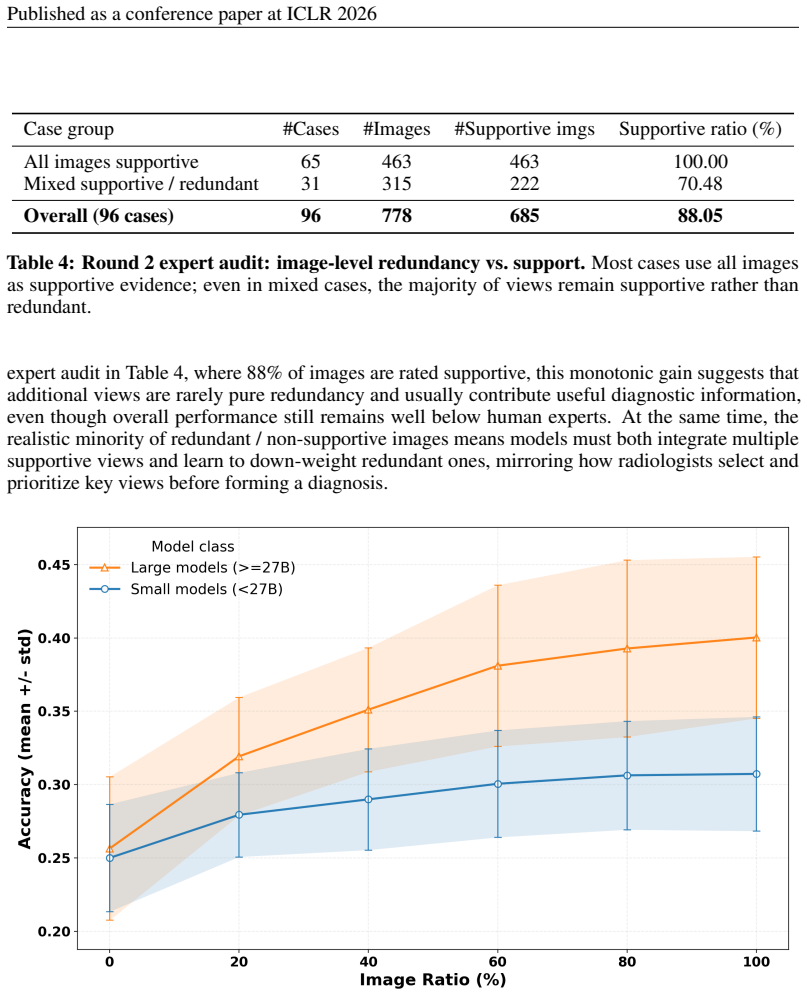






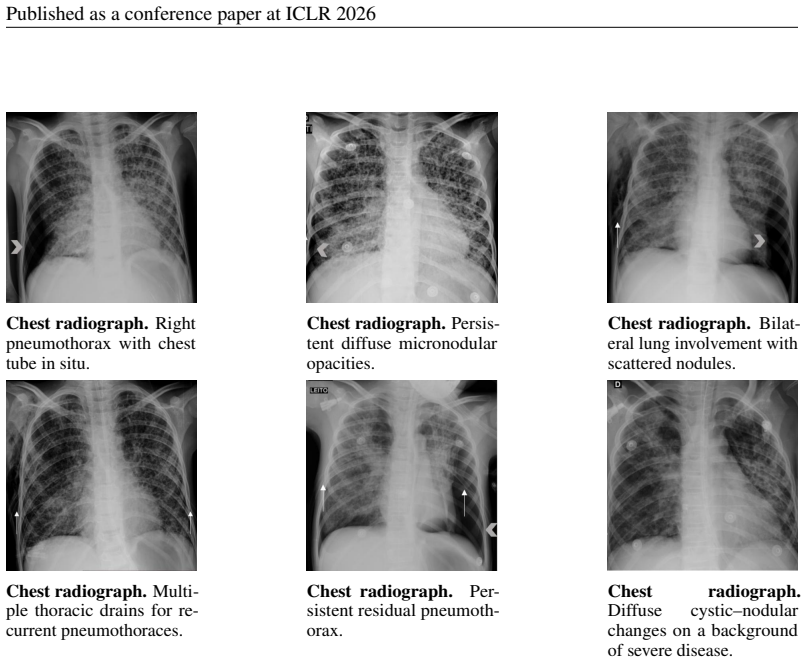
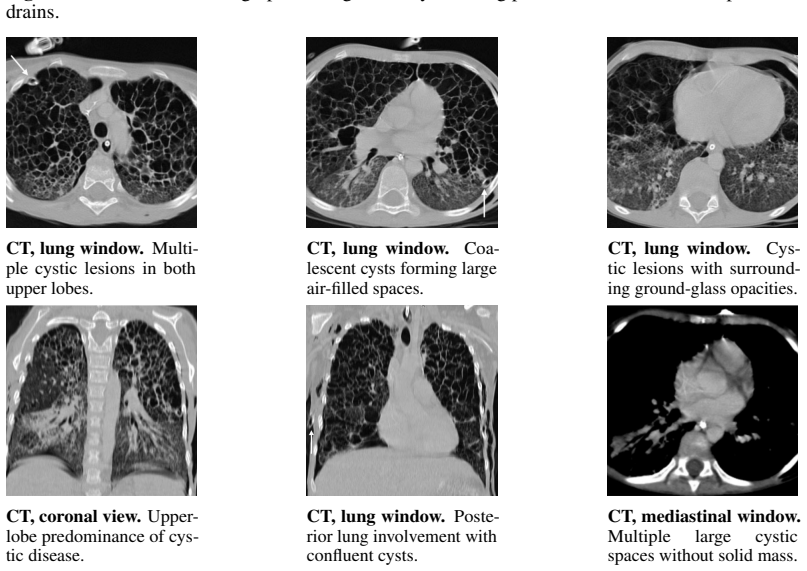


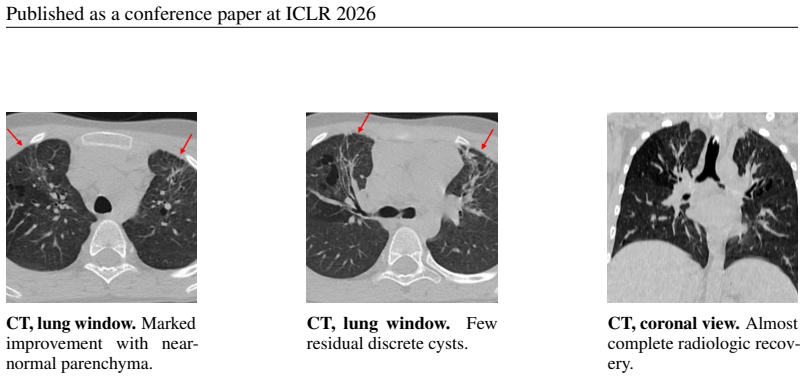



read the original abstract
Large language models perform well on many medical QA benchmarks, but real clinical reasoning often requires integrating evidence across multiple images rather than interpreting a single view. We introduce MedThinkVQA, an expert-annotated benchmark for thinking with multiple images, where models must interpret each image, combine cross-view evidence, and answer diagnostic questions with intermediate supervision and step-level evaluation. The dataset contains 8,067 cases, including 720 test cases, with an average of 6.62 images per case, substantially denser than prior work, whose expert-level benchmarks use at most 1.43 images per case. On the test set, the best closed-source models, Claude-4.6-Opus, Gemini-3-Pro, and GPT-5.2-xhigh, reach only 57.2%, 55.3%, and 54.9% accuracy, while GPT-5-mini and GPT-5-nano reach 39.7% and 30.8%. Strong open-source models lag behind, led by Qwen3.5-397B-A17B at 52.2% and Qwen3.5-27B at 50.6%. Further analysis identifies grounded multi-image reasoning as the main bottleneck: models often fail to extract, align, and compose evidence across views before higher-level inference can help. Providing expert single-image cues and cross-image summaries improves performance, whereas replacing them with self-generated intermediates reduces accuracy. Step-level analysis shows that over 70% of errors arise from image reading and cross-view integration. Scaling results further show that additional inference-time computation helps only when visual grounding is already reliable; when early evidence extraction is weak, longer reasoning yields limited or unstable gains and can amplify misread cues. These results suggest that the key challenge is not reasoning length alone, but reliable mechanisms for grounding, aligning, and composing distributed evidence across real-world multimodal clinical inputs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MedThinkVQA, an expert-annotated benchmark for medical visual question answering that requires integrating evidence across multiple images (average 6.62 images per case in 8,067 total cases, 720 in the test set). It evaluates closed- and open-source LLMs on diagnostic questions with intermediate supervision, reports top accuracies of 57.2% (Claude-4.6-Opus), 55.3% (Gemini-3-Pro), and 52.2% (Qwen3.5-397B-A17B), and performs step-level error analysis concluding that over 70% of errors stem from image reading and cross-view integration. Controlled experiments show that expert-provided single-image cues and cross-image summaries improve performance while self-generated intermediates reduce it, and that scaling inference-time computation yields gains only when early visual grounding is reliable.
Significance. If the step-level error breakdown and intervention results hold, the work makes a useful contribution by providing a denser multi-image medical reasoning benchmark than prior expert-level datasets (which use at most 1.43 images per case) and by empirically directing attention toward reliable visual grounding and cross-view composition rather than reasoning length alone. The scale, expert annotation, held-out test cases, and ablations on intermediate supervision are strengths that could support follow-on model development in multimodal clinical AI.
major comments (2)
- [Step-level error analysis (Results)] Step-level error analysis (Results): the central claim that over 70% of errors arise from image reading and cross-view integration, and that this is the primary bottleneck, rests on the step-level attribution. The manuscript provides no inter-annotator agreement statistics for these labels, no explicit decision rules or categorization criteria for distinguishing 'image reading failure' from later reasoning steps, and no ablation testing robustness to alternative labelings. Without these, the error distribution and the conclusion that 'additional inference-time computation helps only when visual grounding is already reliable' risk being artifacts of the evaluation protocol.
- [Evaluation protocol (Methods)] Evaluation protocol (Methods): the reported accuracies, model comparisons, and error breakdown lack details on statistical testing, how the 720 test cases were selected from the 8,067, and inter-annotator agreement for the expert annotations and step-level labels. These omissions make it difficult to assess the reliability of the performance numbers and the generalizability of the bottleneck finding.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight important aspects of transparency in our error analysis and evaluation protocol. We address each point below and have revised the manuscript accordingly where feasible to improve clarity and rigor without altering the core findings.
read point-by-point responses
-
Referee: [Step-level error analysis (Results)] Step-level error analysis (Results): the central claim that over 70% of errors arise from image reading and cross-view integration, and that this is the primary bottleneck, rests on the step-level attribution. The manuscript provides no inter-annotator agreement statistics for these labels, no explicit decision rules or categorization criteria for distinguishing 'image reading failure' from later reasoning steps, and no ablation testing robustness to alternative labelings. Without these, the error distribution and the conclusion that 'additional inference-time computation helps only when visual grounding is already reliable' risk being artifacts of the evaluation protocol.
Authors: We agree that greater transparency is needed for the step-level error analysis. In the revised manuscript, we will expand the Methods section to include the explicit decision rules and categorization criteria used by the expert annotators for distinguishing image reading failures from later reasoning steps. The main accuracy results, model comparisons, and intervention experiments (expert cues vs. self-generated intermediates) are independent of the precise error percentages and remain unchanged. However, inter-annotator agreement was not computed specifically for the step-level error attribution, as it was performed by the same experts responsible for the original case annotations to ensure consistency. We will explicitly note this as a limitation. A full ablation on alternative labelings was not conducted; we will add a brief sensitivity discussion based on the existing data. revision: partial
-
Referee: [Evaluation protocol (Methods)] Evaluation protocol (Methods): the reported accuracies, model comparisons, and error breakdown lack details on statistical testing, how the 720 test cases were selected from the 8,067, and inter-annotator agreement for the expert annotations and step-level labels. These omissions make it difficult to assess the reliability of the performance numbers and the generalizability of the bottleneck finding.
Authors: We acknowledge these omissions and will strengthen the Methods and Results sections in the revision. The 720 test cases were randomly selected as a held-out set from the full 8,067 cases with no case overlap to ensure generalizability. We will report inter-annotator agreement for the original expert annotations (which exceeded 0.85 Cohen's kappa) and add statistical details such as 95% confidence intervals for accuracies and pairwise significance tests for model comparisons. As noted in the response to the first comment, separate IAA for step-level error labels was not computed. These additions will allow readers to better evaluate the reliability of the reported numbers and the bottleneck conclusions. revision: yes
- Inter-annotator agreement statistics were not computed for the step-level error attribution labels.
Circularity Check
No circularity: empirical benchmark with direct measurements only
full rationale
This paper introduces MedThinkVQA, a new dataset, and reports model accuracies plus step-level error breakdowns on held-out cases. No equations, first-principles derivations, parameter fitting, or predictions are claimed. All results are direct empirical observations (accuracy percentages, error counts) rather than outputs derived from inputs by construction. Self-citations, if present, are not load-bearing for any central claim that reduces to itself. The analysis is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert-annotated cases and step-level labels constitute valid ground truth for clinical multi-image reasoning
Reference graph
Works this paper leans on
-
[1]
Ultrasound shows a dilated retroareolar duct containing an intracystic solid nodule
Step 3:“Ultrasound shows a dilated retroareolar duct containing an intracystic solid nodule.” Expert factual judgment:Incorrect.Error type:Image Understanding Err. In reality, the initial ultrasound was normal, and the follow-up ultrasound showed bilateral subareolar hypoechoic nodules with anechoic centres (abscesses), not a duct with an intra- cystic so...
-
[2]
Step 4:“MRI demonstrates a small enhancing subareolar intraductal lesion without sur- rounding inflammatory change.” Expert factual judgment:Incorrect.Error type:Image Understanding Err. The MRI actually showed bilateral fluid-filled cavities without internal enhancement, sur- rounded by an intensely enhancing capsule and inflammatory tissue with moderate...
-
[3]
The findings are not compatible with a galactocele because there is no fat–fluid level
Step 6:“The findings are not compatible with a galactocele because there is no fat–fluid level.” Expert factual judgment:Correct as stated.Error type:None. The expert accepts that there is no explicit fat–fluid level described. While the accompanying textual explanation overstates how definitively this excludes a galactocele, the literal step (“no fat–flu...
-
[4]
Step 7:“The findings are not compatible with an abscess because there is no pain, erythema, or inflammatory changes.” Expert factual judgment:Incorrect.Error types:Reasoning Err,Clinical Scenario Err, Medical Knowledge Err. This step bundles three distinct problems: • Clinical Scenario Err: It equates the absence of external pain, erythema, or skin signs ...
work page 2026
-
[5]
Generate additional incorrect options so that the total number of answer choices is exactly 5 (no more, no less)
-
[6]
Expand and refine the provided discussion, ensuring it thoroughly explains how to eliminate all incorrect answers and why the correct answer is most appropriate, using reasoning grounded in the CLINICAL_HISTORY and images. ### Suggested Approaches
-
[7]
Consider Erroneous Perspectives: Add distractors that misinterpret or overemphasize aspects of the CLINICAL_HISTORY or images
-
[8]
Leverage Common Misconceptions: Create distractors based on common diagnostic errors or frequently confused conditions
-
[9]
Logical Misdirection: Introduce distractors grounded in logical reasoning that appear plausible but are ultimately incorrect. ### General Requirements
-
[10]
Maintain Consistency: Ensure new options match the original ones in length, structure, and professional wording
-
[11]
Avoid Oversimplified Distractors
-
[12]
Ensure High Plausibility
-
[13]
- Strengthen explanations for ruling out incorrect answers
Expand Discussion: - Include reasoning for the newly generated distractors. - Strengthen explanations for ruling out incorrect answers. - Deepen justification for selecting the correct answer
-
[14]
Final Output Format: Return valid JSON with exactly these fields: options (A-E), correct_answer, discussion. ### Important Output Rules - Keep all *original* options text unchanged; only add new distractors to reach exactly five total options. - Do NOT reorder existing options; append only the missing letters (e.g., add D/E) so that A-E are filled. - The ...
work page 2026
-
[15]
NEVER delete information that relates to any ALLOWED_OPTIONS (even if an EXTRA item partially overlaps)
-
[16]
Remove sentences/clauses whose main role is to introduce, justify, or list items in EXTRA_TO_REMOVE. If a sentence mixes allowed and extra diagnoses, keep the allowed part and delete only the extra part, then fix grammar to remain fluent
-
[17]
Keep general disease definitions, imaging/lab reasoning, and conclusions that support ALLOWED_OPTIONS
-
[18]
Maintain coherence and clinical correctness; do NOT invent new claims
-
[19]
Output strictly as JSON with one key: discussion_new
-
[20]
If EXTRA_TO_REMOVE is empty, return the original discussion as discussion_new. I.2 USERPROMPTTEMPLATE Edit the DISCUSSION by deleting only the parts about the extra differentials. ALLOWED_OPTIONS (keep anything related to these): <ALLOWED_OPTIONS_JSON> DIF_DIAGNOSIS_LIST_CLEAN: <DIF_DIAGNOSIS_LIST_CLEAN_JSON> EXTRA_TO_REMOVE (delete content only about the...
work page 2026
-
[21]
Evaluate whether each step is correct or reasonably supported; reasonable analysis counts as correct
-
[22]
Mark True if the step is explicitly supported, correctly implied, or logically reasonable given the context and your teaching value/domain knowledge
-
[23]
Mark False only if the step is clearly wrong, contradictory, or cannot be reasonably inferred from either the context or standard domain knowledge
-
[24]
Ignore style, redundancy, or reasoning quality--focus only on correctness
-
[25]
Provide exactly one concise 1-2 sentence explanation per step
-
[26]
Return ONLY JSON following the provided schema; one verdict per step, same order. L.2 USERPROMPT(TEMPLATE) Task: For each step below, judge if it is supported by the provided context and relevant teaching value/domain knowledge. - Title: {{title}} - Clinical history: {{clinical_history}} - Imaging findings: {{imaging_findings}} - Discussion: {{discussion}...
work page 2026
-
[27]
Mark True if the sentence is explicitly supported, correctly implied, or logically reasonable given the context and standard domain knowledge
-
[28]
Mark False only if clearly wrong, contradictory, or not reasonably inferable
-
[29]
Ignore style and redundancy--focus only on correctness
-
[30]
Provide exactly one concise 1-2 sentence explanation per sentence
-
[31]
Return ONLY JSON for the schema below. Return STRICT JSON with this schema: { "sentence_judgments": { "<sentence_key>": { "text": "<original sentence>", "factual": true|false, "explanation": "<ONE concise 1-2 sentence explanation>" } } } L.4 RUBRICEVALUATIONPROMPT You are a board-certified radiologist tasked with evaluating the quality of radiology case d...
-
[32]
Read the entire Discussion section carefully
-
[33]
Score each of the 5 rubric criteria on a 0-2 scale
-
[34]
For each rubric score, provide a brief 1-2 sentence justification
-
[35]
Calculate total score (sum of all 5 rubrics, range 0-10) FOCUS ON: - Medical accuracy and evidence-based content - Completeness of information - Educational value for radiology trainees - Clear communication of key concepts - Integration of clinical and imaging perspectives OUTPUT FORMAT: Return ONLY a valid JSON object following the specified schema. Do ...
work page 2026
-
[36]
Preserve content: do NOT introduce facts not present in the explanation
-
[37]
Decompose into atomic inferences or observations -- each step one concise sentence (<= ~30 words)
-
[38]
Order steps to reflect the reasoning flow (e.g., findings -> interpretation -> decision)
-
[39]
Rewrite references like ’option A/B/C’ into plain statements; avoid option letters
-
[40]
If the explanation contrasts entities (e.g., ’X not Y’), separate them into distinct steps
-
[41]
Use the same language as the explanation text (typically English)
-
[42]
Return ONLY the JSON that matches the provided schema
If the explanation is very short, return a single clear step. Return ONLY the JSON that matches the provided schema. P.2 USERPROMPT(TEMPLATE) Task: Convert the following explanation into an ordered list of steps. Context (for referent clarity only - do NOT add facts not present in the explanation): - Title: {title} - Clinical history: {clinical_history} -...
work page 2026
-
[43]
Certain infectious and parasitic diseases(Train:n= 364; 5.0%, Test:n= 55; 7.6%) •1.1A00–A09 Intestinal infectious diseases — 18 / 3 •1.2A15–A19 Tuberculosis — 88 / 9 •1.3A20–A28 Certain zoonotic bacterial diseases — 13 / 2 •1.4A30–A49 Other bacterial diseases — 64 / 12 •1.5A50–A64 Infections with a predominantly sexual mode of transmission — 6 / 1 •1.6A65...
-
[44]
Neoplasms(Train:n= 1934; 26.3%, Test:n= 202; 28.1%) •2.1C00–C14 Malignant neoplasms of lip, oral cavity and pharynx — 14 / 1 •2.2C15–C26 Malignant neoplasms of digestive organs — 187 / 13 •2.3C30–C39 Malignant neoplasms of respiratory and intrathoracic organs — 77 / 8 •2.4C40–C41 Malignant neoplasms of bone and articular cartilage — 51 / 8 •2.5C43–C44 Mel...
work page 1934
-
[45]
Diseases of the blood and blood-forming organs and certain disorders involving the immune mechanism(Train:n= 142; 1.9%, Test:n= 24; 3.3%) •3.1D50–D53 Nutritional anaemias — 2 / 0 •3.2D55–D59 Haemolytic anaemias — 15 / 1 •3.3D60–D64 Aplastic and other anaemias — 1 / 0 •3.4D65–D69 Coagulation defects, purpura and other haemorrhagic conditions — 10 / 0 •3.5D...
-
[46]
Endocrine, nutritional and metabolic diseases(Train:n= 217; 3.0%, Test:n= 14; 1.9%) •4.1E00–E07 Disorders of thyroid gland — 21 / 0 •4.2E10–E14 Diabetes mellitus — 7 / 0 • 4.3E15–E16 Other disorders of glucose regulation and pancreatic internal secretion — 3 / 0 •4.4E20–E35 Disorders of other endocrine glands — 81 / 7 •4.5E50–E64 Other nutritional deficie...
-
[47]
Mental and behavioural disorders(Train:n= 2; 0.0%, Test:n= 0; 0.0%) •5.1F10–F19 Mental and behavioural disorders due to psychoactive substance use — 1 / 0 • 5.2F50–F59 Behavioural syndromes associated with physiological disturbances and physical factors — 1 / 0
-
[48]
Diseases of the nervous system(Train:n= 359; 4.9%, Test:n= 37; 5.1%) •6.1G00–G09 Inflammatory diseases of the central nervous system — 40 / 6 •6.2G10–G14 Systemic atrophies primarily affecting the central nervous system — 11 / 1 •6.3G20–G26 Extrapyramidal and movement disorders — 18 / 1 •6.4G30–G32 Other degenerative diseases of the nervous system — 10 / ...
work page 2026
-
[49]
Diseases of the eye and adnexa(Train:n= 23; 0.3%, Test:n= 5; 0.7%) •7.1H00–H06 Disorders of eyelid, lacrimal system and orbit — 9 / 3 •7.2H15–H22 Disorders of sclera, cornea, iris and ciliary body — 0 / 1 •7.3H25–H28 Disorders of lens — 1 / 0 •7.4H30–H36 Disorders of choroid and retina — 1 / 1 •7.5H40–H42 Glaucoma — 1 / 0 •7.6H43–H45 Disorders of vitreous...
-
[50]
Diseases of the ear and mastoid process(Train:n= 22; 0.3%, Test:n= 2; 0.3%) •8.1H60–H62 Diseases of external ear — 3 / 0 •8.2H65–H75 Diseases of middle ear and mastoid — 7 / 1 •8.3H80–H83 Diseases of inner ear — 9 / 1 •8.4H90–H95 Other disorders of ear — 3 / 0
-
[51]
Diseases of the circulatory system(Train:n= 759; 10.3%, Test:n= 58; 8.1%) •9.1I05–I09 Chronic rheumatic heart diseases — 2 / 0 •9.2I20–I25 Ischaemic heart diseases — 14 / 2 •9.3I26–I28 Pulmonary heart disease and diseases of pulmonary circulation — 42 / 5 •9.4I30–I52 Other forms of heart disease — 55 / 10 •9.5I60–I69 Cerebrovascular diseases — 120 / 10 •9...
-
[52]
Diseases of the respiratory system(Train:n= 222; 3.0%, Test:n= 23; 3.2%) •10.1J00–J06 Acute upper respiratory infections — 4 / 1 •10.2J09–J18 Influenza and pneumonia — 19 / 1 •10.3J30–J39 Other diseases of upper respiratory tract — 22 / 2 •10.4J40–J47 Chronic lower respiratory diseases — 22 / 1 •10.5J60–J70 Lung diseases due to external agents — 23 / 3 •1...
work page 2026
-
[53]
Diseases of the digestive system(Train:n= 892; 12.1%, Test:n= 66; 9.2%) •11.1K00–K14 Diseases of oral cavity, salivary glands and jaws — 56 / 6 •11.2K20–K31 Diseases of oesophagus, stomach and duodenum — 115 / 6 •11.3K35–K38 Diseases of appendix — 50 / 1 •11.4K40–K46 Hernia — 106 / 7 •11.5K50–K52 Noninfective enteritis and colitis — 40 / 2 •11.6K55–K64 Ot...
-
[54]
Diseases of the skin and subcutaneous tissue(Train:n= 43; 0.6%, Test:n= 6; 0.8%) •12.1L00–L08 Infections of the skin and subcutaneous tissue — 16 / 0 •12.2L50–L54 Urticaria and erythema — 4 / 0 •12.3L60–L75 Disorders of skin appendages — 7 / 4 •12.4L80–L99 Other disorders of the skin and subcutaneous tissue — 16 / 2
-
[55]
Diseases of the musculoskeletal system and connective tissue(Train: n= 524 ; 7.1%, Test: n= 61; 8.5%) •13.1M00–M03 Infectious arthropathies — 8 / 2 •13.2M05–M14 Inflammatory polyarthropathies — 24 / 5 •13.3M15–M19 Arthrosis — 6 / 1 •13.4M20–M25 Other joint disorders — 43 / 5 •13.5M30–M36 Systemic connective tissue disorders — 55 / 10 •13.6M40–M43 Deformin...
-
[56]
Diseases of the genitourinary system(Train:n= 344; 4.7%, Test:n= 64; 8.9%) •14.1N00–N08 Glomerular diseases — 3 / 1 •14.2N10–N16 Renal tubulo-interstitial diseases — 37 / 6 •14.3N17–N19 Renal failure — 1 / 1 61 Published as a conference paper at ICLR 2026 •14.4N20–N23 Urolithiasis — 15 / 1 •14.5N25–N29 Other disorders of kidney and ureter — 40 / 3 •14.6N3...
work page 2026
-
[57]
Pregnancy, childbirth and the puerperium(Train:n= 35; 0.5%, Test:n= 7; 1.0%) •15.1O00–O08 Pregnancy with abortive outcome — 20 / 4 • 15.2O10–O16 Oedema, proteinuria and hypertensive disorders in pregnancy, childbirth and the puerperium — 4 / 0 •15.3O20–O29 Other maternal disorders predominantly related to pregnancy — 0 / 1 • 15.4O30–O48 Maternal care rela...
-
[58]
Certain conditions originating in the perinatal period(Train: n= 25 ; 0.3%, Test: n= 0 ; 0.0%) • 16.1P20–P29 Respiratory and cardiovascular disorders specific to the perinatal period — 6 / 0 •16.2P35–P39 Infections specific to the perinatal period — 1 / 0 •16.3P50–P61 Haemorrhagic and haematological disorders of fetus and newborn — 4 / 0 • 16.4P70–P74 Tra...
-
[59]
Congenital malformations, deformations and chromosomal abnormalities(Train:n= 793; 10.8%, Test:n= 60; 8.3%) •17.1Q00–Q07 Congenital malformations of the nervous system — 96 / 10 •17.2Q10–Q18 Congenital malformations of eye, ear, face and neck — 25 / 2 •17.3Q20–Q28 Congenital malformations of the circulatory system — 228 / 11 •17.4Q30–Q34 Congenital malfor...
work page 2026
-
[60]
Symptoms, signs and abnormal clinical and laboratory findings, not elsewhere classified (Train:n= 36; 0.5%, Test:n= 1; 0.1%) • 18.1R00–R09 Symptoms and signs involving the circulatory and respiratory systems — 1 / 0 •18.2R10–R19 Symptoms and signs involving the digestive system and abdomen — 11 / 0 •18.3R20–R23 Symptoms and signs involving the skin and su...
-
[61]
Injury, poisoning and certain other consequences of external causes(Train: n= 572 ; 7.8%, Test:n= 31; 4.3%) •19.1S00–S09 Injuries to the head — 38 / 1 •19.2S10–S19 Injuries to the neck — 30 / 0 •19.3S20–S29 Injuries to the thorax — 55 / 1 •19.4S30–S39 Injuries to the abdomen, lower back, lumbar spine and pelvis — 102 / 5 •19.5S40–S49 Injuries to the shoul...
-
[62]
External causes of morbidity and mortality(Train:n= 3; 0.0%, Test:n= 0; 0.0%) •20.1Y60–Y69 Misadventures to patients during surgical and medical care — 3 / 0
-
[63]
Factors influencing health status and contact with health services(Train: n= 18 ; 0.2%, Test: n= 2; 0.3%) • 21.1Z00–Z13 Persons encountering health services for examination and investigation — 10 / 0 63 Published as a conference paper at ICLR 2026 • 21.2Z40–Z54 Persons encountering health services for specific procedures and health care — 5 / 1 • 21.3Z80–...
work page 2026
-
[64]
Codes for special purposes(Train:n= 18; 0.2%, Test:n= 2; 0.3%) • 22.1U00–U49 Provisional assignment of new diseases of uncertain etiology or emergency use — 18 / 2 Note:For each split, block counts within a chapter sum to the chapter total, and chapter totals across all chapters sum to the split size. Abbreviations: NEC = not elsewhere classified. 64 Publ...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.