Recognition: unknown
Certified Program Synthesis with a Multi-Modal Verifier
Pith reviewed 2026-05-10 08:14 UTC · model grok-4.3
The pith
LeetProof uses a multi-modal verifier in Lean to generate more fully certified programs from natural language than single-mode baselines at the same budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
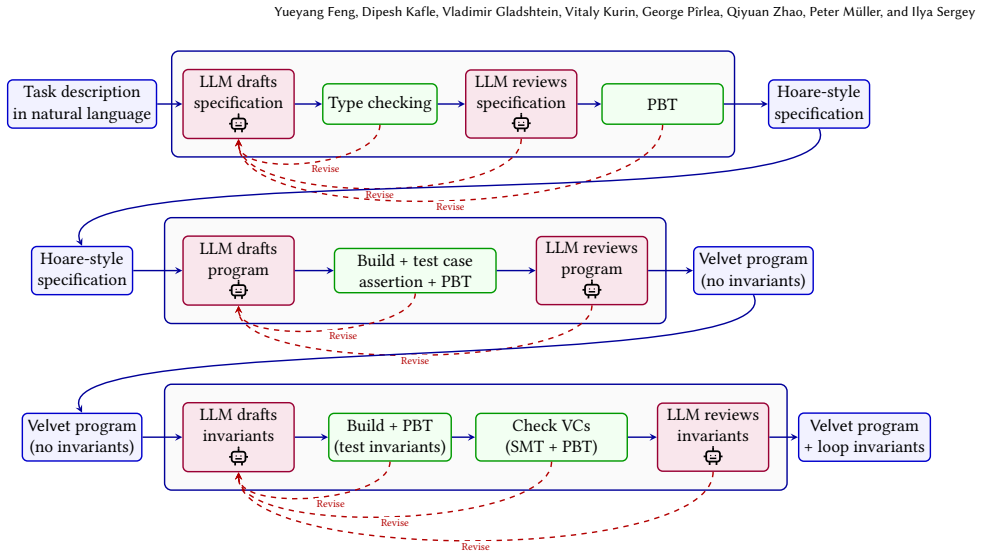
By structuring the certified synthesis workflow around a multi-modal verifier that combines dynamic validation, automated proofs, and interactive proof scripting in a single foundational framework, LeetProof achieves a significantly higher rate of fully certified solutions than a single-mode baseline at the same budget, consistently across two frontier LLM backends, and its specification validation step uncovers defects in existing reference benchmarks.
What carries the argument
Velvet, the multi-modal verifier embedded in Lean, which performs randomized property-based testing for specification validation, decomposes synthesis tasks using verification conditions, and delegates residual proofs to frontier AI provers.
If this is right
- Specifications synthesized from natural language can be tested for weakness or over-strength before any code is generated.
- Synthesis tasks can be decomposed into sub-problems aligned with verification conditions.
- Residual proof obligations can be routed to AI provers specialized for the Lean ecosystem.
- The performance gain holds across different frontier LLM backends at fixed computational budget.
- Existing certified-synthesis benchmarks contain identifiable defects that can be detected systematically.
Where Pith is reading between the lines
- The same staged validation-plus-decomposition pattern could be ported to other foundational proof assistants to test whether multi-modality is broadly useful.
- Software teams might adopt certified synthesis earlier if the pipeline reduces the manual effort needed to reach machine-checkable proofs.
- Cleaning the reference benchmarks of the uncovered defects and re-running both pipelines would isolate how much of the reported gain is due to better handling versus benchmark noise.
- Extending the dynamic-testing stage to larger input spaces could further tighten the quality of generated specifications.
Load-bearing premise
A multi-modal verifier can be realized in Lean to combine dynamic validation, automated proofs, and interactive scripting without prohibitive overhead or loss of expressivity, and the benchmarks remain representative after defects are uncovered.
What would settle it
A head-to-head run of LeetProof against the single-mode baseline on the same natural-language tasks where the percentage of fully machine-checkable certified solutions is not higher for the multi-modal pipeline.
Figures







read the original abstract
Certified program synthesis (aka vericoding) is the process of automatically generating a program, its formal specification, and a machine-checkable proof of their alignment from a natural-language description. Two challenges make vericoding difficult. First, specifications synthesised from natural language are often either too weak to be meaningful or too strong to be implementable, yet existing approaches lack systematic means to detect such defects. Second, the landscape of program verifiers is fragmented: each tool supports a particular reasoning mode -- auto-active (e.g., Dafny, Verus) or interactive (e.g., Coq, Lean) -- with its own trade-off between automation and expressivity. This forces every synthesis methodology to be tailored to a single verification paradigm, limiting the class of tasks it can handle effectively. We overcome both challenges by structuring the certified synthesis workflow around a multi-modal verifier -- a single tool combining dynamic validation, automated proofs, and interactive proof scripting in one foundational framework. We realise this idea in LeetProof, an agentic pipeline built on Velvet, a multi-modal verifier embedded in Lean. Multi-modality enables LeetProof to validate generated specifications via randomised property-based testing before any code is synthesised, decompose the synthesis task into sub-problems guided by verification conditions, and delegate residual proof obligations to frontier AI provers specialised for Lean. We evaluate LeetProof on benchmarks derived from prior work on certified synthesis. Our specification validation uncovers defects in existing reference benchmarks, and LeetProof's staged pipeline achieves a significantly higher rate of fully certified solutions than a single-mode baseline at the same budget -- consistently across two frontier LLM backends.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LeetProof, an agentic pipeline for certified program synthesis (vericoding) built on Velvet, a multi-modal verifier embedded in Lean. Velvet integrates dynamic validation via property-based testing, automated proofs, and interactive scripting in one framework. LeetProof uses this to validate synthesized specifications before code generation, decompose tasks guided by verification conditions, and delegate residual obligations to AI provers. Evaluation on benchmarks derived from prior work reports uncovering defects in reference benchmarks and a significantly higher rate of fully certified solutions than a single-mode baseline at fixed budget, consistent across two frontier LLM backends.
Significance. If the empirical results hold with adequate quantitative support, the work is significant for certified synthesis: it directly tackles the fragmentation of verification tools by unifying modes in a foundational system (Lean), enabling earlier defect detection in specifications and more flexible handling of proof obligations. The uncovering of benchmark defects provides a concrete service to the community. The staged pipeline design and cross-backend consistency are strengths that could influence future agentic synthesis systems. Machine-checked elements in Lean add reliability to the claims.
major comments (2)
- [Evaluation] Evaluation section: The central claim of significantly higher fully certified solution rates (and consistency across backends) is load-bearing but unsupported by any reported success percentages, task counts, error bars, or statistical details in the manuscript; without these, the magnitude and reliability of the improvement over the single-mode baseline cannot be assessed.
- [Sections 3-4] Velvet realization (Sections 3-4): The claim that a multi-modal verifier can be effectively realized in Lean to combine dynamic validation, automated proofs, and interactive scripting without prohibitive overhead or loss of expressivity is central to the approach but lacks any architecture details, integration mechanism, or overhead measurements, undermining evaluation of the weakest assumption.
minor comments (2)
- [Abstract] Abstract: Include at least one key quantitative result (e.g., success rate delta) to ground the 'significantly higher' claim for readers.
- [Introduction] Introduction: Define 'vericoding' on first use and add a citation to the prior work from which benchmarks are derived.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The two major comments identify important gaps in the presentation of our empirical results and the technical realization of Velvet. We will revise the manuscript to address both points directly, as detailed below. These changes will strengthen the paper without altering its core claims or contributions.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The central claim of significantly higher fully certified solution rates (and consistency across backends) is load-bearing but unsupported by any reported success percentages, task counts, error bars, or statistical details in the manuscript; without these, the magnitude and reliability of the improvement over the single-mode baseline cannot be assessed.
Authors: We agree that the evaluation section requires explicit quantitative support for the reported improvement. The current manuscript states that LeetProof achieves a significantly higher rate of fully certified solutions than the single-mode baseline at fixed budget and that this holds consistently across two frontier LLM backends, but does not include the supporting numbers. In the revised version we will add a dedicated evaluation subsection (or expanded table) that reports: (i) the exact benchmark size and task counts, (ii) success percentages for fully certified solutions under LeetProof versus the baseline, (iii) error bars or variance across runs, and (iv) any statistical tests performed. This will allow readers to evaluate both the magnitude and reliability of the gains. revision: yes
-
Referee: [Sections 3-4] Velvet realization (Sections 3-4): The claim that a multi-modal verifier can be effectively realized in Lean to combine dynamic validation, automated proofs, and interactive scripting without prohibitive overhead or loss of expressivity is central to the approach but lacks any architecture details, integration mechanism, or overhead measurements, undermining evaluation of the weakest assumption.
Authors: We concur that Sections 3 and 4 currently provide insufficient detail on Velvet's implementation. The manuscript describes Velvet as a multi-modal verifier embedded in Lean that unifies randomized property-based testing, automated proof tactics, and interactive scripting, but does not supply architecture diagrams, the precise integration points between modes, or concrete overhead measurements. In revision we will expand these sections with: (1) a high-level architecture overview and Lean module structure showing how the three modes coexist without restricting expressivity, (2) the mechanisms used to switch between or combine modes within a single verification condition, and (3) empirical overhead data (runtime and memory) collected on representative tasks. These additions will substantiate the feasibility claim. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical agentic pipeline (LeetProof) built on a multi-modal verifier (Velvet in Lean) and reports experimental results: higher rates of fully certified solutions versus a single-mode baseline at fixed budget, plus discovery of benchmark defects. No mathematical derivation, equations, or first-principles predictions are claimed; the central result is a direct empirical comparison on externally derived benchmarks. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations that reduce the outcome to the paper's own inputs by construction appear in the provided text. The evaluation is externally grounded and falsifiable via replication on the same benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Lean provides a sound foundation for interactive and automated proofs of program correctness.
- domain assumption Randomized property-based testing can reliably detect defects in specifications synthesized from natural language.
invented entities (2)
-
Velvet
no independent evidence
-
LeetProof
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Tudor Achim, Alex Best, Alberto Bietti, Kevin Der, Mathïs Fédérico, Sergei Gukov, Daniel Halpern-Leistner, Kirsten Henningsgard, Yury Kudryashov, Alexander Meiburg, Martin Michelsen, Riley Patterson, Eric Rodriguez, Laura Scharff, Vikram Shanker, Vladimir Sicca, Hari Sowrirajan, Aidan Swope, Matyas Tamas, Vlad Tenev, Jonathan Thomm, Harold Williams, and L...
work page internal anchor Pith review doi:10.48550/arxiv.2510.01346 2025
-
[2]
Pranjal Aggarwal, Bryan Parno, and Sean Welleck. 2025. AlphaVerus: Bootstrap- ping Formally Verified Code Generation through Self-Improving Translation and Treefinement. In ICML (Proceedings of Machine Learning Research) . PMLR / OpenReview.net. https://proceedings.mlr.press/v267/aggarwal25a.html
2025
-
[3]
Appel, Robert Dockins, Aquinas Hobor, Lennart Beringer, Josiah Dodds, Gordon Stewart, Sandrine Blazy, and Xavier Leroy
Andrew W. Appel, Robert Dockins, Aquinas Hobor, Lennart Beringer, Josiah Dodds, Gordon Stewart, Sandrine Blazy, and Xavier Leroy. 2014. Program Logics for Certified Compilers. Cambridge University Press
2014
-
[4]
Mantas Baksys, Stefan Zetzsche, Olivier Bouissou, Remi Delmas, Soonho Kong, and Sean B. Holden. 2025. ATLAS: Automated Toolkit for Large-Scale Verified Code Synthesis. CoRR abs/2512.10173 (2025). https://doi.org/10.48550/ARXIV. 2512.10173 arXiv:2512.10173
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[5]
Debangshu Banerjee, Olivier Bouissou, and Stefan Zetzsche. 2026. DafnyPro: LLM-Assisted Automated Verification for Dafny Programs. CoRR abs/2601.05385 (2026). https://doi.org/10.48550/ARXIV.2601.05385
-
[6]
Haniel Barbosa, Clark W. Barrett, Martin Brain, Gereon Kremer, Hanna Lach- nitt, Makai Mann, Abdalrhman Mohamed, Mudathir Mohamed, Aina Niemetz, Andres Nötzli, Alex Ozdemir, Mathias Preiner, Andrew Reynolds, Ying Sheng, Cesare Tinelli, and Yoni Zohar. 2022. cvc5: A Versatile and Industrial-Strength SMT Solver. In TACAS (LNCS, Vol. 13243) . Springer, 415–4...
-
[7]
Lukas Bulwahn. 2012. The New Quickcheck for Isabelle - Random, Exhaustive and Symbolic Testing under One Roof. In CPP (LNCS) . Springer, 92–108. https: //doi.org/10.1007/978-3-642-35308-6_10
-
[8]
Sergiu Bursuc, Theodore Ehrenborg, Shaowei Lin, Lacramioara Astefanoaei, Ionel Emilian Chiosa, Jure Kukovec, Alok Singh, Oliver Butterley, Adem Bizid, Quinn Dougherty, Miranda Zhao, Max Tan, and Max Tegmark. 2025. A Bench- mark for Vericoding: Formally Verified Program Synthesis.CoRR abs/2509.22908 (2025). https://doi.org/10.48550/ARXIV.2509.22908
-
[9]
In: 2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE)
Saikat Chakraborty, Gabriel Ebner, Siddharth Bhat, Sarah Fakhoury, Sakina Fa- tima, Shuvendu K. Lahiri, and Nikhil Swamy. 2025. Towards Neural Synthe- sis for SMT-Assisted Proof-Oriented Programming. In ICSE. IEEE, 1755–1767. https://doi.org/10.1109/ICSE55347.2025.00002
-
[10]
Tianyu Chen, Shuai Lu, Shan Lu, Yeyun Gong, Chenyuan Yang, Xuheng Li, Md Rakib Hossain Misu, Hao Yu, Nan Duan, Peng Cheng, Fan Yang, Shu- vendu K Lahiri, Tao Xie, and Lidong Zhou. 2025. Automated Proof Gener- ation for Rust Code via Self-Evolution. CoRR abs/2410.15756 (2025). https: //doi.org/10.48550/ARXIV.2410.15756 ICLR 2025
- [11]
-
[12]
Leonardo de Moura and Sebastian Ullrich. 2021. The Lean 4 Theorem Prover and Programming Language. In CADE (LNCS, Vol. 12699) . Springer, 625–635. https://doi.org/10.1007/978-3-030-79876-5_37
-
[13]
Leonardo Mendonça de Moura and Nikolaj Bjørner. 2008. Z3: An Efficient SMT Solver. In TACAS (LNCS, Vol. 4963). Springer, 337–340. https://doi.org/10.1007/ 978-3-540-78800-3_24
2008
-
[14]
Leonardo Mendonça de Moura, Soonho Kong, Jeremy Avigad, Floris van Doorn, and Jakob von Raumer. 2015. The Lean Theorem Prover (System Description). In CADE (LNCS, Vol. 9195) . Springer, 378–388. https://doi.org/10.1007/978-3- 319-21401-6_26
-
[15]
Benjamin Delaware, Clément Pit-Claudel, Jason Gross, and Adam Chlipala. 2015. Fiat: Deductive Synthesis of Abstract Data Types in a Proof Assistant. In POPL. ACM, 689–700. https://doi.org/10.1145/2676726.2677006
-
[16]
Yueyang Feng, Dipesh Kafle, Vladimir Gladshtein, Vitaly Kurin, George Pîrlea, Qiyuan Zhao, Peter Müller, and Ilya Sergey. 2026. LeetProof: Artefact. Zenodo. https://doi.org/10.5281/zenodo.19624966 Includes implementation, benchmarks, and evaluation harness
-
[17]
Cormac Flanagan and K. Rustan M. Leino. 2001. Houdini, an Annotation Assistant for ESC/Java. In FME (LNCS, Vol. 2021) . Springer, 500–517. https: //doi.org/10.1007/3-540-45251-6_29
-
[19]
Foundational Multi-Modal Program Verifiers. Proc. ACM Program. Lang. 10, POPL (2026), 1–28. https://doi.org/10.1145/3776719
-
[20]
Vladimir Gladshtein, George Pîrlea, Qiyuan Zhao, Vitaly Kurin, and Ilya Sergey
-
[21]
In Dafny Work- shop
Velvet: A Multi-Modal Verifier for Effectful Programs. In Dafny Work- shop. https://verse-lab.org/papers/velvet-dafny26.pdf Code available at https: //github.com/verse-lab/velvet
-
[22]
Cutler, Daniel Dickstein, Benjamin C
Harrison Goldstein, Joseph W. Cutler, Daniel Dickstein, Benjamin C. Pierce, and Andrew Head. 2024. Property-Based Testing in Practice. In ICSE. ACM, 187:1– 187:13. https://doi.org/10.1145/3597503.3639581
-
[23]
Harrison Goldstein, Hila Peleg, Cassia Torczon, Daniel Sainati, Leonidas Lam- propoulos, and Benjamin C. Pierce. 2025. The Search for Constrained Random Generators. CoRR abs/2511.12253 (2025). https://doi.org/10.48550/ARXIV.2511. 12253 arXiv:2511.12253
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511 2025
-
[24]
C. A. R. Hoare. 1969. An Axiomatic Basis for Computer Programming. Commun. ACM 12, 10 (1969), 576–580. https://doi.org/10.1145/363235.363259
-
[25]
Thomas Hubert, Rishi Mehta, Laurent Sartran, Miklós Z. Horváth, Goran Žužić, Eric Wieser, Aja Huang, Julian Schrittwieser, Yannick Schroecker, Hussain Ma- soom, Ottavia Bertolli, Tom Zahavy, Amol Mandhane, Jessica Yung, Iuliya Be- loshapka, Borja Ibarz, Vivek Veeriah, Lei Yu, Oliver Nash, Paul Lezeau, Salva- tore Mercuri, Calle Sönne, Bhavik Mehta, Alex D...
-
[26]
John Hughes. 2011. Specification based testing with QuickCheck: tutorial talk. In FMCAD. FMCAD Inc., 17. http://dl.acm.org/citation.cfm?id=2157659
2011
-
[27]
Saketh Ram Kasibatla, Arpan Agarwal, Yuriy Brun, Sorin Lerner, Talia Ringer, and Emily First. 2024. Cobblestone: A Divide-and-Conquer Approach for Au- tomating Formal Verification. CoRR abs/2410.19940 (2024). arXiv: 2410.19940 http://arxiv.org/abs/2410.19940
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Florent Kirchner, Nikolai Kosmatov, Virgile Prevosto, Julien Signoles, and Boris Yakobowski. 2015. Frama-C: A software analysis perspective. Formal Aspects 11 Yueyang Feng, Dipesh Kafle, Vladimir Gladshtein, Vitaly Kurin, George Pîrlea, Qiyuan Zhao, Peter Müller, and Ilya Sergey Comput. 27, 3, 573–609. https://doi.org/10.1007/S00165-014-0326-7
-
[29]
Shuvendu K. Lahiri. 2024. Evaluating LLM-driven User-Intent Formalization for Verification-Aware Languages. In FMCAD. IEEE, 142–147. https://doi.org/ 10.34727/2024/isbn.978-3-85448-065-5_19
-
[30]
Andrea Lattuada, Travis Hance, Jay Bosamiya, Matthias Brun, Chanhee Cho, Hayley LeBlanc, Pranav Srinivasan, Reto Achermann, Tej Chajed, Chris Haw- blitzel, Jon Howell, Jacob R. Lorch, Oded Padon, and Bryan Parno. 2024. Verus: A Practical Foundation for Systems Verification. In SOSP. ACM, 438–454. https: //doi.org/10.1145/3694715.3695952
-
[31]
leanprover-community. 2025. Plausible: A property testing framework for Lean
2025
-
[32]
https://github.com/leanprover-community/plausible
-
[33]
leanprover-community. 2026. Lean Language Reference: The grind tactic. https: //lean-lang.org/doc/reference/latest/The--grind--tactic/
2026
-
[34]
leanprover-community. 2026. Lean Language Reference: Type Classes. https: //lean-lang.org/doc/reference/latest/Type-Classes/
2026
-
[35]
Rustan M
K. Rustan M. Leino. 2010. Dafny: An Automatic Program Verifier for Functional Correctness. In LPAR (LNCS, Vol. 6355) . Springer, 348–370. https://doi.org/10. 1007/978-3-642-17511-4_20
2010
- [36]
-
[37]
Jannis Limperg and Asta Halkjær From. 2023. Aesop: White-Box Best-First Proof Search for Lean. In CPP. ACM, 253–266. https://doi.org/10.1145/3573105. 3575671
-
[38]
Chloe Loughridge, Qinyi Sun, Seth Ahrenbach, Federico Cassano, Chuyue Sun, Ying Sheng, Anish Mudide, Md Rakib Hossain Misu, Nada Amin, and Max Tegmark. 2025. DafnyBench: A Benchmark for Formal Software Verifica- tion. Trans. Mach. Learn. Res. 2025 (2025). https://openreview.net/forum?id= yBgTVWccIx
2025
- [39]
-
[40]
Lezhi Ma, Shangqing Liu, Yi Li, Xiaofei Xie, and Lei Bu. 2025. SpecGen: Auto- mated Generation of Formal Program Specifications via Large Language Models. In ICSE. IEEE, 16–28. https://doi.org/10.1109/ICSE55347.2025.00129
-
[41]
The mathlib Community. 2020. The Lean mathematical library. In CPP. ACM, 367–381. https://doi.org/10.1145/3372885.3373824 https://github.com/ leanprover-community/mathlib4
-
[42]
Kenneth L. McMillan and Oded Padon. 2020. Ivy: A Multi-modal Verification Tool for Distributed Algorithms. In CA V (LNCS, Vol. 12225). Springer, 190–202. https://doi.org/10.1007/978-3-030-53291-8_12
-
[43]
Brando Miranda, Zhanke Zhou, Allen Nie, Elyas Obbad, Leni Aniva, Kai Frons- dal, Weston Kirk, Dilara Soylu, Andrea Yu, Ying Li, and Sanmi Koyejo. 2025. VeriBench: End-to-End Formal Verification Benchmark for AI Code Generation in Lean 4. (2025). https://openreview.net/forum?id=rWkGFmnSNl
2025
-
[44]
Lopes, Iris Ma, and James Noble
Md Rakib Hossain Misu, Cristina V. Lopes, Iris Ma, and James Noble. 2024. To- wards AI-Assisted Synthesis of Verified Dafny Methods. Proc. ACM Softw. Eng. 1, FSE (2024), 812–835. https://doi.org/10.1145/3643763
-
[45]
Abdalrhman Mohamed, Tomaz Mascarenhas, Muhammad Harun Ali Khan, Haniel Barbosa, Andrew Reynolds, Yicheng Qian, Cesare Tinelli, and Clark W. Barrett. 2025. lean-smt: An SMT Tactic for Discharging Proof Goals in Lean. In CA V (LNCS, Vol. 15933). Springer, 197–212. https://doi.org/10.1007/978-3-031- 98682-6_11
-
[46]
Eric Mugnier, Emmanuel Anaya Gonzalez, Ranjit Jhala, Nadia Polikarpova, and Yuanyuan Zhou. 2025. Laurel: Unblocking Automated Verification with Large Language Models. Proc. ACM Program. Lang. 9, OOPSLA1 (2025). https://doi. org/10.1145/3720499
-
[47]
Prasita Mukherjee, Minghai Lu, and Benjamin Delaware. 2025. LLM-Assisted Synthesis of High-Assurance C Programs. In ASE. IEEE, 3108. https://doi.org/ 10.1109/ASE63991.2025.00255
-
[48]
Peter Müller, Malte Schwerhoff, and Alexander J. Summers. 2016. Viper: A Verification Infrastructure for Permission-Based Reasoning. In VMCAI (LNCS, Vol. 9583). Springer, 41–62. https://doi.org/10.1007/978-3-662-49122-5_2
-
[49]
Peter W. O’Hearn, John C. Reynolds, and Hongseok Yang. 2001. Local Reasoning about Programs that Alter Data Structures. In CSL (LNCS, Vol. 2142) . Springer, 1–19. https://doi.org/10.1007/3-540-44802-0_1
-
[50]
McMillan, Aurojit Panda, Mooly Sagiv, and Sharon Shoham
Oded Padon, Kenneth L. McMillan, Aurojit Panda, Mooly Sagiv, and Sharon Shoham. 2016. Ivy: safety verification by interactive generalization. In PLDI. ACM, 614–630. https://doi.org/10.1145/2908080.2908118
-
[51]
Zoe Paraskevopoulou, Cătălin Hriţcu, Maxime Dénès, Leonidas Lampropoulos, and Benjamin C. Pierce. 2015. Foundational Property-Based Testing. In ITP (LNCS, Vol. 9236). Springer, 325–343. https://doi.org/10.1007/978-3-319-22102- 1_22
-
[52]
Arthur Paulino, Damiano Testa, Edward Ayers, Evgenia Karunus, Henrik Bövinga, Jannis Limperg, Siddhartha Gadgil, and Siddharth Bhat. 2024. Metapro- gramming in Lean 4. Available at https://leanprover-community.github.io/ lean4-metaprogramming-book/
2024
-
[53]
George Pîrlea, Vladimir Gladshtein, Elad Kinsbruner, Qiyuan Zhao, and Ilya Sergey. 2025. Veil: A Framework for Automated and Interactive Verification of Transition Systems. In CA V (LNCS, Vol. 15933) . Springer, 26–41. https: //doi.org/10.1007/978-3-031-98682-6_2
-
[54]
Clément Pit-Claudel, Jade Philipoom, Dustin Jamner, Andres Erbsen, and Adam Chlipala. 2022. Relational Compilation for Performance-Critical Applications. In PLDI. ACM, 918–932. https://doi.org/10.1145/3519939.3523706
-
[55]
Nadia Polikarpova and Ilya Sergey. 2019. Structuring the Synthesis of Heap- Manipulating Programs. PACMPL 3, POPL (2019), 72:1–72:30. https://doi.org/ 10.1145/3290385
-
[56]
Yicheng Qian, Joshua Clune, Clark W. Barrett, and Jeremy Avigad. 2025. Lean- Auto: An Interface Between Lean 4 and Automated Theorem Provers. In CA V (LNCS, Vol. 15933). Springer, 175–196. https://doi.org/10.1007/978-3-031-98682- 6_10
-
[57]
John C. Reynolds. 2002. Separation Logic: A Logic for Shared Mutable Data Structures. In LICS. IEEE Computer Society, 55–74. https://doi.org/10.1109/LICS. 2002.1029817
-
[58]
Rocq Development Team. 2025. The Rocq Prover. https://rocq-prover.org. Ver- sion 9.0.0, released March 12, 2025
2025
-
[59]
Grigore Rosu. 2017. K: A Semantic Framework for Programming Languages and Formal Analysis Tools. In Dependable Software Systems Engineering. NATO Science for Peace and Security Series - D: Information and Communication Secu- rity, Vol. 50. IOS Press, 186–206. https://doi.org/10.3233/978-1-61499-810-5-186
-
[60]
Peiyang Song, Kaiyu Yang, and Anima Anandkumar. 2025. Lean Copilot: Large Language Models as Copilots for Theorem Proving in Lean. (2025), 144–169. https://proceedings.mlr.press/v288/song25a.html
2025
-
[61]
Chuyue Sun, Ying Sheng, Oded Padon, and Clark Barrett. 2024. Clover: Closed- Loop Verifiable Code Generation. CoRR abs/2310.17807 (2024). https://doi.org/ 10.48550/ARXIV.2310.17807 SAIV 2024
-
[62]
Nikhil Swamy, Cătălin Hriţcu, Chantal Keller, Aseem Rastogi, Antoine Delignat- Lavaud, Simon Forest, Karthikeyan Bhargavan, Cédric Fournet, Pierre-Yves Strub, Markulf Kohlweiss, Jean-Karim Zinzindohoue, and Santiago Zanella- Béguelin. 2016. Dependent types and multi-monadic effects in F*. InPOPL. ACM, 256–270. https://doi.org/10.1145/2837614.2837655
-
[63]
Amitayush Thakur, Jasper Lee, George Tsoukalas, Meghana Sistla, Matthew Zhao, Stefan Zetzsche, Greg Durrett, Yisong Yue, and Swarat Chaudhuri. 2025. CLEVER: A Curated Benchmark for Formally Verified Code Generation. CoRR abs/2505.13938 (2025). https://doi.org/10.48550/ARXIV.2505.13938 NeurIPS 2025 Datasets and Benchmarks
-
[64]
Ferreira, Sorin Lerner, and Emily First
Kyle Thompson, Nuno Saavedra, Pedro Carrott, Kevin Fisher, Alex Sanchez- Stern, Yuriy Brun, João F. Ferreira, Sorin Lerner, and Emily First. 2024. Rango: Adaptive Retrieval-Augmented Proving for Automated Software Verification. arXiv preprint arXiv:2412.14063 (2024). https://arxiv.org/abs/2412.14063
-
[65]
Haoxin Tu, Huan Zhao, Yahui Song, Mehtab Zafar, Ruijie Meng, and Abhik Roy- choudhury. 2025. Agentic Program Verification. CoRR abs/2511.17330 (2025). https://doi.org/10.48550/ARXIV.2511.17330 arXiv:2511.17330
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.17330 2025
-
[66]
Sumanth Varambally, Thomas Voice, Yanchao Sun, Zhifeng Chen, Rose Yu, and Ke Ye. 2025. Hilbert: Recursively Building Formal Proofs with Informal Reason- ing. CoRR abs/2509.22819 (2025). https://doi.org/10.48550/ARXIV.2509.22819 arXiv:2509.22819
-
[67]
Yasunari Watanabe, Kiran Gopinathan, George Pîrlea, Nadia Polikarpova, and Ilya Sergey. 2021. Certifying the Synthesis of Heap-Manipulating Programs. Proc. ACM Program. Lang. 5, ICFP (2021), 1–29. https://doi.org/10.1145/3473589
-
[68]
Lorch, Shuai Lu, Fan Yang, Ziqiao Zhou, and Shan Lu
Chenyuan Yang, Xuheng Li, Md Rakib Hossain Misu, Jianan Yao, Weidong Cui, Yeyun Gong, Chris Hawblitzel, Shuvendu Lahiri, Jacob R. Lorch, Shuai Lu, Fan Yang, Ziqiao Zhou, and Shan Lu. 2025. AutoVerus: Automated Proof Generation for Rust Code. Proc. ACM Program. Lang. 9, OOPSLA2 (2025). https://doi.org/ 10.1145/3763174
-
[69]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik R Narasimhan, and Ofir Press. 2024. SWE-agent: Agent-Computer Inter- faces Enable Automated Software Engineering. In NeurIPS. https://openreview. net/forum?id=mXpq6ut8J3
2024
-
[70]
Zhe Ye, Zhengxu Yan, Jingxuan He, Timothe Kasriel, Kaiyu Yang, and Dawn Song. 2025. VERINA: Benchmarking Verifiable Code Generation. CoRR abs/2505.23135 (2025). https://doi.org/10.48550/ARXIV.2505.23135 ICLR 2026
-
[71]
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. 2024. Au- toCodeRover: Autonomous Program Improvement. In ISSTA. ACM, 1592–1604. https://doi.org/10.1145/3650212.3680384 12
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.