Recognition: unknown
Crowded in B-Space: Calibrating Shared Directions for LoRA Merging
Pith reviewed 2026-05-10 07:23 UTC · model grok-4.3
The pith
The main source of interference when merging LoRA adapters is over-shared directions in the B matrix, which Pico corrects by downscaling them before the merge and rescaling afterward.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
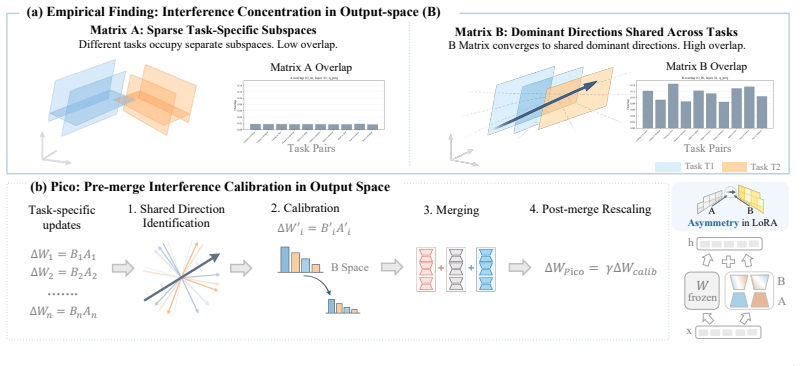
The central claim is that merge interference arises primarily from repeated directions in the output-side B matrices across tasks, while A matrices remain task-specific. Downscaling the over-shared directions in B before the merge, then rescaling the merged update, recovers task-specific information that would otherwise be lost in the combination. This calibration step improves results when added to existing merge methods and can produce adapters that outperform a single LoRA trained on the union of all task data.
What carries the argument
Pico (Pre-merge interference calibration in output-space), which detects and downscales over-shared directions in each task's B matrix before merging and rescales the result afterward.
If this is right
- Merged adapters improve average accuracy by 3.4-8.3 points over base merging methods on math, coding, finance, and medical benchmarks.
- Merged adapters can exceed the performance of a single LoRA trained on all task data together.
- The calibration attaches directly to existing methods such as Task Arithmetic, TIES, and TSV-M.
- Treating the A and B matrices separately during merging reduces interference that treating the full update as one object does not address.
Where Pith is reading between the lines
- Future merging methods may need to handle A and B asymmetrically as a default rather than operating on the combined update.
- The same direction-crowding pattern could be checked in other parameter-efficient fine-tuning techniques to see if similar pre-merge calibration applies.
- Iterative versions of the calibration might allow merging larger numbers of tasks while keeping interference low.
Load-bearing premise
The primary cause of merge interference is over-shared directions in B rather than scaling, noise, or other interactions, and downscaling those directions before merging followed by rescaling preserves task information without new distortions.
What would settle it
A direct test would compare the top principal directions of the B matrices across tasks, apply the downscaling only to those shared directions, and check whether the accuracy gains on the eight benchmarks disappear when the shared directions are left at full scale.
Figures




read the original abstract
Merging separately trained LoRA adapters is a practical alternative to joint multi-task training, but it often hurts performance. Existing methods usually treat the LoRA update $\Delta W = BA$ as a single object and do not distinguish the two LoRA matrices. We show that the main source of LoRA merge interference comes from the output-side matrix $B$. Across tasks, $B$ repeatedly uses a small set of shared directions, while $A$ remains much more task-specific. As a result, the merged adapter overemphasizes these shared directions, and task-specific information is lost. We propose Pico (Pre-merge interference calibration in output-space), a data-free method that calibrates $B$ before merge by downscaling over-shared directions and then rescaling the merged update. Pico plugs directly into existing merging methods such as Task Arithmetic, TIES, and TSV-M. Across eight different benchmarks from math, coding, finance, and medical domains, Pico improves average accuracy by 3.4-8.3 points over the corresponding base method and achieves the best overall average performance. Pico also enables merged adapters to outperform the LoRA trained with all task data. These results show that LoRA merging works better when the two LoRA matrices are treated separately.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that LoRA merge interference stems primarily from over-shared directions in the output matrix B across tasks (while A remains task-specific), causing the merged adapter to overemphasize these directions and lose task-specific information. It proposes Pico, a data-free pre-merge calibration that identifies shared directions in each task's B, downscales them, merges the adapters (plugging into Task Arithmetic, TIES, or TSV-M), and rescales the result. Experiments on eight benchmarks (math, coding, finance, medical) show Pico improves average accuracy by 3.4-8.3 points over base methods and can outperform jointly trained LoRA.
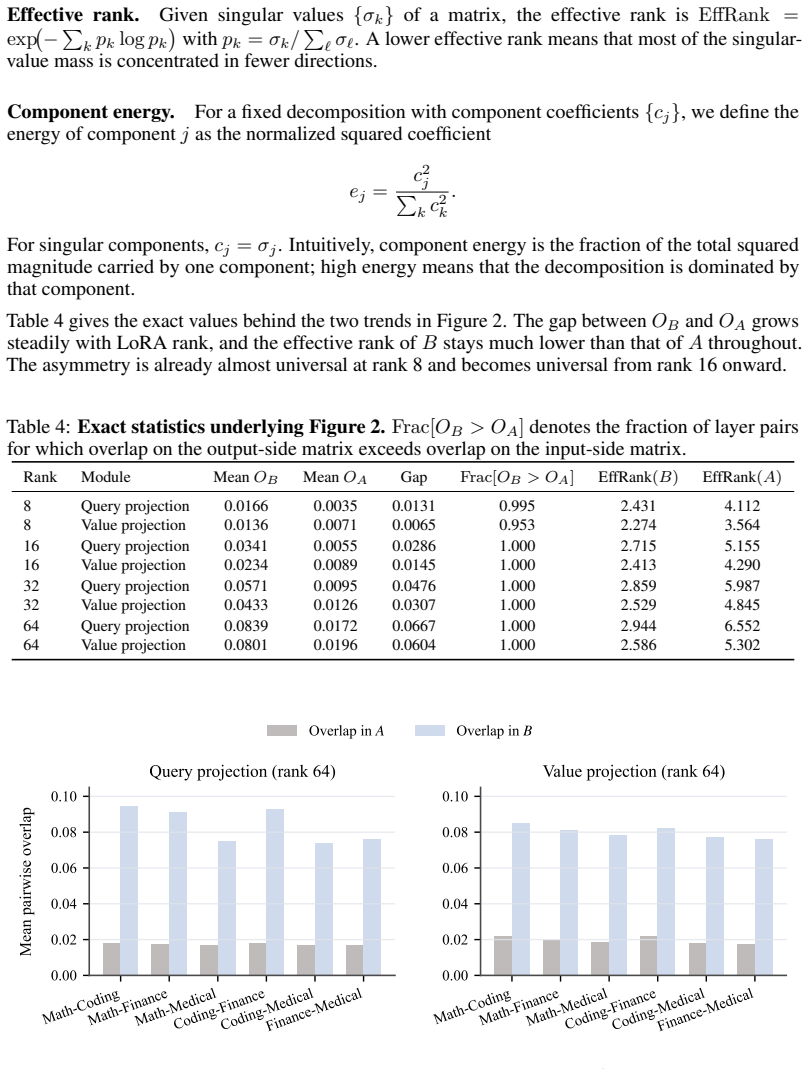
Significance. If the causal attribution and gains hold under controls, Pico offers a lightweight, plug-in enhancement to existing merging techniques by separating treatment of A and B, with potential to improve multi-task adapter deployment without joint training. The empirical consistency across domains and the data-free nature are practical strengths.
major comments (3)
- [§4 and §3.2] §4 (Experiments) and §3.2 (Method): The reported gains are consistent, but the central claim that over-shared directions in B are the primary interference source lacks a control ablation applying identical downscaling/rescaling (same count of directions and scaling factors) to randomly selected or non-shared directions. Without this, the improvements could arise from generic magnitude adjustment or noise suppression rather than the diagnosis of shared directions.
- [§3.1] §3.1 (Observation): The identification of 'shared directions' (via SVD or pairwise similarity on B) and the choice of which directions to downscale require explicit thresholds, selection criteria, and sensitivity analysis; the current description leaves open whether results depend on unstated hyperparameters that could confound the comparison to baselines.
- [§3.3] §3.3 (Pico procedure): The rescaling step after merge is described at a high level; it is unclear whether it exactly restores the original norm per direction or applies a global factor, and how this interacts with the merge operator (e.g., TIES sign election). This detail is load-bearing for reproducibility and for confirming that task-specific information is preserved rather than distorted.
minor comments (2)
- [§3] Notation for the scaling factors and the precise definition of 'over-shared' should be formalized in an equation or algorithm box for clarity.
- [Tables/Figures] Figure captions and table footnotes should explicitly state the number of tasks, LoRA rank, and merge hyperparameters used in each experiment.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below, providing clarifications and indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4 and §3.2] §4 (Experiments) and §3.2 (Method): The reported gains are consistent, but the central claim that over-shared directions in B are the primary interference source lacks a control ablation applying identical downscaling/rescaling (same count of directions and scaling factors) to randomly selected or non-shared directions. Without this, the improvements could arise from generic magnitude adjustment or noise suppression rather than the diagnosis of shared directions.
Authors: We agree that the absence of this control ablation leaves the causal attribution open to alternative explanations such as generic regularization. While §3.1 shows that B matrices exhibit substantially higher directional overlap across tasks than A matrices, and the gains hold when Pico is plugged into multiple merge operators, this does not fully rule out non-specific effects. We will add the requested control experiment in the revised §4, applying identical downscaling and rescaling to randomly selected directions (and separately to non-shared directions) while keeping the number and scaling factors matched, and report the resulting performance. revision: yes
-
Referee: [§3.1] §3.1 (Observation): The identification of 'shared directions' (via SVD or pairwise similarity on B) and the choice of which directions to downscale require explicit thresholds, selection criteria, and sensitivity analysis; the current description leaves open whether results depend on unstated hyperparameters that could confound the comparison to baselines.
Authors: We will revise §3.1 to state the precise identification procedure, including the similarity metric, any threshold applied to declare directions as shared, and the rule for selecting which shared directions to downscale. In addition, we will include a sensitivity analysis that varies these choices over a reasonable range and shows that the reported gains remain stable, thereby addressing potential concerns about hidden hyperparameters. revision: yes
-
Referee: [§3.3] §3.3 (Pico procedure): The rescaling step after merge is described at a high level; it is unclear whether it exactly restores the original norm per direction or applies a global factor, and how this interacts with the merge operator (e.g., TIES sign election). This detail is load-bearing for reproducibility and for confirming that task-specific information is preserved rather than distorted.
Authors: We will expand §3.3 with the exact mathematical definition of the rescaling operation. The procedure computes a per-direction scaling factor from the pre-merge norms of the original B matrices and applies it after the merge operator has been executed (including any sign election or trimming performed by TIES). This ensures that the magnitude of each direction is restored individually rather than via a single global factor. We will also supply pseudocode to make the interaction with each supported merge method fully reproducible. revision: yes
Circularity Check
No significant circularity; empirical observation drives heuristic calibration
full rationale
The paper's chain begins with an empirical observation (B matrices reuse directions across tasks while A remains task-specific) and proceeds to a data-free calibration procedure (downscale shared directions in B pre-merge, rescale post-merge) that is plugged into existing methods. No step reduces by the paper's own equations to a fitted parameter renamed as a prediction, a self-definitional loop, or a load-bearing self-citation whose content is unverified. Reported gains are measured on external benchmarks against base merging methods and full-data LoRA, remaining falsifiable and independent of the diagnostic claim. The derivation is therefore self-contained rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lawyer-instruct
Alignment-Lab-AI (2026). Lawyer-instruct
2026
-
[2]
Program Synthesis with Large Language Models
Austin, J., Odena, A., Nye, M. I., Bosma, M., Michalewski, H., Dohan, D., Jiang, E., Cai, C. J., Terry, M., Le, Q. V ., and Sutton, C. (2021). Program synthesis with large language models.CoRR, abs/2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Cao, C., Lin, H., Zhong, Z., Gao, X., Cai, M., He, C., Han, S., and Wu, L. (2026). Unlocking data value in finance: A study on distillation and difficulty-aware training
2026
-
[4]
Chen, M., Tworek, J., Jun, H., Yuan, Q., de Oliveira Pinto, H. P., Kaplan, J., Edwards, H., Burda, Y ., Joseph, N., Brockman, G., Ray, A., Puri, R., Krueger, G., Petrov, M., Khlaaf, H., Sastry, G., Mishkin, P., Chan, B., Gray, S., Ryder, N., Pavlov, M., Power, A., Kaiser, L., Bavarian, M., Winter, C., Tillet, P., Such, F. P., Cummings, D., Plappert, M., C...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Chen, Z., Li, S., Smiley, C., Ma, Z., Shah, S., and Wang, W. Y . (2022). Convfinqa: Exploring the chain of numerical reasoning in conversational finance question answering. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, pages 6279–6292. Association...
2022
-
[6]
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. (2021). Training verifiers to solve math word problems.CoRR, abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
T., Bhardwaj, R., and Poria, S
Deep, P. T., Bhardwaj, R., and Poria, S. (2024). Della-merging: Reducing interference in model merging through magnitude-based sampling
2024
-
[8]
A., Crisostomi, D., Bucarelli, M
Gargiulo, A. A., Crisostomi, D., Bucarelli, M. S., Scardapane, S., Silvestri, F., and Rodolà, E. (2025). Task singular vectors: Reducing task interference in model merging. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 18695–18705. Computer Vision Foundation / IEEE
2025
-
[9]
Guo, P., Zeng, S., Wang, Y ., Fan, H., Wang, F., and Qu, L. (2025). Selective aggregation for low-rank adaptation in federated learning. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net
2025
-
[10]
Hayou, S., Ghosh, N., and Yu, B. (2024). Lora+: Efficient low rank adaptation of large models. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024, Proceedings of Machine Learning Research, pages 17783–17806. PMLR / OpenReview.net
2024
-
[11]
J., yelong shen, Wallis, P., Allen-Zhu, Z., Li, Y ., Wang, S., Wang, L., and Chen, W
Hu, E. J., yelong shen, Wallis, P., Allen-Zhu, Z., Li, Y ., Wang, S., Wang, L., and Chen, W. (2022). LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations
2022
-
[12]
T., Wortsman, M., Schmidt, L., Hajishirzi, H., and Farhadi, A
Ilharco, G., Ribeiro, M. T., Wortsman, M., Schmidt, L., Hajishirzi, H., and Farhadi, A. (2023). Editing models with task arithmetic. InThe Eleventh International Conference on Learning Representations
2023
- [13]
- [14]
-
[15]
W., and Lu, X
Jin, Q., Dhingra, B., Liu, Z., Cohen, W. W., and Lu, X. (2019). Pubmedqa: A dataset for biomedical research question answering. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019, pages 25...
2019
-
[16]
Gemini Embedding: Generalizable Embeddings from Gemini
Lee, J., Chen, F., Dua, S., Cer, D., Shanbhogue, M., Naim, I., Ábrego, G. H., Li, Z., Chen, K., Vera, H. S., Ren, X., Zhang, S., Salz, D., Boratko, M., Han, J., Chen, B., Huang, S., Rao, V ., Suganthan, P., Han, F., Doumanoglou, A., Gupta, N., Moiseev, F., Yip, C., Jain, A., Baumgartner, S., Shahi, S., Gomez, F. P., Mariserla, S., Choi, M., Shah, P., Goen...
work page internal anchor Pith review arXiv 2025
-
[17]
Li, Y ., Peng, Z., Zhang, J., Guo, J., Duan, Y ., and Shi, Y . (2026). When shared knowledge hurts: Spectral over-accumulation in model merging
2026
-
[18]
Lightman, H., Kosaraju, V ., Burda, Y ., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., and Cobbe, K. (2024). Let’s verify step by step. InThe Twelfth International Confer- ence on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net
2024
-
[19]
F., Cheng, K., and Chen, M
Liu, S., Wang, C., Yin, H., Molchanov, P., Wang, Y . F., Cheng, K., and Chen, M. (2024). Dora: Weight-decomposed low-rank adaptation. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024, Proceedings of Machine Learning Research, pages 32100–32121. PMLR / OpenReview.net
2024
-
[20]
Medical-reasoning-sft-trinity-mini
OpenMed (2025). Medical-reasoning-sft-trinity-mini
2025
-
[21]
D., Calderara, S., and van de Weijer, J
Panariello, A., Marczak, D., Magistri, S., Porrello, A., Twardowski, B., Bagdanov, A. D., Calderara, S., and van de Weijer, J. (2025). Accurate and efficient low-rank model merging in core space. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[22]
Prabhakar, A., Li, Y ., Narasimhan, K., Kakade, S., Malach, E., and Jelassi, S. (2025). Lora soups: Merging loras for practical skill composition tasks. InProceedings of the 31st International Conference on Computational Linguistics: Industry Track, pages 644–655
2025
-
[23]
Stoica, G., Ramesh, P., Ecsedi, B., Choshen, L., and Hoffman, J. (2025). Model merging with SVD to tie the knots. InThe Thirteenth International Conference on Learning Representations
2025
-
[24]
Team, L. (2024). The llama 3 herd of models.CoRR, abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Tian, C., Shi, Z., Guo, Z., Li, L., and zhong Xu, C. (2024). HydraloRA: An asymmetric loRA architecture for efficient fine-tuning. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
-
[26]
Wei, Y ., Wang, Z., Liu, J., Ding, Y ., and Zhang, L. (2024). Magicoder: Empowering code generation with oss-instruct. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024, Proceedings of Machine Learning Research, pages 52632–52657. PMLR / OpenReview.net
2024
-
[27]
Y ., Roelofs, R., Lopes, R
Wortsman, M., Ilharco, G., Gadre, S. Y ., Roelofs, R., Lopes, R. G., Morcos, A. S., Namkoong, H., Farhadi, A., Carmon, Y ., Kornblith, S., and Schmidt, L. (2022). Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. In Chaudhuri, K., Jegelka, S., Song, L., Szepesvári, C., Niu, G., and Sabato, S....
2022
-
[28]
Yadav, P., Tam, D., Choshen, L., Raffel, C., and Bansal, M. (2023). TIES-merging: Resolv- ing interference when merging models. InThirty-seventh Conference on Neural Information Processing Systems. 11
2023
-
[29]
T., Li, Z., Weller, A., and Liu, W
Yu, L., Jiang, W., Shi, H., Yu, J., Liu, Z., Zhang, Y ., Kwok, J. T., Li, Z., Weller, A., and Liu, W. (2024a). Metamath: Bootstrap your own mathematical questions for large language models. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net
2024
-
[30]
Yu, L., Yu, B., Yu, H., Huang, F., and Li, Y . (2024b). Language models are super mario: absorb- ing abilities from homologous models as a free lunch. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org
-
[31]
Zhang, L., Zhang, L., Shi, S., Chu, X., and Li, B. (2023). Lora-fa: Memory-efficient low-rank adaptation for large language models fine-tuning.CoRR, abs/2308.03303
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Zhang, Y ., Li, M., Long, D., Zhang, X., Lin, H., Yang, B., Xie, P., Yang, A., Liu, D., Lin, J., Huang, F., and Zhou, J. (2025). Qwen3 embedding: Advancing text embedding and reranking through foundation models.CoRR, abs/2506.05176
work page internal anchor Pith review arXiv 2025
-
[33]
Zhao, Z., Shen, T., Zhu, D., Li, Z., Su, J., Wang, X., and Wu, F. (2025). Merging loras like playing LEGO: pushing the modularity of lora to extremes through rank-wise clustering. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net
2025
-
[34]
B., Choshen, L., Ghassemi, M., Yurochkin, M., and Solomon, J
Zhu, J., Greenewald, K., Nadjahi, K., Sáez De Ocáriz Borde, H., Gabrielsson, R. B., Choshen, L., Ghassemi, M., Yurochkin, M., and Solomon, J. (2024). Asymmetry in low-rank adapters of foundation models. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 62369–62385. PMLR. A ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.