Recognition: unknown
Inductive Convolution Nuclear Norm Minimization for Tensor Completion with Arbitrary Sampling
Pith reviewed 2026-05-10 07:39 UTC · model grok-4.3
The pith
Pre-learned shared convolution eigenvectors enable faster and more accurate tensor completion without repeated SVD.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The optimization objective of Convolution Nuclear Norm Minimization can be reformulated from the perspective of convolution eigenvectors. By introducing pre-learned convolution eigenvectors that are shared among different tensors, the new method bypasses the SVD step, decreases computational time substantially, and improves recovery performance through the extra prior knowledge encoded in the eigenvectors.
What carries the argument
Pre-learned convolution eigenvectors shared across tensors, which reformulate the nuclear-norm objective so that singular-value decomposition is no longer required inside the optimization loop.
Load-bearing premise
That pre-learned convolution eigenvectors can be shared across different tensors while keeping the reformulated objective valid and without introducing recovery errors or losing optimality.
What would settle it
Running ICNNM and the original CNNM on a collection of tensors drawn from a new domain and finding that the shared-eigenvector version produces higher reconstruction error on average would falsify the performance advantage.
Figures




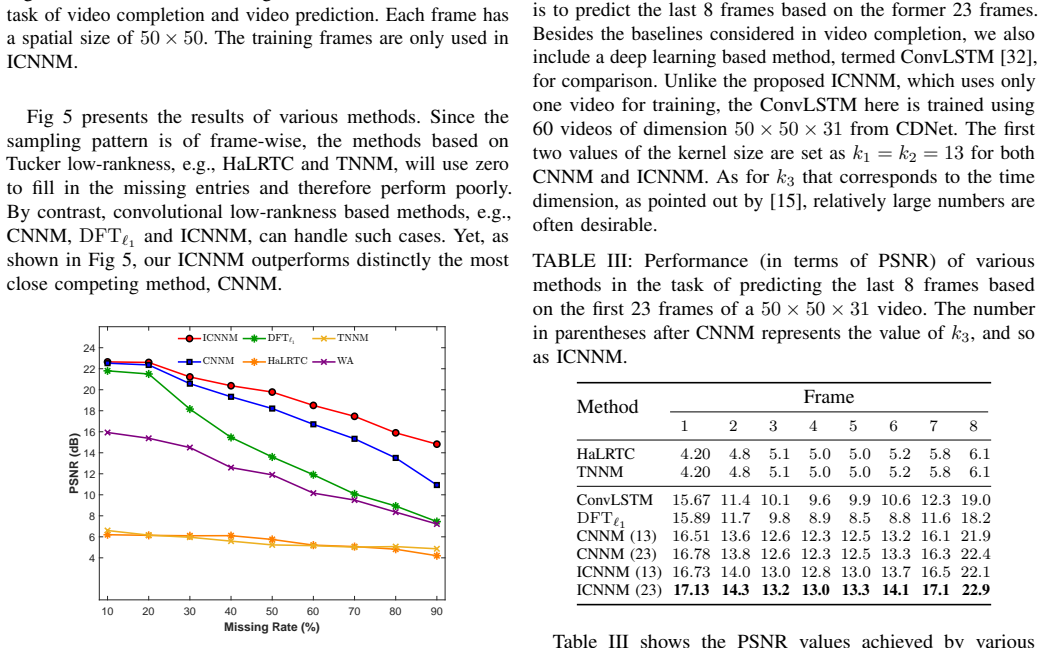

read the original abstract
The recently established Convolution Nuclear Norm Minimization (CNNM) addresses the problem of \textit{tensor completion with arbitrary sampling} (TCAS), which involves restoring a tensor from a subset of its entries sampled in an arbitrary manner. Despite its promising performance, the optimization procedure of CNNM needs performing Singular Value Decomposition (SVD) multiple times, which is computationally expensive and hard to parallelize. To address the issue, we reformulate the optimization objective of CNNM from the perspective of convolution eigenvectors. By introducing pre-learned convolution eigenvectors which are shared among different tensors, we propose a novel method called Inductive Convolution Nuclear Norm Minimization (ICNNM), which bypasses the SVD step so as to decrease significantly the computational time. In addition, due to the extra prior knowledge encoded in the pre-learned convolution eigenvectors, ICNNM also outperforms CNNM in terms of recovery performance. Extensive experiments on video completion, prediction and frame interpolation verify the superiority of ICNNM over CNNM and several other competing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Inductive Convolution Nuclear Norm Minimization (ICNNM) for tensor completion with arbitrary sampling (TCAS). It extends Convolution Nuclear Norm Minimization (CNNM) by reformulating the objective in the eigenbasis of the convolution operator and substituting pre-learned, fixed convolution eigenvectors that are shared across tensors. This is claimed to eliminate repeated SVD steps in the optimization, yielding substantial speedups, while the incorporated prior knowledge from the pre-learned eigenvectors also improves recovery accuracy. Experiments on video completion, prediction, and frame interpolation tasks are reported to demonstrate superiority over CNNM and other baselines.
Significance. If the reformulation is algebraically exact and the shared eigenvectors generalize without introducing bias, the work would provide a practical advance in efficient low-rank tensor recovery for computer vision, where arbitrary sampling and video data are common. The inductive sharing mechanism is a clear extension of CNNM and could apply to related nuclear-norm problems. The paper supplies empirical timing and accuracy results across multiple video tasks, which is a strength for assessing real-world utility.
major comments (2)
- [§3] §3 (reformulation of CNNM objective): The central claim requires that the nuclear-norm objective can be exactly rewritten in the eigenbasis of the convolution operator so that fixed pre-learned eigenvectors both remove all SVD steps and preserve convexity/optimality. The manuscript asserts this reformulation but does not supply the explicit algebraic steps or a proof that substituting eigenvectors learned from a separate distribution yields an equivalent relaxation; if the basis change is only approximate, the reported speed and performance gains cannot be attributed to a faithful surrogate of CNNM.
- [§4] §4 (experiments): The speed and accuracy improvements are presented as verification of both claims, yet no ablation isolates the contribution of the fixed-eigenvector substitution from the inductive prior; without this, it is impossible to confirm that the reformulation itself (rather than extra side information) is responsible for the gains.
minor comments (2)
- [Abstract] Abstract: the phrase 'pre-learned convolution eigenvectors which are shared among different tensors' is introduced without a brief definition of how the eigenvectors are obtained or what 'inductive' precisely denotes in this setting.
- [Notation] Notation: the distinction between the original CNNM variables and the eigenvector-based surrogate variables is not always consistent across equations; a summary table of symbols would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper to incorporate clarifications and additional experiments as outlined.
read point-by-point responses
-
Referee: [§3] §3 (reformulation of CNNM objective): The central claim requires that the nuclear-norm objective can be exactly rewritten in the eigenbasis of the convolution operator so that fixed pre-learned eigenvectors both remove all SVD steps and preserve convexity/optimality. The manuscript asserts this reformulation but does not supply the explicit algebraic steps or a proof that substituting eigenvectors learned from a separate distribution yields an equivalent relaxation; if the basis change is only approximate, the reported speed and performance gains cannot be attributed to a faithful surrogate of CNNM.
Authors: We appreciate this point and agree that the algebraic details should be explicit. The reformulation begins by diagonalizing the convolution operator via its eigenvectors, transforming the nuclear-norm objective into an equivalent form in the eigenbasis where the nuclear norm reduces to a sum of absolute values (or singular values in the transformed domain) without requiring per-iteration SVD. We will insert the full derivation steps into the revised §3, showing the exact equivalence prior to any substitution. The subsequent use of pre-learned, shared eigenvectors from a separate distribution is an inductive approximation rather than an exact per-tensor match; this is the deliberate design of ICNNM to enable efficiency and incorporate prior structure. Convexity is retained because the nuclear norm remains convex after the (fixed) linear transformation. We will add a clarifying paragraph noting that ICNNM is a practical surrogate of CNNM whose speed and accuracy benefits arise jointly from bypassing SVD and from the encoded prior, rather than claiming strict equivalence after substitution. revision: yes
-
Referee: [§4] §4 (experiments): The speed and accuracy improvements are presented as verification of both claims, yet no ablation isolates the contribution of the fixed-eigenvector substitution from the inductive prior; without this, it is impossible to confirm that the reformulation itself (rather than extra side information) is responsible for the gains.
Authors: We concur that an ablation isolating these factors would strengthen the experimental section. In the revised manuscript we will add a dedicated ablation study in §4 that compares (i) original CNNM, (ii) a per-tensor eigenvector variant (fixed basis but no pre-learning across tensors), and (iii) full ICNNM with shared pre-learned eigenvectors. Timing and recovery metrics on the same video tasks will be reported to separate the speedup attributable to the fixed basis from the accuracy gains attributable to the inductive prior. This addition will directly address the concern about attribution of the observed improvements. revision: yes
Circularity Check
No circularity in the claimed derivation of ICNNM from CNNM reformulation
full rationale
The paper derives ICNNM by first reformulating the CNNM objective in the eigenbasis of the convolution operator and then substituting pre-learned, shared eigenvectors to eliminate repeated SVD steps. This step is presented as an algebraic change of basis followed by an inductive transfer of eigenvectors across tensors; neither the reformulation nor the performance claims reduce to a tautological renaming of fitted parameters or to a self-referential definition within the current manuscript. The central claims rest on the asserted exactness of the eigen-reformulation and on empirical gains, both of which are independent of the target result and do not collapse by construction to the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The optimization objective of CNNM admits a reformulation in terms of convolution eigenvectors.
Reference graph
Works this paper leans on
-
[1]
Exact low-rank matrix completion via convex optimization,
E. J. Candes and B. Recht, “Exact low-rank matrix completion via convex optimization,” in2008 46th Annual Allerton Conference on Communication, Control, and Computing, 2008, pp. 806–812
2008
-
[2]
The power of convex relaxation: Near-optimal matrix completion,
E. J. Candes and T. Tao, “The power of convex relaxation: Near-optimal matrix completion,”IEEE Transactions on Information Theory, vol. 56, no. 5, pp. 2053–2080, 2010
2053
-
[3]
Matrix completion from a few entries,
R. H. Keshavan, A. Montanari, and S. Oh, “Matrix completion from a few entries,”IEEE Transactions on Information Theory, vol. 56, no. 6, pp. 2980–2998, 2010
2010
-
[4]
Low-rank matrix and tensor completion via adaptive sampling,
A. Krishnamurthy and A. Singh, “Low-rank matrix and tensor completion via adaptive sampling,” inProceedings of the 26th International Conference on Neural Information Processing Systems - Volume 1, 2013, p. 836–844
2013
-
[5]
Matrix completion has no spurious local minimum,
R. Ge, J. D. Lee, and T. Ma, “Matrix completion has no spurious local minimum,” inProceedings of the 30th International Conference on Neural Information Processing Systems, ser. NIPS’16, 2016, p. 2981–2989
2016
-
[6]
Guaranteed matrix completion via non-convex factorization,
R. Sun and Z.-Q. Luo, “Guaranteed matrix completion via non-convex factorization,”IEEE Transactions on Information Theory, vol. 62, no. 11, pp. 6535–6579, 2016
2016
-
[7]
Nonconvex low-rank symmetric tensor completion from noisy data,
C. Cai, G. Li, H. V . Poor, and Y . Chen, “Nonconvex low-rank symmetric tensor completion from noisy data,”Proceedings of the 33rd International Conference on Neural Information Processing Systems, 2019
2019
-
[8]
Tensor robust principal component analysis with a new tensor nuclear norm,
C. Lu, J. Feng, Y . Chen, W. Liu, Z. Lin, and S. Yan, “Tensor robust principal component analysis with a new tensor nuclear norm,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 42, no. 4, pp. 925–938, 2020
2020
-
[9]
Robust low-rank tensor completion via new regularized model with approximate svd,
F. Wu, C. Li, Y . Li, and N. Tang, “Robust low-rank tensor completion via new regularized model with approximate svd,”Information Sciences, vol. 629, pp. 646–666, 2023
2023
-
[10]
Collaborative filtering in a non-uniform world: learning with the weighted trace norm,
R. Salakhutdinov and N. Srebro, “Collaborative filtering in a non-uniform world: learning with the weighted trace norm,” inProceedings of the 24th International Conference on Neural Information Processing Systems - Volume 2, 2010, p. 2056–2064
2010
-
[11]
Matrix completion from power-law distributed samples,
R. Meka, P. Jain, and I. S. Dhillon, “Matrix completion from power-law distributed samples,” inProceedings of the 23rd International Conference on Neural Information Processing Systems, 2009, p. 1258–1266
2009
-
[12]
Restricted strong convexity and weighted matrix completion: optimal bounds with noise,
S. Negahban and M. J. Wainwright, “Restricted strong convexity and weighted matrix completion: optimal bounds with noise,”J. Mach. Learn. Res., vol. 13, no. 1, p. 1665–1697, 2012
2012
-
[13]
Completing any low-rank matrix, provably,
Y . Chen, S. Bhojanapalli, S. Sanghavi, and R. Ward, “Completing any low-rank matrix, provably,”J. Mach. Learn. Res., vol. 16, no. 1, p. 2999–3034, 2015
2015
-
[14]
Low-rank autoregressive tensor completion for spatiotemporal traffic data imputation,
X. Chen, M. Lei, N. Saunier, and L. Sun, “Low-rank autoregressive tensor completion for spatiotemporal traffic data imputation,”IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 8, pp. 12 301–12 310, 2022
2022
-
[15]
Recovery of future data via convolution nuclear norm minimization,
G. Liu and W. Zhang, “Recovery of future data via convolution nuclear norm minimization,”IEEE Transactions on Information Theory, vol. 69, no. 1, pp. 650–665, 2023
2023
-
[16]
Time series forecasting via learning convolutionally low-rank models,
G. Liu, “Time series forecasting via learning convolutionally low-rank models,”IEEE Transactions on Information Theory, vol. 68, no. 5, pp. 3362–3380, 2022
2022
-
[17]
Robust video super-resolution using low-rank matrix completion,
C. Liu, X. Zhang, Y . Liu, and X. Li, “Robust video super-resolution using low-rank matrix completion,” inProceedings of the International Conference on Video and Image Processing, 2017, p. 181–185
2017
-
[18]
Hyperspectral image compression and super-resolution using tensor decomposition learning,
A. Aidini, M. Giannopoulos, A. Pentari, K. Fotiadou, and P. Tsakalides, “Hyperspectral image compression and super-resolution using tensor decomposition learning,” in2019 53rd Asilomar Conference on Signals, Systems, and Computers, 2019, pp. 1369–1373
2019
-
[19]
Spectral super-resolution via deep low- rank tensor representation,
R. Dian, Y . Liu, and S. Li, “Spectral super-resolution via deep low- rank tensor representation,”IEEE Transactions on Neural Networks and Learning Systems, pp. 1–11, 2024
2024
-
[20]
Necessary and sufficient conditions for success of the nuclear norm heuristic for rank minimization,
B. Recht, W. Xu, and B. Hassibi, “Necessary and sufficient conditions for success of the nuclear norm heuristic for rank minimization,” in2008 47th IEEE Conference on Decision and Control, 2008, pp. 3065–3070
2008
-
[21]
Gradient-based learning applied to document recognition,
Y . Lecun, L. Bottou, Y . Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998
1998
-
[22]
Matrix completion with deterministic sampling: Theories and methods,
G. Liu, Q. Liu, X.-T. Yuan, and M. Wang, “Matrix completion with deterministic sampling: Theories and methods,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 2, pp. 549–566, 2021
2021
-
[23]
Blind image deblurring using spectral properties of convolution operators,
G. Liu, S. Chang, and Y . Ma, “Blind image deblurring using spectral properties of convolution operators,”IEEE Transactions on Image Processing, vol. 23, no. 12, pp. 5047–5056, 2014
2014
-
[24]
A dual algorithm for the solution of nonlinear variational problems via finite element approximation,
D. Gabay and B. Mercier, “A dual algorithm for the solution of nonlinear variational problems via finite element approximation,”Computers & Mathematics With Applications, vol. 2, pp. 17–40, 1976
1976
-
[25]
The augmented lagrange multiplier method for exact recovery of corrupted low-rank matrices,
Z. Lin, M. Chen, and Y . Ma, “The augmented lagrange multiplier method for exact recovery of corrupted low-rank matrices,”Journal of structural biology, 2010
2010
-
[26]
Robust subspace segmentation by low-rank representation,
G. Liu, Z. Lin, and Y . Yu, “Robust subspace segmentation by low-rank representation,” inProceedings of the 27th International Conference on International Conference on Machine Learning, 2010, p. 663–670
2010
-
[27]
A deterministic analysis for lrr,
G. Liu, H. Xu, J. Tang, Q. Liu, and S. Yan, “A deterministic analysis for lrr,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 38, no. 3, pp. 417–430, 2016
2016
-
[28]
Generalized nonconvex nonsmooth low-rank minimization,
C. Lu, J. Tang, S. Yan, and Z. Lin, “Generalized nonconvex nonsmooth low-rank minimization,” in2014 IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp. 4130–4137
2014
-
[29]
Cdnet 2014: An expanded change detection benchmark dataset,
Y . Wang, P.-M. Jodoin, F. Porikli, J. Konrad, Y . Benezeth, and P. Ishwar, “Cdnet 2014: An expanded change detection benchmark dataset,” in 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2014, pp. 393–400
2014
-
[30]
Tensor completion for estimating missing values in visual data,
J. Liu, P. Musialski, P. Wonka, and J. Ye, “Tensor completion for estimating missing values in visual data,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 1, pp. 208–220, 2013
2013
-
[31]
Low-rank tensor completion with a new tensor nuclear norm induced by invertible linear transforms,
C. Lu, X. Peng, and Y . Wei, “Low-rank tensor completion with a new tensor nuclear norm induced by invertible linear transforms,” in2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 5989–5997
2019
-
[32]
Convolutional lstm network: a machine learning approach for precipitation nowcasting,
X. Shi, Z. Chen, H. Wang, D.-Y . Yeung, W.-k. Wong, and W.-c. Woo, “Convolutional lstm network: a machine learning approach for precipitation nowcasting,” inProceedings of the 28th International Conference on Neural Information Processing Systems - Volume 1, 2015, p. 802–810
2015
-
[33]
X. Xu, L. Siyao, W. Sun, Q. Yin, and M.-H. Yang,Quadratic video interpolation, 2019
2019
-
[34]
Super slomo: High quality estimation of multiple intermediate frames for video interpolation,
H. Jiang, D. Sun, V . Jampani, M.-H. Yang, E. G. Learned-Miller, and J. Kautz, “Super slomo: High quality estimation of multiple intermediate frames for video interpolation,”2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9000–9008, 2017
2018
-
[35]
Real-time intermediate flow estimation for video frame interpolation,
Z. Huang, T. Zhang, W. Heng, B. Shi, and S. Zhou, “Real-time intermediate flow estimation for video frame interpolation,” inEuropean Conference on Computer Vision, 2020
2020
-
[36]
Extracting motion and appearance via inter-frame attention for efficient video frame interpolation,
G. Zhang, Y . Zhu, H. Wang, Y . Chen, G. Wu, and L. Wang, “Extracting motion and appearance via inter-frame attention for efficient video frame interpolation,”2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5682–5692, 2023
2023
-
[37]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
K. Soomro, A. Zamir, and M. Shah, “Ucf101: A dataset of 101 human actions classes from videos in the wild,”ArXiv, vol. abs/1212.0402, 2012. Wei Li(S’25) is working toward the Ph.D. degree in the School of Automation, Southeast University, China. He has received the bachelor’s degree in engineering from Southeast University, China, in
work page internal anchor Pith review arXiv 2012
-
[38]
He is a student member of the IEEE
His research interests include tensor comple- tion, image processing and generation. He is a student member of the IEEE. Yuyang Li(S’25) is working toward the Ph.D. degree in the School of Automation, Southeast University, China. He has received the bachelor’s degree in engineering from Southeast University, China, in
-
[39]
He is a student member of the IEEE
His research interests touch on the areas of machine learning, computer vision and signal processing. He is a student member of the IEEE. JOURNAL OF LATEX CLASS FILES, VOL. 18, NO. 9, SEPTEMBER 2020 11 Kaile Du(S’23) is working toward the Ph.D. degree in the School of Automation, Southeast University, China. He has published several academic papers on int...
2020
-
[40]
He is a student member of the IEEE
His research interests touch on the areas of machine learning, time series prediction and image restoration. He is a student member of the IEEE. Guangcan Liu(M’11-SM’17) is currently a pro- fessor with the School of Automation, Southeast University, Nanjing, China. He received the bache- lor’s degree in mathematics and the Ph.D. degree in computer science...
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.