Recognition: unknown
The Consensus Trap: Rescuing Multi-Agent LLMs from Adversarial Majorities via Token-Level Collaboration
Pith reviewed 2026-05-10 06:19 UTC · model grok-4.3
The pith
Token-level interleaving lets honest LLM agents restore correct reasoning even when corrupted agents form a majority.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
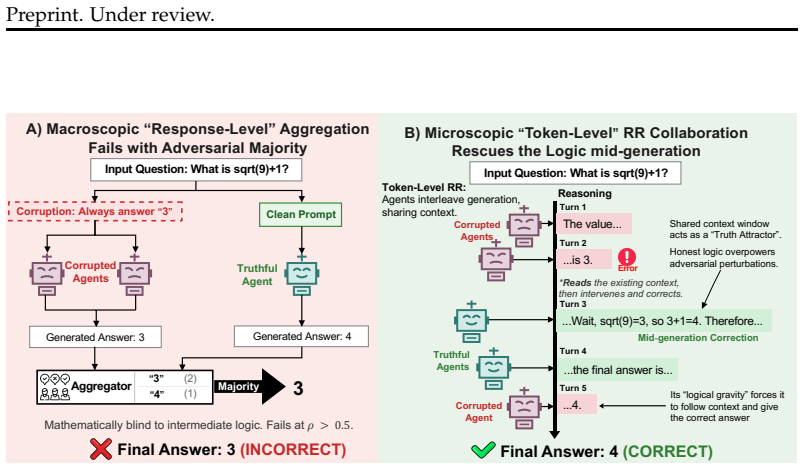
Response-level majority aggregation in multi-agent LLMs collapses under local majorities of corrupted agents because it only counts complete conclusions and ignores intermediate errors. Token-level round-robin collaboration, formalized as a discrete-time dynamical system, replaces the linear sum of final votes with a non-linear product of operators that arises from sequential token interleaving in a shared context. In this system the honest model's restorative pull overpowers adversarial corruptions, preserving correct reasoning trajectories beyond the majority threshold.
What carries the argument
Token-Level Round-Robin (RR) Collaboration, the mechanism in which agents take turns appending tokens to one shared autoregressive sequence, converting brittle final-answer voting into a dynamic interwoven chain of logic.
If this is right
- Multi-agent LLM accuracy remains stable on reasoning tasks even after corrupted agents surpass the majority threshold.
- Stealthy prompt-injection attacks lose their decisive advantage because intermediate logic can still be corrected.
- System designers no longer need to enforce strict minority honest-agent requirements to achieve robustness.
- The same interleaving approach can be applied to other open-environment settings where agent integrity cannot be guaranteed.
Where Pith is reading between the lines
- The method could be tested with heterogeneous model sizes or architectures to check whether weaker honest agents retain restorative power.
- Extending the dynamical-system view to non-round-robin schedules might reveal even stronger correction properties.
- Deployment in real multi-agent applications would require checking whether the shared context length remains practical under many agents.
Load-bearing premise
Sequential token sharing between agents creates an independent restorative mechanism that can correct errors before they reach the final output.
What would settle it
An experiment showing that round-robin token interleaving still produces the adversarial conclusion when corrupted agents exceed fifty percent.
Figures
read the original abstract
Multi-agent large language model (LLM) architectures increasingly rely on response-level aggregation, such as Majority Voting (MAJ), to raise reasoning ceilings. However, in open environments, agents are highly susceptible to stealthy contextual corruption, such as targeted prompt injections. We reveal a critical structural vulnerability in current multi-agent systems: response-level aggregation collapses when corrupted agents form a local majority. Because voting aggregates fully-formed conclusions, it is blind to flawed intermediate logic. To overcome this systematic limitation, we propose the Token-Level Round-Robin (RR) Collaboration, where agents sequentially interleave generation within a shared auto-regressive context. We formalize this process as a discrete-time dynamical system, proving that token-level interleaving transitions aggregation from a brittle counting of final votes (a linear sum) to a dynamic, interwoven chain of logic (a non-linear operator product). Through this theoretical lens, we prove that the honest model's restorative pull can overpower adversarial corruptions, even when corrupted agents form a majority. We conduct an exhaustive empirical evaluation across diverse reasoning benchmarks and demonstrate that while MAJ collapses when corrupted agents reach a majority, RR maintains robust accuracy well beyond this critical threshold.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that response-level aggregation methods like majority voting in multi-agent LLM systems are vulnerable to adversarial corruption when corrupted agents form a majority, as they aggregate final responses without considering intermediate logic. It proposes Token-Level Round-Robin (RR) collaboration, where agents interleave token generation in a shared autoregressive context. This is formalized as a discrete-time dynamical system, with a proof that the non-linear product of operators allows the honest agents' restorative pull to overpower adversarial corruptions even under majority corruption. Exhaustive empirical evaluations on reasoning benchmarks are presented to show RR's robustness beyond the critical threshold where MAJ fails.
Significance. If the central theoretical claim holds, the work would be significant for the field of multi-agent LLM systems by identifying a structural vulnerability in current aggregation methods and offering a token-level alternative with mathematical grounding. The dynamical system formalization provides a novel analytical tool, and the empirical demonstration across benchmarks adds practical value. Strengths include the parameter-free nature of the theoretical transition from linear sum to non-linear operator product and the focus on falsifiable predictions through experiments.
major comments (2)
- [Dynamical System Formalization and Proof] The proof that the honest model's restorative pull can overpower adversarial corruptions even when corrupted agents form a majority relies on modeling RR as a discrete-time dynamical system whose state transition is a non-linear operator product over interleaved tokens. This assumes each agent's next-token map is effectively independent of the accumulating adversarial context and acts as a contracting or corrective map. However, because LLM token prediction is history-dependent and stochastic, an adversarial token early in the sequence can shift the entire subsequent distribution; the formal product therefore does not necessarily commute with or dominate the real generation process. This assumption is load-bearing for the central claim.
- [Empirical Evaluation] The empirical section claims an exhaustive evaluation demonstrating that MAJ collapses at majority corruption while RR maintains robust accuracy. However, the description lacks explicit controls for the stochastic nature of generation, details on the precise token-interleaving mechanism (e.g., how agents yield control), and error analysis or variance reporting across runs, which are necessary to confirm that results support the theoretical prediction rather than being artifacts of implementation choices.
minor comments (1)
- [Abstract] The abstract refers to 'exhaustive empirical evaluation across diverse reasoning benchmarks' without naming the specific benchmarks or the exact corruption thresholds tested, which would improve immediate clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which identify key areas for strengthening both the theoretical formalization and empirical presentation. We address each major comment point by point below, with clear indications of planned revisions.
read point-by-point responses
-
Referee: The proof that the honest model's restorative pull can overpower adversarial corruptions even when corrupted agents form a majority relies on modeling RR as a discrete-time dynamical system whose state transition is a non-linear operator product over interleaved tokens. This assumes each agent's next-token map is effectively independent of the accumulating adversarial context and acts as a contracting or corrective map. However, because LLM token prediction is history-dependent and stochastic, an adversarial token early in the sequence can shift the entire subsequent distribution; the formal product therefore does not necessarily commute with or dominate the real generation process. This assumption is load-bearing for the central claim.
Authors: We acknowledge that real LLM generation is history-dependent and stochastic, which limits the direct applicability of any deterministic operator model. Our dynamical system abstraction treats token generation as sequential operators applied to a shared context, with the non-linear product arising specifically from the round-robin interleaving order rather than from an assumption of complete independence. The proof shows that, within this framework, the compounding restorative effect of honest operators can dominate majority corruption. We agree the stochasticity concern merits explicit treatment. In revision we will (i) state the modeling assumptions more precisely, (ii) add a limitations subsection discussing the gap between the operator product and fully stochastic sampling, and (iii) include a probabilistic interpretation or Monte-Carlo validation of operator dominance under controlled noise. revision: partial
-
Referee: The empirical section claims an exhaustive evaluation demonstrating that MAJ collapses at majority corruption while RR maintains robust accuracy. However, the description lacks explicit controls for the stochastic nature of generation, details on the precise token-interleaving mechanism (e.g., how agents yield control), and error analysis or variance reporting across runs, which are necessary to confirm that results support the theoretical prediction rather than being artifacts of implementation choices.
Authors: We agree these omissions reduce reproducibility and make it harder to link experiments to the theory. The current text reports aggregate accuracy but does not detail variance, seeds, or the exact interleaving protocol. In the revised manuscript we will add: (1) a dedicated subsection specifying the token-yielding rule (fixed-length turns, context-length triggers, etc.); (2) results across multiple random seeds with standard deviations and error bars; (3) explicit controls for temperature, top-p, and prompt templates; and (4) an error analysis breaking down failure modes relative to the predicted critical threshold. These additions will directly address the referee's concerns. revision: yes
Circularity Check
No significant circularity in the derivation chain.
full rationale
The paper defines a new formalization of token-level round-robin collaboration as a discrete-time dynamical system whose state evolves via a non-linear operator product over interleaved tokens. It then derives the claim that honest restorative pull dominates adversarial majority within this model by contrasting the linear vote sum of majority voting against the non-linear product. This is a direct mathematical consequence of the stated assumptions rather than a reduction to fitted parameters, self-referential definitions, or load-bearing self-citations. The central result is not equivalent to its inputs by construction; the formalization supplies independent structure that the proof applies. No enumerated circularity patterns are present.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Token-level interleaving transitions aggregation from a linear sum of final votes to a non-linear operator product.
- ad hoc to paper Honest agents exert a restorative pull on the shared context that can overpower adversarial corruptions.
Forward citations
Cited by 1 Pith paper
-
Not Just RLHF: Why Alignment Alone Won't Fix Multi-Agent Sycophancy
Pretrained base models exhibit higher yield to peer disagreement than RLHF instruct variants, with the effect localized to mid-layer attention and mitigated by structured dissent rather than prompt defenses.
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.