DREAM: Dynamic Retinal Enhancement with Adaptive Multi-modal Fusion for Expert Precision Medical Report Generation
Pith reviewed 2026-05-10 07:14 UTC · model grok-4.3
The pith
DREAM generates more accurate medical reports from retinal images by adaptively fusing visual data with ophthalmologist keywords.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
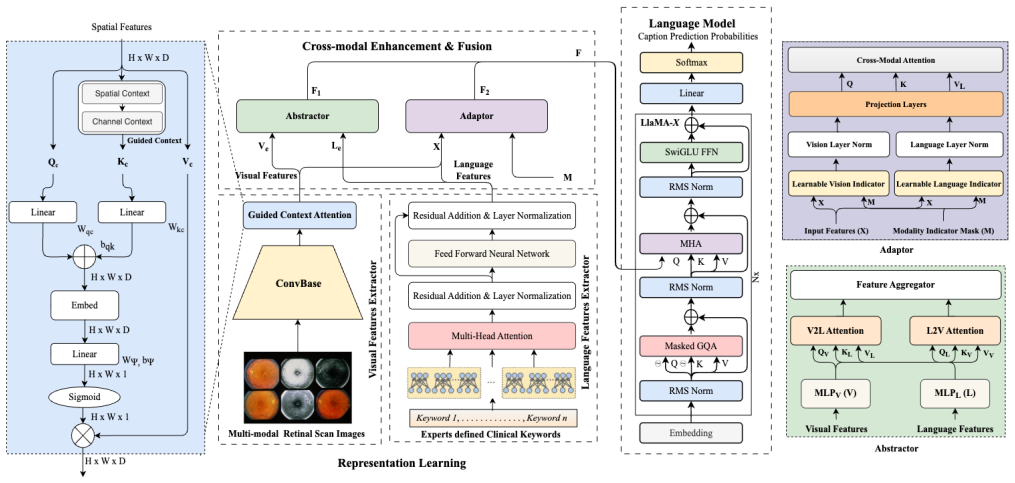
DREAM employs a unique two-stage fusion mechanism that intelligently integrates visual data with clinical keywords curated by ophthalmologists. First, the Abstractor module maps image and keyword features into a shared space, enhancing visual data with pathology-relevant insights. Next, the Adaptor performs adaptive multi-modal fusion, dynamically weighting the importance of each modality using learnable parameters to create a unified representation. To ensure the model's outputs are semantically grounded in clinical reality, a Contrastive Alignment module aligns these fused representations with ground-truth medical reports during training.
What carries the argument
The two-stage fusion with adaptive multi-modal weighting in the Adaptor module, which learns to balance retinal image features against ophthalmologist keywords before contrastive alignment.
If this is right
- The model achieves a new state-of-the-art BLEU-4 score of 0.241 on the DeepEyeNet benchmark for retinal report generation.
- The same architecture shows strong generalization when evaluated on the ROCO dataset.
- Dynamic weighting of modalities reduces the tendency of vision-language models to overfit when medical training data is limited.
- Contrastive alignment during training produces reports that stay semantically consistent with ground-truth clinical descriptions.
Where Pith is reading between the lines
- The method could be tested on other image-report pairs such as chest X-rays if equivalent expert keywords are supplied.
- Removing the need for manual keywords at test time would require a separate keyword-prediction head trained jointly with the fusion stages.
- If the adaptive weights prove stable across hospitals, the framework might support deployment in settings with varying imaging equipment.
Load-bearing premise
That ophthalmologist-curated keywords remain available at inference time and that the adaptive weighting combined with contrastive alignment will reliably avoid overfitting on scarce data without adding new biases.
What would settle it
Running the trained model on the DeepEyeNet test set after removing all ophthalmologist keywords at inference time and observing whether BLEU-4 falls below the reported 0.241 or matches prior non-fusion baselines.
Figures

read the original abstract
Automating medical reports for retinal images requires a sophisticated blend of visual pattern recognition and deep clinical knowledge. Current Large Vision-Language Models (LVLMs) often struggle in specialized medical fields where data is scarce, leading to models that overfit and miss subtle but critical pathologies. To address this, we introduce DREAM (Dynamic Retinal Enhancement with Adaptive Multi-modal Fusion), a novel framework for high-fidelity medical report generation that excels even with limited data. DREAM employs a unique two-stage fusion mechanism that intelligently integrates visual data with clinical keywords curated by ophthalmologists. First, the Abstractor module maps image and keyword features into a shared space, enhancing visual data with pathology-relevant insights. Next, the Adaptor performs adaptive multi-modal fusion, dynamically weighting the importance of each modality using learnable parameters to create a unified representation. To ensure the model's outputs are semantically grounded in clinical reality, a Contrastive Alignment module aligns these fused representations with ground-truth medical reports during training. By combining medical expertise with an efficient fusion strategy, DREAM sets a new state-of-the-art on the DeepEyeNet benchmark, achieving a BLEU-4 score of 0.241, and further demonstrates strong generalization to the ROCO dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DREAM, a two-stage multi-modal framework for retinal image report generation. An Abstractor maps image features and ophthalmologist-curated keywords into a shared space; an Adaptor performs dynamic fusion via learnable modality weights; and a Contrastive Alignment module grounds the fused representation to ground-truth reports. The central claim is that this yields SOTA performance on DeepEyeNet (BLEU-4 = 0.241) while generalizing to ROCO, even under limited data.
Significance. If the performance claims can be substantiated with proper controls, the work would offer a concrete mechanism for injecting expert-curated knowledge into vision-language models for medical report generation, addressing data scarcity in specialized domains such as ophthalmology.
major comments (2)
- [Abstract] Abstract: The reported BLEU-4 score of 0.241 and the generalization claim are presented without any baseline comparisons, ablation results on the keyword stream, statistical tests, or error analysis. This absence prevents evaluation of whether the adaptive fusion contributes beyond the privileged keyword input.
- [Abstract] Abstract (Adaptor and Abstractor descriptions): The SOTA claim relies on ophthalmologist-curated keywords being available at inference time, yet no ablation is described that removes or replaces the keyword stream, tests a vision-only variant, or evaluates performance when keywords are absent. The learnable parameters in the Adaptor are trained on the same data used for reporting results, with no independent verification of robustness.
minor comments (1)
- [Abstract] The description of the Contrastive Alignment objective would benefit from an explicit equation or loss formulation to clarify how it interacts with the adaptive weighting.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which have helped us identify areas for improvement in the manuscript. Below, we provide point-by-point responses to the major comments.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported BLEU-4 score of 0.241 and the generalization claim are presented without any baseline comparisons, ablation results on the keyword stream, statistical tests, or error analysis. This absence prevents evaluation of whether the adaptive fusion contributes beyond the privileged keyword input.
Authors: The abstract, due to its brevity, does not detail the experimental comparisons. We will revise the abstract to incorporate mentions of baseline comparisons, ablation results on the keyword stream, and statistical tests to better contextualize the BLEU-4 score and generalization claim. We will also add an error analysis to the manuscript. revision: yes
-
Referee: [Abstract] Abstract (Adaptor and Abstractor descriptions): The SOTA claim relies on ophthalmologist-curated keywords being available at inference time, yet no ablation is described that removes or replaces the keyword stream, tests a vision-only variant, or evaluates performance when keywords are absent. The learnable parameters in the Adaptor are trained on the same data used for reporting results, with no independent verification of robustness.
Authors: We acknowledge that the current manuscript does not include ablations removing the keyword stream or testing a vision-only variant. The framework is designed for scenarios where expert-curated keywords are available at inference, as is common in clinical practice for precision. However, to strengthen the evaluation, we will add the requested ablations in the revised version, including performance when keywords are absent. For the Adaptor parameters, they are trained on the training data with results on test sets; we will provide additional verification of robustness through cross-validation details and sensitivity analysis. revision: yes
Circularity Check
No significant circularity in DREAM's empirical framework
full rationale
The paper describes a standard supervised ML architecture (Abstractor for shared-space mapping of images and ophthalmologist-curated keywords, Adaptor for learnable-parameter adaptive fusion, and Contrastive Alignment trained against ground-truth reports) and reports its BLEU-4 performance after training on the DeepEyeNet benchmark. This is the conventional procedure for claiming benchmark results and does not reduce any claimed derivation or prediction to its inputs by construction. No mathematical first-principles chain, self-definitional equations, or load-bearing self-citations appear; the keyword modality is an explicit architectural input rather than a hidden tautology. The result is self-contained against the external benchmark.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable modality weights in Adaptor
axioms (1)
- domain assumption Clinical keywords selected by ophthalmologists accurately capture pathology-relevant information for any given retinal image.
Reference graph
Works this paper leans on
-
[1]
DeepOpht: medical report generation for retinal images via deep models and visual explanation
Jia-Hong Huang et al. “DeepOpht: medical report generation for retinal images via deep models and visual explanation”. In:Proceedings of the IEEE/CVF winter conference on applications of computer vision. 2021, pp. 2442–2452
work page 2021
-
[2]
VisualGPT: Data-efficient adaptation of pretrained language models for image caption- ing
Jun Chen et al. “VisualGPT: Data-efficient adaptation of pretrained language models for image caption- ing”. In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022, pp. 18030–18040
work page 2022
-
[3]
LlaV A-Med: Training a large language-and-vision assistant for biomedicine in one day
Chunyuan Li et al. “LlaV A-Med: Training a large language-and-vision assistant for biomedicine in one day”. In:Advances in Neural Information Processing Systems36 (2024)
work page 2024
-
[4]
Expert-defined Keywords Im- prove Interpretability of Retinal Image Captioning
Ting-Wei Wu et al. “Expert-defined Keywords Im- prove Interpretability of Retinal Image Captioning”. In:Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2023, pp. 1859– 1868
work page 2023
-
[5]
mPLUG-Owl2: Revolutionizing multi-modal large language model with modality col- laboration
Qinghao Ye et al. “mPLUG-Owl2: Revolutionizing multi-modal large language model with modality col- laboration”. In:Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition. 2024, pp. 13040–13051
work page 2024
-
[6]
Visiongpt: Vision-language understand- ing agent using generalized multimodal framework,
Chris Kelly et al. “VisionGPT: Vision-language under- standing agent using generalized multimodal frame- work”. In:arXiv preprint arXiv:2403.09027(2024)
-
[7]
Show and tell: A neural image caption generator
Oriol Vinyals et al. “Show and tell: A neural image caption generator”. In:Proceedings of the IEEE con- ference on computer vision and pattern recognition. 2015, pp. 3156–3164
work page 2015
-
[8]
Show, attend and tell: Neural image caption generation with visual attention
Kelvin Xu et al. “Show, attend and tell: Neural image caption generation with visual attention”. In:Interna- tional conference on machine learning. PMLR. 2015, pp. 2048–2057
work page 2015
-
[9]
Deep context-encoding net- work for retinal image captioning
Jia-Hong Huang et al. “Deep context-encoding net- work for retinal image captioning”. In:2021 IEEE International Conference on Image Processing (ICIP). IEEE. 2021, pp. 3762–3766
work page 2021
-
[10]
Non-local attention improves description generation for retinal images
Jia-Hong Huang et al. “Non-local attention improves description generation for retinal images”. In:Pro- ceedings of the IEEE/CVF winter conference on ap- plications of computer vision. 2022, pp. 1606–1615
work page 2022
-
[11]
Gated contextual transformer network for multi- modal retinal image clinical description generation
Nagur Shareef Shaik and Teja Krishna Cherukuri. “Gated contextual transformer network for multi- modal retinal image clinical description generation”. In:Image and Vision Computing(2024), p. 104946
work page 2024
-
[12]
Nagur Shareef Shaik, Teja Krishna Cherukuri, and Dong Hye Ye. “M3T: Multi-Modal Medical Trans- former to Bridge Clinical Context with Visual Insights for Retinal Image Medical Description Generation”. In:Proceedings of the IEEE International Confer- ence on Image Processing (ICIP). arXiv preprint arXiv:2406.13129. Abu Dhabi, United Arab Emirates: IEEE, 2024
-
[13]
Teja Krishna Cherukuri et al. “GCS-M3VLT: Guided Context Self-Attention based Multi-modal Medical Vision Language Transformer for Retinal Image Cap- tioning”. In:2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE. 2025, pp. 1–5
work page 2025
-
[14]
Ashish Vaswani et al. “Attention is all you need”. In: Advances in neural information processing systems30 (2017)
work page 2017
-
[15]
Learning transferable visual mod- els from natural language supervision
Alec Radford et al. “Learning transferable visual mod- els from natural language supervision”. In:Interna- tional conference on machine learning. PmLR. 2021, pp. 8748–8763
work page 2021
-
[16]
EfficientNetV2: Smaller models and faster training
Mingxing Tan and Quoc Le. “EfficientNetV2: Smaller models and faster training”. In:International confer- ence on machine learning. PMLR. 2021, pp. 10096– 10106
work page 2021
-
[17]
Guided Context Gating: Learning to Leverage Salient Lesions in Retinal Fundus Images
Teja Krishna Cherukuri, Nagur Shareef Shaik, and Dong Hye Ye. “Guided Context Gating: Learning to Leverage Salient Lesions in Retinal Fundus Images”. In:Proceedings of the IEEE International Confer- ence on Image Processing (ICIP). arXiv preprint arXiv:2406.13126. Abu Dhabi, United Arab Emirates: IEEE, 2024
-
[18]
Gaussian Error Linear Units (GELUs)
Dan Hendrycks and Kevin Gimpel. “Gaussian Er- ror Linear Units (GELUS)”. In:arXiv preprint arXiv:1606.08415(2016)
work page Pith review arXiv 2016
-
[19]
LLaMA: Open and efficient foundation language models
Hugo Touvron et al. “LLaMA: Open and efficient foundation language models”. In: (2023)
work page 2023
-
[20]
Language Models are Few-Shot Learners
Tom B Brown. “Language models are few-shot learn- ers”. In:arXiv preprint arXiv:2005.14165(2020)
work page internal anchor Pith review arXiv 2005
-
[21]
Contextualized keyword representations for multi- modal retinal image captioning
Jia-Hong Huang, Ting-Wei Wu, and Marcel Worring. “Contextualized keyword representations for multi- modal retinal image captioning”. In:Proceedings of the 2021 International Conference on Multimedia Re- trieval. 2021, pp. 645–652
work page 2021
-
[22]
Rocov2: Radiology objects in context version 2, an updated multimodal image dataset
Johannes R ¨uckert et al. “Rocov2: Radiology objects in context version 2, an updated multimodal image dataset”. In:Scientific Data11.1 (2024), p. 688
work page 2024
-
[23]
BERTScore: Evaluating Text Generation with BERT
Tianyi Zhang* et al. “BERTScore: Evaluating Text Generation with BERT”. In:International Conference on Learning Representations. 2020
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.