Recognition: unknown
Clover: A Neural-Symbolic Agentic Harness with Stochastic Tree-of-Thoughts for Verified RTL Repair
Pith reviewed 2026-05-10 06:05 UTC · model grok-4.3
The pith
Clover orchestrates RTL repair as structured search using stochastic tree-of-thoughts and dynamic agent dispatch for verified fixes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Clover is a neural-symbolic agentic harness that frames RTL program repair as a structured search over possible code manipulations. Tasks are dynamically assigned to LLM agents or symbolic solvers, while stochastic tree-of-thoughts maintains the primary agent's working context as an explicit search tree to balance exploration and exploitation. An RTL-specific toolbox supplies the agents with direct access to the simulation and verification environment, enabling the system to reach and confirm correct repairs.
What carries the argument
stochastic tree-of-thoughts, a test-time scaling method that represents the agent's context as a search tree to balance exploration and exploitation while avoiding context corruption during repair.
If this is right
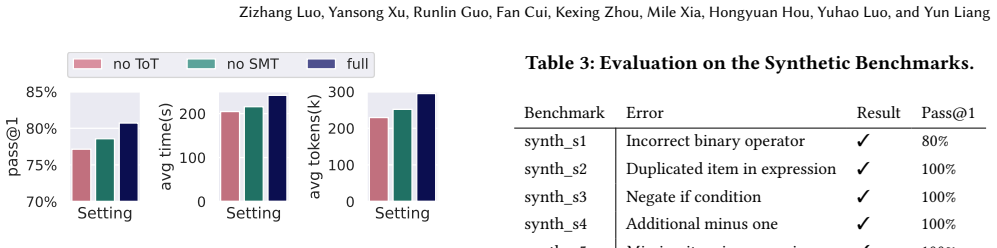
- Bug coverage on standard RTL-repair benchmarks rises by 94 percent over traditional template-based methods and by 63 percent over LLM-only baselines.
- An average pass@1 rate of 87.5 percent indicates that the generated repairs are reliable enough for direct use in automated verification flows.
- Dynamic dispatching between neural and symbolic components allows the system to handle diverse repair operations without a single fixed strategy.
- Completion of repairs inside a fixed time budget shows the approach can fit inside existing hardware design schedules.
Where Pith is reading between the lines
- The same search-tree discipline could be applied to other long-context agent tasks such as software debugging or formal verification script writing.
- Adding more domain-specific symbolic back-ends might further raise the fraction of bugs that receive fully automatic, machine-checked fixes.
- The explicit tree representation of context offers a concrete way to audit and replay repair decisions, which could help meet documentation requirements in safety-critical hardware projects.
Load-bearing premise
That routing tasks to specialized agents or solvers through a stochastic tree-of-thoughts structure will reliably prevent context corruption and produce verified repairs on long RTL modules and waveforms without heavy manual tuning.
What would settle it
A controlled run on a set of long RTL designs containing known bugs in which Clover fails to return passing, verified fixes for a substantial fraction of cases within the stated time limit due to context loss or incorrect dispatch decisions.
Figures




read the original abstract
RTL program repair remains a critical bottleneck in hardware design and verification. Traditional automatic program repair (APR) methods rely on predefined templates and synthesis, limiting their bug coverage. Large language models (LLMs) and coding agents based on them offer flexibility but suffer from randomness and context corruption when handling long RTL code and waveforms. We present Clover, a neural-symbolic agentic harness that orchestrates RTL repair as a structured search over code manipulations to explore a validated solution for the bug. Recognizing that different repair operations favor distinct strategies, Clover dynamically dispatches tasks to specialized LLM agents or symbolic solvers. At its core, Clover introduces stochastic tree-of-thoughts, a test-time scaling mechanism that manages the main agent's context as a search tree, balancing exploration and exploitation for reliable outcomes. An RTL-specific toolbox further empowers agents to interact with the debugging environment. Evaluated on the RTL-repair benchmark, Clover fixes 96.8% of bugs within a fixed time limit, covering 94% and 63% more bugs than both pure traditional and LLM-based baselines, respectively, while achieving an average pass@1 rate of 87.5%, demonstrating high reliability and effectiveness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Clover, a neural-symbolic agentic harness for verified RTL repair. It orchestrates repair as structured search via stochastic tree-of-thoughts (managing context as a search tree with exploration/exploitation balance), dynamically dispatches tasks to specialized LLM agents or symbolic solvers, and provides an RTL-specific toolbox for environment interaction. On the RTL-repair benchmark, it reports fixing 96.8% of bugs within a fixed time limit (94% and 63% more than pure traditional and LLM-based baselines) with 87.5% average pass@1.
Significance. If the empirical results hold under rigorous evaluation, the work advances automated hardware verification by combining neural flexibility with symbolic verification to mitigate context corruption in long RTL code and waveforms. The stochastic tree-of-thoughts mechanism is a coherent test-time scaling contribution for agentic systems, and the dynamic dispatch plus toolbox design addresses a practical pain point in RTL debugging.
major comments (1)
- [§5] §5 (Experimental Evaluation): The section reports concrete benchmark numbers (96.8% fix rate, 87.5% pass@1, relative improvements) but provides insufficient detail on experimental setup, including exact baseline implementations, LLM model versions and prompting, time-limit enforcement, statistical significance tests, and potential confounds such as benchmark subset selection or manual tuning. This is load-bearing for the central performance claim.
minor comments (2)
- [Abstract] The abstract and §3 refer to 'the RTL-repair benchmark' without a citation or brief characterization of its size, bug types, or waveform requirements; adding this would improve accessibility.
- [§4.1] Figure 2 (architecture diagram) and the description of stochastic tree-of-thoughts in §4.1 would benefit from an explicit pseudocode listing of the search procedure to clarify branching, pruning, and verification steps.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and positive assessment of the work's significance. We agree that greater experimental detail is required to substantiate the central claims and will revise §5 accordingly.
read point-by-point responses
-
Referee: [§5] §5 (Experimental Evaluation): The section reports concrete benchmark numbers (96.8% fix rate, 87.5% pass@1, relative improvements) but provides insufficient detail on experimental setup, including exact baseline implementations, LLM model versions and prompting, time-limit enforcement, statistical significance tests, and potential confounds such as benchmark subset selection or manual tuning. This is load-bearing for the central performance claim.
Authors: We acknowledge that the current description of the experimental setup in §5 is insufficient for full reproducibility and rigorous evaluation. In the revised manuscript we will expand this section with: (i) exact LLM versions, API parameters, and temperature settings; (ii) complete prompt templates and agent role instructions; (iii) precise re-implementations of all baselines, including any adaptations made to traditional APR tools and prior LLM agents; (iv) uniform time-limit enforcement protocol (wall-clock seconds, hardware platform, and early-termination rules); (v) statistical significance tests (McNemar’s test on paired fix rates and bootstrap confidence intervals on pass@1); and (vi) explicit discussion of benchmark subset selection, any manual tuning performed, and steps taken to mitigate confounds. These additions will be presented in a dedicated “Experimental Setup” subsection with tables for clarity. The reported performance numbers themselves remain unchanged. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an empirical system (Clover) for RTL repair using stochastic tree-of-thoughts, dynamic agent dispatch, and an RTL toolbox, with results reported as success rates on an external benchmark (96.8% bugs fixed, 87.5% pass@1). No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear in the abstract or described content. The architecture is presented as a design to address context corruption rather than a derivation that reduces to its own inputs by construction. This is a standard empirical engineering paper with no detectable circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
d.].Icarus Verilog
[n. d.].Icarus Verilog. https://steveicarus.github.io/iverilog/
-
[2]
https://www.veripool.org/verilator
2025.Verilator. https://www.veripool.org/verilator
2025
-
[3]
https://yosyshq.net/yosys/
2025.Yosys Open Synthesis Suite. https://yosyshq.net/yosys/
2025
-
[4]
Baleegh Ahmad, Shailja Thakur, Benjamin Tan, Ramesh Karri, and Hammond Pearce. 2024. On Hardware Security Bug Code Fixes by Prompting Large Language Models.IEEE Transactions on Information Forensics and Security19 (2024), 4043–4057. doi:10.1109/TIFS.2024. 3374558
-
[5]
Hammad Ahmad, Yu Huang, and Westley Weimer. 2022. CirFix: auto- matically repairing defects in hardware design code. InProceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems. ACM, Lausanne Switzerland, 990–1003. doi:10.1145/3503222.3507763
-
[6]
Fan Cui, Chenyang Yin, Kexing Zhou, Youwei Xiao, and the oth- ers. 2024. OriGen: Enhancing RTL Code Generation with Code-to- Code Augmentation and Self-Reflection. InProceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design, ICCAD 2024, Newark Liberty International Airport Marriott, NJ, USA, October 27-31, 2024, Jinjun Xiong and R...
2024
-
[7]
2025.Investigating Automatic Bug Repair Using Large Language Models for Digital Hardware Design
Abdelrahman Elnaggar. 2025.Investigating Automatic Bug Repair Using Large Language Models for Digital Hardware Design. Ph. D. Dissertation. University of Calgary
2025
-
[8]
Zhiyu Fan, Xiang Gao, Martin Mirchev, Abhik Roychoudhury, and Shin Hwei Tan. 2023. Automated Repair of Programs from Large Language Models. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). 1469–1481. doi:10.1109/ICSE48619.2023. 00128
- [9]
-
[10]
hudson trading. [n. d.].slang-server. https://hudson-trading.github. io/slang-server/
-
[11]
Kevin Laeufer, Brandon Fajardo, Abhik Ahuja, Vighnesh Iyer, Borivoje Nikolić, and Koushik Sen. 2024. RTL-Repair: Fast Symbolic Repair of Hardware Design Code. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3. ACM, La Jolla CA USA, 867–881. doi:10. 1145/3620666.3651346
-
[12]
Dacheng Li, Shiyi Cao, Chengkun Cao, Xiuyu Li, Shangyin Tan, Kurt Keutzer, Jiarong Xing, Joseph E. Gonzalez, and Ion Stoica. 2025. S*: Test Time Scaling for Code Generation. arXiv:2502.14382 (2025). doi:10. 48550/arXiv.2502.14382
-
[13]
Qingwen Lin, Boyan Xu, Guimin Hu, Zijian Li, Zhifeng Hao, Keli Zhang, and Ruichu Cai. 2025. CMCTS: A Constrained Monte Carlo Tree Search Framework for Mathematical Reasoning in Large Lan- guage Model. arXiv:2502.11169 (2025). doi:10.48550/arXiv.2502.11169
-
[14]
2026.Harness engineering: leveraging Codex in an agent-first world
Ryan Lopopolo. 2026.Harness engineering: leveraging Codex in an agent-first world. https://openai.com/index/harness-engineering/
2026
-
[15]
Lingrui Mei, Jiayu Yao, Yuyao Ge, Yiwei Wang, Baolong Bi, Yujun Cai, Jiazhi Liu, Mingyu Li, Zhong-Zhi Li, Duzhen Zhang, Chenlin Zhou, Jiayi Mao, Tianze Xia, Jiafeng Guo, and Shenghua Liu. 2025. A Survey of Context Engineering for Large Language Models. arXiv:2507.13334 (2025). doi:10.48550/arXiv.2507.13334
work page internal anchor Pith review doi:10.48550/arxiv.2507.13334 2025
-
[16]
Khushboo Qayyum, Muhammad Hassan, Sallar Ahmadi-Pour, Chan- dan Kumar Jha, and Rolf Drechsler. 2024. From Bugs to Fixes: HDL Bug Identification and Patching using LLMs and RAG. In2024 IEEE LLM Aided Design Workshop (LAD). 1–5. doi:10.1109/LAD62341.2024. 10691874 9 Zizhang Luo, Yansong Xu, Runlin Guo, Fan Cui, Kexing Zhou, Mile Xia, Hongyuan Hou, Yuhao Luo...
-
[17]
Yun-Da Tsai, Mingjie Liu, and Haoxing Ren. 2024. RTLFixer: Au- tomatically Fixing RTL Syntax Errors with Large Language Models. doi:10.48550/arXiv.2311.16543
-
[18]
Shobha Vasudevan, Wenjie Joe Jiang, David Bieber, Rishabh Singh, C Richard Ho, Charles Sutton, et al. 2021. Learning semantic represen- tations to verify hardware designs.Advances in Neural Information Processing Systems34 (2021), 23491–23504
2021
-
[19]
Shobha Vasudevan, David Sheridan, Sanjay Patel, David Tcheng, Bill Tuohy, and Daniel Johnson. 2010. GoldMine: Automatic assertion gen- eration using data mining and static analysis. In2010 Design, Automa- tion & Test in Europe Conference & Exhibition (DATE 2010). 626–629. doi:10.1109/DATE.2010.5457129
-
[20]
2018.Intel Could Make Billions Off of Meltdown & Spectre
Jayce Wagner. 2018.Intel Could Make Billions Off of Meltdown & Spectre. https://www.digitaltrends.com/computing/intel-could-make- billions-offmeltdown-spectre/3
2018
-
[21]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sha- ran Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self- Consistency Improves Chain of Thought Reasoning in Language Mod- els. arXiv:2203.11171 (2023). doi:10.48550/arXiv.2203.11171
-
[22]
Jiang Wu, Zhuo Zhang, Deheng Yang, Xiankai Meng, Jiayu He, Xi- aoguang Mao, and Yan Lei. 2022. Fault Localization for Hardware Design Code with Time-Aware Program Spectrum. In2022 IEEE 40th International Conference on Computer Design (ICCD). 537–544. doi:10.1109/ICCD56317.2022.00085
-
[23]
Chunqiu Steven Xia, Yuxiang Wei, and Lingming Zhang. 2023. Au- tomated Program Repair in the Era of Large Pre-trained Language Models. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). 1482–1494. doi:10.1109/ICSE48619.2023.00129
-
[24]
Ke Xu, Jialin Sun, Yuchen Hu, Xinwei Fang, Weiwei Shan, Xi Wang, and Zhe Jiang. 2024. MEIC: Re-thinking RTL Debug Automation using LLMs. InProceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design. ACM. doi:10.1145/3676536.3676801
-
[25]
Deheng Yang, Jiayu He, Xiaoguang Mao, Tun Li, Yan Lei, Xin Yi, and Jiang Wu. 2024. Strider: Signal Value Transition-Guided Defect Repair for HDL Programming Assignments.IEEE Transactions on Computer- Aided Design of Integrated Circuits and Systems43, 5 (2024), 1594–1607. doi:10.1109/TCAD.2023.3341750
-
[27]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. InAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curran Associates, Inc., 11809–11822
2023
-
[28]
Xufeng Yao, Haoyang Li, Tsz Ho Chan, Wenyi Xiao, Mingxuan Yuan, Yu Huang, Lei Chen, and Bei Yu. 2024. HDLdebugger: Streamlining HDL debugging with Large Language Models. doi:10.48550/arXiv. 2403.11671
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[29]
Keyi Zhang, Zain Asgar, and Mark Horowitz. 2022. Bringing source- level debugging frameworks to hardware generators. InDAC ’22: 59th ACM/IEEE Design Automation Conference, San Francisco, California, USA, July 10 - 14, 2022, Rob Oshana (Ed.). ACM, 1171–1176. doi:10. 1145/3489517.3530603
-
[30]
Qiyuan Zhang, Fuyuan Lyu, Zexu Sun, Lei Wang, Weixu Zhang, Wenyue Hua, Haolun Wu, Zhihan Guo, Yufei Wang, Niklas Muen- nighoff, Irwin King, Xue Liu, and Chen Ma. 2025. A Survey on Test- Time Scaling in Large Language Models: What, How, Where, and How Well? arXiv:2503.24235 (2025). doi:10.48550/arXiv.2503.24235 10
work page internal anchor Pith review doi:10.48550/arxiv.2503.24235 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.