Recognition: unknown
MESA: A Training-Free Multi-Exemplar Deep Framework for Restoring Ancient Inscription Textures
Pith reviewed 2026-05-10 06:17 UTC · model grok-4.3
The pith
MESA restores damaged ancient inscription images by guiding synthesis with textures from multiple well-preserved exemplars without training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MESA encodes VGG19 convolutional features as Gram matrices to capture exemplar texture, style, and stroke structure. For each neural network layer, it selects the exemplar minimizing Mean-Squared Displacement to the damaged input. Layer-wise contribution weights come from Optical Character Recognition-estimated character widths in the exemplar set to bias filters toward scales matching letter geometry. A training mask preserves intact regions so synthesis is restricted to damaged areas.
What carries the argument
MESA framework using Gram matrices of VGG19 features for multi-exemplar texture capture, with mean-squared displacement selection and OCR-derived weights for layer contributions.
Load-bearing premise
Suitable well-preserved exemplars with matching letterforms and material are available and the mean-squared displacement selection plus OCR widths will pick the right ones.
What would settle it
A controlled test on inscriptions with known original intact versions after applying artificial damage, verifying if MESA reconstructs the correct textures and letter shapes.
Figures




















read the original abstract
Ancient inscriptions frequently suffer missing or corrupted regions from fragmentation, erosion, or other damage, hindering reading, and analysis. We review prior image restoration methods and their applicability to inscription image recovery, then introduce MESA (Multi-Exemplar, Style-Aware) -an image-level restoration method that uses well-preserved exemplar inscriptions (from the same epigraphic monument, material, or similar letterforms) to guide reconstruction of damaged text. MESA encodes VGG19 convolutional features as Gram matrices to capture exemplar texture, style, and stroke structure; for each neural network layer it selects the exemplar minimizing Mean-Squared Displacement (MSD) to the damaged input. Layer-wise contribution weights are derived from Optical Character Recognition-estimated character widths in the exemplar set to bias filters toward scales matching letter geometry, and a training mask preserves intact regions so synthesis is restricted to damaged areas. We also summarize prior network architectures and exemplar and single-image synthesis, inpainting, and Generative Adversarial Network (GAN) approaches, highlighting limitations that MESA addresses. Comparative experiments demonstrate the advantages of MESA. Finally, we provide a practical roadmap for choosing restoration strategies given available exemplars and metadata.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MESA, a training-free image-level restoration framework for damaged ancient inscriptions. It encodes VGG19 features as Gram matrices from multiple well-preserved exemplars (same monument, material, or letterforms), selects per-layer the exemplar minimizing Mean-Squared Displacement (MSD) to the damaged input, derives layer weights from OCR-estimated character widths to bias toward matching scales, and applies an intact-region mask to restrict synthesis to damaged areas. The work reviews prior inpainting, style transfer, and GAN methods, claims comparative experiments show advantages, and provides a roadmap for choosing strategies based on available exemplars.
Significance. If the central claims hold, MESA offers a practical, training-free alternative to data-hungry methods for epigraphic restoration when suitable exemplars exist, leveraging standard components (VGG19, Gram matrices, OCR) in a style-aware pipeline. The parameter-free exemplar selection and mask-based preservation are notable strengths for reproducibility. However, significance is limited by the absence of quantitative metrics or dataset details in the provided text, and the approach's reliability depends on unproven robustness of MSD selection under damage.
major comments (2)
- [Method (exemplar selection and MSD computation)] The exemplar selection step (described in the method overview) relies on per-layer MSD minimization between Gram matrices (or features) of the damaged input and each exemplar. Because MSD is evaluated on the full damaged image, erosion, fragmentation, and artifacts can distort local activations and global statistics; no analysis shows that the argmin still recovers the underlying letterform style rather than an exemplar matching the damage pattern. The downstream OCR-derived weights and intact mask operate after selection and cannot correct an upstream mismatch. This is load-bearing for the claim that MESA reliably guides reconstruction.
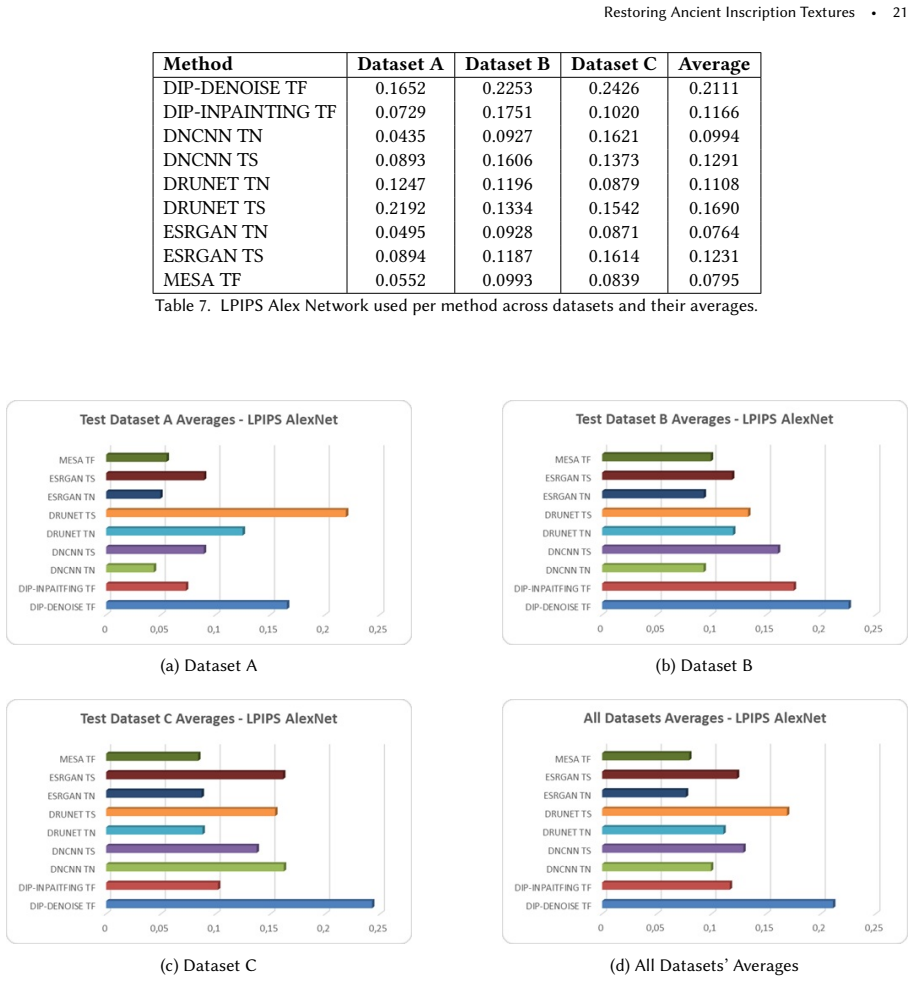
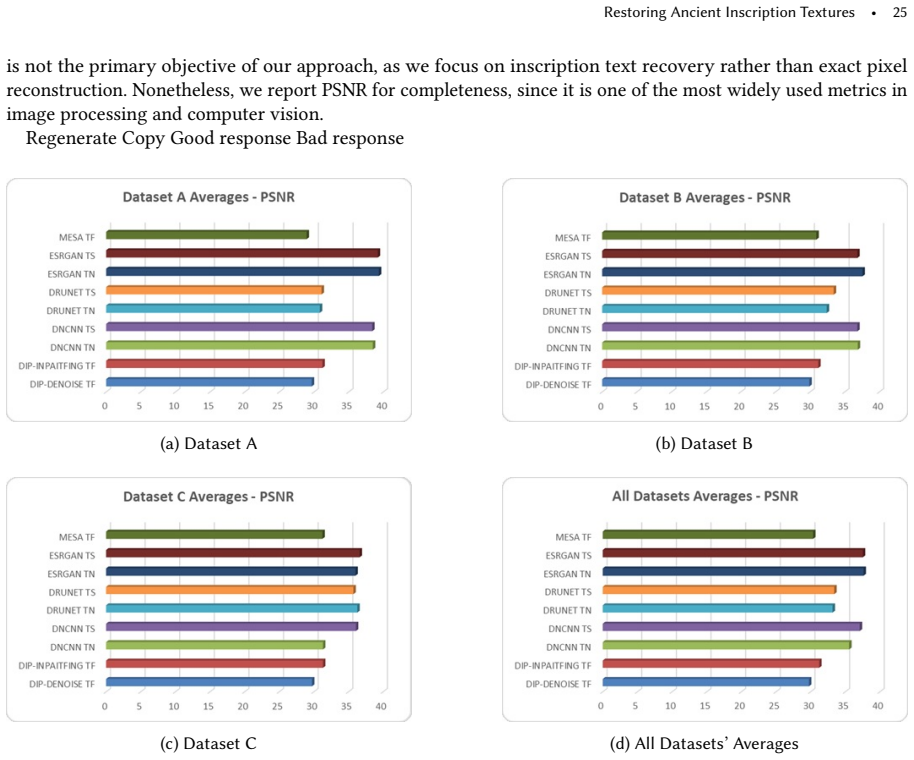
- [Abstract and Experimental section] The abstract and conclusion state that 'comparative experiments demonstrate the advantages of MESA,' yet no quantitative results, error metrics (e.g., PSNR, SSIM, perceptual scores), dataset sizes, baseline details, or ablation tables are referenced. Without these, the performance claims cannot be verified and the cross-method superiority remains unsupported.
minor comments (2)
- [Method notation] Clarify the precise definition and computation of 'Mean-Squared Displacement' (MSD) when applied to Gram matrices or VGG features, as this term is non-standard in style-transfer literature (typically MSE or Frobenius distance is used).
- [Abstract] The abstract would be strengthened by including at least one key quantitative result or metric to support the 'demonstrate advantages' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the presentation and support for our claims.
read point-by-point responses
-
Referee: [Method (exemplar selection and MSD computation)] The exemplar selection step (described in the method overview) relies on per-layer MSD minimization between Gram matrices (or features) of the damaged input and each exemplar. Because MSD is evaluated on the full damaged image, erosion, fragmentation, and artifacts can distort local activations and global statistics; no analysis shows that the argmin still recovers the underlying letterform style rather than an exemplar matching the damage pattern. The downstream OCR-derived weights and intact mask operate after selection and cannot correct an upstream mismatch. This is load-bearing for the claim that MESA reliably guides reconstruction.
Authors: We acknowledge the concern that MSD computed over the full image could potentially be influenced by damage patterns rather than underlying style. Gram matrices from VGG19 layers are intended to capture global second-order statistics of texture and stroke structure, which are less sensitive to localized erosion or fragmentation than raw features. Nevertheless, the manuscript does not include explicit robustness analysis of the selection step. In the revised version we will add a new subsection with controlled experiments: we will apply synthetic damage masks of varying severity to intact exemplars, re-run the per-layer MSD selection, and demonstrate that the chosen exemplar consistently matches the original letterform style (verified via visual inspection and OCR consistency) rather than the damage configuration. This analysis will directly address the load-bearing nature of the selection mechanism. revision: yes
-
Referee: [Abstract and Experimental section] The abstract and conclusion state that 'comparative experiments demonstrate the advantages of MESA,' yet no quantitative results, error metrics (e.g., PSNR, SSIM, perceptual scores), dataset sizes, baseline details, or ablation tables are referenced. Without these, the performance claims cannot be verified and the cross-method superiority remains unsupported.
Authors: We agree that the current experimental section relies on qualitative visual comparisons and does not report numerical metrics, dataset statistics, or ablations, which limits verifiability of the superiority claims. The manuscript presents side-by-side results against representative inpainting and style-transfer baselines, but these are not quantified. In the revision we will expand the experimental section to include: (1) a clear description of the evaluation dataset (number of images, sources, and damage characteristics), (2) quantitative metrics (PSNR, SSIM, and a perceptual metric such as LPIPS) computed against ground-truth intact regions where available, (3) details of the baseline implementations, and (4) ablation tables isolating the contributions of per-layer MSD selection, OCR-derived weights, and the intact-region mask. These additions will be placed before the conclusion and will directly support the statements in the abstract. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents MESA as a pipeline that encodes VGG19 features into Gram matrices, selects exemplars via MSD minimization per layer, derives layer weights from OCR-estimated character widths, and applies an intact-region mask for synthesis. These steps operate on external inputs (damaged image, exemplar set, pre-trained VGG19, OCR) without any equation or selection rule that reduces the restored output to a fitted parameter, self-defined quantity, or self-citation chain. No load-bearing premise collapses to prior author work by construction, and the method remains self-contained against the listed external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption VGG19 convolutional features encoded as Gram matrices capture texture, style, and stroke structure relevant to inscription restoration
- domain assumption OCR-estimated character widths in the exemplar set provide reliable layer-wise contribution weights that match letter geometry
Reference graph
Works this paper leans on
-
[1]
Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dandelion Mané, Rajat Monga, Sherry Moore, Derek Murra...
2015
-
[2]
Yannis Assael, Thea Sommerschield, Alison Cooley, Brendan Shillingford, John Pavlopoulos, Priyanka Suresh, Bailey Herms, Justin Grayston, Benjamin Maynard, Nicholas Dietrich, Robbe Wulgaert, Jonathan Prag, Alex Mullen, and Shakir Mohamed. 2025. Contextual- izing ancient texts with generative neural networks.Nature(07 2025), 1–7. doi:10.1038/s41586-025-09292-5
-
[3]
Yannis Assael, Thea Sommerschield, and J. Prag. 2019. Restoring ancient text using deep learning: a case study on Greek epigraphy. In Conference on Empirical Methods in Natural Language Processing. https://api.semanticscholar.org/CorpusID:202781916
2019
-
[4]
Yannis Assael, Thea Sommerschield, and Jonathan Prag. 2019. Restoring ancient text using deep learning: a case study on Greek epigraphy. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Kentaro Inui, Jing Jiang, Vincent Ng, and...
-
[5]
Yannis Assael*, Thea Sommerschield*, Brendan Shillingford, Mahyar Bordbar, John Pavlopoulos, Marita Chatzipanagiotou, Ion Androut- sopoulos, Jonathan Prag, and Nando de Freitas. 2022. Restoring and attributing ancient texts using deep neural networks.Nature(2022). doi:10.1038/s41586-022-04448-z
-
[6]
Tai-Yin Chiu. 2019. Understanding Generalized Whitening and Coloring Transform for Universal Style Transfer. In2019 IEEE/CVF International Conference on Computer Vision (ICCV). 4451–4459. doi:10.1109/ICCV.2019.00455
-
[7]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, et al. 2024. The LLaMA 3 Herd of Models. arXiv:2407.21783 [cs.AI] doi:10.48550/ arXiv.2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Leon A. Gatys, Alexander S. Ecker, and Matthias Bethge. 2016. Image Style Transfer Using Convolutional Neural Networks. In2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2414–2423. doi:10.1109/CVPR.2016.265
-
[9]
Shuhao Guan, Moule Lin, Cheng Xu, Xinyi Liu, Jinman Zhao, Jiexin Fan, Qi Xu, and Derek Greene. 2025. PreP-OCR: A Complete Pipeline for Document Image Restoration and Enhanced OCR Accuracy. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and M...
-
[10]
Xun Huang and Serge Belongie. 2017. Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization. In2017 IEEE International Conference on Computer Vision (ICCV). 1510–1519. doi:10.1109/ICCV.2017.167
-
[11]
Huynh-Thu and M
Q. Huynh-Thu and M. Ghanbari. 2008. Scope of validity of PSNR in image/video quality assessment.Electronics letters44, 13 (2008), 800–801
2008
-
[12]
Christian Ledig, Lucas Theis, Ferenc Huszár, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, and Wenzhe Shi. 2017. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 105–114. doi:10.110...
-
[13]
V. I. Levenshtein. 1966. Binary Codes Capable of Correcting Deletions, Insertions and Reversals.Soviet Physics Doklady10 (Feb. 1966), 707
1966
-
[14]
Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. 2021. SwinIR: Image Restoration Using Swin Transformer. In2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW). 1833–1844. doi:10.1109/ICCVW54120. 2021.00210
-
[15]
Dong C Liu and Jorge Nocedal. 1989. On the limited memory BFGS method for large scale optimization.Mathematical programming45, 1-3 (1989), 503–528
1989
-
[16]
Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro. 2018. Image Inpainting for Irregular Holes Using Partial Convolutions. InProceedings of the European Conference on Computer Vision (ECCV)(Munich, Germany). Springer-Verlag, Berlin, Heidelberg, 89–105. doi:10.1007/978-3-030-01252-6_6
-
[17]
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. 2015. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, Nassir Navab, Joachim Hornegger, William M. Wells, and Alejandro F. Frangi (Eds.). Springer International Publishing, Cham, 234–241
2015
-
[18]
Karen Simonyan and Andrew Zisserman. 2014. Very Deep Convolutional Networks for Large-Scale Image Recognition.CoRR abs/1409.1556 (2014). http://arxiv.org/abs/1409.1556
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[19]
Ray Smith. 2007. An Overview of the Tesseract OCR Engine. InProceedings of the International Conference on Document Analysis and Recognition (ICDAR), Vol. 2. IEEE, 629–633
2007
-
[20]
Lempitsky
Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, Anastasia Remizova, Arsenii Ashukha, Aleksei Silvestrov, Naejin Kong, Harshith Goka, Kiwoong Park, and Victor S. Lempitsky. 2021. Resolution-robust Large Mask Inpainting with Fourier Convolutions.2022 IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV)(2021), 3172–3182. https://api.sem...
2021
-
[21]
Vasilis Toulatzis and Ioannis Fudos. 2019. Deep Terrain Expansion: Terrain Texture Synthesis with Deep Learning. InComputer Graphics and Visual Computing (CGVC), Franck P. Vidal, Gary K. L. Tam, and Jonathan C. Roberts (Eds.). The Eurographics Association. doi:10.2312/cgvc.20191262
-
[22]
Vasilis Toulatzis and Ioannis Fudos. 2021. Deep Tiling: Texture Tile Synthesis Using a Constant Space Deep Learning Approach. In Advances in Visual Computing, George Bebis, Vassilis Athitsos, Tong Yan, Manfred Lau, Frederick Li, Conglei Shi, Xiaoru Yuan, Christos Mousas, and Gerd Bruder (Eds.). Springer International Publishing, Cham, 414–426
2021
-
[23]
Dmitry Ulyanov, Andrea Vedaldi, and Victor Lempitsky. 2018. Deep Image Prior. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2018
-
[24]
Xintao Wang, Ke Yu, Shixiang Wu, Jinjin Gu, Yihao Liu, Chao Dong, Yu Qiao, and Chen Change Loy. 2018. ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks. InComputer Vision – ECCV 2018 Workshops: Munich, Germany, September 8-14, 2018, Proceedings, Part V(Munich, Germany). Springer-Verlag, Berlin, Heidelberg, 63–79. doi:10.1007/978-3-030-11021-5_5
-
[25]
Zhou Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli. 2004. Image quality assessment: from error visibility to structural similarity. Trans. Img. Proc.13, 4 (April 2004), 600–612. doi:10.1109/TIP.2003.819861
-
[26]
Zhenhua Yang, Dezhi Peng, Yongxin Shi, Yuyi Zhang, Chongyu Liu, and Lianwen Jin. 2025. Predicting the Original Appearance of Damaged Historical Documents.Proceedings of the AAAI Conference on Artificial Intelligence (AAAI)(2025). 34•Vasilis Toulatzis, Sofia Theodoridou, and Ioannis Fudos
2025
-
[27]
Kai Zhang, Yawei Li, Wangmeng Zuo, Lei Zhang, Luc Gool, and Radu Timofte. 2021. Plug-and-Play Image Restoration With Deep Denoiser Prior.IEEE Transactions on Pattern Analysis and Machine IntelligencePP (06 2021), 1–1. doi:10.1109/TPAMI.2021.3088914
-
[28]
Kai Zhang, Wangmeng Zuo, Yunjin Chen, Deyu Meng, and Lei Zhang. 2016. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising.IEEE Transactions on Image ProcessingPP (08 2016). doi:10.1109/TIP.2017.2662206
-
[29]
Zhang, Wangmeng Zuo, and Lei Zhang
K. Zhang, Wangmeng Zuo, and Lei Zhang. 2017. FFDNet: Toward a Fast and Flexible Solution for CNN-Based Image Denoising.IEEE Transactions on Image Processing27 (2017), 4608–4622. https://api.semanticscholar.org/CorpusID:10514149
2017
-
[30]
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. 2018. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 586–595
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.