Recognition: unknown
Single-Language Evidence Is Insufficient for Automated Logging: A Multilingual Benchmark and Empirical Study with LLMs
Pith reviewed 2026-05-10 05:15 UTC · model grok-4.3
The pith
Automated logging recommendations from large language models do not transfer reliably across programming languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
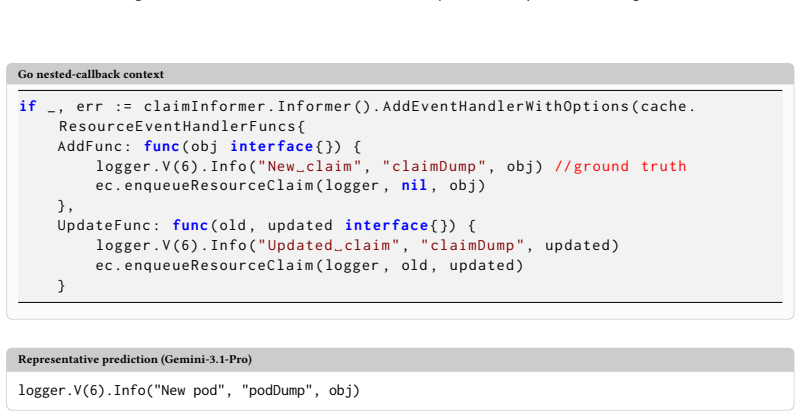
MultiLogBench demonstrates that logging-site localization, framework-anchor matching, severity prediction, and message generation exhibit cross-language variation when evaluated with a unified protocol on 63,965 snapshots and 744 revision cases from six languages. Framework matching proves the most language-sensitive task, loop and nested sites are hardest, and only the strongest models show stable rankings. Patterns observed on snapshot data largely hold on revision data, and input transformations do not produce a broad performance collapse.
What carries the argument
MultiLogBench, a benchmark containing production code snapshots and developer revision histories across six programming languages that enables direct comparison of LLM performance on logging decisions.
If this is right
- Performance gaps appear most sharply in framework-anchor matching.
- Certain code structures such as loops and nested callables consistently challenge models more than others.
- Rankings among the best models stay consistent while lower-ranked models vary with language.
- Snapshot-based evaluations largely predict outcomes on real maintenance revisions.
- Transformed code inputs do not trigger a uniform drop in quality across tasks.
Where Pith is reading between the lines
- Tool builders may need to supply language-specific prompts or fine-tuning for logging assistance beyond the top models.
- Similar multilingual benchmarks could expose hidden limitations in other software engineering automation tasks.
- Maintenance history data offers a more realistic test than static repositories for any code-change prediction work.
- Adding more languages or larger revision sets would clarify whether the observed variations are universal or tied to the current sample.
Load-bearing premise
The six languages and the collected snapshots plus revision cases form a representative sample of logging practices, and the shared evaluation protocol does not favor any language.
What would settle it
Finding that the same seven models produce nearly identical results on a new language or that framework matching shows no language differences would indicate that multilingual testing is unnecessary.
Figures












read the original abstract
Logging statements are central to debugging, failure diagnosis, and production observability, yet writing them requires developers to decide where to place a logging statement, which API and severity level to use, and what runtime information to expose. Automated logging aims to reduce this burden, but existing evidence remains dominated by Java-centric repository-snapshot dataset. It is therefore unclear whether conclusions about model behavior and model selection generalize across programming-language ecosystems or realistic code evolution. This paper presents MultiLogBench, a multilingual benchmark and empirical study spanning six programming language ecosystems. MultiLogBench contains 63,965 production-code repository-snapshot instances, 744 revision-history cases where developers introduce logging statements during maintenance, and a paired transformed revision-history branch for robustness analysis. Using seven contemporary large language models under a unified protocol, we evaluate logging-site localization, framework-anchor matching, severity prediction, message generation, variable recovery, and cascaded overall quality. Results show clear cross-language variation: framework-anchor matching is the most language-sensitive component, loop and nested-callable sites are the hardest structural contexts, and model rankings are stable only at the top tier. These patterns persist at a coarse level on revision-history data, while transformed inputs do not cause a broad same-direction performance collapse. Overall, MultiLogBench shows that robust claims about automated logging require multilingual evaluation and maintenance-oriented validation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MultiLogBench, a multilingual benchmark spanning six programming languages with 63,965 repository-snapshot instances and 744 revision-history cases where developers added logging statements. Using seven LLMs under a unified protocol, it evaluates logging-site localization, framework-anchor matching, severity prediction, message generation, variable recovery, and overall quality. The study reports cross-language performance variations (especially in framework-anchor matching and loop/nested-callable sites), stable top-tier model rankings, and that patterns hold coarsely on revision data without broad collapse on transformed inputs. It concludes that single-language evidence is insufficient and that multilingual evaluation plus maintenance-oriented validation are required for robust claims about automated logging.
Significance. If the representativeness and protocol fairness hold, this work provides a valuable large-scale multilingual resource that could shift the field away from Java-centric studies toward more generalizable findings on LLM-based logging automation. The inclusion of real revision-history cases for maintenance validation and the paired transformed branch for robustness testing are notable strengths that address gaps in prior snapshot-only evaluations. The empirical scale and multi-task protocol could serve as a foundation for future benchmarks if the cross-language variations are shown to reflect genuine differences rather than sampling or prompting artifacts.
major comments (2)
- [Abstract] Abstract and Data Collection: The 744 revision-history cases are an order of magnitude smaller than the 63,965 snapshots; without reported statistical power analysis, confidence intervals, or per-language breakdown of these cases, the claim that 'patterns persist at a coarse level on revision-history data' lacks sufficient support and weakens the maintenance-oriented validation argument.
- [Methodology] Evaluation Protocol: No details are provided on controls for project domain, logging-framework prevalence across languages, or per-language prompt adaptation/tokenization effects. This is load-bearing for the central claim, as unaddressed biases in the unified protocol could produce the observed cross-language variation (e.g., in framework-anchor matching) as artifacts rather than evidence that single-language studies are insufficient.
minor comments (2)
- [Abstract] The abstract uses 'coarse level' for revision-history persistence without defining the granularity or metrics used; a brief clarification would improve readability.
- Consider adding a table summarizing per-language snapshot and revision counts to make the scale and balance of the benchmark immediately visible.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our multilingual benchmark and its implications. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and Data Collection: The 744 revision-history cases are an order of magnitude smaller than the 63,965 snapshots; without reported statistical power analysis, confidence intervals, or per-language breakdown of these cases, the claim that 'patterns persist at a coarse level on revision-history data' lacks sufficient support and weakens the maintenance-oriented validation argument.
Authors: We agree that the smaller size of the revision-history set (744 cases) requires more transparent statistical reporting to support the maintenance-validation claim. In the revised manuscript we will add: (1) a per-language breakdown of the 744 cases, (2) 95% confidence intervals for the key metrics on the revision-history data, and (3) a brief discussion of statistical power limitations. We will also tone down the abstract claim from “patterns persist” to “patterns hold at a coarse level without broad collapse,” while retaining the point that the direction of results is consistent with the snapshot data. These changes strengthen rather than weaken the maintenance-oriented argument by making its evidential basis explicit. revision: yes
-
Referee: [Methodology] Evaluation Protocol: No details are provided on controls for project domain, logging-framework prevalence across languages, or per-language prompt adaptation/tokenization effects. This is load-bearing for the central claim, as unaddressed biases in the unified protocol could produce the observed cross-language variation (e.g., in framework-anchor matching) as artifacts rather than evidence that single-language studies are insufficient.
Authors: We accept that the current manuscript under-describes protocol controls. In the revised Methodology section we will add: (1) explicit criteria used to select repositories so that application domains (web services, utilities, data-processing tools) are represented across languages, (2) the observed prevalence of logging frameworks (e.g., Log4j vs. SLF4J in Java, logging vs. loguru in Python) within each language’s snapshot set, and (3) the exact prompt templates with the minimal language-specific adaptations (syntax only) while keeping task instructions identical. We will also note tokenization differences as an inherent model factor and add a short “Protocol Fairness and Limitations” subsection that discusses why the consistent ranking of top-tier models across languages makes pure artifact explanations less likely. These additions directly address the concern that cross-language variation might be protocol-induced. revision: yes
Circularity Check
No significant circularity: empirical benchmark with independent data collection
full rationale
The paper is an empirical study that collects new multilingual data (63,965 repository snapshots and 744 revision cases across six languages) and evaluates seven LLMs under a unified protocol on tasks like logging-site localization and severity prediction. No equations, fitted parameters, or derivations are present; conclusions follow directly from observed cross-language variations in the collected data. Representativeness and protocol fairness are external-validity assumptions, not reductions of any claim to its own inputs by construction. No self-citations, ansatzes, or renamings create load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The six selected programming languages and their production code instances adequately represent diverse logging practices across ecosystems.
- domain assumption The defined tasks (localization, severity prediction, message generation, etc.) and unified protocol capture the essential challenges of automated logging without language-specific bias.
Reference graph
Works this paper leans on
-
[1]
Roozbeh Aghili, Heng Li, and Foutse Khomh. 2025. Protecting Privacy in Software Logs: What Should Be Anonymized?Proc. ACM Softw. Eng.2, FSE, Article FSE060 (June 2025), 22 pages. https://doi.org/10.1145/3715779
-
[2]
Anthropic. 2026. Introducing Claude Sonnet 4.6. Anthropic News. https://www.anthropic.com/news/claude-sonnet-4-6 Accessed 2026-04-10
2026
-
[3]
Han Anu, Jie Chen, Wenchang Shi, Jianwei Hou, Bin Liang, and Bo Qin. 2019. An Approach to Recommendation of Verbosity Log Levels Based on Logging Intention. In2019 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 125–134. https: //doi.org/10.1109/icsme.2019.00022
-
[4]
Max Brunsfeld and tree-sitter contributors. 2026. tree-sitter: An Incremental Parsing System for Programming Tools. https://github.com/tree- sitter/tree-sitter. GitHub repository. Accessed April 17, 2026
2026
-
[5]
Jeanderson Candido, Jan Haesen, Mauricio Aniche, and Arie van Deursen. 2021. An Exploratory Study of Log Placement Recommendation in an Enterprise System. In2021 IEEE/ACM 18th International Conference on Mining Software Repositories (MSR). IEEE, 143–154. https://doi.org/10.1109/ msr52588.2021.00027
-
[6]
Boyuan Chen and Zhen Ming Jiang. 2017. Characterizing and detecting anti-patterns in the logging code. In2017 IEEE/ACM 39th International Conference on Software Engineering (ICSE). IEEE, 71–81. https://doi.org/10.1109/icse.2017.15
-
[7]
Boyuan Chen and Zhen Ming Jiang. 2017. Characterizing logging practices in Java-based open source software projects - a replication study in Apache Software Foundation.Empirical Software Engineering22, 1 (2017), 330–374. https://doi.org/10.1007/s10664-016-9429-5
-
[8]
Boyuan Chen and Zhen Ming Jiang. 2019. Extracting and studying the Logging-Code-Issue-Introducing changes in Java-based large-scale open source software systems.Empirical Software Engineering24, 4 (2019), 2285–2322. https://doi.org/10.1007/s10664-019-09690-0
-
[9]
Boyuan Chen and Zhen Ming Jiang. 2020. Studying the use of Java logging utilities in the wild. InProceedings of the ACM/IEEE 42nd International Conference on Software Engineering. ACM, 397–408. https://doi.org/10.1145/3377811.3380408
-
[10]
Ozren Dabic, Emad Aghajani, and Gabriele Bavota. 2021. Sampling projects in github for MSR studies. In2021 IEEE/ACM 18th International Conference on Mining Software Repositories (MSR). IEEE, 560–564. https://doi.org/10.1109/MSR52588.2021.00074
-
[11]
DeepSeek-AI. 2025. DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models. https://doi.org/10.48550/arXiv.2512.02556 arXiv:2512.02556 [cs.CL]
work page internal anchor Pith review doi:10.48550/arxiv.2512.02556 2025
-
[12]
Zishuo Ding, Heng Li, and Weiyi Shang. 2022. LoGenText: Automatically Generating Logging Texts Using Neural Machine Translation. In2022 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 349–360. https://doi.org/10.1109/saner53432.2022.00051
-
[13]
Zishuo Ding, Yiming Tang, Xiaoyu Cheng, Heng Li, and Weiyi Shang. 2023. LoGenText-Plus: Improving Neural Machine Translation Based Logging Texts Generation with Syntactic Templates.ACM Transactions on Software Engineering and Methodology33, 2 (2023), 1–45. https: //doi.org/10.1145/3624740
-
[14]
Zishuo Ding, Yiming Tang, Yang Li, Heng Li, and Weiyi Shang. 2023. On the temporal relations between logging and code. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 843–854. https://doi.org/10.1109/ICSE48619.2023.00079
-
[15]
Shengcheng Duan, Yihua Xu, Sheng Zhang, Shen Wang, and Yue Duan. 2025. PDLogger: Automated Logging Framework for Practical Software Development.arXiv preprint arXiv:2507.19951(2025). https://doi.org/10.48550/arXiv.2507.19951
-
[16]
Patrick Loic Foalem, Foutse Khomh, and Heng Li. 2024. Studying logging practice in machine learning-based applications.Information and Software Technology170 (2024), 107450. https://doi.org/10.1016/j.infsof.2024.107450
-
[17]
Qiang Fu, Jieming Zhu, Wenlu Hu, Jian-Guang Lou, Rui Ding, Qingwei Lin, Dongmei Zhang, and Tao Xie. 2014. Where do developers log? an empirical study on logging practices in industry. InCompanion Proceedings of the 36th International Conference on Software Engineering. ACM, 24–33. https://doi.org/10.1145/2591062.2591175
-
[18]
Sina Gholamian and Paul A. S. Ward. 2020. Logging statements’ prediction based on source code clones. InProceedings of the 35th Annual ACM Symposium on Applied Computing (SAC ’20). ACM, 82–91. https://doi.org/10.1145/3341105.3373845
-
[19]
GitHub. 2025. Octoverse: A New Developer Joins GitHub Every Second as AI Leads TypeScript to #1. https://github.blog/news-insights/octoverse/ octoverse-a-new-developer-joins-github-every-second-as-ai-leads-typescript-to-1/. GitHub Blog. Published October 28, 2025. Accessed April 3, 2026
2025
-
[20]
GLM-5-Team, Aohan Zeng, et al . 2026. GLM-5: from Vibe Coding to Agentic Engineering. https://doi.org/10.48550/arXiv.2602.15763 arXiv:2602.15763 [cs.LG]
work page internal anchor Pith review doi:10.48550/arxiv.2602.15763 2026
-
[21]
Wenwei Gu, Renyi Zhong, Guangba Yu, Xinying Sun, Jinyang Liu, Yintong Huo, Zhuangbin Chen, Jianping Zhang, Jiazhen Gu, Yongqiang Yang, and Michael R. Lyu. 2025. KPIRoot+: An Efficient Integrated Framework for Anomaly Detection and Root Cause Analysis in Large-Scale Cloud Systems.Empirical Software Engineering31, 2 (2025), 28. https://doi.org/10.1007/s1066...
-
[22]
Mehran Hassani, Weiyi Shang, Emad Shihab, and Nikolaos Tsantalis. 2018. Studying and detecting log-related issues.Empirical Software Engineering 23, 6 (2018), 3248–3280. https://doi.org/10.1007/s10664-018-9603-z
-
[23]
Shilin He, Pinjia He, Zhuangbin Chen, Tianyi Yang, Yuxin Su, and Michael R Lyu. 2021. A survey on automated log analysis for reliability engineering. ACM computing surveys (CSUR)54, 6 (2021), 1–37. https://doi.org/10.1145/3460345
-
[24]
Zhihan Jiang, Junjie Huang, Guangba Yu, Zhuangbin Chen, Yichen Li, Renyi Zhong, Cong Feng, Yongqiang Yang, Zengyin Yang, and Michael Lyu
-
[25]
InProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering
L4: Diagnosing large-scale llm training failures via automated log analysis. InProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering. 51–63. https://doi.org/10.1145/3696630.3728531
-
[26]
Suhas Kabinna, Cor-Paul Bezemer, Weiyi Shang, and Ahmed E. Hassan. 2016. Logging library migrations: a case study for the Apache Software Foundation projects. InProceedings of the 13th International Conference on Mining Software Repositories. ACM, 154–164. https://doi.org/10.1145/ 2901739.2901769
-
[27]
Suhas Kabinna, Cor-Paul Bezemer, Weiyi Shang, and Ahmed E. Hassan. 2018. Examining the stability of logging statements.Empirical Software Engineering23, 1 (2018), 290–333. https://doi.org/10.1007/s10664-017-9518-0
-
[28]
Taeyoung Kim, Suntae Kim, Sooyong Park, and YoungBeom Park. 2019. Automatic recommendation to appropriate log levels.Software: Practice and Experience50, 3 (2019), 189–209. https://doi.org/10.1002/spe.2771
-
[29]
Kimi Team, Tongtong Bai, et al. 2026. Kimi K2.5: Visual Agentic Intelligence. https://doi.org/10.48550/arXiv.2602.02276 arXiv:2602.02276 [cs.CL]
work page internal anchor Pith review doi:10.48550/arxiv.2602.02276 2026
-
[30]
Heng Li, Weiyi Shang, Bram Adams, Mohammed Sayagh, and Ahmed E. Hassan. 2021. A Qualitative Study of the Benefits and Costs of Logging From Developers’ Perspectives.IEEE Transactions on Software Engineering47, 12 (2021), 2858–2873. https://doi.org/10.1109/tse.2020.2970422
-
[31]
Heng Li, Weiyi Shang, and Ahmed E. Hassan. 2016. Which log level should developers choose for a new logging statement?Empirical Software Engineering22, 4 (2016), 1684–1716. https://doi.org/10.1007/s10664-016-9456-2
-
[32]
Heng Li, Haoxiang Zhang, Shaowei Wang, and Ahmed E. Hassan. 2022. Studying the Practices of Logging Exception Stack Traces in Open-Source Software Projects.IEEE Transactions on Software Engineering48, 12 (2022), 4907–4924. https://doi.org/10.1109/tse.2021.3129688
-
[33]
Min Li, Gou Tan, Pengfei Chen, and Chuanfu Zhang. 2026. LogGen: Integrating traditional model and LLM with code analysis for precise log generation.Journal of Systems and Software236 (2026), 112816. https://doi.org/10.1016/j.jss.2026.112816
-
[34]
Yichen Li, Yintong Huo, Zhihan Jiang, Renyi Zhong, Pinjia He, Yuxin Su, Lionel C. Briand, and Michael R. Lyu. 2024. Exploring the Effectiveness of LLMs in Automated Logging Statement Generation: An Empirical Study.IEEE Transactions on Software Engineering50, 12 (2024), 3188–3207. https://doi.org/10.1109/tse.2024.3475375
-
[35]
Yichen Li, Yintong Huo, Renyi Zhong, Zhihan Jiang, Jinyang Liu, Junjie Huang, Jiazhen Gu, Pinjia He, and Michael R. Lyu. 2024. Go Static: Contextualized Logging Statement Generation.Proceedings of the ACM on Software Engineering1, FSE (2024), 609–630. https://doi.org/10.1145/3643754
-
[36]
Yichen Li, Jinyang Liu, Junsong Pu, Zhihan Jiang, Zhuangbin Chen, Xiao He, Tieying Zhang, Jianjun Chen, Yi Li, Rui Shi, and Michael R. Lyu. 2025. Automated Proactive Logging Quality Improvement for Large-Scale Codebases. In2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). 3426–3437. https://doi.org/10.1109/ASE63991.2025.00283
-
[37]
Zhenhao Li, An Ran Chen, Xing Hu, Xin Xia, Tse-Hsun Chen, and Weiyi Shang. 2023. Are they all good? studying practitioners’ expectations on the readability of log messages. In2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 129–140. https://doi.org/10.1109/ASE56229.2023.00136
-
[38]
Zhenhao Li, Tse-Hsun Chen, Jinqiu Yang, and Weiyi Shang. 2019. DLFinder: Characterizing and Detecting Duplicate Logging Code Smells. In2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE). IEEE, 152–163. https://doi.org/10.1109/icse.2019.00032
-
[39]
Zhenhao Li, Tse-Hsun Chen, Jinqiu Yang, and Weiyi Shang. 2021. Studying duplicate logging statements and their relationships with code clones. IEEE Transactions on Software Engineering48, 7 (2021), 2476–2494. https://doi.org/10.1109/TSE.2021.3060918
-
[40]
Zhenhao Li, Tse-Hsun (Peter) Chen, and Weiyi Shang. 2020. Where shall we log?: studying and suggesting logging locations in code blocks. InProceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering (ASE). ACM, Virtual Event Australia. https: //doi.org/10.1145/3324884.3416636
-
[41]
Zhenhao Li, Heng Li, Tse-Hsun Chen, and Weiyi Shang. 2021. Deeplv: Suggesting log levels using ordinal based neural networks. In2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE). IEEE, 1461–1472. https://doi.org/10.1109/ICSE43902.2021.00131
-
[42]
Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. InText Summarization Branches Out. Association for Computational Linguistics, Barcelona, Spain, 74–81. https://aclanthology.org/W04-1013/
2004
-
[43]
Jiahao Liu, Jun Zeng, Xiang Wang, Kaihang Ji, and Zhenkai Liang. 2022. TeLL: log level suggestions via modeling multi-level code block information. InProceedings of the 31st ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA ’22). ACM, 27–38. https: //doi.org/10.1145/3533767.3534379
-
[44]
Zhongxin Liu, Xin Xia, David Lo, Zhenchang Xing, Ahmed E. Hassan, and Shanping Li. 2019. Which Variables Should I Log?IEEE Transactions on Software Engineering (TSE)(2019), 1–1. https://doi.org/10.1109/TSE.2019.2941943
-
[45]
Antonio Mastropaolo, Valentina Ferrari, Luca Pascarella, and Gabriele Bavota. 2024. Log statements generation via deep learning: Widening the support provided to developers.Journal of Systems and Software210 (2024), 111947. https://doi.org/10.1016/j.jss.2023.111947
-
[46]
Antonio Mastropaolo, Luca Pascarella, and Gabriele Bavota. 2022. Using deep learning to generate complete log statements. InProceedings of the 44th International Conference on Software Engineering(Pittsburgh, Pennsylvania)(ICSE ’22). Association for Computing Machinery, New York, NY, USA, 2279–2290. https://doi.org/10.1145/3510003.3511561 Manuscript submi...
-
[47]
OpenAI. 2025. Advanced usage: Reproducible outputs. https://platform.openai.com/docs/advanced-usage/reproducible-outputs. Accessed: 2025-11-30
2025
-
[48]
OpenAI. 2026. Introducing GPT-5.4. OpenAI Product Release. https://openai.com/index/introducing-gpt-5-4/ Accessed 2026-04-10
2026
-
[49]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics (ACL). 311–318. https://doi.org/10.3115/1073083.1073135
-
[50]
Qwen Team. 2025. Qwen3 Technical Report. https://doi.org/10.48550/arXiv.2505.09388 arXiv:2505.09388 [cs.CL] Official citation recommended by the Qwen3-Coder-480B-A35B-Instruct model card
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[51]
The P robabilistic R elevance F ramework: BM25 and B eyond
Stephen Robertson and Hugo Zaragoza. 2009.The probabilistic relevance framework: BM25 and beyond. Vol. 4. Now Publishers Inc. https: //doi.org/10.1561/1500000019
-
[52]
Guoping Rong, Shenghui Gu, He Zhang, Dong Shao, and Wanggen Liu. 2018. How Is Logging Practice Implemented in Open Source Software Projects? A Preliminary Exploration. In2018 25th Australasian Software Engineering Conference (ASWEC). IEEE, 171–180. https://doi.org/10.1109/ aswec.2018.00031
-
[53]
Guoping Rong, Yangchen Xu, Shenghui Gu, He Zhang, and Dong Shao. 2020. Can You Capture Information As You Intend To? A Case Study on Logging Practice in Industry. In2020 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 12–22. https: //doi.org/10.1109/icsme46990.2020.00012
-
[54]
June Sallou, Thomas Durieux, and Annibale Panichella. 2024. Breaking the silence: the threats of using llms in software engineering. InProceedings of the 2024 ACM/IEEE 44th International Conference on Software Engineering: New Ideas and Emerging Results. 102–106. https://doi.org/10.1145/ 3639476.3639764
-
[55]
Weiyi Shang, Meiyappan Nagappan, and Ahmed E. Hassan. 2015. Studying the relationship between logging characteristics and the code quality of platform software.Empirical Software Engineering20, 1 (2015), 1–27. https://doi.org/10.1007/s10664-013-9274-8
-
[56]
Weiyi Shang, Meiyappan Nagappan, Ahmed E. Hassan, and Zhen Ming Jiang. 2014. Understanding Log Lines Using Development Knowledge. In 2014 IEEE International Conference on Software Maintenance and Evolution. IEEE, 21–30. https://doi.org/10.1109/icsme.2014.24
-
[57]
Stack Overflow. 2024. 2024 Stack Overflow Developer Survey: Technology. https://survey.stackoverflow.co/2024/technology. Accessed April 3, 2026
2024
-
[58]
Boyin Tan, Junjielong Xu, Zhouruixing Zhu, and Pinjia He. 2025. AL-Bench: A Benchmark for Automatic Logging. https://doi.org/10.48550/ARXIV. 2502.03160
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[59]
Yiming Tang, Allan Spektor, Raffi Khatchadourian, and Mehdi Bagherzadeh. 2022. Automated evolution of feature logging statement levels using git histories and degree of interest.Science of Computer Programming214 (2022), 102724. https://doi.org/10.1016/j.scico.2021.102724
-
[60]
The Gemini Team. 2026. Gemini 3.1 Pro: A Smarter Model for Your Most Complex Tasks. Google Blog. https://blog.google/innovation-and- ai/models-and-research/gemini-models/gemini-3-1-pro/ Accessed 2026-04-10
2026
-
[61]
Xin Wang, Yang Feng, Jiaoxiao Qian, Yang Zhang, Zhenhao Li, and Zishuo Ding. 2026. Logging Like Humans for LLMs: Rethinking Logging via Execution and Runtime Feedback. https://doi.org/10.48550/arXiv.2603.29122 arXiv:2603.29122 [cs.SE]
-
[62]
Xin Wang, Zhenhao Li, and Zishuo Ding. 2025. Defects4Log: Benchmarking LLMs for Logging Code Defect Detection and Reasoning.arXiv preprint arXiv:2508.11305(2025). https://doi.org/10.48550/arXiv.2508.11305
-
[63]
Yi Wu, Nan Jiang, Hung Viet Pham, Thibaud Lutellier, Jordan Davis, Lin Tan, Petr Babkin, and Sameena Shah. 2023. How effective are neural networks for fixing security vulnerabilities. InProceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis. 1282–1294. https://doi.org/10.1145/3597926.3598135
-
[64]
Chunqiu Steven Xia, Yuxiang Wei, and Lingming Zhang. 2023. Automated program repair in the era of large pre-trained language models. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 1482–1494. https://doi.org/10.1109/ICSE48619.2023.00129
-
[65]
Xiaoyuan Xie, Zhipeng Cai, Songqiang Chen, and Jifeng Xuan. 2024. FastLog: An End-to-End Method to Efficiently Generate and Insert Logging Statements. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA ’24). ACM, 26–37. https: //doi.org/10.1145/3650212.3652107
-
[66]
Junjielong Xu, Ziang Cui, Yuan Zhao, Xu Zhang, Shilin He, Pinjia He, Liqun Li, Yu Kang, Qingwei Lin, Yingnong Dang, Saravan Rajmohan, and Dongmei Zhang. 2024. UniLog: Automatic Logging via LLM and In-Context Learning. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering (ICSE ’24). ACM, 1–12. https://doi.org/10.1145/3597503.3623326
-
[67]
Yi Zeng, Jinfu Chen, Weiyi Shang, and Tse-Hsun Chen. 2019. Studying the characteristics of logging practices in mobile apps: a case study on F-Droid.Empirical Software Engineering24, 6 (2019), 3394–3434. https://doi.org/10.1007/s10664-019-09687-9
-
[68]
Haonan Zhang, Yiming Tang, Maxime Lamothe, Heng Li, and Weiyi Shang. 2022. Studying Logging Practice in Test Code.Empirical Software Engineering27, 4 (2022), 83. https://doi.org/10.1007/s10664-022-10139-0
-
[69]
Xu Zhao, Kirk Rodrigues, Yu Luo, Michael Stumm, Ding Yuan, and Yuanyuan Zhou. 2017. Log20: Fully Automated Optimal Placement of Log Printing Statements under Specified Overhead Threshold. InProceedings of the 26th Symposium on Operating Systems Principles (SOSP). ACM, Shanghai China, 565–581. https://doi.org/10.1145/3132747.3132778
-
[70]
Chen Zhi, Jianwei Yin, Shuiguang Deng, Maoxin Ye, Min Fu, and Tao Xie. 2019. An Exploratory Study of Logging Configuration Practice in Java. In 2019 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 459–469. https://doi.org/10.1109/icsme.2019.00079
-
[71]
Chen Zhi, Jianwei Yin, Junxiao Han, and Shuiguang Deng. 2020. A Preliminary Study on Sensitive Information Exposure Through Logging. In2020 27th Asia-Pacific Software Engineering Conference (APSEC). IEEE, 470–474. https://doi.org/10.1109/apsec51365.2020.00058 Manuscript submitted to ACM 36 Renyi Zhong, Yichen Li, Yulun Wu, Jinxi Kuang, Yintong Huo, and Mi...
-
[72]
Renyi Zhong, Yintong Huo, Wenwei Gu, Yichen Li, and Michael R. Lyu. 2025. End-to-End Automated Logging via Multi-Agent Framework. https://doi.org/10.48550/arXiv.2511.18528 arXiv:2511.18528 [cs.SE]
-
[73]
Renyi Zhong, Yichen Li, Jinxi Kuang, Wenwei Gu, Yintong Huo, and Michael R. Lyu. 2025. LogUpdater: Automated Detection and Repair of Specific Defects in Logging Statements.ACM Trans. Softw. Eng. Methodol.35, 1, Article 16 (Dec. 2025), 31 pages. https://doi.org/10.1145/3731754
-
[74]
Renyi Zhong, Yichen Li, Guangba Yu, Wenwei Gu, Jinxi Kuang, Yintong Huo, and Michael R. Lyu. 2025. Larger Is Not Always Better: Exploring Small Open-source Language Models in Logging Statement Generation.ACM Transactions on Software Engineering and Methodology(2025). https://doi.org/10.1145/3773287
-
[75]
Rui Zhou, Mohammad Hamdaqa, Haipeng Cai, and Abdelwahab Hamou-Lhadj. 2020. MobiLogLeak: A Preliminary Study on Data Leakage Caused by Poor Logging Practices. In2020 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 577–581. https://doi.org/10.1109/saner48275.2020.9054831
-
[76]
Jieming Zhu, Pinjia He, Qiang Fu, Hongyu Zhang, Michael R. Lyu, and Dongmei Zhang. 2015. Learning to Log: Helping Developers Make Informed Logging Decisions. In2015 IEEE/ACM 37th IEEE International Conference on Software Engineering. IEEE, 415–425. https://doi.org/10.1109/icse.2015.60 Manuscript submitted to ACM
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.