Recognition: unknown
Infrastructure-Centric World Models: Bridging Temporal Depth and Spatial Breadth for Roadside Perception
Pith reviewed 2026-05-10 05:22 UTC · model grok-4.3
The pith
Infrastructure sensors provide persistent bird's-eye views that complement vehicle sensors by capturing long-term traffic dynamics in world models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
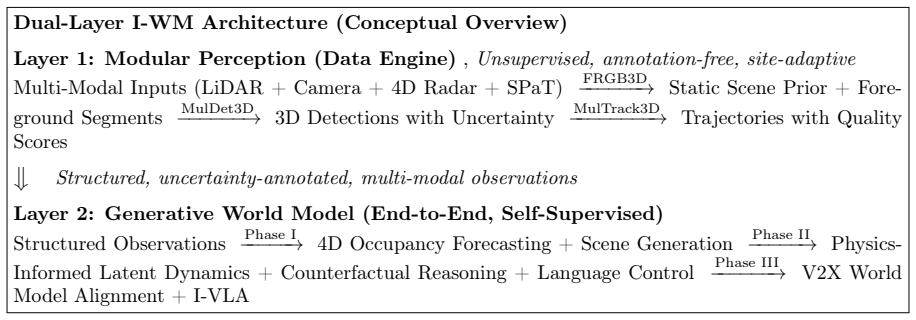
Infrastructure-centric world models offer a fundamentally complementary capability through the bird's-eye, multi-sensor, persistent viewpoint that roadside systems uniquely possess. Fixed sensors excel at temporal depth by building long-term behavioral distributions that include rare events, whereas vehicle sensors provide spatial breadth across road networks. The work presents this vision in three phases with a dual-layer architecture for annotation-free perception as a data engine, a phased sensor strategy, a taxonomy of driving world model paradigms, and the introduction of Infrastructure VLA as a unification of roadside perception, language, and control actions.
What carries the argument
Spatio-temporal complementarity between fixed roadside sensors' temporal depth and vehicle sensors' spatial breadth, implemented via a dual-layer architecture and phased sensor strategy for annotation-free generative models.
If this is right
- Phase I produces generative scene understanding that propagates quality-aware uncertainty from roadside multi-sensor data.
- Phase II enables physics-informed predictive dynamics with multi-agent counterfactual reasoning.
- Phase III supports collaborative world models through latent space alignment for V2X communication.
- The approach unifies roadside perception with language commands and traffic control actions under Infrastructure VLA.
- Existing multi-LiDAR pipelines can serve as foundations for scaling to annotation-free end-to-end models.
Where Pith is reading between the lines
- Fixed roadside installations could accumulate data on infrequent events more efficiently than fleets of moving vehicles.
- The phased sensor rollout allows incremental validation starting with current LiDAR deployments before adding newer modalities.
- Latent alignment techniques might reduce bandwidth needs when sharing world model states between infrastructure and vehicles.
- The same complementarity principle could apply to other persistent sensor networks such as urban surveillance grids.
Load-bearing premise
That the claimed complementarity between roadside temporal depth and vehicle spatial breadth holds in practice and that generative world models can be built annotation-free using the proposed dual-layer architecture.
What would settle it
A controlled test in which a generative world model trained solely on vehicle sensor data matches or exceeds the long-term prediction accuracy and rare-event handling of one that also incorporates roadside sensor streams.
Figures
read the original abstract
World models, generative AI systems that simulate how environments evolve, are transforming autonomous driving, yet all existing approaches adopt an ego-vehicle perspective, leaving the infrastructure viewpoint unexplored. We argue that infrastructure-centric world models offer a fundamentally complementary capability: the bird's-eye, multi-sensor, persistent viewpoint that roadside systems uniquely possess. Central to our thesis is a spatio-temporal complementarity: fixed roadside sensors excel at temporal depth, accumulating long-term behavioral distributions including rare safety-critical events, while vehicle-borne sensors excel at spatial breadth, sampling diverse scenes across large road networks. This paper presents a vision for Infrastructure-centric World Models (I-WM) in three phases: (I) generative scene understanding with quality-aware uncertainty propagation, (II) physics-informed predictive dynamics with multi-agent counterfactual reasoning, and (III) collaborative world models for V2X communication via latent space alignment. We propose a dual-layer architecture, annotation-free perception as a multi-modal data engine feeding end-to-end generative world models, with a phased sensor strategy from LiDAR through 4D radar and signal phase data to event cameras. We establish a taxonomy of driving world model paradigms, position I-WM relative to LeCun's JEPA, Li Fei-Fei's spatial intelligence, and VLA architectures, and introduce Infrastructure VLA (I-VLA) as a novel unification of roadside perception, language commands, and traffic control actions. Our vision builds upon existing multi-LiDAR pipelines and identifies open-source foundations for each phase, providing a path toward infrastructure that understands and anticipates traffic.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that infrastructure-centric world models (I-WM) provide a fundamentally complementary capability to ego-vehicle world models by leveraging the bird's-eye, multi-sensor, persistent viewpoint unique to roadside systems. It centers on a spatio-temporal complementarity argument—fixed sensors for temporal depth and long-term behavioral distributions including rare events, vehicles for spatial breadth—and outlines a three-phase roadmap: (I) generative scene understanding with quality-aware uncertainty propagation, (II) physics-informed predictive dynamics with multi-agent counterfactual reasoning, and (III) collaborative world models for V2X via latent space alignment. The manuscript proposes a dual-layer architecture with annotation-free perception as a multi-modal data engine, a phased sensor strategy (LiDAR to 4D radar to event cameras), a taxonomy of driving world model paradigms, positioning relative to JEPA and VLA, and introduces Infrastructure VLA (I-VLA).
Significance. If the complementarity argument and phased roadmap hold, the vision could advance persistent, infrastructure-supported perception for better modeling of long-term traffic behaviors and rare safety-critical events, with potential benefits for V2X collaboration and safety. The paper's strengths include its explicit taxonomy, positioning within existing frameworks (JEPA, spatial intelligence, VLA), and identification of open-source foundations for each phase, which supplies a structured, actionable research agenda rather than purely abstract speculation.
minor comments (3)
- [Dual-layer architecture] The dual-layer architecture and annotation-free strategy are described conceptually; a diagram or pseudocode sketch of the data flow from the perception layer to the generative world model layer would substantially improve clarity and allow readers to assess feasibility.
- [Taxonomy] The taxonomy of driving world model paradigms is referenced but not detailed with examples or a comparative table; including such a summary would help position I-WM more concretely relative to ego-centric approaches.
- [Phased sensor strategy] The phased sensor strategy (LiDAR through 4D radar, signal phase data, event cameras) is listed at a high level; brief discussion of fusion or synchronization challenges across these modalities would strengthen the practicality of the proposed data engine.
Simulated Author's Rebuttal
We thank the referee for the detailed summary, recognition of the paper's strengths in taxonomy and positioning, and the recommendation for minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The manuscript is a vision paper that frames its central thesis as an argument for spatio-temporal complementarity between roadside and vehicle sensors, along with a three-phase research roadmap and dual-layer architecture proposal. No equations, derivations, fitted parameters, or quantitative predictions appear in the text; the claims rest on descriptive positioning relative to external works (LeCun's JEPA, Li Fei-Fei's spatial intelligence, VLA architectures) rather than any self-referential reduction or self-citation chain. The proposal explicitly identifies itself as forward-looking future work without claiming completed technical results that could loop back to its own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption World models are generative AI systems that simulate how environments evolve
- domain assumption Fixed roadside sensors excel at temporal depth while vehicle-borne sensors excel at spatial breadth
invented entities (2)
-
Infrastructure-centric World Models (I-WM)
no independent evidence
-
Infrastructure VLA (I-VLA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Self-supervised learning from images with a joint- embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint- embedding predictive architecture. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[2]
V-JEPA 2: Self-supervised video models enable understanding, prediction, and planning
Mahmoud Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Mojtaba Komeili, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-JEPA 2: Self-supervised video models enable understanding, prediction, and planning. Meta AI Research, 2025. V-JEPA 2.1 released March 2026
2025
-
[3]
Lejepa: Provable and scalable self-supervised learning without the heuristics, 2025
Randall Balestriero and Yann LeCun. LeJEPA: Provable and scalable self-supervised learning without the heuristics.arXiv preprint arXiv:2511.08544, 2025
-
[4]
DynamicCity: Large-scale 4D occupancy generation from dynamic scenes
Hengwei Bian, Lingdong Kong, Haozhe Xie, Liang Pan, Yu Qiao, and Ziwei Liu. DynamicCity: Large-scale 4D occupancy generation from dynamic scenes. InInternational Conference on Learning Representations (ICLR), 2025. Spotlight paper
2025
-
[5]
Physics-informed deep learning for traffic state estimation: A survey and the outlook.Algorithms, 16(6):305, 2023
Xuan Di, Rongye Shi, Zhaobin Mo, and Yongjie Fu. Physics-informed deep learning for traffic state estimation: A survey and the outlook.Algorithms, 16(6):305, 2023
2023
-
[6]
Understanding world or predicting future? A comprehensive survey of world models.ACM Computing Surveys, 58(3):1–38, 2025
Jingtao Ding, Yunke Zhang, Yu Shang, Yuheng Zhang, Zefang Zong, Jie Feng, Yuan Yuan, Hongyuan Su, Nian Li, Nicholas Sukiennik, et al. Understanding world or predicting future? A comprehensive survey of world models.ACM Computing Surveys, 58(3):1–38, 2025
2025
-
[7]
4D mmwave radar for autonomous driving perception: A comprehensive survey.IEEE Transactions on Intelligent Vehicles, 9:4606–4620, 2024
Lili Fan, Jianming Wang, Yuxue Chang, Yang Li, Yue Wang, and Dong Cao. 4D mmwave radar for autonomous driving perception: A comprehensive survey.IEEE Transactions on Intelligent Vehicles, 9:4606–4620, 2024. 14
2024
-
[8]
A survey of world models for autonomous driving.arXiv preprint arXiv:2501.11260, 2025
Tuo Feng, Wenguan Wang, and Yi Yang. A survey of world models for autonomous driving. ACM Computing Surveys, 2025. arXiv:2501.11260
-
[9]
Dechen Gao, Shuangyu Cai, Hanchu Zhou, Hang Wang, Iman Soltani, and Junshan Zhang. CarDreamer: Open-source learning platform for world model based autonomous driving.IEEE Internet of Things Journal, 12:2866–2875, 2024. arXiv:2405.09111
-
[10]
Vista: A generalizable driving world model with high fidelity and versatile controllability
Shenyuan Gao, Jiazhi Yang, Li Chen, Kashyap Chitta, Yihang Qiu, Andreas Geiger, Jun Zhang, and Hongyang Li. Vista: A generalizable driving world model with high fidelity and versatile controllability. InAdvances in Neural Information Processing Systems, volume 37, pages 91560–91596, 2024
2024
-
[11]
Yanchen Guan, Haicheng Liao, Zhenning Li, Jia Hu, Chengzhong Xu, Yunjian Zhang, Guofa Li, and Changjun Jiang. World models for autonomous driving: An initial survey.IEEE Transactions on Intelligent Vehicles, 2024. arXiv:2403.02622
-
[12]
Masteringdiversedomains through world models.Nature, 2025
DanijarHafner, JurgisPasukonis, JimmyBa, andTimothyLillicrap. Masteringdiversedomains through world models.Nature, 2025
2025
-
[13]
Research challenges and progress in the end- to-end V2X cooperative autonomous driving competition
Ruiyang Hao, Haibao Yu, Jiaru Zhong, Chuanye Wang, Jiahao Wang, Yiming Kan, Wenxian Yang, Siqi Fan, Huilin Yin, Jianing Qiu, et al. Research challenges and progress in the end- to-end V2X cooperative autonomous driving competition. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, pages 1828–1839, 2025
2025
-
[14]
GAIA-1: A Generative World Model for Autonomous Driving
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. GAIA-1: A generative world model for autonomous driving. arXiv preprint arXiv:2309.17080, 2023
work page internal anchor Pith review arXiv 2023
-
[15]
RangeLDM: Fast realistic LiDAR point cloud generation
Qianjiang Hu, Zhimin Zhang, and Wei Hu. RangeLDM: Fast realistic LiDAR point cloud generation. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[16]
V2X-R: Cooperative LiDAR-4D radar fusion for 3D object detection with denoising diffusion
Hao Huang et al. V2X-R: Cooperative LiDAR-4D radar fusion for 3D object detection with denoising diffusion. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[17]
Tao Huang, Jiaxing Chen, Shan Zhang, Jianming Hu, Yi Zhang, and Shengbo Eben Li. Vehicle- to-everything cooperative perception for autonomous driving.IEEE Transactions on Intelligent Transportation Systems, 2025. arXiv:2310.03525
-
[18]
STDEN: Towards physics- guided neural networks for traffic flow prediction
Jiahao Ji, Jingyuan Wang, Zhe Jiang, Jiawei Jiang, and Hu Zhang. STDEN: Towards physics- guided neural networks for traffic flow prediction. InProceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 4048–4056, 2022
2022
-
[19]
A path towards autonomous machine intelligence.OpenReview preprint, 2022
Yann LeCun. A path towards autonomous machine intelligence.OpenReview preprint, 2022
2022
-
[20]
End-to-end autonomous driving through V2X cooperation
Boyi Li et al. End-to-end autonomous driving through V2X cooperation. InProceedings of the AAAI Conference on Artificial Intelligence, 2024
2024
-
[21]
From words to worlds: Spatial intelligence is AI’s next fron- tier
Fei-Fei Li. From words to worlds: Spatial intelligence is AI’s next fron- tier. Substack, November 2025. URLhttps://drfeifei.substack.com/p/ from-words-to-worlds-spatial-intelligence. 15
2025
-
[22]
Yingyan Li, Shuyao Shang, Weisong Liu, Bing Zhan, Haochen Wang, Yuqi Wang, Yuntao Chen, Xiaoman Wang, Yasong An, Chufeng Tang, et al. DriveVLA-W0: World models amplify data scaling law in autonomous driving. InInternational Conference on Learning Representations (ICLR), 2026. arXiv:2510.12796
-
[23]
LeWorld- Model: Stable end-to-end joint-embedding predictive architecture from pixels.arXiv preprint, 2026
LucasMaes, QuentinLeLidec, DamienScieur, YannLeCun, andRandallBalestriero. LeWorld- Model: Stable end-to-end joint-embedding predictive architecture from pixels.arXiv preprint, 2026
2026
-
[24]
DriveWorld: 4D pre-trained scene understanding via world models for autonomous driving
Chen Min, Dawei Zhao, Liang Xiao, Jian Zhao, Xinli Xu, Zheng Zhu, Lei Jin, Jianshu Li, Yulan Guo, Junliang Xing, et al. DriveWorld: 4D pre-trained scene understanding via world models for autonomous driving. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15522–15533, 2024
2024
-
[25]
Traffic signal control via reinforcement learning: A review on appli- cations and innovations.Infrastructures, 10(5):114, 2025
Mohammad Noaeen et al. Traffic signal control via reinforcement learning: A review on appli- cations and innovations.Infrastructures, 10(5):114, 2025
2025
-
[26]
Cosmos World Foundation Model Platform for Physical AI
NVIDIA. Cosmos world foundation model platform for physical AI.arXiv preprint arXiv:2501.03575, 2025
work page internal anchor Pith review arXiv 2025
-
[27]
MaziarRaissi, ParisPerdikaris, andGeorgeEmKarniadakis. Physics-informedneuralnetworks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational Physics, 378:686–707, 2019
2019
-
[28]
Towards realistic scene generation with LiDAR diffusion models
Haoxi Ran, Vitor Guizilini, and Yue Wang. Towards realistic scene generation with LiDAR diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[29]
Advancing open-source world models,
Robbyant Team, Ant Group. Advancing open-source world models: LingBot-World.arXiv preprint arXiv:2601.20540, 2025
-
[30]
UrbanWorld: An urban world model for 3D city generation.arXiv preprint arXiv:2407.11965, 2024
Yu Shang, Yuming Lin, Yu Zheng, Hangyu Fan, Jingtao Ding, Jie Feng, Jiansheng Chen, Li Tian, and Yong Li. UrbanWorld: An urban world model for 3D city generation.arXiv preprint arXiv:2407.11965, 2024
-
[31]
Hierarchical reinforcement learning-based traffic signal control.Scientific Reports, 15:32862, 2025
Jiahao Shen. Hierarchical reinforcement learning-based traffic signal control.Scientific Reports, 15:32862, 2025
2025
-
[32]
HunyuanWorld 1.0: Generating immersive, explorable, and inter- active 3D worlds from words or pixels.arXiv preprint, 2025
Tencent Hunyuan3D Team. HunyuanWorld 1.0: Generating immersive, explorable, and inter- active 3D worlds from words or pixels.arXiv preprint, 2025
2025
-
[33]
Sifan Tu, Xin Zhou, Dingkang Liang, Xingyu Jiang, Yumeng Zhang, Xiaofan Li, and Xiang Bai. The role of world models in shaping autonomous driving: A comprehensive survey.arXiv preprint arXiv:2502.10498, 2025
-
[34]
V2XScenes: A multiple challenging traffic conditions dataset for large- range vehicle-infrastructure cooperative perception
Chuanye Wang et al. V2XScenes: A multiple challenging traffic conditions dataset for large- range vehicle-infrastructure cooperative perception. InIEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[35]
Research on world models for connected automated driving: Advances, challenges, and outlook.Applied Sciences, 15(16):8986, 2025
Haoran Wang et al. Research on world models for connected automated driving: Advances, challenges, and outlook.Applied Sciences, 15(16):8986, 2025. 16
2025
-
[36]
Drive- Dreamer: Towards real-world-driven world models for autonomous driving
Xiaofeng Wang, Zheng Zhu, Guan Huang, Xinze Chen, Jiagang Zhu, and Jiwen Lu. Drive- Dreamer: Towards real-world-driven world models for autonomous driving. InEuropean Con- ference on Computer Vision (ECCV), 2024
2024
-
[37]
Driving into the future: Multiview visual forecasting and planning with world model for autonomous driving
Yuqi Wang, Jiawei He, Lue Fan, Hongxin Li, Yuntao Chen, and Zhaoxiang Zhang. Driving into the future: Multiview visual forecasting and planning with world model for autonomous driving. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[38]
The Waymo world model: A new frontier for autonomous driving simulation
Waymo Team. The Waymo world model: A new frontier for autonomous driving simulation. Waymo Blog, February 2026. URLhttps://waymo.com/blog/2026/02/ the-waymo-world-model-a-new-frontier-for-autonomous-driving-simulation
2026
-
[39]
Marble: A multimodal world model for spatial intelligence
World Labs. Marble: A multimodal world model for spatial intelligence. World Labs, 2025. URLhttps://www.worldlabs.ai/blog
2025
-
[40]
V2X-Real: A large-scale dataset for vehicle-to-everything cooperative perception
Hao Xiang, Zhaoliang Zheng, Xin Xia, Runsheng Xu, Letian Gao, Zewei Zhou, et al. V2X-Real: A large-scale dataset for vehicle-to-everything cooperative perception. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[41]
V2X- ViT: Vehicle-to-everything cooperative perception with vision transformer
Runsheng Xu, Hao Xiang, Zhengzhong Tu, Xin Xia, Ming-Hsuan Yang, and Jiaqi Ma. V2X- ViT: Vehicle-to-everything cooperative perception with vision transformer. InEuropean Con- ference on Computer Vision (ECCV), 2022
2022
-
[42]
Driving in the occupancy world: Vision-centric 4D occupancy forecasting and planning via world models for autonomous driving
Yu Yang, Jianbiao Mei, Yukai Ma, Siliang Du, Wenqing Chen, Yijie Qian, Yuxiang Feng, and Yong Liu. Driving in the occupancy world: Vision-centric 4D occupancy forecasting and planning via world models for autonomous driving. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 9327–9335, 2025
2025
-
[43]
DAIR-V2X: A large-scale dataset for vehicle-infrastructure cooperative 3D object detection
Haibao Yu, Yizhen Luo, Mao Shu, Yiyi Huo, Zebang Yang, Yifeng Shi, Zhenglong Guo, Hanyu Li, Xing Hu, Jirui Yuan, et al. DAIR-V2X: A large-scale dataset for vehicle-infrastructure cooperative 3D object detection. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21361–21370, 2022
2022
-
[44]
V2X-Seq: A large-scale sequential dataset for vehicle- infrastructure cooperative perception and forecasting
Haibao Yu, Wenxian Yang, Hongzhi Ruan, Zhenwei Yang, Yingjuan Tang, Xu Gao, Xin Hao, Yifeng Shi, Yifeng Pan, Ning Sun, et al. V2X-Seq: A large-scale sequential dataset for vehicle- infrastructure cooperative perception and forecasting. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5486–5495, 2023
2023
-
[45]
Jinqing Zhang, Zehua Fu, Zelin Xu, Wenying Dai, Qingjie Liu, and Yunhong Wang. ResWorld: Temporal residual world model for end-to-end autonomous driving. InInternational Conference on Learning Representations (ICLR), 2026. arXiv:2602.10884
-
[46]
NeRF-LiDAR: Generating realistic LiDAR point clouds with neural radiance fields
Junge Zhang, Feihu Zhang, Shaochen Kuang, and Li Zhang. NeRF-LiDAR: Generating realistic LiDAR point clouds with neural radiance fields. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 7178–7186, 2024
2024
-
[47]
Physics-informed deep learning for traffic state estimation based on the traffic flow model and computational graph method.Information Fusion, 101:101971, 2024
Junyi Zhang, Shuai Mao, Lufeng Yang, Wei Ma, Shukai Li, and Ziyou Gao. Physics-informed deep learning for traffic state estimation based on the traffic flow model and computational graph method.Information Fusion, 101:101971, 2024. 17
2024
-
[48]
Copi- lot4D: Learning unsupervised world models for autonomous driving via discrete diffusion
Lunjun Zhang, Yuwen Xiong, Ze Yang, Sergio Casas, Rui Hu, and Raquel Urtasun. Copi- lot4D: Learning unsupervised world models for autonomous driving via discrete diffusion. In International Conference on Learning Representations (ICLR), 2024
2024
-
[49]
Epona: Autoregressive diffusion world model for autonomous driving
Shuyang Zhang et al. Epona: Autoregressive diffusion world model for autonomous driving. InIEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[50]
OccWorld: Learning a 3D occupancy world model for autonomous driving
Wenzhao Zheng, Weiliang Chen, Yuanhui Huang, Borui Zhang, Yueqi Duan, and Jiwen Lu. OccWorld: Learning a 3D occupancy world model for autonomous driving. InEuropean Con- ference on Computer Vision (ECCV), pages 55–72, 2024
2024
-
[51]
HERMES: A unified self-driving world model for simulta- neous 3D scene understanding and generation
Xin Zhou, Dingkang Liang, Sifan Tu, Xiwu Chen, Yikang Ding, Dingyuan Zhang, Feiyang Tan, Hengshuang Zhao, and Xiang Bai. HERMES: A unified self-driving world model for simulta- neous 3D scene understanding and generation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 27817–27827, 2025
2025
-
[52]
Walter Zimmer, Christian Creß, Huu Tung Nguyen, and Alois C. Knoll. TUMTraf intersection dataset: All you need for urban 3D camera-LiDAR roadside perception. InIEEE International Conference on Intelligent Transportation Systems (ITSC), 2023. IEEE Best Student Paper Award
2023
-
[53]
Walter Zimmer, Gerhard Arya Wardana, Suren Sritharan, Xingcheng Zhou, Rui Song, and Alois C. Knoll. TUMTraf V2X cooperative perception dataset. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[54]
LidarDM: Generative LiDAR simulation in a generated world.arXiv preprint arXiv:2404.02903, 2024
Vlas Zyrianov, Henry Che, Zhijian Liu, and Shenlong Wang. LidarDM: Generative LiDAR simulation in a generated world.arXiv preprint arXiv:2404.02903, 2024. 18
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.